

现在做的项目是个大数据报表系统,刚开始的时候,负责做Java方面的接口(项目前端为独立的Java web 系统,后端也是Java web的系统,前后端系统通过接口传输数据),后来领导觉得大家需要多元化发展,要全面发展。就让大数据组的同事,给我们报表组的同事培训了下大数据方面的知识,主要是hive的。就这样就开启了新的篇章,虽然比较腹议,自此大数据离线数据计算的工作就交给我们报表组了,我们还是欣然的接受了,我自己还是相当想向大数据方面发展的。
自此,开启了大数据开发的篇章。
---------------沉默的分割线-----------------------------
学习Hadoop开发,当然少不了搭建Hadoop集群了。
最方便的搭建环境,当然是在自己电脑上安装虚拟机(土豪请出门右转)
下面进入正题。
本着最新、最快、最强的原则,我选择了centos7,jdk8,hadoop3 作为我测试的平台。
不解释,上下载链接:
centos7 : https://www.centos.org/download/
centos 各个版本简介:
DVD ISO : 标准版(一般选择)
Everything ISO : 对标准版进行补充,集成所有软件
Minimal ISO : 最小版(高手选择)
jdk8 : http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
进oracle的官网下载就是了
hadoop3 :http://hadoop.apache.org/releases.html
具体选择如下:
centos 7 DVD,选一个镜像下载即可
jdk 很早就有使用过了,没有下在,使用的版本是 : jdk-8u91-linux-x64
hadoop版本: 3.0.1 (安装的时候,3.1.0 还未出来)
系统镜像下载完成后即可安装虚拟机。
---------------------以下为正文--------------------------
vmware:
1、创建虚拟机
2、选择典型安装,下一步
3、选择第二项 Installer disc image file(iso) : 选择下载的系统镜像,下一步
4、命名虚拟机,这里以虚拟机将要使用的主机名命名,选择安装路径,下一步
说明:我的C盘是个256G的ssd,所以虚拟机直接安装在了C盘,请使具体情况选择安装位置,安装后可以移动。
5、配置虚拟机硬盘大小,文件是否使用多文件。选择20G,单文件存储,下一步
20G的硬盘大小,开发足够使用,要是需要很大空间,视具体情况调整。20G足够,大点也可以。
我的主节点给了40G,其他节点都是20G。
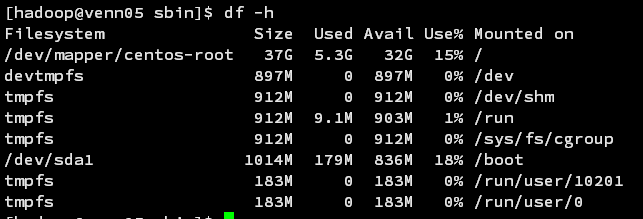
如下图:安装完成后
40G的还有32G剩余空间
20G的还有13G剩余空间
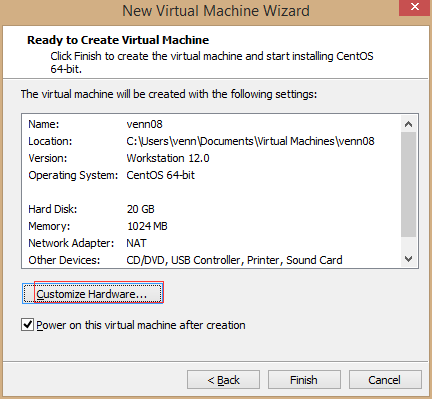
6、点击“customize hardware..”,修改硬盘配置,点击完成。
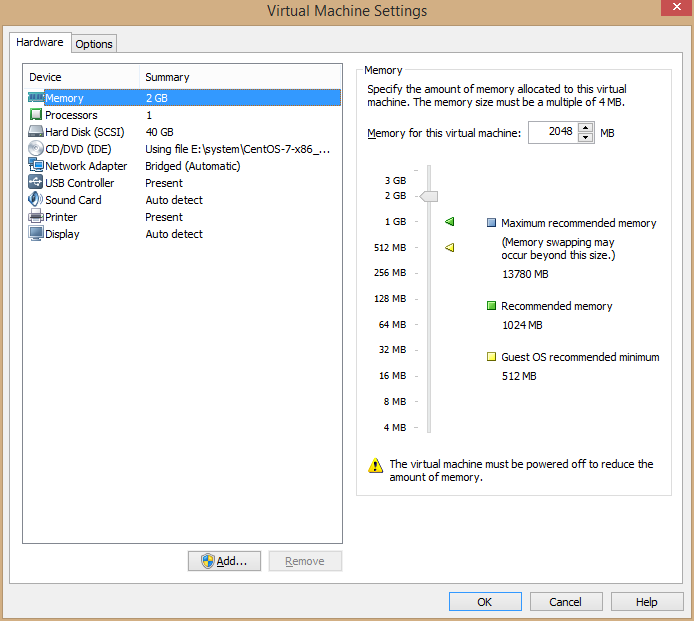
修改内存:选择合适的内存(1G足够,越多越好,虚拟机内存加起来不能超过物理机的一半),我的内存比较大,主节点选的2G,其他节点都是1G
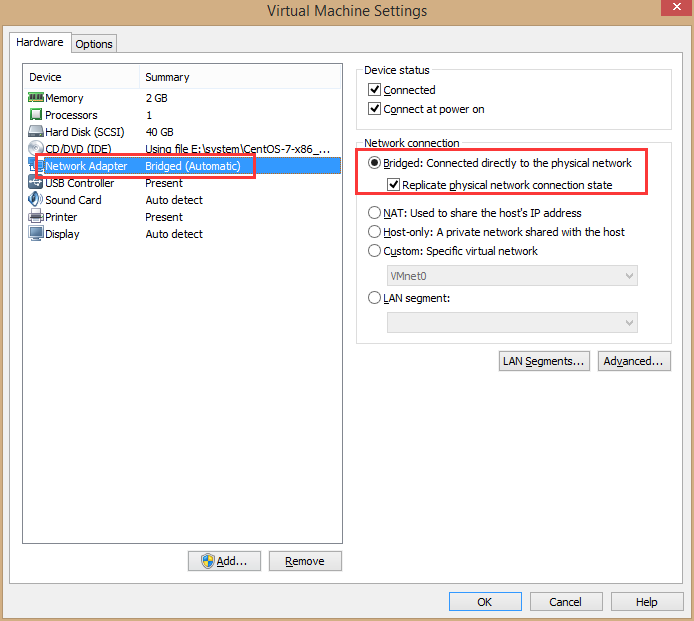
修改网络:选择桥接,复制物理连接
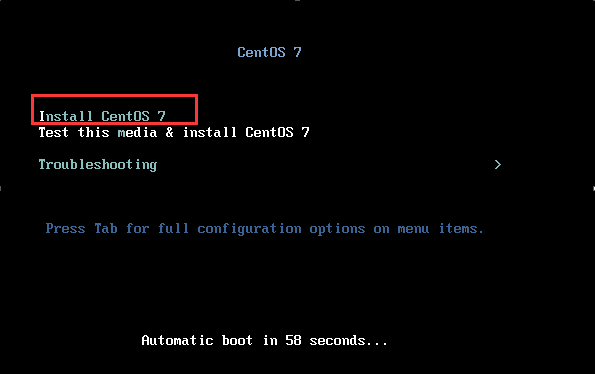
7,选择 “Install CentOS 7” 开始安装。
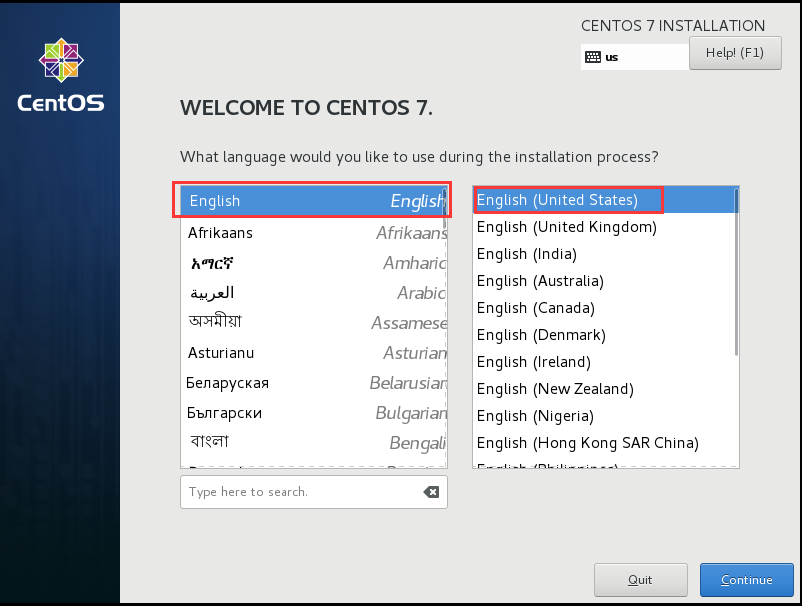
8、选择语言 "English " "English (United States)" ,点击 “Continue”
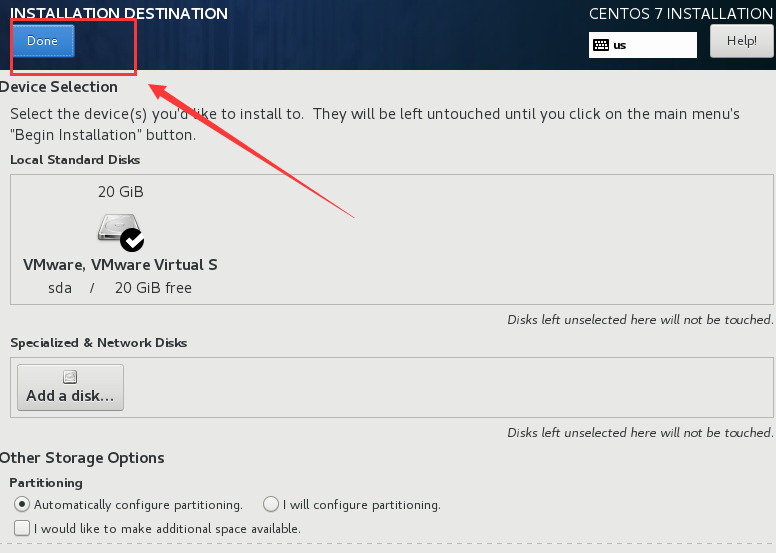
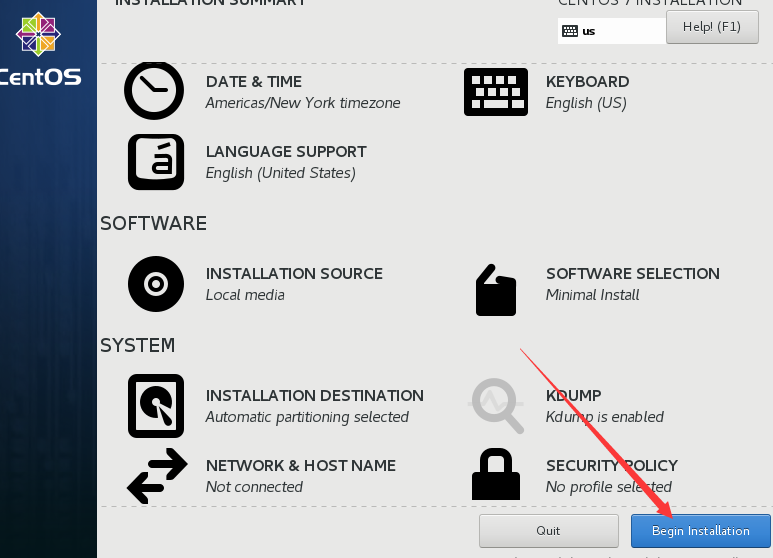
9、选择硬盘分区,保持默认,点击 “Done” ,返回前页,点击右下角 “Begin Installation” ,开始安装

10、设置root用户密码,密码简单,点击两次“Done” 直接设置。坐等系统安装完成(我的机器几分钟就完成了)。

11、安装完成后,点击右下角“Reboot”,重启电脑。
12、使用root 登录系统
13、修改主机名:
vi /etc/hostname
删除文件里面的内容,直接数据主机名
结果如下:

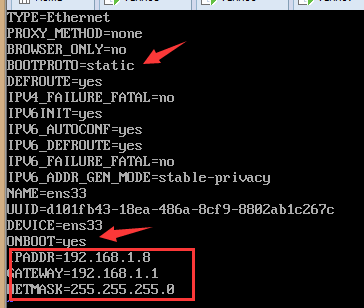
14、修改IP为静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33 文件后面可能不一样
修改前,修改后如下,ip视具体情况定
我的主机ip地址为:192.168.1.107
venn05虚拟机ip地址为: 192.168.1.5
venn06虚拟机ip地址为: 192.168.1.6
依次类推
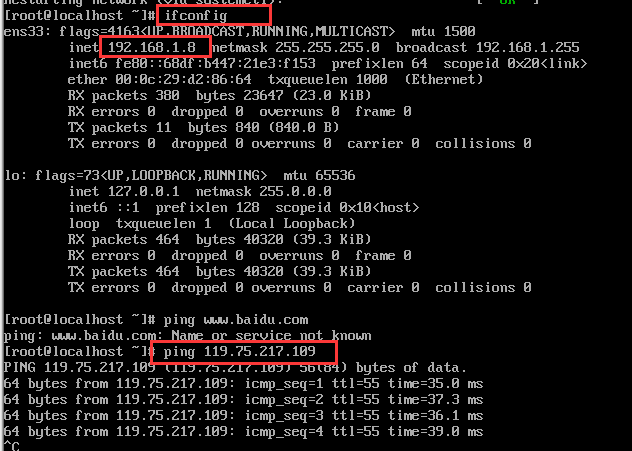
15、重启网络,查看ip,ping 百度(ip: 119.75.217.109)
service network restart
16、关闭防火墙
停止firewall : systemctl stop firewalld.service
禁止firewall开机启动 : systemctl disable firewalld.service
注:centos 使用 firewall 作为默认防火墙,不是iptables
reboot 重启电脑,安装完成,其他节点虚拟机安装相同。
至此虚拟机安装完成。
集群搭建完成后,我发现vmware 有个“clone” 的功能,可以克隆虚拟机,不用重复安装。
1、克隆,关闭虚拟机,右键虚拟机,选择“manage”,选择“clone”,

2、下一步
3、下一步

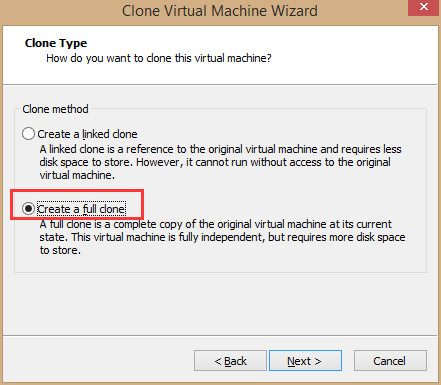
4、选择“create a full clone” 下一步
5、命名虚拟机,修改安装位置,下一步
6、点击“close” ,完成克隆。
克隆完成的虚拟机注意修改主机名和ip地址。

