
福大软工1816 · 第五次作业 - 结对作业2
一、在文章开头给出结对同学的博客链接、本作业博客的链接、你所Fork的同名仓库的Github项目地址
结对同学的博客链接:https://www.cnblogs.com/YangLiLiang/p/9752105.html
本作业博客的链接:https://edu.cnblogs.com/campus/fzu/Grade2016SE/homework/2138
Github项目地址:https://github.com/Stellaaa18/pair-project
二、给出具体分工
林翔宇:负责实现多参数混合使用功能实现;单词数统计,词频统计;负责整合代码;性能分析;
杨礼亮:负责爬虫、处理数据;分权重词频统计部分代码;实现字符、行数统计部分代码;
各自写自己负责部分的博客。
三、给出PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 15 |
| Development | 开发 | 580 | 840 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 60 | 150 |
| · Coding | · 具体编码 | 240 | 300 |
| · Code Review | · 代码复审 | 60 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 160 | 240 |
| Reporting | 报告 | 130 | 140 |
| · Test Repor | · 测试报告 | 90 | 100 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| | 合计 |720 | 995
四、解题思路描述与设计实现说明
1、爬虫使用
爬虫工具:八爪鱼采集器
使用方法:
这个工具使用起来很简易。
首先建立一个自定义采集,输入将要采集的网页网址,保存网址后便会自动跳转。
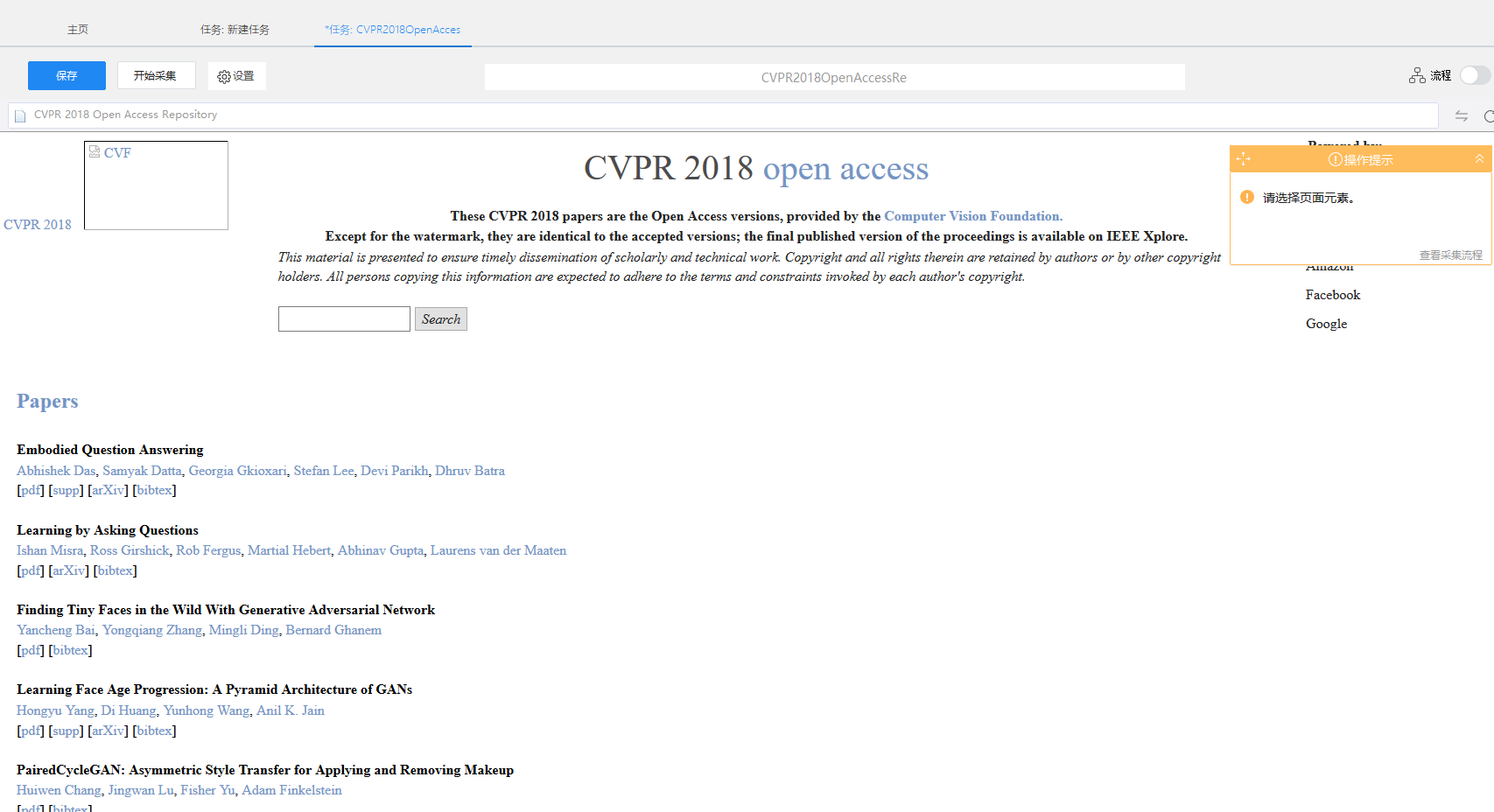
第二,我将标题与简介分开采集,采集标题只需要在本页面直接采集,采集简介要设计循环链接。

采集完成后就可以以excel格式导出,再将excel中的数据粘贴到文本中。
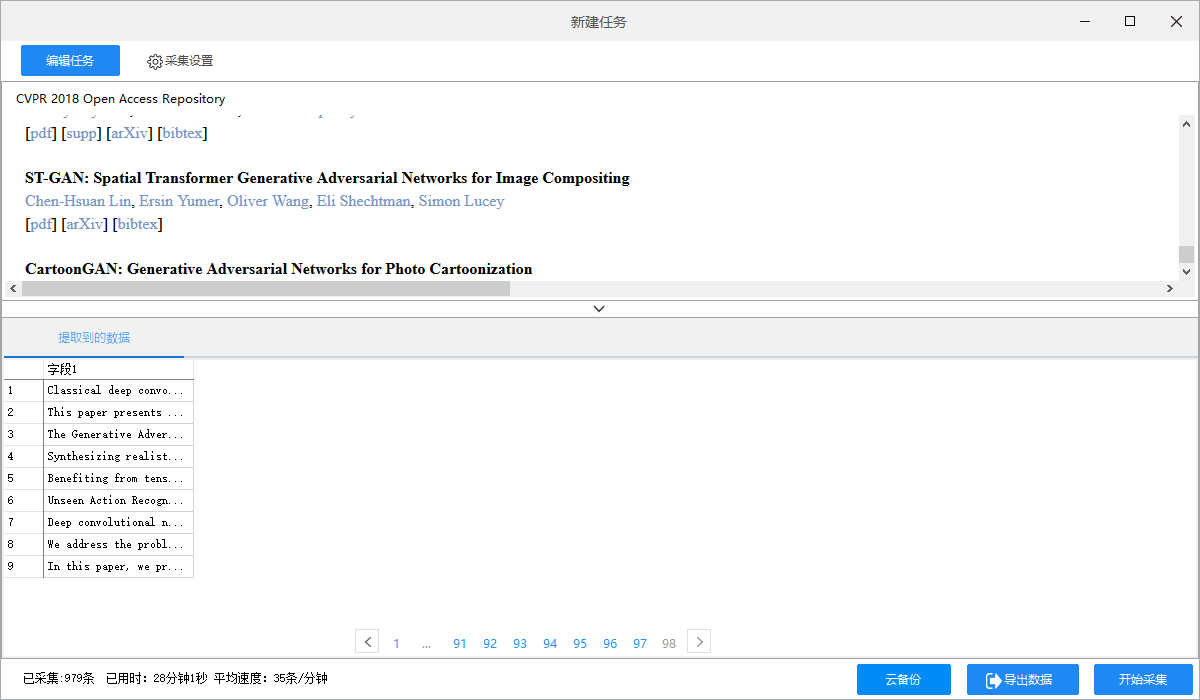
我是将标题和简介放到两个文本中,采集后的数据比较混乱,需要按格式输出,所以用c语言写了一些程序来整理文本。
这里附上一些伪代码
//在简介前面加上 Abstract:
void Abstract(char *filename)
{
ifstream file;
file.open(filename);
string s;
string t="Abstract: ";
ofstream fileOutput;
fileOutput.open("2.txt", ios::app);
while(getline(file, s))
{
fileOutput << t+s << endl;
}
file.close();
}
//在标题前面加上 Title:
void Title(char *filename)
{
ifstream file;
file.open(filename);
string s;
string t="Title: ";
ofstream fileOutput;
fileOutput.open("1.txt", ios::app);
while(getline(file, s))
{
fileOutput << t+s << endl;
}
file.close();
}
//按格式输出
void Title(char *filename)
{
ifstream file;
file.open(filename);
string s;
int count= 979;
for(int i=0;i<count;i++)
{
getline(file, s);
title[i]=s;
}
file.close();
}
void Abstract(char *filename)
{
ifstream file;
file.open(filename);
string s;
int count= 979;
for(int i=0;i<count;i++)
{
getline(file, s);
abstract[i]=s;
}
file.close();
}
int main()
{
ofstream fileOutput;
fileOutput.open("result.txt", ios::app);
char filename1[105]= "1.txt";
char filename2[105]= "2.txt";
Title(filename1);
Abstract(filename2);
int count= 979;
for(int i=0;i<count;i++)
{
fileOutput<<i<<endl;
fileOutput<<title[i]<<endl;
fileOutput<<abstract[i]<<endl;
fileOutput<<endl<<endl;
}
return 0;
}
最终结果如下

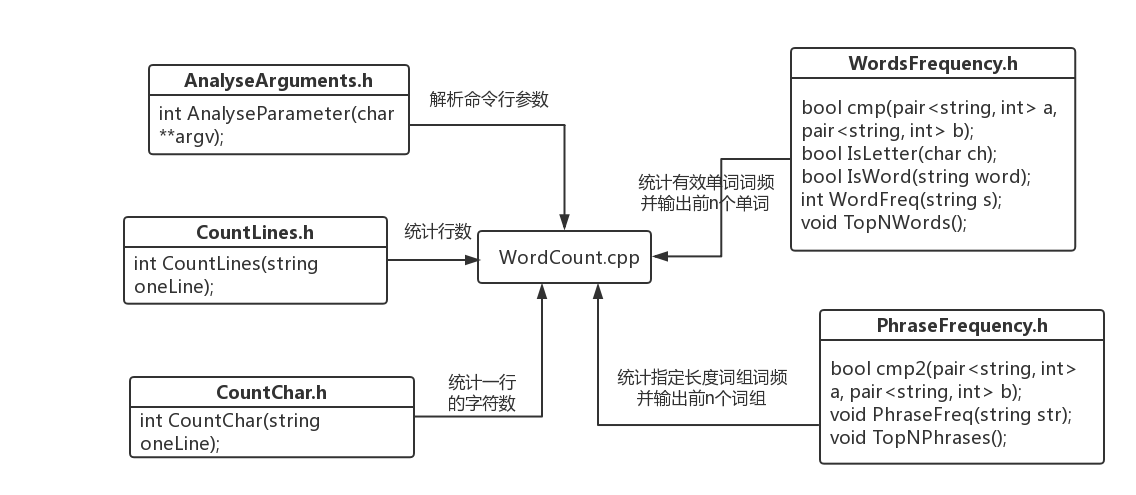
2、代码组织与内部实现设计(类图)
3、说明算法的关键与关键实现部分流程图

五、关键代码解释
1、贴出你认为重要的/有价值的代码片段,并解释
以下是主函数的部分代码,用来处理输入文件
int main()
{
ifstream fin(inputFile);
string str;
while (getline(fin, str)) { //按行读取文件内容
inTitle = 0;
if (str.substr(0, 7) == "Title: ") {//"Title: "不计算在内
str = str.substr(7, str.length());
inTitle = 1;
}
else if (str.substr(0, 10) == "Abstract: ") {//"Abstract: "不计算在内
str = str.substr(10, str.length());
}
else if (IsNum(str[0]) || str==""){ //不统计论文编号和空行
continue;
}
if (countPhrase) {//countPhrase=1,启用词组词频统计
PhraseFreq(str);
}
characters += CountChar(str);
words += WordFreq(str);
lines += CountLines(str);
}
fin.close();
return 0;
}
统计一行中的词组词频
void PhraseFreq(string s)
{
string word = "";
string phrase = "";
int cnt = 0, secWord;
int len = s.length();
for (int i = 0; i < len; i++) {
if (s[i] >= 'A' && s[i] <= 'Z') {
s[i] += 32; //大写转小写
}
//遍历到最后一个字符,和遇到分隔符一样,要判断当前词组是否符合条件
if ((s[i] >= '0'&&s[i] <= '9') || (s[i] >= 'a'&&s[i] <= 'z')) {
word += s[i];
if (i == len - 1 && IsWord(word)) {
cnt++;
if (cnt == 1) {
phrase += word;
}
else {
phrase += " ";
phrase += word;
}
if (cnt == 2) {
secWord = i - word.size()-1;
}
if (cnt == phraseLen) {
if (weightOnWord && inTitle) {
mapPhrase[phrase] += 10;
}
else
mapPhrase[phrase]++;
i = secWord;
}
}
}
else if(word!=""){ //遇到分隔符且word不为空
if (IsWord(word)) { //如果是有效单词
cnt++;
//单词加到phrase中
if (cnt == 1) {
phrase += word;
}
else {
phrase += " ";
phrase += word;
}
if (cnt == 2) { //记录词组第二个单词的位置
secWord = i - word.size()-1;
}
if (cnt == phraseLen) {
if (weightOnWord && inTitle) { //若启用权重统计并且是属于title的单词
mapPhrase[phrase]+=10; //权重为10
}
else
mapPhrase[phrase]++;
i = secWord; //回到第二个单词首
cnt = 0; //当前单词数清零
phrase = ""; //phrase清零
}
}
else {
cnt = 0;
phrase = "";
}
word = "";
}
}
}
六、性能分析与改进
展示性能分析图和程序中消耗最大的函数
使用爬取的论文进行测试,输入命令行参数为WordCount.exe -i paper.txt -o result.txt -w 1 -m 3 -n 10,运行时间为18.716s,输出结果如下:

性能报告截图:

从中可以看出,消耗最大的函数是TopNPhrase(),占据总运行时间的49.1%。

七、单元测试
附上检测代码:
TEST_METHOD(TestMethod1)
{
string name;
name="chartest1.txt";
int chars = CountChar(name);
Assert::AreEqual(chars, 40);
}
TEST_METHOD(TestMethod2)
{
string name;
name = "chartest2.txt";
int chars = CountChar(name);
Assert::AreEqual(chars, 74);
}
TEST_METHOD(TestMethod3)
{
string name;
name = "wordtest1.txt";
ifstream fin(name);
int words = 0;
string str;
while (getline(fin, str)) {
inTitle = 0;
if (str.substr(0, 7) == "Title: ") {
str = str.substr(7, str.length());
inTitle = 1;
}
else if (str.substr(0, 10) == "Abstract: ") {
str = str.substr(10, str.length());
}
else if (IsNum(str[0]) || str == "") { //ignore paper number and empty lines
continue;
}
if (countPhrase) {
PhraseFreq(str);
}
words += WordFreq(str);
}
fin.close();
Assert::AreEqual(words, 5);
}
TEST_METHOD(TestMethod4)
{
string name;
name = "wordtest2.txt";
ifstream fin(name);
int words = 0;
string str;
while (getline(fin, str)) {
inTitle = 0;
if (str.substr(0, 7) == "Title: ") {
str = str.substr(7, str.length());
inTitle = 1;
}
else if (str.substr(0, 10) == "Abstract: ") {
str = str.substr(10, str.length());
}
else if (IsNum(str[0]) || str == "") { //ignore paper number and empty lines
continue;
}
if (countPhrase) {
PhraseFreq(str);
}
words += WordFreq(str);
}
fin.close();
Assert::AreEqual(words, 9);
}
TEST_METHOD(TestMethod5)
{
string name;
name = "linetest1.txt";
ifstream fin(name);
int lines = 0;
string str;
while (getline(fin, str)) {
inTitle = 0;
if (str.substr(0, 7) == "Title: ") {
str = str.substr(7, str.length());
inTitle = 1;
}
else if (str.substr(0, 10) == "Abstract: ") {
str = str.substr(10, str.length());
}
else if (IsNum(str[0]) || str == "") { //ignore paper number and empty lines
continue;
}
if (countPhrase) {
PhraseFreq(str);
}
lines += CountLines(str);
}
fin.close();
Assert::AreEqual(lines, 5);
}
TEST_METHOD(TestMethod6)
{
string name;
name = "linetest2.txt";
ifstream fin(name);
int lines = 0;
string str;
while (getline(fin, str)) {
inTitle = 0;
if (str.substr(0, 7) == "Title: ") {
str = str.substr(7, str.length());
inTitle = 1;
}
else if (str.substr(0, 10) == "Abstract: ") {
str = str.substr(10, str.length());
}
else if (IsNum(str[0]) || str == "") { //ignore paper number and empty lines
continue;
}
if (countPhrase) {
PhraseFreq(str);
}
lines += CountLines(str);
}
fin.close();
Assert::AreEqual(lines, 5);
}
TEST_METHOD(TestMethod7)
{
string name;
name = "characterstest.txt";
ifstream fin(name);
int characters = 0;
string str;
while (getline(fin, str)) {
inTitle = 0;
if (str.substr(0, 7) == "Title: ") {
str = str.substr(7, str.length());
inTitle = 1;
}
else if (str.substr(0, 10) == "Abstract: ") {
str = str.substr(10, str.length());
}
else if (IsNum(str[0]) || str == "") { //ignore paper number and empty lines
continue;
}
if (countPhrase) {
PhraseFreq(str);
}
characters += CountChar(str);
}
fin.close();
Assert::AreEqual(characters, 5);
}
TEST_METHOD(TestMethod8)
{
string name;
name = "phrasetest1.txt";
ifstream fin(name);
string str;
while (getline(fin, str)) {
inTitle = 0;
if (countPhrase) {
PhraseFreq(str);
}
}
fin.close();
if (countPhrase) { //phrase statistics
TopNPhrases();
}
else { //word statistics
TopNWords();
}
for (auto x : mapPhrase) {
vecPhrase.push_back(x);
}
sort(vecPhrase.begin(), vecPhrase.end(), cmp2);
Assert::AreEqual(vecPhrase[1].first, string("monday tuesday wednesday"));
Assert::AreEqual(vecPhrase[1].second, 11);
}
TEST_METHOD(TestMethod9)
{
string name;
name = "phrasetest2.txt";
ifstream fin(name);
string str;
while (getline(fin, str)) {
inTitle = 0;
if (countPhrase) {
PhraseFreq(str);
}
}
fin.close();
if (countPhrase) { //phrase statistics
TopNPhrases();
}
else { //word statistics
TopNWords();
}
for (auto x : mapPhrase) {
vecPhrase.push_back(x);
}
sort(vecPhrase.begin(), vecPhrase.end(), cmp2);
Assert::AreEqual(vecPhrase[1].first, string("convolutional neural networks"));
Assert::AreEqual(vecPhrase[1].second, 196);
}
八、贴出Github的代码签入记录

九、遇到的代码模块异常或结对困难及解决方法
困难:
- 由于事先没有确定接口,后期代码合并困难
- 在写代码的过程中两个人都没有注释代码的习惯,使得两个人都看不懂对方的代码。一定要改!!!
- 结对过程中联系很少,经常不知道对方的进度。
解决方法:
- 分工时接口一定一定要事先讲清楚
- 养成写注释的习惯
- 要经常沟通,知道对方的进度
十、评价你的队友
值得学习的地方:
做事认真负责,也很积极,比较有时间观念,快要到截止时间时会提醒我。
需要改进的地方 :
合作过程沟通较少,彼此工作比较分离。
十一、学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 400 | 400 | 30 | 30 | 学会写单元测试和用vs进行性能分析 |
| 2 | 0 | 400 | 20 | 50 | 学会了墨刀这个原型设计软件的使用;学会了如何与队友沟通与合作 |
| 3 | 344 | 744 | 16 | 66 | 进一步掌握git的使用 |

