
序列构成的数组
序列类型的划分:
第一种划分:
- 容器序列:可以存放不同类型的数据,存放的是引用
- list、tuple、collections.deque
- 扁平序列:只能存放一种类型的数据,存放的是值
- str、bytes、bytearray、memoryview、array.array
第二种划分:
- 可变序列:内容可以改变
- list、bytearray、array.array、collections.deque、memoryview
- 不可变序列
- tuple、str、bytes
列表推导同filter和map的比较
- filter和map合起来能做的事情,列表推导也能做,而且还不需要借助难以理解和阅读的lambda表达式
from collections import abc s = 'abcdefg' # 列表推导 l1 = [ord(x) for x in s if ord(x)>99] print(l1) # map返回的是一个map object,它是一个Iterator map_object = map(ord, s) print(isinstance(map_object,abc.Iterator)) # map和filter结合 l2 = list(filter(lambda x: x > 99, map_object)) print(l2)
输出:
[100, 101, 102, 103]
True
[100, 101, 102, 103]
生成器表达式
生成器表达式背后遵循了迭代器协议,可以逐个地产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。
生成器表达式语法和列表推导差不多,只不过把方括号换成圆括号而已
import array symbols = 'aeiou' # 用生成器构造tuple t = tuple(ord(x) for x in symbols) print(t) print('-' * 100) # 用生成器构造array a = array.array('I',(ord(x) for x in symbols)) print(a) print('-' * 100) # 生成器产生笛卡尔积 colors = ['black','white'] size = ['S','M','L'] for tshirt in ('{0} {1}'.format(c,s) for c in colors for s in size): print(tshirt)
输出:
(97, 101, 105, 111, 117)
----------------------------------------------------------------------------------------------------
array('I', [97, 101, 105, 111, 117])
----------------------------------------------------------------------------------------------------
black S
black M
black L
white S
white M
white L
元组拆包
在一行语句内把元组分别赋值给多个变量
import os # 元组拆包常规操作 person = ('Alice',20) name,age = person print('name is',name,'age is',age) print('-' * 100) # 使用“_”占位符 _,filename = os.path.split("D\Program Files\Test.doc") print('filename =',filename) print('-' * 100) # 使用*占位符 address = ('China', 'ZheJiang', 'HangZhou',310000) _,province,*other,zipcode = address print('province =',province,', zipcode = ',zipcode) print('-' * 100) # 嵌套拆包 numbers = (('one',1),('two',2),('three',3)) for (name, value) in numbers: print(name,'=',value)
输出:
name is Alice age is 20
----------------------------------------------------------------------------------------------------
filename = Test.doc
----------------------------------------------------------------------------------------------------
province = ZheJiang , zipcode = 310000
----------------------------------------------------------------------------------------------------
one = 1
two = 2
three = 3
具名元组
collections.namedtuple是一个工厂函数,它可以用来构建一个带字段名的元组,这个带字段名的元组的行为模式就像一个类
from collections import namedtuple,OrderedDict # 使用namedtuple定义一个Country类 Country = namedtuple('Country','name_and_abbr area population') china = Country(('China','CN'),960,13) print(china) print('-' * 20,'用.号访问Country类的属性','-' * 20) # 用.号访问Country类的属性 print('china.population=',china.population) name,abbr = china.name_and_abbr print('name='+name,'abbr='+abbr) print('-' * 20,'用[]访问Country类的属性','-' * 20) # 也可以用[]访问Country类的属性 print('china[0]=',china[0]) print('-' * 20,'Country类的_fileds方法','-' * 20) # Country类的_fileds方法返回它的字段 print('Country._filds =',Country._fields) print('-' * 20,'Country类的_make方法','-' * 20) # Country类的_make方法构造一个实例 japan1 = Country._make((('Japan','JP'),97.8,1.26)) print(japan1) # 和调用构造函数效果相同: japan2 =Country(*(('Japan','JP'),97.8,1.26)) print(japan2) print('-' * 20,'Country类的_asdict方法','-' * 20) # Country类的_asdict方法把具名元组以collections.OrderedDict的形式返回 print('china._asdict() is OrderedDict:',isinstance(china._asdict(),OrderedDict)) for name,value in china._asdict().items(): print(name,'=',value)
输出:
Country(name_and_abbr=('China', 'CN'), area=960, population=13)
-------------------- 用.号访问Country类的属性 --------------------
china.population= 13
name=China abbr=CN
-------------------- 用[]访问Country类的属性 --------------------
china[0]= ('China', 'CN')
-------------------- Country类的_fileds方法 --------------------
Country._filds = ('name_and_abbr', 'area', 'population')
-------------------- Country类的_make方法 --------------------
Country(name_and_abbr=('Japan', 'JP'), area=97.8, population=1.26)
Country(name_and_abbr=('Japan', 'JP'), area=97.8, population=1.26)
-------------------- Country类的_asdict方法 --------------------
china._asdict() is OrderedDict: True
name_and_abbr = ('China', 'CN')
area = 960
population = 13
切片
在切片和区间操作里不包含区间范围的最后一个元素
l = [10,20,30,40,50,60] print('l[:2] =',l[:2]) print('l[2:] =',l[2:])
输出:
l[:2] = [10, 20]
l[2:] = [30, 40, 50, 60]
使用slice对切片进行命名
people = '''person1 20 175 person2 30 163 person3 25 182 ''' name = slice(0,7) age = slice(8,10) height = slice(11,14) for item in people.split("\n"): print('name:',item[name]) print('age:',item[age]) print('height:',item[height]) print('-' * 100)
输出:
name: person1
age: 20
height: 175
----------------------------------------------------------------------------------------------------
name: person2
age: 30
height: 163
----------------------------------------------------------------------------------------------------
name: person3
age: 25
height: 182
----------------------------------------------------------------------------------------------------
给切片赋值
如果把切片放在赋值语句的左边,或把它作为del操作的对象,我们就可以对序列进行嫁接、切除或就地修改操作
l = list(range(1,11)) print('l:',l) # 把l的第9和10项替换成100 print('-' * 20,'把l的第9和10项替换成100','-' * 20) l[8:10] = [100] print(l) print('-' * 20,'把l的第1,3,5,7,9项替换成95,96,97,98,99','-' * 20) # 把l的第1,3,5,7,9项替换成95,96,97,98,99 l[::2] = [95,96,97,98,99] print(l) # 删除l的第2,4,6,8项 print('-' * 20,'删除l的第2,4,6,8项','-' * 20) del l[1::2] print(l)
输出:
l: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
-------------------- 把l的第9和10项替换成100 --------------------
[1, 2, 3, 4, 5, 6, 7, 8, 100]
-------------------- 把l的第1,3,5,7,9项替换成95,96,97,98,99 --------------------
[95, 2, 96, 4, 97, 6, 98, 8, 99]
-------------------- 删除l的第2,4,6,8项 --------------------
[95, 96, 97, 98, 99]
对序列使用+和*
+和*都是对序列进行拼接,在拼接的过程中,两个被操作的序列都不会被修改,Python会建立一个包含同样类型数据的序列来作为拼接的结果
*操作把一个序列复制几份然后拼接起来,但这里使用浅copy,对于嵌套结构需要当心
def print_split(s): print('-' * 20, s, '-' * 20) # 拼接使用浅copy # 使用基本类型没有影响 print_split('使用基本类型没有影响') l1 = [1] print('id of l1[0]:', id(l1[0])) # 对l1中的元素进行复制,然后拼接 # l是由两个整数构成的list l = l1 * 2 print(l) for item in l: print(id(item)) # 不会影响l[1] l[0]=2 print(l) # 使用对象有副作用 print_split('使用对象有副作用') l2=[['_']] print('id of l2[0]:',id(l2[0])) # 对l2中的元素进行复制,然后拼接 # l是由两个list构成的list l = l2*2 for item in l: print(id(item)) # 会影响l[1][0] l[0][0]='a' print(l)
输出:
-------------------- 使用基本类型没有影响 --------------------
id of l1[0]: 140734998434848
[1, 1]
140734998434848
140734998434848
[2, 1]
-------------------- 使用对象有副作用 --------------------
id of l2[0]: 1171703476616
1171703476616
1171703476616
[['a'], ['a']]
建立嵌套列表的一个例子
def print_split(s): print('-' * 20, s, '-' * 20) # 建立由列表组成的列表 print_split('建立由列表组成的列表') # 错误的建立方式:会把相同列表复制三次 print_split('错误的建立方式:会把相同列表复制三次') board = [['_'] * 3] * 3 print(board) board[0][0]='a' print(board) # 正确的建立嵌套列表方式: print_split('正确的建立嵌套列表方式') board = [['_']*3 for i in range(3)] print(board) board[0][0]='a' print(board)
输出:
-------------------- 建立由列表组成的列表 --------------------
-------------------- 错误的建立方式:会把相同列表复制三次 --------------------
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
[['a', '_', '_'], ['a', '_', '_'], ['a', '_', '_']]
-------------------- 正确的建立嵌套列表方式 --------------------
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
[['a', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
list.sort方法和内置函数sorted
不同点:
list.sort方法就地排序列表,返回None
sorted方法返回一个新建的排好序的列表
相同点:
接受参数相同
reverse:如果被设定为True,序列以降序输出
key:一个只有一个参数的函数,被用在序列里的每一个元素上,所产生的结果将是排序算法依赖的对比关键字
fruits = ['grape','raspberry','apple','banana'] print('sorted(fruits):',sorted(fruits)) # 原列表并未被改变 print('fruits:',fruits) print('sorted(fruits,reverse=True):',sorted(fruits,reverse=True)) print('sorted(fruits,key=len):',sorted(fruits,key=len)) print('list.sort(fruits):',list.sort(fruits)) # 原列表被改变了 print('fruits:',fruits)
输出:
sorted(fruits): ['apple', 'banana', 'grape', 'raspberry']
fruits: ['grape', 'raspberry', 'apple', 'banana']
sorted(fruits,reverse=True): ['raspberry', 'grape', 'banana', 'apple']
sorted(fruits,key=len): ['grape', 'apple', 'banana', 'raspberry']
list.sort(fruits): None
fruits: ['apple', 'banana', 'grape', 'raspberry']
bisect管理已排序的序列
bisect模块包含两个主要函数:bisect和insort,它们都利用二分查找算法来在有序序列中查找或插入元素
bisect函数其实是bisect_right函数的别名,后者还有一个姊妹函数叫bisect_left,它们的区别在于,bisect_left返回的插入位置是序列中所有与插入元素相同的元素的前面,而bisect_right则是后面
与bisect相似,insort有一个变体叫insort_left,差异与bisect和bisect_left相似
from random import randint from bisect import bisect,insort l = [randint(0,20) for i in range(10)] list.sort(l) print('l:',l) x = randint(0,20) print('x:',x) # 查找插入位置 print('position to insert x:',bisect(l,x)) # 进行插入 insort(l,x) print('l:',l)
输出:(输出随机改变)
l: [7, 8, 9, 12, 13, 13, 14, 17, 18, 18]
x: 2
position to insert x: 0
l: [2, 7, 8, 9, 12, 13, 13, 14, 17, 18, 18]
from bisect import bisect,insort def grade(score,breakpoints=[60,70,80,90],grades='FDCBA'): pos = bisect(breakpoints,score) return grades[pos] print([grade(score) for score in [33,99,77,70,89,90,100]])
输出:
['F', 'A', 'C', 'C', 'B', 'A', 'A']
数组
如果我们需要一个只包含数字的列表,那么array.array比list更高效
数组支持所有跟可变序列有关的方法,比如.pop .insert ,extend
另外,数组还提供从文件读取和存入文件的更快的方法:.fromfile 和 .tofile
数组第一个参数是数组存放的元素类型
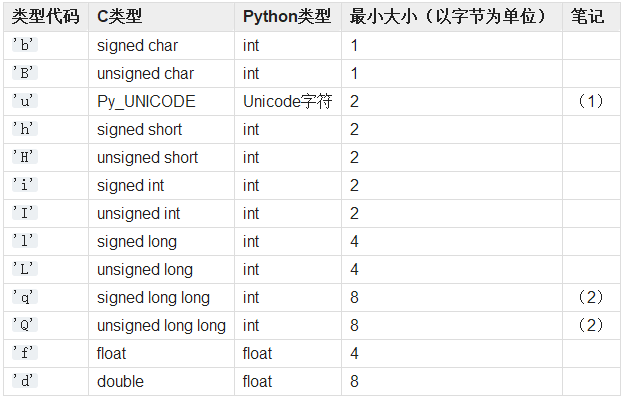
from array import array from random import random # 建立一个double构成的数组,一共10^6个元素 arr = array('d',(random() for i in range(10**6))) # 把数组放进文件 with open('floats.bin','wb') as fp: arr.tofile(fp) # 打印数组最后一个元素 print(arr[-1]) # 新建一个double数组 floats = array('d') fp = open('floats.bin','rb') # 从文件读取数据,构造数组 floats.fromfile(fp,10**6) # 打印数组最后一个元素 print(floats[-1])
输出(随机输出):
0.608500026173036
0.608500026173036
内存视图
memoryview让用户在不复制内容的情况下操作同一个数组的不同切片
能用不同的方式读写同一块内存数据,而且内容字节不会随意移动
from array import array # 定义一个以两个字节带符号整数构成的数组 num = array('h',[-2,-1,0,1,2]) # 用array构造memoryview mv2 = memoryview(num) # memoryview的长度是根据其解析类型来的 print('len(mv):',len(mv2)) # 对元素的解析也是根据其解析类型来的 print('mv[0]:',mv2[0]) # 换一种解析类型,用一个字节来解析 mv1 = mv2.cast('B') # 打印用一个字节来解析的内容 print(mv1.tolist()) # 把第6个字节替换成00000100,注意,每个字的高低位字节是倒过来显示的 mv1[5] = 4 # 会影响到原先的memoryview print(mv2.tolist())
输出:
len(mv): 5
mv[0]: -2
[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
[-2, -1, 1024, 1, 2]
双端队列
删除列表的第一个元素之类的操作是很耗时的
collections.deque类是一个线程安全,可以快速从两端添加或者删除元素的数据类型
from collections import deque # 定义一个长度为10的双端队列 # 用0-9填充 dq = deque(range(10),maxlen=10) print('dq:',dq) # rotate参数是正数,右放到左; dq.rotate(3) print('dq.rotate(3):',dq) # rotate参数是负数,左放到右 dq.rotate(-3) print('dq.rotate(-3):',dq) # deque可以在两端添加元素,但另一端的元素会被挤出 dq.append(10) print('deque.append(10):',dq) dq.appendleft(0) print('dq.appendleft(0):',dq) # deque也可以在两端添加可迭代对象 dq.extend([11,12]) print('dq.extend([11,12]):',dq) # 注意,deque是一个一个添加元素的,所以在左端添加可迭代对象时,顺序是倒过来的 dq.extendleft([1,0]) print('dq.extendleft([1,0]):',dq) # deque可以在两端删除元素,但不能带参数 a = dq.pop() print('dq.pop():',a) print('dq after pop:',dq) a = dq.popleft() print('dq.popleft():',a) print('dq after pop:',dq)
输出:
dq: deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.rotate(3): deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
dq.rotate(-3): deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
deque.append(10): deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], maxlen=10)
dq.appendleft(0): deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.extend([11,12]): deque([2, 3, 4, 5, 6, 7, 8, 9, 11, 12], maxlen=10)
dq.extendleft([1,0]): deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.pop(): 9
dq after pop: deque([0, 1, 2, 3, 4, 5, 6, 7, 8], maxlen=10)
dq.popleft(): 0
dq after pop: deque([1, 2, 3, 4, 5, 6, 7, 8], maxlen=10)
