
GBDT算法梳理
1.GBDT(Gradient Boosting Decision Tree)思想
Boosting :
给定初始训练数据,由此训练出第一个基学习器;
根据基学习器的表现对样本进行调整,在之前学习器做错的样本上投入更多关注;
用调整后的样本,训练下一个基学习器;
重复上述过程 T 次,将 T 个学习器加权结合。
Gradient boosting
Gradient boosting是 boosting 的其中一种方法,它主要的思想是,每一次建立单个学习器时,是在之前建立的模型的损失函数的梯度下降方向。
我们知道损失函数(loss function)越大,说明模型越容易出错,如果我们的模型能够让损失函数持续的下降,则说明我们的模型在不停的改进,而最好的方式就是让损失函数在其梯度(Gradient)的方向上下降。
GBDT
GBDT是 GB 和 DT(Decision Tree) 的结合,就是当 GB 中的单个学习器为决策树时的情况.决策树分为两大类,回归树和分类树。前者用于预测实数值,如明天的温度、用户的年龄、网页的相关程度;后者用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。这里要强调的是,前者的结果加减是有意义的,如10岁+5岁-3岁=12岁,后者则无意义,如男+男+女=到底是男是女?GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;
如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。而分类树的结果显然是没办法累加的,所以GBDT中的树都是回归树,这点对理解GBDT相当重要
我们通过一张图片,来说明gbdt的训练过程:

gbdt通过多轮迭代,每轮迭代产生一个弱分类器,每个分类器在上一轮分类器的残差基础上进行训练。对弱分类器的要求一般是足够简单,并且是低方差和高偏差的。因为训练的过程是通过降低偏差来不断提高最终分类器的精度,(此处是可以证明的)。
弱分类器一般会选择为CART TREE(也就是分类回归树)。由于上述高偏差和简单的要求 每个分类回归树的深度不会很深。最终的总分类器 是将每轮训练得到的弱分类器加权求和得到的(也就是加法模型)。
模型最终可以描述为:

2.负梯度拟合
我们希望找到一个 使得
最小,那么
就得沿着使损失函数L减小的方向变化,即:
同时,最新的学习器是由当前学习器 与本次要产生的回归树
相加得到的:
因此,为了让损失函数减小,需要令:
即用损失函数对f(x)的负梯度来拟合回归树。
3.损失函数
这里我们再对常用的GBDT损失函数做一个总结。
对于分类算法,其损失函数一般有对数损失函数和指数损失函数两种:
a) 如果是指数损失函数,则损失函数表达式为

b) 如果是对数损失函数,分为二元分类和多元分类两种,参见4节和5节。
对于回归算法,常用损失函数有如下3种:
a)均方差,这个是最常见的回归损失函数了
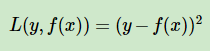
b)绝对损失,这个损失函数也很常见

对应负梯度误差为:
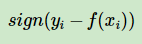
4.回归分类

5.多元分类


对于上式,我曾详细地推导过一次,大家可以看这里--> 深度学习数学推导之Sigmoid,Softmax,Cross-entropy

6.正则化
我们需要对GBDT进行正则化,防止过拟合。GBDT的正则化主要有三种方式。
1) 第一种是步长(learning rate)。定义为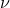 ,对于前面的弱学习器的迭代
,对于前面的弱学习器的迭代

如果我们加上了正则化项,则有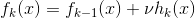
的取值范围为 。
。
对于同样的训练集学习效果,较小的意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
2)第二种是对于弱学习器即CART回归树进行正则化剪枝。
3) 第三种正则化的方式是通过子采样比例(subsample)。取值为(0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间。
7.优缺点
GBDT主要的优点有:
1) 可以灵活处理各种类型的数据,包括连续值和离散值。
2) 在相对少的调参时间情况下,预测的准确率也可以比较高。这个是相对SVM来说的。
3)使用一些健壮的损失函数,对异常值的鲁棒性非常强。比如 Huber损失函数和Quantile损失函数。
GBDT的主要缺点有:
1)由于弱学习器之间存在依赖关系,难以并行训练数据。不过可以通过自采样的SGBT来达到部分并行。
8.sklearn参数
sklearn.ensemble.GradientBoostingRegressor(
loss='ls', ##默认ls损失函数'ls'是指最小二乘回归lad'(最小绝对偏差)'huber'是两者的组合
n_estimators=100, ##默认100 回归树个数 弱学习器个数
learning_rate=0.1, ##默认0.1学习速率/步长0.0-1.0的超参数 每个树学习前一个树的残差的步长
max_depth=3, ## 默认值为3每个回归树的深度 控制树的大小 也可用叶节点的数量max leaf nodes控制
subsample=1, ##用于拟合个别基础学习器的样本分数 选择子样本<1.0导致方差的减少和偏差的增加
min_samples_split=2, ##生成子节点所需的最小样本数 如果是浮点数代表是百分比
min_samples_leaf=1, ##叶节点所需的最小样本数 如果是浮点数代表是百分比
max_features=None, ##在寻找最佳分割点要考虑的特征数量auto全选/sqrt开方/log2对数/None全选/int自定义几个/float百分比
max_leaf_nodes=None, ##叶节点的数量 None不限数量
min_impurity_split=1e-7, ##停止分裂叶子节点的阈值
verbose=0, ##打印输出 大于1打印每棵树的进度和性能
warm_start=False, ##True在前面基础上增量训练 False默认擦除重新训练 增加树
random_state=0 ##随机种子-方便重现
)
9.应用场景
GBDT几乎可用于所有回归问题(线性/非线性),相对logistic regression仅能用于线性回归,GBDT的适用面非常广。亦可用于二分类问题(设定阈值,大于阈值为正例,反之为负例)。
https://www.jianshu.com/p/d55f7aaac4a7
https://www.cnblogs.com/peizhe123/p/5086128.html
http://www.cnblogs.com/duan-decode/p/9889955.html
http://www.cnblogs.com/sandy-t/p/6863918.html
https://blog.csdn.net/qq_20412595/article/details/82589378

