

软件工程实践2018第四次作业——结对作业2
博客链接:博客地址
github项目地址:结对作业2
具体分工:
爬虫部分:王彬
基本功能部分:王彬
附加题部分:葛亮
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 1560 | 1520 |
| · Analysis | · 需求分析 (包括学习新技术) | 180 | 300 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 30 | 50 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 120 | 180 |
| · Coding | · 具体编码 | 600 | 480 |
| · Code Review | · 代码复审 | 120 | 180 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| Reporting | 报告 | 70 | 80 |
| · Test Repor | · 测试报告 | 30 | 50 |
| · Size Measurement | · 计算工作量 | 20 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 1650 | 1620 |
解题思路
爬虫使用:
- 本次作业需要使用网络爬虫技术,在一开始进行需求评估的时候,我就认为用C++实现爬虫太过繁琐,因为C++相对于python等脚本语言来说抽象程度还不够高,从套接字编程到网页爬取都需要亲力亲为。而且网络上关于C++爬虫的资料也不多,所以我就选用了相对更方便的python来完成任务,通过对CVPR网站的分析,我发现需要爬取的内容格式工整,且整个网站也没有反爬虫措施,所以我直接使用python的urllib库和正则表达式完成了论文列表的抓取
代码组织与内部实现设计
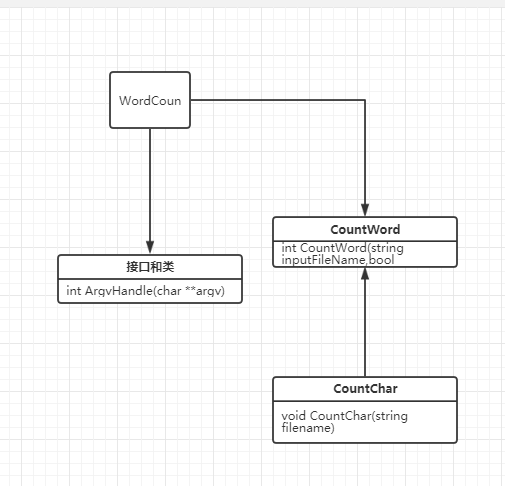
- 代码由四个部分组成:
-
WordCount:程序的入口,负责调用其他函数
-
argHandle: 负责对传入参数的合法性进行判别
-
CountChar:负责对传入文本进行字符数统计
-
CountWord:负责对文本进行单词处理
-
类图
-
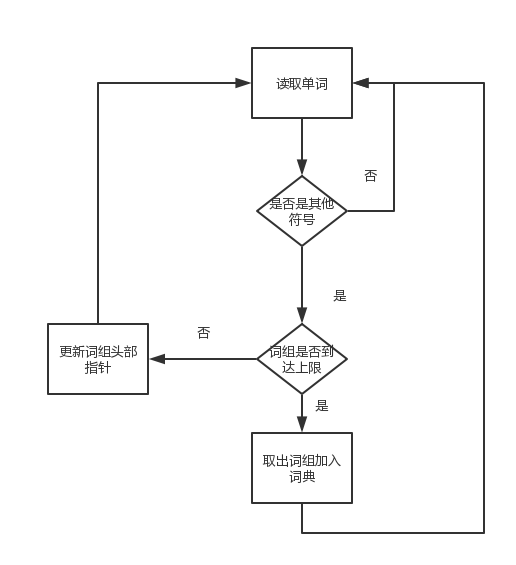
说明算法的关键与关键实现部分流程图
-
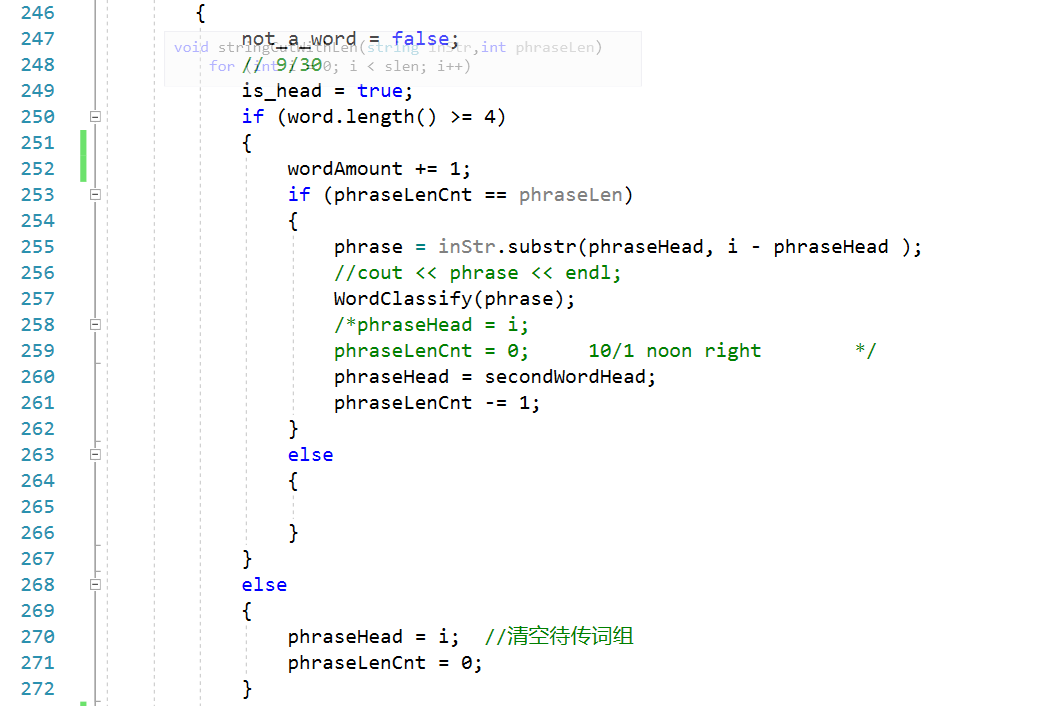
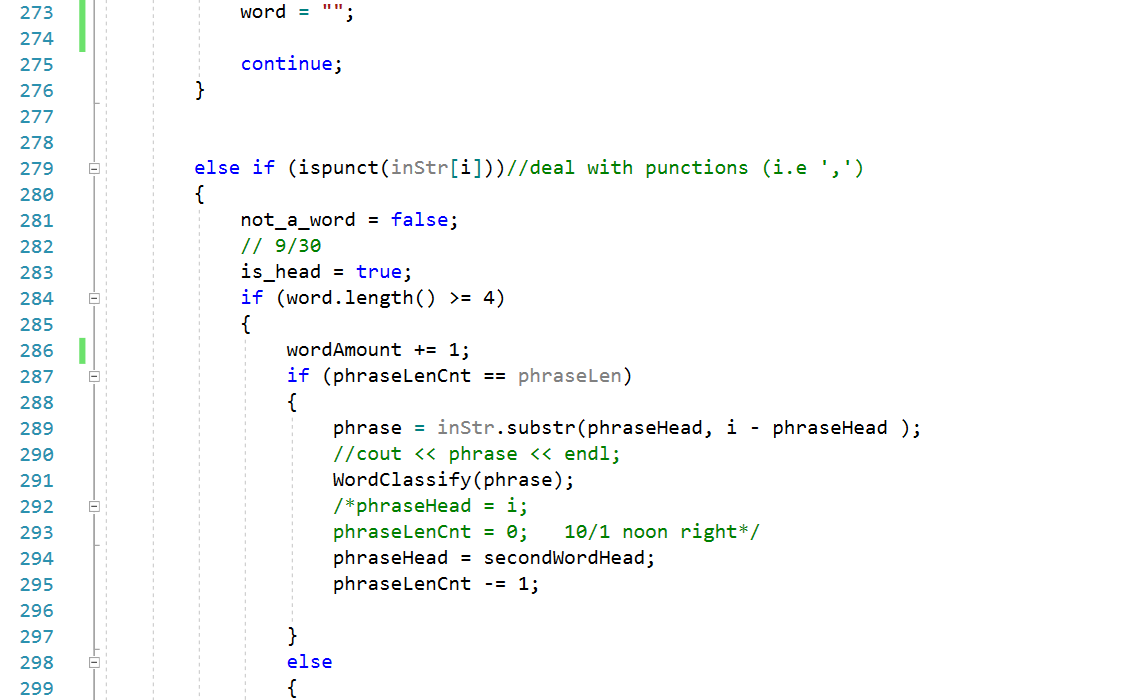
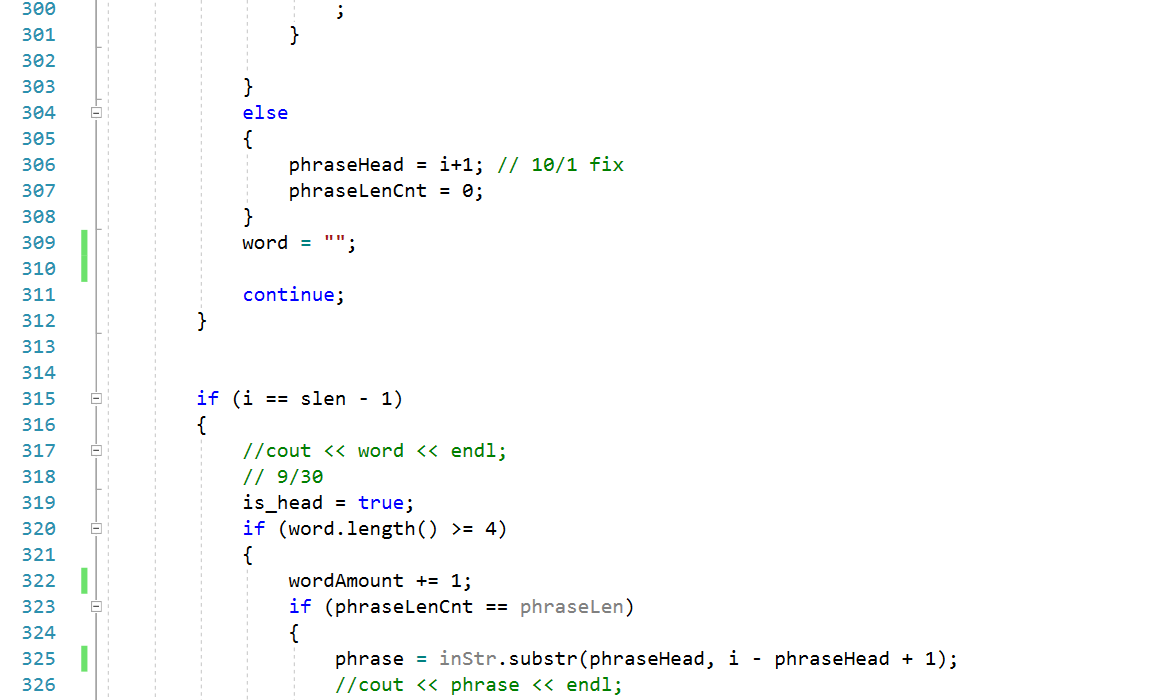
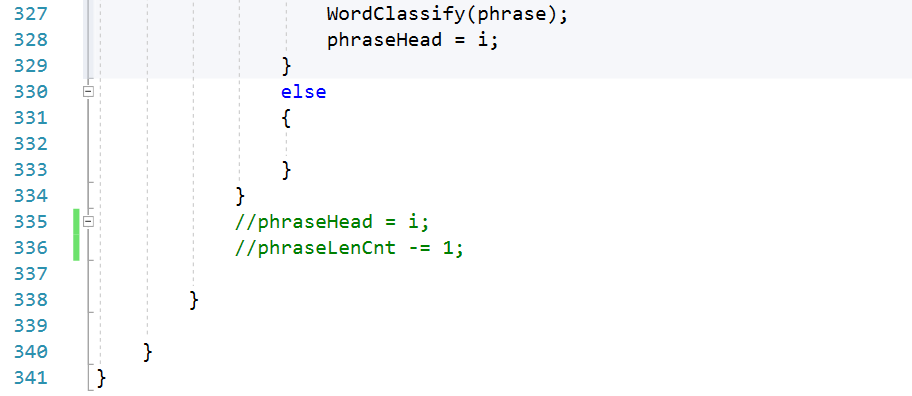
因为这次的作业是在上一次结对作业的基础上进行的,所以问题的核心难点依旧是在单词(词组)的划分上,针对指定长度词组,我使用的方法的基本理念是一方面使用作业一中的划词程序将符合条件的单个单词取出,另一方面不断维护词组的开始和结束两个哨兵节点,这样每当规定长度的词组被取出,就可根据词组头尾两个哨兵节点取出整个字符串的字串(即所需词组)
-
在爬出的CVPR顶会论文列表中,TITLE和ABSTRACT之后的内容都是单独一行呈现的,所以我的划词程序是以一次读入一整行字符串开始的,这样处理后能天然的划分出的单词(词组)是属于Title或是属于Abstract
-
另一方面,为了维护针对词组的滑动窗口,划词函数额外维护每个词组的第二个单词的起始位置,这样就能在整个字符串的维度上,实现一定长度词组的步进
核心算法流程图:
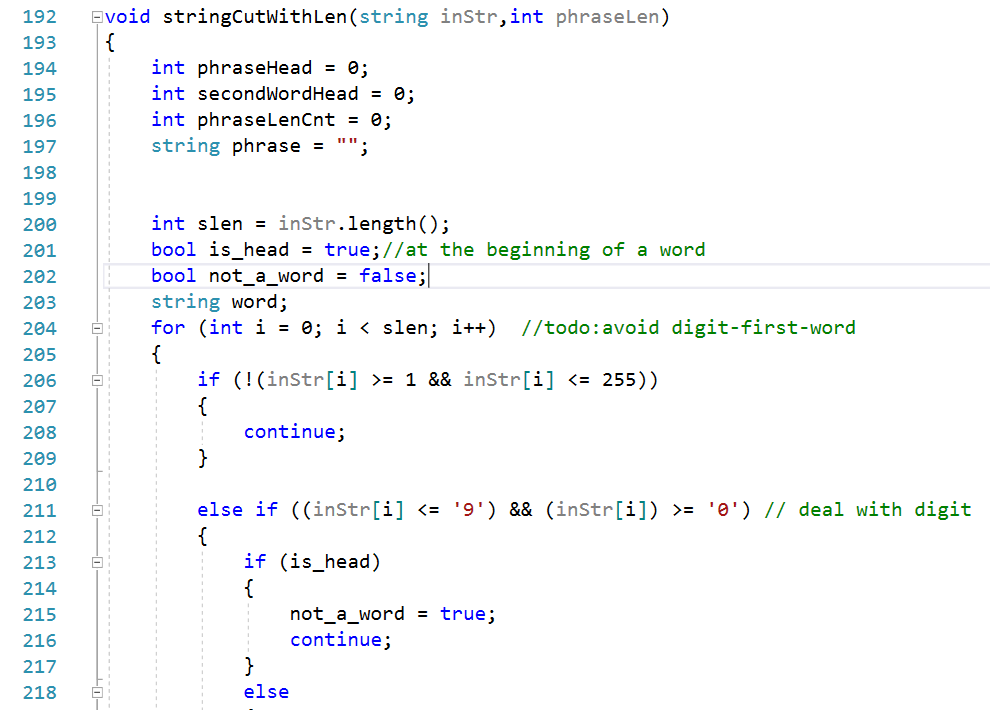
核心代码展示:

性能改进
-
针对我们的程序,在性能测试上使用了从CVPR上爬取的论文列表来作为性能测试的样本,在最开始的测试中,跑完全文本耗时12.09s
-
性能分析:
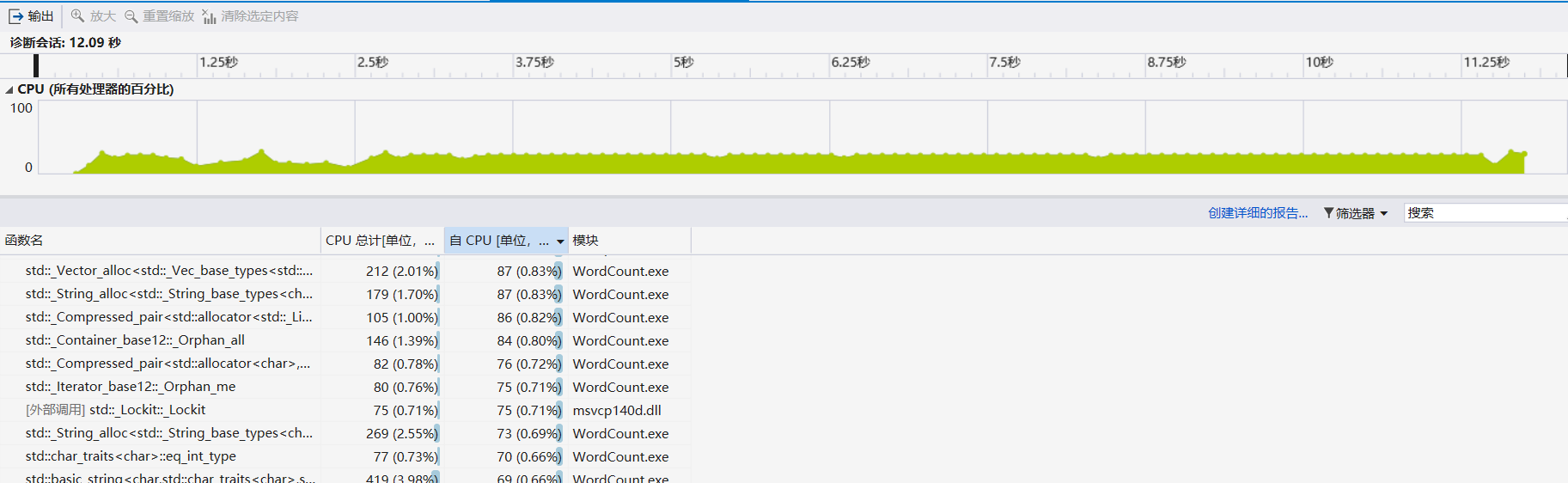
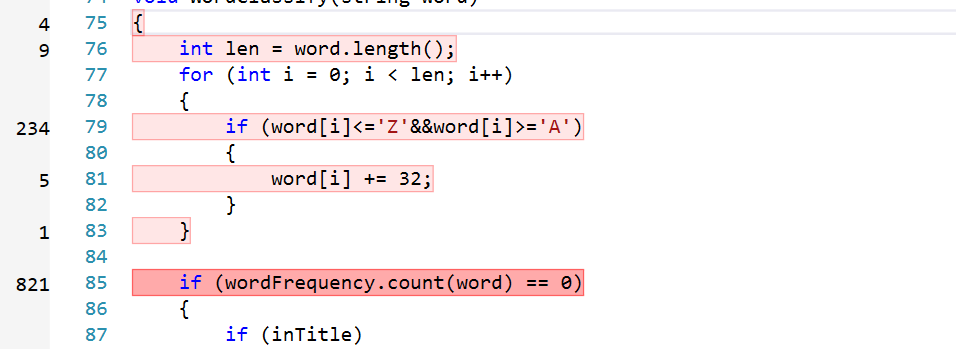
- 通过分析,可以发现代码逻辑在所指出的地方存在不合理的地方,经过改正后:
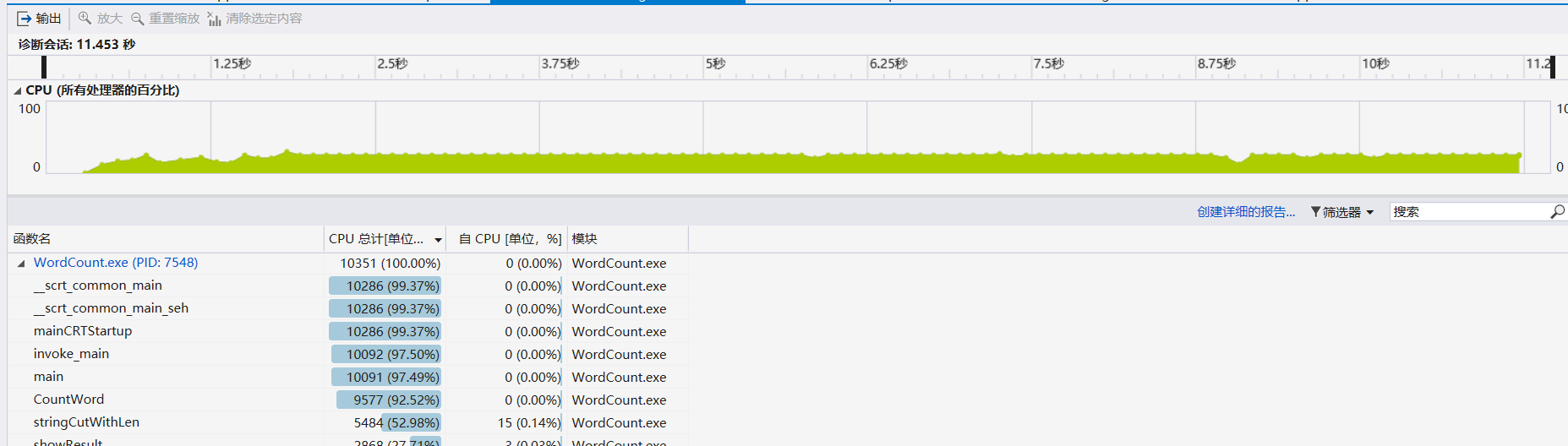
- 运行相同文本的时间由原来的12.09s变成11.45秒,性能提升5.3%
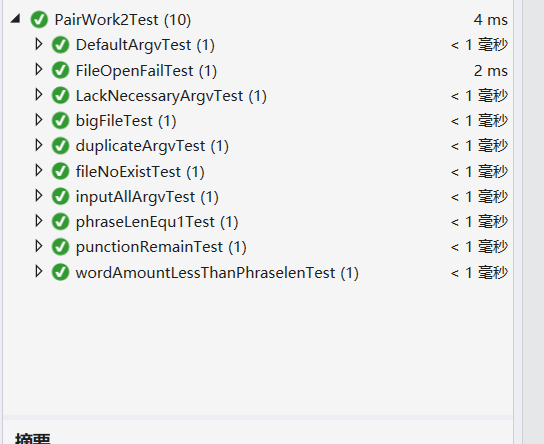
单元测试
-
安排的十个单元测试:
-
缺少3个必要参数时程序提示参数错误
-
缺省2个附加参数程序能按照缺省值正确运行
-
输入所有参数时程序正确运行
-
输入重复参数程序提示参数错误
-
传入较大文件时程序正确运行
-
当词组长度为1时,程序能正确运行
-
当一行的单词数少于词组长度时无输出
-
词组内有其他符号时划词后能保留
-
输入文件不存在时程序提示参数错误
-
输入文件无法打开时程序提示参数错误
测试结果:
github代码签入记录
遇到的代码模块异常或结对困难及解决方法
-
爬虫使用:在一开始使用pyhton进行论文列表爬取时,爬取结果会出现,一些论文丢失的问题,在我确认所使用的正则表达式没有问题后,通过比对爬取成功的论文于爬取失败的论文的html格式,我发现CVPR论文列表的网页中
<div id="abstract" >这一标签的末尾有一个空格,这在正则表达测试器中可以匹配到所有结果,但在真正爬取时python的正则表达式会把有空格情况和无空格情况看作两种不同格式,导致爬取失败 -
需求分析遇到的困难,在需求分析时一开始看到总共有7点需求,且需求间会有不同程度的耦合,这使我们在抽象接口时顾此失彼。解决方法:不断阅读作业需求,首先找出与其他需求关联度最高的部分,优先解耦
附加题
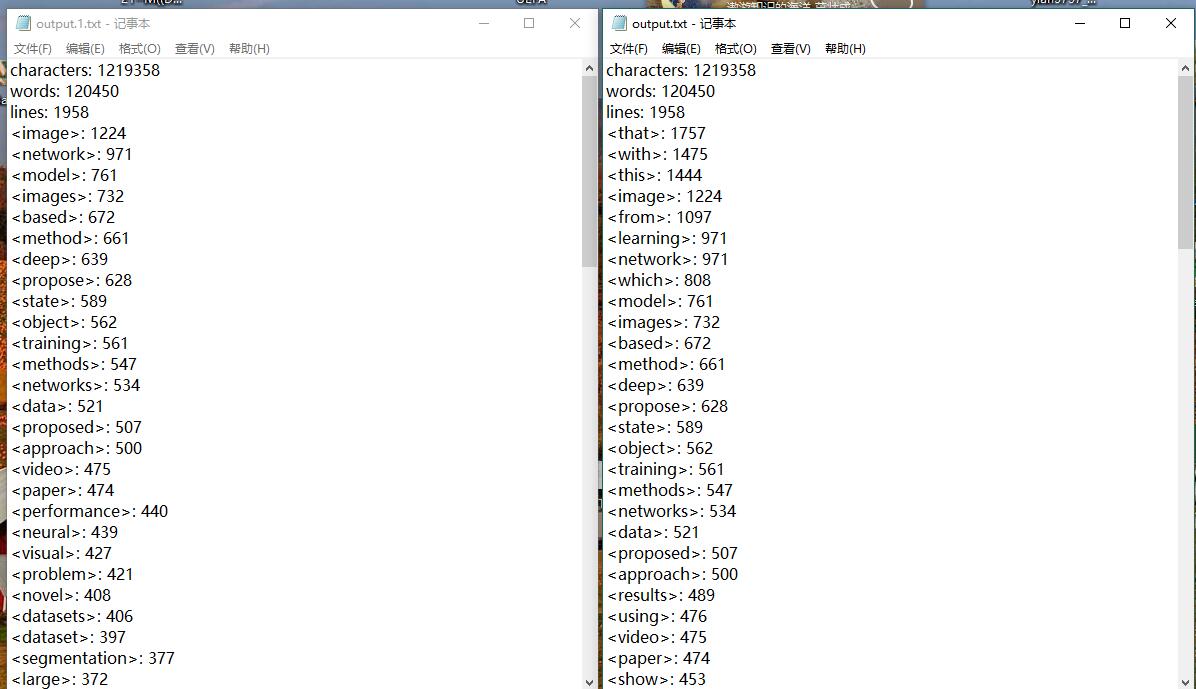
- 考虑到得到topN后的高频词中有着不少像“the,that,show,then”这些出现频率很高但对主题并没有很短关联的助词和无意义词汇,我们决定写个过滤掉他们的小功能,为了在N很小的时候可以筛选出更有用的信息。于是就有了这样一句十分暴力的比较。

- 优化前后对比将无关的助词过滤掉:
- 而后我也对输出做了相对直观的改进,让词频的输出不局限与数字,而是以的形式按照词频所占词频总数的比例输出一个类似于能量条的笑脸串。

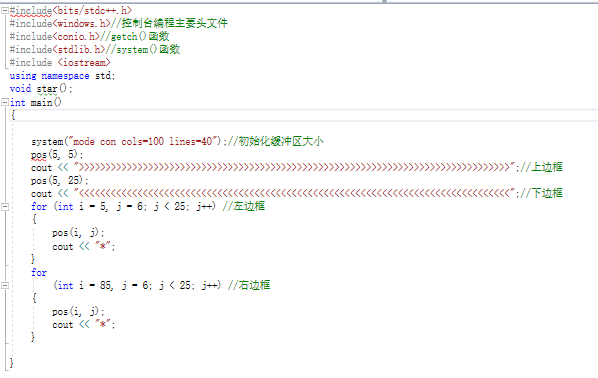
- 我们还有一个大胆的设想就是给这个小程序增加美丽的边框,研究了一番命令提示符工具后增加了一个关于输出界面的源文件。
评价你的队友
- 感谢这次结对作业,能够获得难得的机会能一边打代码一边有队友进行实时复审,实在是难得的体验。另一方面,很高兴认识葛亮,并且能在国庆的头一天一起打Game,有葛亮在旁边复审就强迫我必须先把代码逻辑理顺,再动手实现,这样子反而提高了我们两的项目进度
学习进度条
| 第N周 | 新增代码 | 累计代码 | 本周学习耗时 | 累计学习耗时 | 重大成长 |
|---|---|---|---|---|---|
| 1 | 300 | 300 | 5 | 5 | 初步了解基于python的网页爬虫原理,阅读urllib和beatufsoup官方文档 |
| 2 | 0 | 300 | 3 | 8 | 学习Blasiq模型设计工具 |
| 3 | 200 | 500 | 10 | 18 | 简单python爬虫编写,爬取数据处理 |
| 4 | 580 | 1080 | 25 | 43 | 较复杂C++代码逻辑的实现 |
