
Java基础
Java 是编译型语言,需要先编译,再运行,因此要安装JDK (Java Development ToolKit ,Java开发工具包),因为它提供了编译和运行命令。Windows下,http://jdk.java.net/java-se-ri/11下载压缩包后解压,打开目录,bin目录里面就是java所有命令,javac编译java文件,产生.class文件,java运行编译好的class文件。怎样使用命令呢?配置环境变量,还要配置一下CLASSPATH,网上有太多配置教程,就不说了。Ubuntu安装JDK,sudo apt update,然后sudo apt install openjdk-版本号-jdk, 比如sudo apt install openjdk-21-jdk, 就可以使用Java了。为了以后升级,也简单记录一下删除Java 的步骤。sudo apt remove openjdk-版本号-jdk, 比如sudo apt remove openjdk-21-jdk。有时需要手动删除,找到java包安装目录,通常在/opt/或/usr/lib/, 在我的电脑上,java包装在/usr/lib/jvm

sudo rm -r /usr/lib/jvm 删除整个jvm 目录就可以删除java了。
安装编辑器或IDE。VS Code,Eclispe, IntelliJ IDEA, Spring Tools 4 都可以。说一下Spring Tools 4,它的安装比较特别,官网https://spring.io/tools,有Spring Tools 4 for Eclipse,假设在Windows下,选择windows X86_64, 下载下来的是一个jar 包。要用java -jar 命令,而不是winRAR解压。在jar包所在目录,按住shift 右击,选择’在此处打开powershell, 输入java -jar spring, 按tab 键,

按enter,等待解压完成,出现sts-4.7.1.RELEASE的文件夹,里面就有启动sts的快捷键 。需要注意的是,下载下来的Spring Tools 4 jar包不要放到中文路径下,路径中也不要有特殊符号(例如&等)。
Java是面向对象的编程语言,做什么事情都要先找一个对象,然后使用这个对象来完成。这和我们日常生活差不多,不想洗衣服,就买一个洗衣机,不想做饭,就下餐馆,这是因为对象都有着特定的属性和功能,实现了某个需求,要不然,也不会找这个对象。在Java中,从哪里找对象呢?Java提供一些,但大部分需要自己创建,自己找自己创建的对象,怎么创建对象呢?要先创建一个类,然后使用类创建对象,就像盖房子之前,要先有图纸,然后按图纸建房子。图纸是对房子的各种属性和功能进行详细的描述,类也是对对象的属性和方法进行的详细描述。Java编程就是创建类,然后使用类创建对象,最后调用对象的属性和方法。怎么创建类?class 类名{,换行,写属性和方法,最后以}结束。
class 类名 { 类型 属性名; 类型 属性名; 类型 方法名(参数列表) {} 类型 方法名(参数列表) {} }
写到哪里,每一个Java程序(文件)都以.java结尾,文件名通常和类名相同,一个类一个文件,比如创建一个Box类,就创建一个Box.java文件,类名以大写字母开头。在VS code 中,新建Box.java文件。Java又是强类型语言,什么都有类型,属性,方法,参数等。假如Box有长,宽,高,取值都是小数,那就是double类型,有一个方法,计算体积,方法的返回值也是double类型,没有参数,Box 就可以如下定义
class Box { double width; double height; double depth; double volume() { return width * height * depth; } }
类创建好了,就可以创建对象了。在哪里创建对象?在Java 中,每一个类都可以定义一个main方法,执行某个类时,就会自动调用main 方法,main方法的格式也是固定的,public static void main(String[] args) {方法体}, 在方法体中创建对象,调用方法就可以了。创建对象用的是new 类名(),比如new Box(), 创建成功后,最好把它赋值一个变量,以便使用这个对象。声明什么类型的变量来接受创建的对象呢?因为是使用Box类来创建的对象,这个对象就是Box类, Box box1 就声明变量成功了,突然发现class 创建了一个新的类型,我们使用新的类型创建对象。
public static void main(String[] args) { Box box1 = new Box(); // 声明变量的方式是类型 变量名 box1.width = 10; box1.height = 20; box1.depth = 15; double vol = box1.width * box1.height * box1.depth; System.out.println("Volume is " + vol); }
打开VS Code 终端,输入javac Box.java ,多了一个Box.class 文件,编译成功,再输入java Box,控制台输出“Volume is 3000”。有时,javac 命令要提供代码文件(Box.java)的文件编码,比如 javac -encoding UTF-8 Box.java,才能编译成功。一个最基本的Java程序就写完了,涉及到了Java的基本数据类型,表达式,运算符,方法的定义,new操作符。
基本数据类型
整数(byte, short, int, long),4种不同类型的主要区别在于所占存储空间不同,存储的数据范围不同。byte占1字节,只能存储-128 ~ 127,short占2个字节,存储-32,768~ 32,767,int占4个字节,存储-2,147,483,648 ~ 2,147,483,647,差不多20亿,long占8个字节,存储-–9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807。通常使用int,只有数据特别大时,才使用long。
浮点数(float, double)用于表示小数,由于小数是无穷的,计算机内存有限,所以只能表示有限的小数,不能表示的小数只能用近似值表示,这就是浮点数的精度,用多少位小数来近似表示真实值,float 称为单精度,就是小数点后面6-7位来近似表示真实值,double称为双精度,小数点后面有15-16位小数来近似真实值,所以通常使用double类型。
字符(char):Java创建时,所有Unicode字符都能用两个字节进行存储,所以创建了char类型,占2个字节,存储一个Unicode字符。比如 'a','你'。有些字符不是很容易表示,就用转义字符,比如 '\n','\''。但现在Unicode字符太多了,一个char已经放不下了,两个字节的char只能存储Unicode编码从0到65536的字符。
布尔值只有true或false两种,表示真假。
表达式和运算符
最简单的表达式是字面量,比如10,20.0。由于Java是强类型语言,字面量也有类型,整数的默认类型是int,10是int类型,小数的默认类型是double,20.0是double类型。如要一个整数特别大,超出了int的取值范围,就要在后面加L,表示它是Long类型,比如100000000000就有问题,要用100000000000L。特别大的数中间可以加_,1_000_000_000,_只是用来提高代码的阅读性,编译器会去掉它。如果一个小数是float类型,后面要加f,比如20.0f。稍微复杂的一点的表达式,就是使用运算符,算术运算符(+, -, *, /, %),比较运算符(==, !=, >, <),逻辑运算符(&&, ||, !),比如10 + 20,10 > 5等。使用运算符时要注意,运算的两端一定要数据类型相同,否则无法运算,比如布尔型就不能和整数进行运算。但有一个例外,就是计算的两端都是数值型,数值类型相互兼容,计算时,Java会进行自动类型提升,把运算的两端变成相同的类型,就是小类型转化成大类型。
public static void main(String[] args) {
byte a = 10;
float b = 100;
double c = 20.0;
System.out.println(a * b * c);
}
byte(short)先提升成int,就是 int * float * double,int,float再提升成double,整个表达式的值是一个double类型,Java的表达式也是有类型的。

实线的转换不会损失精度,虚线的转换有可能会损失精度。进行算术运算时,需要要注意
除法:整数相除返回的也是整数(舍弃小数),除0会报错,而浮点数相除返回的是浮点数,除0则是返回NaN。越界:整数计算,如果计算结果超出int的取值范围,会把计算结果的高位舍弃掉(这里的高位是二进制的位,计算结果用二进制表示),得到的结果还是int 类型(在int 类型的取值范围内)。但浮点数,如果上溢(超出了浮点数的最大值),就会返回负无穷或正无穷,如果下溢(超出了浮点数的最小值),则返回0。准确性:浮点数的计算是不精确的,因为存储的不精确,比如存储0.1,可能是用0.999999存储的,0.1 + 0.2 等于0.300000004, 而不是0.3。如果想要进行精确计算,就要使用BigInteger或BigDecimal,分别用于整数或小数的计算。Math 类提供了大量的计算函数,比如sqrt,pow, floodMod,但它的浮点数计算也是不精确的,如果要精确计算,使用StrictMath.
语句
表达式后面加;就成了语句,语句就是告诉计算机要做什么事情。单纯的表达式语句没有意义,比如 5;,有意义的是变量声明,赋值语句,控制和循环语句等。由于Java是强类型,变量声明时要指定类型,比如 int num;赋值使用等号,num = 10; 需要注意的是赋值时,Java也会做类型兼容性检查,如果类型不兼容就报错,不能把布尔类型赋值给int类型。不过,数值类型之间是兼容的,可以把小类型赋值给大类型,但不能把大类型赋值给小类型
byte b = 4; b = b+3;
b+3是int类型,却赋值给byte类型,大类型赋给小类型,报错。但是4也是int类型,怎么能赋值给byte?字面量和变量不一样,字面量在编译时就知道它的大小(4肯定能放到byte中),但变量只有在运行时才知道它的大小。编译时,编译器只知道int赋值给了byte,报错了。非要这么做,必须强制类型转换, 把int型转化成byte. byte b = (byte) b+3; 强制类型转化也是在类型兼容进行,也就是数值类型之间进行,但真正的程序中很少用到强制类型转换。
变量声明同时赋值称为初始化,int num = 10; 当初始化时,Java可以通过初始化值来推断变量的类型,就可以用var来声明变量,var num = 10; 赋值也有简便写法,+=, -=, ×=, /=,比如 x+=4 相当于 x = x + 4; 但需要注意的,操作符两边数据类型不一致,就进行类型转化。比如 x是int类型,x+=3.5, x = (int)(x + 3.5); 赋值也是一个表达式,也会产生一个值, x+=3.5,就是x的值,int y= x+=3.5, 但一般也不会这么用。if else, while, for 等流程控制语句和其它语言都一样,就是需要注意嵌套块不能和外面的变量重名
public static void main(String[] args) {
int n;
. . .
{
int k;
int n; // ERROR--can't redeclare n in inner block
. . .
}
}
如果使用多个条件,返回不同的值,可以使用switch 表达式,在main 函数中
var n = 10;
int num = switch (n) {
case 1 -> n + 10; // 使用 -> 就不用使用break
case 2 -> n + 100;
default -> n + 1000;
};
方法(函数)
方法和其他语言中的函数没有什么区别,就是定义一段要执行的代码,不过Java中的方法有重载的概念,在一个类中,方法可以重名(类中有多个同名方法),只要方法的参数列表不同,方法名加参数列表称为函数签名。Box 类增加几个测试方法
void test() { System.out.println("No parameters"); } void test(int a, int b) { System.out.println("a and b: " + a + " " + b); } double test(double a) { System.out.println("double a: " + a); return a * a; }
然后在main方法中调用
public static void main(String[] args) { var ob = new Box(); ob.test(); ob.test(10, 20); ob.test(10); // invoke test(double) ob.test(123.25); }
当方法被调用时,Java会把实参和形参的类型和数量进行匹配,匹配到哪个方法,就调用哪个方法,匹配不到就报错了。类型匹配的时候,也不一定百分百类型相同,只要类型兼容就可以了,比如数值型类型,可以做类型提升,再进行匹配,当然,匹配的时候,肯定是百分百类型相同优先,实在匹配不到,才类型兼容。比如test(10),没有接受int类型的方法,只能把int转化成double,调用test(double)。如果有test(int),肯定先调用test(int)。需要注意的是函数重载和函数的返回值没有关系。假如有 int test(int a) 和boolean test(int a) 两个重载方法,当在main方法中调用 test(5)时,Java 也不知道调用哪一个,因为虽然test方法有返回值,但调用的时候,完全可以舍弃返回值。
变长参数用...
static void vaTest(int ... v) {
System.out.println("Number of args: " + v.length);
for(int x: v) {
System.out.println(x + " ");
}
System.out.println();
}
对象的创建(new 操作符)
创建对象时,在new操作符完成之前,Java会调用构造函数对对象进行初始化,但Box类并没有提供构造函数,是的,如果类中没有提供构造函数,Java会提供一个默认的构造函数,给属性设置默认值进行初始化。数值型赋值为0,布尔型赋值为false,类类型赋值为null。
// 构造函数名和类名相同,和方法定义相似,但没有返回值,因为它隐式返回它所在的类的类型 Box() { width = 0.0; height = 0.0; depth = 0.0; }
创建对象实际上就是在内存中开辟一块空间给对象,然后返回这块空间的内存地址。Box mybox = new Box(); mybox变量实际获取的是对象内存地址。使用mybox时,它就像一个Box对象,但是它只是一个实际box对象的内存地址。mybox引用了一个Box对象。 每一个对象都拥有类中实例变量的一份copy, Box对象包含它自己的copy的实例变量,width, height, and depth.
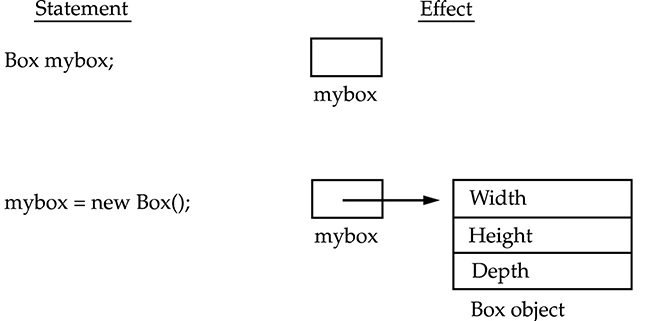
一定要区分对象和对象类型的变量,变量只是栈中的一块内存空间,没有存储任何内容,赋值之后,它也不包含对象,只是包含对象的引用地址。对象是创建在堆内存中。new 操作符的返回值是引用(地址)。Box mybox = new Box(); 有两部分,表达式 new Box() 创建了一个Box类型的对象, 它的值是新创建对象的引用。引用然后存储在box1变量中。当把对象变量赋值给另一个对象变量,赋值的只是地址,两个变量指向同一个对象,同一个内存地址。Box b1= new Box; Box b2 = b1;
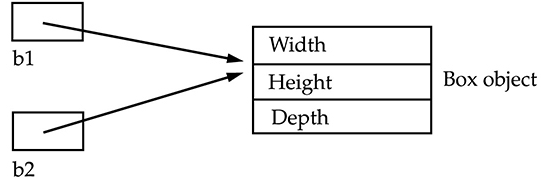
一个变量对对象做的任何改变,都会影响另一个变量。可以通过赋值为null,来解除对对象的引用,比如b1 = null; 谈到对象变量的赋值,就不得不提一下函数的调用,函数的调用,实际上就是把实参的值赋值给形参,在 Java中,参数的传递都是按值传递。当传递对象参数时,实际上传递的是对象的内存地址,形参和实参都指向了同一个对象,方法内对对象的修改,也影响方法外的对象。当传递基本数据类型时,复制的就是值,形参的修改对方法外的实参没有影响。参数得到的永远是实参的值的复制,方法永远不能改变外部变量的值(让外部的变量获取另外一个对象的地址),但是它可以改变变量指向的对象的状态,Box增加如下方法
void meth(int i) { i = i * 2; } void meth(Box o) { o.width = o.width * 2; }
在main 函数中调用
var box = new Box(); box.width = 20; int a = 15; System.out.println("a before call: " + a); box.meth(a); System.out.println("a after call: " + a); System.out.println("box.width before call: " + box.width); box.meth(box); System.out.println("box.width after call: " + box.width);
当想显示初始化对象时,就要定义了构造函数,这时默认构造函数就会消失。
Box(double w, double h, double d) {
width = w;
height = h;
depth = d;
}
但是w,h, d 作为参数,可读性不好。如果使用width, height和double,又和实例变量重名了。这时可以使用this。在方法中,this就是指的当前对象,this.width就是引用的实例属性
Box(double width, double height, double depth) {
this.width = width;
this.height = height;
this.depth = depth;
}
如果两个函数都要,那就要重载,手动把默认的构造函数写上。一个构造函数可以调用另外一个构造函数, 用this,this要写到构造函数的第一行,
Box() { this(0, 0, 0); }
除了构造函数初始化,也可以直接给属性赋初始值,这个赋值先于构造函数执行。
class Box {
width = 20.0;
. . .
}
还有初始化代码块,直接在类中写一个大括号,大括号里面进行初始化
{
width = 20.0
}
构造函数被调用,如果它调用了另外一个构造函数,那么另外一个构造函数先执行,如果没有调用构造函数,所有实例变量先默认初始化,然后属性赋初值和初始代码块按照它们类中定义的顺序依次执行,最后构造函数执行。
封装
以上类的定义中,属性能被外界访问,按理说,属性是状态,不应该被外界直接访问,应该把它们封装到类里面,然后暴露方法,让外界访问。封装控制了类中的哪些成员可以被外界访问,类也变成了一个黑盒,外界只管调用方法,内部的实现不要管。Java提供了访问修饰符,public, private, protected,如果成员没有被任何一个修饰,就是使用的默认的访问权限。当一个类成员被public修饰时,这个成员可以被外界访问到。当一个成员被private 修饰时,这个成员只能在该类中使用。Box.java修改如下
public class Box {
private double width;
public double height;
double depth;
void setWidth(double width) {
this.width = width;
}
double getWidth(){
return width;
}
}
在同级目录新建Test.java
public class Test {
public static void main(String[] args) {
Box box = new Box();
box.height = 20; // pulic access
box.depth = 10; // default access
box.width = 30; // 错误
box.setWidth(30); // 使用方法访问私有属性
}
}
javac Test.java 进行编译,报错(width 在 Box 中是 private 访问控制)。通常提供一个成员变量,要private修饰,并提供对应的get和set方法。当成员变量是布尔类型时,它的get方法以is开头(isRect)。需要注意的是,get方法不要返回可变对象的引用,如果返回的对象可变,要先clone它,然后进行返回。
有时候,使用一个类成员时,完全不需要对象,直接使用类名就可以,这样的成员称为静态成员,用static修饰。静态成员属于类,像全局变量,因此当创建对象时,静态变量并不会复制到对象上,类的所有实例对象都共享这个静态变量
public class UseStatic { static int a = 3; static int b; private int width = 20; // 静态方法属于类,不能使用this,不能访问实例属性 static void meth(int x) { // System.out.println(width); 无法从静态上下文中引用非静态 变量 width System.out.println("x= " + x + " a= " + a + " b=" + b); } static { // 静态代码块初始化 System.out.println("静态代码块初始化"); b = a * 4; } public static void main(String[] args) { // 静态方法可以直接调用静态方法 meth(42); } }
当UseStatic被使用时, 所有的静态语句都执行了。首先a被设置成3,然后静态代码块执行,b赋值为12。静态方法还有一个重要的作用,就是工厂方法来创建对象,比如NumberFromat提供getCurrencyInstance()等静态方法创建对象,main 方法中
// 用静态方法创建对象 NumberFormat currencyFormatter = NumberFormat.getCurrencyInstance(); NumberFormat percentFormatter = NumberFormat.getPercentInstance(); double x = 0.1; System.out.println(currencyFormatter.format(x)); // prints $0.10 System.out.println(percentFormatter.format(x)); // prints 10%
继承
当写了大量的类以后,再写类时,就会发现这个类怎么和以前的一个类这么相似呢,或者有个类已经实现这个类的部分功能?这就是Java 中的继承和组合。比如,要写一个汽车类,发现以前有一个轮胎类,这时我们就可以直接把轮胎类对象放到汽车类作为属性直接使用,这就是组合,组合和现实中的组合没有区别,组合一个类,和搭积木一样,它体现了一种has-a 的关系。再比如已经有了一个员工类(Employee),再创建一个经理类(Manager),经理也是员工,经理类完全可以复用员工类,然后再在员工类的基础上,添加自己特有的属性和方法。这种复用就是继承,一个类继承另一个类,它就拥有了另外一个类的所有属性和方法,类自己再添加自己特有的属性或方法。Manager类继承Employee类,使用extends关键字,被继承的类称为父类,创建的新类称为子类。继承是is-a的关系,新类也是一个已存在的类,就可以使用继承。Employee.java
public class Employee { private double salary; public Employee() {} public Employee(double s) { salary = s; } public void raiseSalary(double byPercent) { double raise = salary * byPercent / 100; salary += raise; } // 省略 salary get 和 set 方法 }
Manager.java
public class Manager extends Employee{
private double bonus;
public void setBonus(double bonus) {
this.bonus = bonus;
}
}
Manager类继承Employee类,Manager对象就有了getName和getHireDay等方法,尽管这些方法并没有定义在Manager类上。每一个Manager对象也有2个属性,salary和bouns,salary是来自父类。尽管子类包含父类的所有属性和公有方法,但它不能直接访问父类的私有属性。这就有一个问题,子类不能直接读取父类的私有属性,但能通过get, set等公有方法来获取。子类怎么初始化从父类得到的属性?父类提供初始化这些属性的构造函数,子类可以在自己的构造函数中调用父类的构造函数,为此有一个super方法,子类的构造函数调super,super就会调用父类的构造函数,来完成继承属性的初始化。Manager类添加构造方法
public Manager(double salary) {
super(salary);
bonus = 0;
}
Manger也有get salary的需求,但父类的getSalary不满足需求,因为Manager的getSalary要加bonus。Manager是不是要重新定义一个方法getManagerSalary?不是,Manager 可以定义一个和父类同名的方法,这称为覆写或重写,复写要注意,函数签名必须保持一致,返回类型原来是要求是一模一样的,
public double getSalary() { double baseSalary = super.getSalary(); // 子类调用父类的同名函数,要用super来调用父类中的方法 return baseSalary + bonus; }
现在要求是类型兼容,比如复写
public Employee getBuddy() { . . . }
可以返回Manager
public Manager getBuddy() { . . . }
有了继承关系后,可以把子类对象赋值给父类声明的变量,Employee e = new Manager(5000);,但也带来一个问题,manager对象隐式的向上转型为父类型,变量e只能获取到父类型定义的属性和方法。是引用变量,而不是它所指向的对象,决定了哪些方法能被访问到,这是合理的,因为父类并不知道子类添加了什么方法。但是当子类复写了父类的方法后,子类和父类都拥有同一个方法名,Java运行时会调用子类的复写的方法,这称为动态方法分配(运行时多态)。Java的对象变量是多态的(多种形态), 比如 Employee的变量,它可以引用Employee 对象,也可以引用Emloyee 的子类对象(经理,秘书等),有多个形态。方法调用的解析过程,比如 x.f(args), x 是C类型,
编译器先看x的类型和它调用方法名f,然后迭代C类型上的所有f方法,以及父类上的所有公有的f方法,父类上的私有方法不能被子类访问。最后方法重载解析,找到最匹配的f()方法。如果匹配的f()方法是私有的,静态的,final 修饰的,编译器就知道调用这个方法,这称为静态绑定。但如果f()是公有的,方法的调用要依赖对象的实际类型,要使用动态绑定,在运行时确认对象的实际类型(就是确认隐式的this),这时编译器会生成一条指令,说明f函数的调用需要动态绑定。当程序真正运行时,虚拟机需要找到x引用的实际对象的类型,然后调用该类型的f方法,比如,x的实际类型是D,是C的子类,如果f方法在D类上有定义,就调用D类的方法,如果D类上没有定义,就调用C类上面的方法。final 修饰一个方法,这个方法不能被复写。当final修饰一个类时,这个类不能被继承。
当把子类对象赋值给父类对象类型的变量时,可以强制类型转化成子类,从而用子类型的方法,这也称为向下转型。
Employee employee = new Manager(10000);
Manager manager = (Manager) employee;
在转化之前,最好使用instanceOf 判断一下,能转化,才转化,
if(employee instanceof Manager) {
Manager manager = (Manager) employee;
manager.setBonus(5000);
}
// 或者新写法:当employee 是Manager的时候, 赋值给boss 变量
if(employee instanceof Manager boss) {
boss.setBonus(5000);
}
但是当使用var 声明变量,Java在做类型推断时,赋给变量的值是什么引用类型,变量就是什么引用类型。
class MyClass {} class FirstDerivedClass extends MyClass {int x;} class SecondeDerivedClass extends MyClass {int y;} class Test { static MyClass getObj(int which) { switch (which) { case 0: return new MyClass(); case 1: return new FirstDerivedClass(); default: return new SecondeDerivedClass(); } } public static void main(String[] args) { // 虽然getObj方法返回不同的对象,但是它声明的返回值类型是MyClass // 所以 mc,mc1, mc2 都被推断成了MyClass类。 var mc = getObj(0); var mc1 = getObj(1); var mc2 = getObj(2); mc1.x = 10 // error,mc1是MyClass类,并不是FirstDerivedClass mc2.y = 10 // error, mc1是MyClass类,并不是SecondeDerivedClass } }
所有类都默认继承Object类,不用写extends Object,Object有几个重要的方法,equals判断两个对象是否相等,它的默认实现就比较两个对象的地址是否相等。toString()方法,把对象转化成String 进行输出,默认的实现是输出地址。所以子类感觉不合适,就要复写方法,比如两个Employyee,只要salary相同,就认为两个对象相等,Employee 添加equals方法
public boolean equals(Object otherObject) { if (this == otherObject) return true; // 地址相同是同一个对象,一定相等 if (otherObject == null) return false; // null肯定不相等 if (getClass() != otherObject.getClass()) return false; // 两个对象属于不同的类,也不相等 Employee other = (Employee) otherObject; // otherObject 是一个非null的Employee对象 return salary == other.salary; // 按照需求进行测试相等 }
当子类也要复写equals方法时,先调用父类的equals方法,再比较子类的特殊性,Manager类增加equals方法
public boolean equals(Object otherObject) { if (!super.equals(otherObject)) return false; Manager other = (Manager) otherObject; return bonus == other.bonus; }
当调用equals方法,传递过来的参数是子类怎么处理?上面使用的是getClass() 方法,很明显,它会返回false. 但有的人会使用 InstanceOf 来代替getClass
if (!(otherObject instanceof Employee)) return false;
如果这样判断相等的话,otherObject可以是子类对象,并且返回true。但这会带来一个问题: 因为Java规定 x.equals(y),y.equals(x) 也必须成立。如果x 和y 是不同的类型,比如x是父类(Employee), y是子类(Manager),父类中的equals 方法,如果使用instanceof 来判断,那么 x.equals(y) 返回true. 那么 y.equals(x) 也必须成立。那么在子类中实现equals() 方法的时候,它接受是父类的对象,它就只能判断父类定义的属性,而不能使用子类它自己有的属性来判断相等。 那么什么时候使用instanceOf, 什么时候使用getClass(). 如果子类仍然需要实现自己的equals()方法,那就在父类中的equals方法中使用getClass()。 如果子类不需要实现自己的equals()方法,而是使用父类中的equals()方法,那么父类中可以实现instanceOf().
hashCode:如果两个对象相等,它们的hashcode也应相等。因此,实现equals方法的同时,最好实现一下hashCode()方法,我们用哪些属性判断的两个对象相等,就生成哪些属性的hashCode. 把属性传递给Objects.hash()就可以了
public int hashCode() { return Objects.hash(salary); }
toString方法,当把对象转换成字符串时,转换成什么样的字符串,通常是把对象的属性都显示出来
public String toString() { return "Employee[salary=" + salary + "]"; }
继承是类与类之间的关系,一个对象用哪个类创建,他就拥有哪个类定义的所有属性和方法,当用一个子类创建对象时,对象包含子类的所有属性, 一个一个对象是独立的, 没有什么关系。创建的对象并不知道它是由父类还是子类创建的。继承的属性主要是由构造函数的调用实现的,子类的构造函数调用父类的构造函数。
抽象方法,抽象类。父类拥有共性,子类拥有个性,不断向上抽取共性的时候,父类越来越抽象,就只剩下描述了,根本没有具体的实现方式,太抽象了,也没有办法实现,只能由子类进行实现,这时就要使用abstract声明类,它不能创建对象。
public abstract class Person {
public abstract double getPaid();
}
实体类实现抽象类,就是实现抽象方法,也是用的extends
public class Worker extends Person {
public double getDescription() {
return 5000.0;
}
}
接口
接口(协议)仅仅是声明了一个类有什么方法,能做什么事情,因此它只有抽象方法。接口的定义用interface
interface Callback { void callback(int param); }
所有方法默认都是public abstract 的,因此这两个关键字可以不写。一旦接口被定义,很多类都可以实现它,表示它可以做接口定义的事情,一个类也可以实现多个接口。实现接口,就是复写接口中定义的所有方法,格式为 class 类名 [extends 父类] implements 接口名, [接口名...],复写的方法必须public
class Client implements Callback {
public void callback(int param) {
System.out.println("callback called with" + param);
}
}
实现接口,只是确保类有接口定义的方法,至于实现细节,接口不管,想怎么实现,就怎么实现,类可以定义私有变量,构造函数等,只要达到接口的要求,就可以了,甚至,类都可以比接口有更多的方法。有了接口,有了实现类,用接口声明变量,变量就可以引用实现类创建的对象,变量调用方法时,就会执行它所引用的对象所属的实现类中定义的方法。接口可以继承接口,一个类要实现接口,就要实现接口中的所有方法,包括继承过来的接口。从JDK8以后,接口的方法可以提供默认实现,也可以有静态方法和私有方法。私有方法只能默认方法和其他私有方法调用,
interface Callback { void callback(int param); default int getNumbeer() { return 0; } // static interface methods are not inherited by either an implementing class or a subinterface. static int getDefaultNumber() { return 0; } }
default和static方法都有特殊的用途,default方法主要是可扩展,给以前的接口添加方法,不会对以前的代码造成破坏。给接口添加方法,实现类就要实现它,以前的代码就要重写,否则报错。有了default实现,实现类没有实现的方法就用default 实现,以前的代码照样运行。虽然有了这些方法,接口原始的作用仍然存在。通常来说,使用接口时,可以当这些方法不存在一样继续使用,它的主要目的仍然是声明做什么,而不是怎么做,这些方法只是增加了灵活性。增加default 方法也没有改变接口关键的一点,它不能保存状态信息。
有了默认实现,一个类实现多个接口,而接口中都定义了相同名字的默认实现,要怎么处理?比如:Alpha, Beta 都定义了reset()方法(默认实现),MyClass 实现了Alpha和Beta,需要手动实现reset()方法,可以继承一个有reset方法的类,也可以在实现方法中指定使用哪一个默认方法,使用方式是接口名.super.方法名,比如Alpha.super.reset()
interface Alpha { default int reset() { return 0; } } interface Beta { default int reset() { return 5; } } public class MyClass implements Alpha, Beta { public int reset() { return Alpha.super.reset(); }; }
Java的方法定义是返回值类型,如果返回值类型是一个类,那么这个方法要返回 一个对象。如果返回值是一个接口,那么方法也要返回一个对象,实现这个接口的对象。
异常
程序在运行过程中发生了错误,破坏了它的正常执行,就是发生了异常,Java就会抛一个包含异常详细信息的对象出来,默认情况下,异常对象会被抛到控制台,整个程序停止执行。

某一处异常肯定不能影响整个程序的运行,所以要处理这个异常,使用的是try catch, finally。可能发生异常的代码放到try中,如果异常真发生了,被抛出,catch捕获,进行处理。不管异常有没有发生都要执行的代码放到finally中,它不是必须的。
class Exc0 { public static void main(String[] args) { try { int d = 0; int a = 42 / 0; } catch (ArithmeticException e) { System.out.println("除0"); } } }
当catch多个异常时,可以用 |
catch (IllegalAccessException | ArithmeticException e) {
System.out.println(e);
}
所有异常类都是Throwable的子类。Throwable有两个直接子类:Exception和Error。Exception是需要程序处理的,它有一个子类RuntimeException,比如除0,数组越界,通常指的是代码编写有误,如果在除0之前,判断一下是不是0,就不会发生错误。其它子类是发生了坏的事情,比如网络断了,写的程序本身没有问题,程序控制不了网络断不断,这是外界的环境导致的。Error 是关于JVM运行环境的错,比如Stack overflow,程序处理不了。只要和外界有关的代码引发的异常,都需try/catch。编译器也确保程序中要为这些代码提供异常处理程序,因此称为受查异常, 受编译器检查的异常。RuntimeException 和Error也称为不受查异常。

如果一个方法调用一个抛出受查异常的方法,如果不处理,就要在方法头标识它抛出的受查异常
class MyAnimation {
. . .
public Image loadImage(String s) throws FileNotFoundException, EOFException {
. . .
}
}
除了Java运行时自动抛出异常,也可以手动抛出异常,用throw。
class ThrowsDemo {
static void throwOne() throws IllegalAccessException {
throw new IllegalAccessError("demo");
}
public static void main(String[] args) {
try {
throwOne();
} catch (IllegalAccessException e) {
System.out.println(e);
}
}
}
Java的异常还有一个chained exceptions 的概念,两个异常相关联,第二个异常描述了第一个异常的原因。比如一个方法抛出了空指针异常,但是实际的原因是因为除0,导致空指针异常。尽管这个方法必须抛出空指针异常,但你想把引起空指针异常的原因(底层的异常)也告诉调用者,chained exceptions 就是处理这种层级异常的。创建异常对象的时候,直接把底层异常作为参数传递给它,或先创建异常对象,再调用initCause()方法,设置底层异常。在catch 中就可以调用getCause()来获取到底层异常。
public class ChainException { static void demoproc() { var e = new NullPointerException("top layer"); e.initCause(new ArithmeticException("cause")); throw e; } public static void main(String[] args) { try { demoproc(); } catch (NullPointerException e) { System.out.println("Caught: " + e); System.out.println("Origin cause: " + e.getCause()); } } }
如果父类的方法中有抛出异常 void show() throws Exception,那么子类在覆盖这个方法的时候,可以不抛出异常,如果要抛出异常,则抛出和父类一样的异常或是父类异常的子类。如果父类的方法没有抛出异常,子类覆盖的时候决定不能抛出异常。
包(Package)
应用程序通常有多个类组成,为了解决命名冲突,有了包的概念。把类放到包下,这个类就属于这个包了。包其实就是文件夹,把不同的类放到不同的文件夹下。物理层面,新建一个文件夹world,然后在world 里面建一个Person.java,代码层面,Person.java第一行写package world;来镜像这个行为。package 后面的内容,要和真实的物理层面的文件夹一一对应起来。如果文件夹是嵌套的,在world文件夹下面再新建一个hello文件夹,里面再一个Person类,那Person类的开头就要写package world.hello;,package后面点号就代表下一级文件夹。但是还有一个问题,package 后面的路径从哪里开始算的?基础目录开始算的,新建一个文件夹,开始写类,基础目录就是项目的根目录,如果用maven 创建的项目,它的基础目录是Maven指定的src/mian/java。package后面跟的就是从基础目录到类所经过的路径,不包括基础目录,每经过一层目录,就用.连接起来。
package world;
class Person {
void speak() {
System.out.println("在world 文件夹下" ); // 方法调用属性。
}
}
在根目录下面的任何一个类,比如Box类,中的main方法,创建Person对象,Person p = new Person(); 然后javac Box.java,报错,找不到Person类。有了包之后,类只能被它所在的包中的类使用,不能被外面的类使用,除非用public 修饰 , 在class前面加public。此时类也分为了两种,public类被外界访问(使用),非public的类包内访问(使用),Person类前面加public。有了包,还意味着类有了所属, 就不能直接使用类名了,而是要把它的所属也带上,Person类的真正名称是 world.Person。world.Person p = new world.Person()。javac Box.java 没有报错了。Java编译时,先找.class文件(world.Person.class),如果找不到,就会找对应的.java文件(world.Person.java),如果找到了就进行编译,然后把.class文件放到.java文件的同级目录下(world下面多了Person.class),要在基础目录下执行javac命令。但此时,如果p.speak(); 调用speak方法,还是会报错,speak()在Person中不是公共的; 无法从外部程序包中对其进行访问。这就是成员default访问权限和public访问权限的区别,default成员只能在包内使用,public成员在包外使用,在speak方法前面加public。
package world; public class Person { public void speak() { System.out.println("在world 文件夹下"); // 方法调用属性。 } }
有了包之后,使用包内的类,要先看它是不是public,再看它的成员是不是public。使用方式还有点繁琐,包名加类名,这时java 提供了导包(import)机制,先把包导入到要使用包的java文件中,然后使用包中的类时,直接使用类名。 Box.java
// 文件开头 import world.Person; // 在main中 Person p = new Person();
import 真正导入的是某个类,真正落脚到类名上,因为程序运行时,使用的是类。但是如果导入的包中和使用包的java 文件中,有重名的类名时,就要使用包和类名,指定使用哪一个包下面的类。import 定位类,只是编译器的形为,JVM执行时,.class文件中,类全是包名加类名。Java运行时(JVM)是怎么找到你创建的类的(去哪里找你创建的包)?首先,默认情况下,当前工作目录作为起点(执行java命令的目录),因此如果你的包是当前工作目录的子目录,这个包将会被找到。其次,设置 CLASSPATH 环境变量来指定一个或多个目录路径。第三,可以将 -classpath 选项与 java 和 javac 一起使用来指定类的路径。package world,为了找到world 包,可以在world 包的父目录开始执行,也可以设置 CLASSPATH 包含world 路径,或者执行java命令时,-classpath指定world的路径。如果使用后两种情况,路径不用包含world它自己,到world的父目录就可以了。比如在Windows,world目录在C:\MyPrograms\Java\mypack,classPath要设置成C:\MyPrograms\Java。对于我们这种简单的项目,直接在根目录下,java Box就可以了。如果world下面的Person有main 方法要执行,需要在根目录下,javac world/Person.java 进行编译,java world.Person运行。注意:javac操作的的是路径文件, java运行时用的是. 来加载类
现在.class文件分布到不同的文件夹中,可以把 .class文件都放到一个文件夹下,然后对这个文件夹进行压缩,就是jar包,如book.jar。jar包是压缩包。把jar放到classpath中,称序就可以使用这个jar包中的所有class文件。如windwos 下面classPath 环境变量,c:\archives\book.jar。创建jar包用jar命令, jar cvf jar包名 file1 file2 .... 比如 jar cvf book.jar *.class。c是create,v是输出过程信息,f是指定文件。
枚举
有名字的常量列表,定义了新的类型以及类型的合法值。
enum Apple {
Jonathan, GoldenDel, RedDel
}
枚举实际上是一个Apple类,每一个选项都是一个类的实例,也只有这么多实例,不能创建新的实例。创建一个枚举类型变量,它只能取枚举类型定义的常量,Apple ap = Apple.RedDel; 两个枚举常量可以用== 比较相等。当在switch 中使用 枚举时,case可以直接使用枚举常量,因为switch表达式已经表现出它是一个枚举类型,没有必要再重复了。
public static void main(String[] args) {
Apple ap = Apple.GoldenDel;
switch (ap) {
case Jonathan:
System.out.println("Jonathan");
break;
case GoldenDel:
System.out.println("GoldenDel");
break;
default:
break;
}
}
枚举有几个常用的方法,values() 和value.of。values() 返回数组,数组的每一项都是一个枚举常量。value.of() 接受一个字符串,返回与之相对应的枚举常量。toString() 返回枚举常量的字符串表达,比如"Jonathan" ordinal( ),获取到枚举常量在枚举列表中的位置(ordinal value,从0开始)。
public static void main(String[] args) {
Apple ap = Apple.valueOf("GoldenDel");
Apple[] allApples = Apple.values();
for (Apple a: allApples) {
System.out.println(a);
}
}
枚举是一个类,也就是说,它可以定义构造函数,枚举常量被创建时,构造函数就会被调用。
enum Apple {
Jonathan(10), GoldenDel(9), RedDel(12); //传递给构造函数的参数放到每一个枚举常量的后面,用()括起来。
private int price;
Apple(int p) {
price = p;
}
int getPrice() {
return price;
}
}
public class Test {
public static void main(String[] args) {
System.out.println(Apple.Jonathan.getPrice());
}
}
Java 程序是类组成的,类又是由属性和方法构成。在程序开发的过程中,我们可以书写每一个类,但是绝大多数的程序开发者都会使用第三方提供的类库。因此在学习java 的时候,不光要学习怎么书写java 代码来创建自己的类,还要学习其它类库提供了API.
引用数据类型---字符串
在Java中,字符串是对象,属于String类,按理说,创建对象都要用new,但字符串有字面量的表现形式, "Hello" 就是一个对象,当使用字面量时,字符串字面量是共享的,Java会在内存中会开辟一个字符串缓冲区(常量池),来存储创建的字面量。当创建新的字符串字面量时,它会先到字符串常量池中查找这个对象有没有存在,如果有,直接返回,如果没有,新建这个对象, 然后把放入池子中并返回。
String anotherString = “abc” ; // 创建
String b = "abc" // 直接返回
从这个角度说,字符串是不可变的。由于是对象,操作字符串,使用的是方法,由于不可变,所有方法都是返回新的字符串。
public static void main(String[] args) { String greeting = "Hello"; String s = greeting.substring(0, 3); // 获取部分字符串 String catS = greeting.concat(greeting); // 拼接字符串 // 当然有更简单的方法 使用 + String catS1 = greeting + greeting; // String catNum = greeting + 13; // 每个对象都能转化成字符串 boolean equation = s.equals(greeting); // 使用equals比较相等 boolean equation = s.equalsIgnoreCase(greeting); // 不要用== 比较大小,因为它是比较的对象的地址是否相等, 是否存在内存中相同的地方 boolean e = s == greeting; // 可以把 null 赋值给任何引用类型, 表明变量不引用任对象。 String b = null; }
字符串存到内存中,是按UTF-16编码,一个字符要么用2个字节存储,有的用4个字节存储,2个字节也称为code unit。 length方法就是计算多少个code unit。当一个unicode 字符能在两个字节表示,length没有问题,当不能用两个字节表示,length()方法,就会有问题,比如,只有一个表情包,却显示length是2,它不能准确地计算一个字符串的长度
var emoj = "🚀"; System.out.println(emoj.length()); // 2
为了得到真实的长度(code points 的数量), 就要使用
var emoj = "🚀"; var length = emoj.codePointCount(0, emoj.length()); System.out.println(length); // 1
还有charAt,也是获取某个code unit 对应的字符,如果两个code unit 组成一个字符,你会发现,charAt 只能返回””, 不能返回真实的字符。所以要使用codePoint, 想要得到第几个字符,就要得到第几个字符的codePoint. 当计算codePoint()传递给它的是code unit的索引 ,所以先要计算第几个字符code unit 索引。第一个字符的code unit 是0,可以codePointAt(0) 获取到第一个字符的codePoint. 但第二个字符的code unit 是2,而不是1, 使用codePointAt(2) 可以获取到第二个字符的code point. 所以获取到code unit 的索引 也是一个问题。Java 提供了offsetByCodePoints() 来获取哪一个字符的code unit索引,第一个参数是0,第二个参数就是从第一个位置开始的偏移量,也就是想获取第几个字符,这个参数就是几
int index = emoj.offsetByCodePoints(0, 0); // 获取到第0个字符的code unit 索引 int index = emoj.offsetByCodePoints(0, 1); // 获取到第1个字符的code unit 索引(所在的位置)
有了code unit 索引,就可以计算code point.
int codepoint = emoj.codePointAt(index);
整个程序如下:
var emoj = "🚀😃🤣"; int index = emoj.offsetByCodePoints(0, 2); int cp = emoj.codePointAt(index); // 获取到code point, String str = Character.toString(cp); // 🤣 把单个code point 转化成字符。
遍历字符串,也要遍历code point,
var emoj = "s🚀😃🤣d"; int i = 0; while (i < emoj.length()) { int cp = emoj.codePointAt(i); System.out.println(Character.toString(cp)); // 如果codePoint 比较大,要占2个code unit,所以要加2 if (Character.isSupplementaryCodePoint(cp)) i += 2; else i++; }
还有一个简单的方法,获取到字符串的所有codepoint 数组,直接遍历
var emoj = "s🚀😃🤣d"; int[] codePoints = emoj.codePoints().toArray(); for (int i = 0; i < codePoints.length; i++) { String s = Character.toString(codePoints[i]); System.out.println(s); }
把整个code point 数组转化成字符串,使用new String
var emoj = "s🚀😃🤣d"; int[] codePoints = emoj.codePoints().toArray(); String s = new String(codePoints, 0, codePoints.length);
在java 中,虽然字符串是作为对象存在的,但是一旦创建之后,这个字符串对象就不会再发生变化,字符串的任何操作都会生成一个新的对象。对于频繁进行字符串操作来说,要生成好多个对象,不利于性能, 所以java 就有了一个类,StringBuilder, 专门用来操作大量变化的字符串。
Occasionally, you need to build up strings from shorter strings, such as keystrokes or words from a file. It would be inefficient to use string concatenation for this purpose. Every time you concatenate strings, a new String object is constructed. This is time consuming and wastes memory. Using the StringBuilder class avoids this problem.
StringBuilder builder = new StringBuilder(); // //调用append方法添加字符。 builder.append("hello"); // 修改某个位置上的字符 builder.setCharAt(2,'c'); // 在某个位置插入字符 builder.insert(3, "wordl"); // 删除字符 builder.delete(0, 2); // 还有一个length方法,一共有多少个字符System.out.println(builder.length()); // 调用toString 方法,转化成字符串 String completeString = builder.toString(); System.out.println(completeString);
Text Blocks provide string literals that span multiple lines
String greeting = """ Hello World""";
String.format: 格式化字符串,像js中的`${}` String message = String.format("name: %s, age: %d", firstName, age);
引用数据类型---数组
数组就是相同类型的元素的集合,可以通过索引来获取每一个元素。要存储的元素的类型加[] 就是数组类型,比如 int[] a;创建一个数组对象的引用,new int[], 就是创建数组对象,不过要给一个容量。
int[] a = new int[100];
容量一旦确定,就不能再修改了。数组的初始化可以使用{}, 还可以创建匿名数组
int[] smallPrimes = { 2, 3, 5, 7, 11, 13 }; new int[] { 17, 19, 23, 29, 31, 37 }
创建一个数组,有默认的初始化,数值类型初始化为0,布尔类型初始化为false,引用类型初始化为null。对数组进行遍历,可以使用普通的for循环,可以使用 for Each
int[] smallPrimes = { 2, 3, 5, 7, 11, 13 }; for (int element: smallPrimes) { System.out.println(element); }
数组变量赋值给另一个变量,赋址的是引用,也就是地址,最终是两个数组变量指向同一个数组。
int[] luckyNumbers = smallPrimes; luckyNumbers[5] = 12; // now smallPrimes[5] is also 12
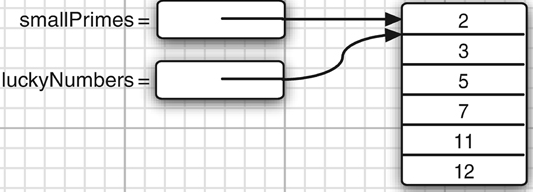
创建不同的数组,只复制数组的值,使用copyof
int[] copiedLuckyNumbers = Arrays.copyOf(luckyNumbers, luckyNumbers.length);
数组的排序是用Arrays.sort方法。 二维数组是数组的数组,
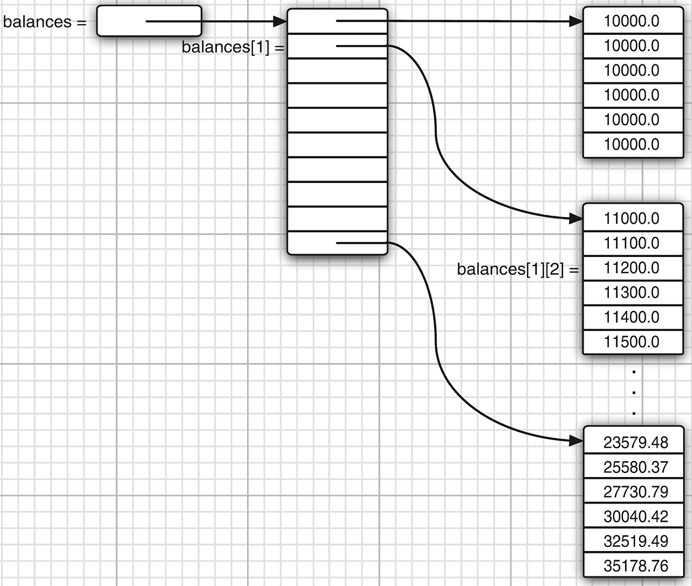
public static void main(String[] args) { double[][] balances; // 声明变量 balances = new double[5][4]; // 赋值 int[][] magicSquare = // 初始化 { {16, 3, 2, 13}, {5, 10, 11, 8}, {9, 6, 7, 12}, {4, 15, 14, 1} }; }
获取二维数组每一个元素,magicSquare[][], 用双重for 循环
for (int i = 1; i < balances.length; i++) { for (int j = 0; j < balances[i].length; j++) { double oldBalance = balances[i - 1][j]; double interest = . . .; balances[i][j] = oldBalance + interest; } }
还有一个toString,Arrays.toString, Arrays.deepToString() 二维数组。
I/O
Java通过流来操作I/O,流是对数据源或目的地的抽象,流自动连接到物理设备。尽管物理设备不同,流都是相同的方式进行操作,输入流抽象不同的输入,比如文件,键盘和网络,输出流抽象了不同的输出,控制台,文件和网络。输入流从数据源读取数据,发送到程序,输出流从程序拿到数据然后发送到目的地。
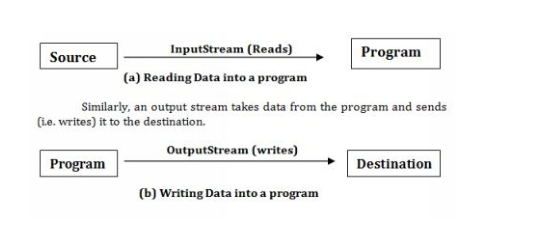
程序连接并打开数据源上的输入流,然后串行读取数据。 类似地,程序连接并打开一个到数据目标位置的输出流,并串行写出数据。 在这两种情况下,程序都不知道端点(源和目的地)的详细信息
字节流和字符流,但底层都是字节流,因为数据在计算机中都是二进制存储的。InputSteam和OutputStream字节流,Reader和Writer 字符流,都有read和write方法。控制台的输入是system.in,它是一个InputStream, 要转化成字符流,需要指定字节到字符的编码,用InputStreamReader。控制台的编码是什么编码,不知道也没有关系,可以使用System.console().charset()方法,提高效率,用bufferReader。字符流,就是读取到字节后,按照指定编码表,转化成字符,再输出给程序,没有指定编码表,就是用系统默认的编码表,所以IDEA和Eclipse编辑器都会把编码设置为utf-8。但Java中的字符串是UTF-16编码,所以Java拿到字符后,还要做一道转化,把它们转化成UTF-16
import java.io.*; public class Test { public static void main(String[] args) throws IOException { BufferedReader br = new BufferedReader( new InputStreamReader(System.in, System.console().charset())); String lines; while ((lines = br.readLine()) != null) { System.out.println(lines); } System.out.println(lines); } }
按ctrl + c 可以结束程序。PrintWriter is one of the character-based classes, 写到控制台。
public static void main(String[] args) throws IOException { PrintWriter pw = new PrintWriter(System.out, true); pw.println(-7); pw.println("This is a string"); }
当读取文件时,要关闭文件。自动关闭。
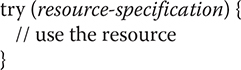
Typically, resource-specification is a statement that declares and initializes a resource, such as a file stream. It consists of a variable declaration in which the variable is initialized with a reference to the object being managed. When the try block ends, the resource is automatically released. In the case of a file, this means that the file is automatically closed. (Thus, there is no need to call close( ) explicitly.) Of course, this form of try can also include catch and finally clauses. This form of try is called the try-with-resources statement. The try-with-resources statement can be used only with those resources that implement the AutoCloseable interface defined by java.lang. This interface defines the close( ) method. AutoCloseable is inherited by the Closeable interface in java.io. Both interfaces are implemented by the stream classes. Thus, try-with-resources can be used when working with streams, including file streams.
import java.io.*; public class Test { public static void main(String[] args) throws IOException { int i; try (FileInputStream fin = new FileInputStream("a.txt"); var fout = new FileOutputStream("b.txt")) { do { i = fin.read(); if (i != -1) { fout.write(i); } } while (i != -1); } catch (IOException e) { System.out.println("An I/O Error Occurred"); } } }
read方法是从流里面读数据到内存中, write方法是从内存中写数据到流中。
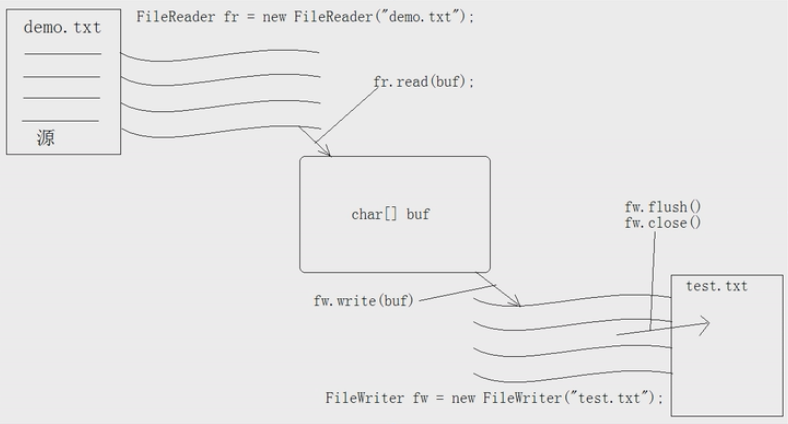
fs.read() 从流中读取数据,如果读到buffer中,buffer填充满了,fs.read() 它就不读了。它只读一次,并且返回读到的字符数。流中(或文件中)还有大量的数据,怎么办?再调用fs.read() 方法,fs.read()的方法从流中读到的数据,又重新填充buffer区,覆盖掉以前的数据。所以流的读取,就是不停地调用read()方法,去填充buffer区,那就while循环read()方法,但是while循环有一个终止条件,read()方法,如果读不到数据,那就返回-1, 正好,可以作为判断条件。真正的核心在于while 循环fs.read()方法。for(int len =0; len !=-1;) {len = fs.read()}
Java 中字符串有一个getBytes 方法,返回字符串占据的字节数组,字符串用多少个字节进行表示. 其实getBytes如果不使用任何参数的时候,它会采用系统默认的编码格式, java 中的字符串是unicode 编码,这个没有问题,但当调用getBytes时,java 会把unicode 编码转化成默认的编码或指定的编码格式,然后再返回所占据的字节数。
当我们使用返回的字节数组转化成字符串时,使用的语法如下 String newStr = new String(str.getBytes(), "UTF-8"); 后面的字符编码,utf-8, 指的是str.getBytes 返回的字节时所使用的字节编码, 先按照utf-8的格式,把str.getBytes() 的得到字节转化成字符,然后,jkd 再把utf-8的字符转换成Unicode 编码, 如果我们没有指定后面的编码,就会按照操作系统默认编码转换成字符,然后转换成unicode编码。
java 读取文件的路径,如果给fileread一个文件名,它是相对路径,相对于执行java程序的路径(在控制台调用java 命令所在的路径), 通常是在根目录或基础路径下执行程序,所以要把读取的文件放到根目录下或基础目录下。
泛型
泛型就是参数化的类型,类型也有了参数,定义类时,后面跟<>,<>中定义的参数,
class Gen<T> { T ob; Gen(T o) { this.ob = o;} T getOb() { return ob;} void show() { System.out.println(ob);} }
使用泛型类创建对象时,就要给它传递实际的参数,参数只能是引用类型。new Gen<Box>,相当于创建一个Box版本的Gen类型,所有T都会被替换成Box。new Gen<String>("Generics Test"); 相等于创建了String 版本的Gen。如果是基本类型,就要使用包装类,比如Integer。new Gen<Integer>(5),自动装箱和拆箱。在使用上,泛型类可以看做是普通类的工厂。泛型的一个关键点,不同版本之间并不兼容, 不可能把newGen<Box> 创建的对象赋值给new Gen<String> 创建的对象(Generic Types Differ Based on Their Type Arguments )。
泛型的类型可以有界。指定类型参数时,创建一个上限,所有类型参数都必须是其子类。<T extends superclass>
class Stats<T extends Number> { T[] nums; Stats (T[] o) { nums = o; } double average() { double sum = 0.0; for (int i = 0; i < nums.length; i++) { sum += nums[i].doubleValue(); } return sum / nums.length; } }
如果限定的类型是多个,要用& 连接起来,T extends Comparable & Serializable, 不过,这多个限定类型中最多有一个类类型,可以有多个接口类型。类类型必须放到第一个位置。
通配符,在一个泛型类中声明一个可以接收任意版本的该泛型类的对象,使用通配符。
boolean isSaveAvg(Stats<?> ob) { if(average() == ob.average()) { return true; } return false; }
因为任意一个版本的泛型类的对象都有average()方法,It is important to understand that the wildcard does not affect what type of Stats objects can be created. This is governed by the extends clause in the Stats declaration. The wildcard simply matches any valid Stats object. bounded wildcard <? extend Stats>, 当使用通配符时,只能声明变量,也就是它只负责匹配创建好的对象,能不能赋值给这个变量,创建对象的控制类型在类声明处。
方法也可以是泛型:在一个普通类中也可以创建泛型方法,类型参数放到方法的返回值前面。
class GenMethDemo { static <T extends Comparable<T>, V extends T> boolean isIn(T x, V[] y) { for (int i = 0; i < y.length; i++) { if (x.equals(y[i])) return true; } return false; } } public class Test { public static void main(String[] args) { Integer[] nums = { 1, 3, 5 }; if (GenMethDemo.isIn(3, nums)) { System.out.println("2 is in number"); } } }
当调用泛型方法时,并没有指定类型,和普通方法一样使用,这是因为,根据传递的参数,可以推断出类型。
泛型接口和类的声明一样,
interface MinMax<T extends Comparable<T>> { T min(); T max(); }
class Myclass<T extends Comparable<T>> implements MinMax<T> { }
通常情况下,如果一个类实现泛型接口,这个类必须是泛型,至少它要有一个类型参数,这样才能传给接口。In general, if a class implements a generic interface, then that class must also be generic, at least to the extent that it takes a type parameter that is passed to the interface. class MyClass implements MinMax<T> 是错的,因为MyClass 没有声明一个类型参数,所以没有一种方法,给MinMax 接口传递一个类型参数。当然,如果一个类实现某个特定类型的泛型接口,比如,class MyClass implements MinMax<Integer> ,实现类没有必要泛型了。
泛型的继承:一个泛型类可以是父类,也可以是子类。当一个父类是泛型时,所有子类都必要是泛型,这样才能把类型传递给父类。in a generic hierarchy, any type arguments needed by a generic superclass must be passed up the hierarchy by all subclasses.
// 泛型父类 class Gen<T> { T ob; Gen(T o) { ob = o; } T getOb() { return ob; } } // 泛型子类 class Gen2<T> extends Gen<T> { Gen2(T o) { super(o); } }
Gen2 继承泛型类Gen,Gen2的声明方式是 class Gen<T> extends Gen<T> {} ,Gen2中声明的T也会传递给Gen。比如 Gen2<Integer> num = new Gen2<Integer>(100), 把Integer类型作为 类型参数传递给了Gen,因此,在Gen中的ob 也是Integer类型。 需要注意的是Gen2 本身没有用到T,除了用来支持Gen父类。即使子类自己不是泛型,它也必须声明类型参数,因为是父类要求的。Thus, even if a subclass of a generic superclass would otherwise not need to be generic, it still must specify the type parameter(s) required by its generic superclass.
泛型子类,完全可以继承非泛型类。
class NonGen { int num; NonGen(int i) { num = i; } int getNum() { return num; } } // 泛型子类 class Gen2<T> extends NonGen { T ob; Gen2(T o, int i) { super(i); ob = o; } T getOb() { return ob; } }
Java 实现泛型 是通过泛型的擦除。When your Java code is compiled, all generic type information is removed (erased). This means replacing type parameters with their bound type, which is Object if no explicit bound is specified, and then applying the appropriate casts (as determined by the type arguments) to maintain type compatibility with the types specified by the type arguments. The compiler also enforces this type compatibility. This approach to generics means that no type parameters exist at run time. They are simply a source-code mechanism.
Bridge Methods
Occasionally, the compiler will need to add a bridge method to a class to handle situations in which the type erasure of an overriding method in a subclass does not produce the same erasure as the method in the superclass. In this case, a method is generated that uses the type erasure of the superclass, and this method calls the method that has the type erasure specified by the subclass. Of course, bridge methods only occur at the bytecode level, are not seen by you, and are not available for your use.
class Gen<T> { T ob; Gen(T o) { ob = o; } T getOb() { return ob; } } // 泛型子类 class Gen2<T> extends Gen<String> { Gen2(String o) { super(o); } String getOb() { System.out.println("call String getobj()"); return ob; } }
Gen2 继承String 版本的Gen, 并复写了getObj,返回String。但由于泛型的擦除,Object getOb() {}

The inclusion of generics gives rise to another type of error that you must guard against: ambiguity. Ambiguity errors occur when erasure causes two seemingly distinct generic declarations to resolve to the same erased type, causing a conflict. Here is an example that involves method overloading:
class MyGenClass<T, V> { T ob1; V ob2; void set(T o) { ob1 = o; } void set(V o) { ob2 = o; } }
由于泛型擦除,set 变成不 void set(Object o) {}, 不用泛型来override, 最好方法定义不同的名字。
Java 虚拟机并没有泛型类型的对象,所有对象都属于普通类型。当编译时,所有类型擦除,用 它extends的类或Object来替代泛型T。
public class Pair<T> { private T first; public Pair(T first) { this.first = first; } public T getFirst() { return first;} public void setFirst(T first) { this.first = first;} }
编译后,
public class Pair{ private Object first; public Pair(Object first) { this.first = first; } public Object getFirst() { return first;} public void setFirst(Object first) { this.first = first;} }
成了一个普通类,和没有泛型之前的实现一样。程序中可能有 Pair<String> 或Pair<Integer>, 但泛型擦除后,它们都是普通Pair类。程序中调用泛型方法,类型已被擦除,编译器就会插入强制类型转换。
Pair<Employee> buddies = . . .; Employee buddy = buddies.getFirst(); // (Employee) buddies. getFirst
类型的擦除带来了复杂度,比如,DateInterval 类继承了Pair<LocalDate>,写代码时,可以看做Pair中的所有泛型都变成了LocalDate, 所以在DateInterval 类中,复写父类的setSecond方法,参数完成可以是LocalDate类型,来进行复写。使用的时候
class DateInterval extends Pair<LocalDate> { public void setFirst(LocalDate first) { if (first.compareTo(getFirst()) >= 0) super.setFirst(first); } }
但泛型擦除后,
class DateInterval extends Pair { public void setFirst(LocalDate first) { if (first.compareTo(getFirst()) >= 0) super.setFirst(first); } }
DateInterval类有了两个方法,
public void setFirst(Object first)// Pair父类泛型擦除 public void setFirst(LocalDate first) { }
DateInterval中的setSecond() 方法,并不是对父类Pair中setSecond()方法的复写,因为父类中的方法参数是Object类型,而子类DateInterval的setSecond方法,参数类型是LocalDate. 泛型擦除之后,没有多态了。如下调用方式就会有问题
var interval = new DateInterval(. . .); Pair pair = interval; pair.setFirst(aDate);
此时,pair.setFirst()调用的是父类的setFirst()方法,和我们的最初想法不一致。为了解决这个问题,编译器在子类中,又增加了一个方法,复写父类的setFirst() 方法。在复写的方法中调用子类的setFirst()方法。
class DateInterval extends Pair { public void setFirst(LocalDate first) { if (first.compareTo(getFirst()) >= 0) super.setFirst(First); } // 编译器生成的bridge method, 为了保持多态 public void setFirst(Object First) { setFirst((LocalDate)first); } }
由于泛型的擦除,Java中的泛型有很多限制,比如类型只能是类类型,不能是原始类型,所以要使用原始类型的包装类。运行query时也不能使用泛型。
if (a instanceof Pair<String>) // ERROR Pair<String> p = (Pair<String>) a; // warning--can only test that a is a Pair
getClass method always returns the raw type
Pair<String> stringPair = . . .; Pair<Employee> employeePair = . . .; if (stringPair.getClass() == employeePair.getClass()) // they are equal
不能创建参数化类型的数组。var table = new Pair<String>[10]; 因为类型擦除后,table 变成了 new Pair[] 类型, table[0] 可以添加new Pair<Employee>(),所以是错误的。 也不能实例化类型参数,比如 new T() , 因为泛型擦除后,变成了new Object(); 也不能构建泛型的数组 new T[100],
泛型通配符:通配符类型,类型参数允许变化。Pair<? extends Employee> 表示泛型Pair 的类型参数是Employee或它的的子类,比如Pari<Manager>
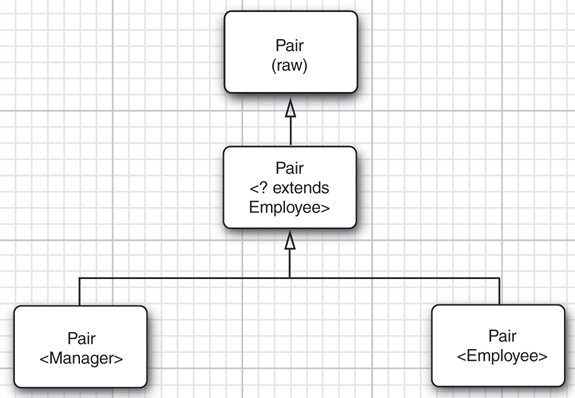
考虑下面的代码
var managerBuddies = new Pair<Manager>(ceo); Pair<? extends Employee> wildcardBuddies = managerBuddies; // OK wildcardBuddies.setFirst(lowlyEmployee); // compile-time error
调用setFirst方法,编译时报错。Pair<? extends Employee>相当于
? extends Employee getFirst() void setFirst(? extends Employee)

还有? super Manager, Pair<? super Manager> has methods that can be described as follows:
void setFirst(? super Manager) ? super Manager getFirst()
它能调用setFirst, 但不能调用getFirst

当Pair
public static void swap(Pair<?> p) { swapHelper(p); } public static <T> void swapHelper(Pair<T> p) { T t = p.getFirst(); p.setFirst(p.getSecond()); p.setSecond(t); }
这是泛型捕获。Pair<?> 表示pair类型的创建的任意类型。


Before moving on, it’s necessary to state that the Java compiler does not actually create different versions of Gen, or of any other generic class. Although it’s helpful to think in these terms, it is not what actually happens. Instead, the compiler removes all generic type information, substituting the necessary casts, to make your code behave as if a specific version of Gen were created. Thus, there is really only one version of Gen that actually exists in your program. The process of removing generic type information is called erasure, and we will return to this topic later in this chapter.
Lambda 表达式
lambda表达式:就像JS中的箭头函数,(a, b) ->a + b,只是一个表达式,没有名字,本身也没有办法调用。它要赋值一个变量,通过变量进行调用。变量是什么类型?函数接口的概念。函数接口就是只有一个抽象方法的接口,lambda表达式,也是一个方法,一一对应,函数接口方法也正好定义了lambda函数的参数类型和返回值。函数接口声明的变量,直接调用接口的方法,就相当于调用lambda表达式。一个lambda表达式能赋值给一个函数接口的变量,就是因为,lambda表达式中参数和返回值,正好和接口中定义的方法的返回值和参数类型一模一样。,在Java中,定义一个功能是用的接口。因此可以定义一个接口,用来描述这个lambda实现的功能。 有了接口,也就可以声明变量,可以把Lambda赋值给这个变量。同时,接口也定义了方法名,Lambda 实现的方法名,变量.方法名,就可以调用了这个Lambda. 要注意了是Lambda 只是实现了一个功能,所以接口中只能定义一个抽象方法。赋值给这个变量,决定了这个Lambda表达式的一切。
如果一个lambda的body 中,只是一个对象的方法的调用,那个这个lambda 可以简写成函数的引用。
(x) -> {System.out.print(x)} 这个lambda的body中, 只有一个对象System.out的print方法的调用, 因此可以写成
System.out::print。 方法引用只是Lambda表达式的简写,只是格式上的简写而已,永运都是先有Lambda表达式,再有方法引用。
其实方法的调用还有一种情况,参数作为主体,调用一个方法。比如 x -> x.trim() 这时方法引用简写成类::trim().
一个lambda表达式的参数是固定的,因为这是在接口中固定好的。但在参数怎么用,那是实现的事情,也就是lambda 中body决定的。我们可以把所有的参数都传递给一个方法。Math.pow(a, b). 也可以把第一个参数作为对象,调用一个方法,方法中的参数接受第个参数。(x, y) -> x.compareTo(y). 既然有两种情况,肯定就明两种简写:,就是方法,方法也分为对象的方法或静态方法:
Obj::实例方法名: 类::静态方法
一个方法对象调用另一个方法,类::实例方法名。 方法引用怎么简写:完全取决于labmda 函数,函数体中怎么使用这个方法。
构造函数可以看做是静态方法。
泛型函数接口,
interface Somefunc<T> { T func(T t); }
使用泛型接口,声明变量的时候,要指定类型,那么接口中方法的类型,也就确定了,就可以写一个lambda表达式,赋值给它。
public class Test { public static void main(String[] args) { Somefunc<Integer> identify = i -> i; System.out.println(identify.func(2)); } }
lambda 表达式都是定义在方法中,在lambda表达式中,可以获取到包含它的类的属性(包括静态属性),也可以使用this来引用包含它的类的实例对象,因此在lambda表达式中,能够get和set包含它的类的属性,并能调用方法。lambda表达式,甚至可以获取到包含它的方法中定义的变量(局部变量),但不能修改,此时,这个变量是effectively final。effectively final变量 赋值之后,不能修改。在包含lambda 表达式的方法中定义的局部变量,一旦被lambda表达式使用,它就是effectively final,不能再被修改了(无论在lambda表达式内,还是外),这称为变量捕获。
interface Func{ int func(int n); } public class Test { public static void main(String[] args) { int num = 10; Func sum = (n) -> { int v = num + n; //只是使用 // num++ 不能修改 return v; }; // 也不能修改, 因为effectively final // num = 9 } }
当lambda表达式的方法体是一个方法的调用时,可以把方法的调用转化成方法引用,
interface Func{ void print(Object o); } public class Test { public static void main(String[] args) { Func p = o -> System.out.println(o); p.print("ok"); } }
o -> System.out.println(o); 方法体就是调用了一下System.out方法的println方法,再也没有做什么了。转化为方法引用:System.out::println, 当Java在执行的时候,自动转化成对应的lambda表达式。
interface Func{ void print(Object o); } public class Test { public static void main(String[] args) { Func p = System.out::println; p.print("ok"); } }
有一种特殊的情况要注意,lamdba方法体中方法的调用是由参数发起的,参数是一个对象,调用了它身上的方法,比如 (File file)-> file.isHidden(), 再比如lambda表达式接受两个参数,方法体是一个参数调用一个方法,方法用到了第二个参数,整个lambda表达式的方法体还是一个函数调用
interface Func { String getSubString(String s, int n); } public class Test { public static void main(String[] args) { Func cFunc = (str, n) -> str.substring(n); String getString = cFunc.getSubString("abc", 1); System.out.println(getString); } }
(str, n) -> str.substring(n); 就是一个String 的对象,传递过来的任意一个String对象, 这种转化成方法引用,就要用类::方法, Func cFunc = String::substring; 方法引用,引用一个泛型方法,就要在方法引用的时候,指定泛型的类型。
interface Func<T> { int func(T[] vals, T v); } class MyArrayOps { static <T> int countMatching(T[] vals, T v) { int count = 0; for (int i = 0; i < vals.length; i++) { if (vals[i] == v) count++; } return count; } } public class Test { static <T> int myOp(Func<T> f, T[] vals, T v) { return f.func(vals, v); } public static void main(String[] args) { Integer[] vals = { 1, 2, 3 }; // MyArrayOps::<Integer>countMatching 中间的泛型可以去掉,可以推断出来 int count = myOp(MyArrayOps::<Integer>countMatching, vals, 3); System.out.println(count); } }
如果函数接口的方法中返回的是一个对象,方法引用就要用构造函数
interface Func { MyClass func(int n); } class MyClass { int value; MyClass(int v) { value = v; } } public class Test { public static void main(String[] args) { Func myClassCons = MyClass::new; // n -> new MyClass(n); MyClass mc = myClassCons.func(100); System.out.println(mc.value); } }
如果MyClass 是一个泛型,
interface Func<T> { MyClass<T> func(int n); } class MyClass<T> { T value; MyClass(T v) { value = v; } } public class Test { public static void main(String[] args) { Func<Integer> myClassCons = MyClass<Integer>::new; // n -> new MyClass<Integer>(n); MyClass mc = myClassCons.func(100); System.out.println(mc.value); } }
构造函数引用的方式,还可以用来创建数组,格式是 数组中元素类型[]::new
interface ArrayCreator<T> { T func(int n); } class MyClass { int value; MyClass(int v) { value = v; } } public class Test { public static void main(String[] args) { ArrayCreator<MyClass[]> myArrayCons = MyClass[]::new; MyClass[] a = myArrayCons.func(2); // 创建2个元素的数组,元素是myClass a[0] = new MyClass(90); System.out.println(a[0].value); } }
Specifically, many functional interfaces such as Comparator, Function, and Predicate provide methods that allow composition. combine several simple lambda expressions to build more complicated ones. 都是通过默认方法提供的。比如Comparator方法提供了comparing方法来指定用什么比较大小,它后还可以跟reversed() 反转排序,然后用thenComparing 再接一个比较方法。
import java.util.*; class Apple { private int weight = 0; private String color = ""; public Apple(int weight, String color) { this.weight = weight; this.color = color; } public Integer getWeight() { return weight; } public String getColor() { return color; } public String toString() { return "Apple{" + "color='" + color + '\'' + ", weight=" + weight + '}'; } } public class FilteringApples { public static void main(String... args) { List<Apple> inventory = Arrays.asList(new Apple(80, "green"), new Apple(155, "green"), new Apple(120, "red")); inventory.sort( Comparator.comparing(Apple::getWeight) .reversed() .thenComparing(Apple::getColor)); System.out.println(inventory); } }
先按苹果的重量进行排序(从小到大(reversed)),然后,如果两个苹果的重量相同,再按颜色进行排序。Predicate接口也有三个方法进行组合,negate() 对Predicate进行取反,and,or 进行连接。
public class FilteringApples { public static void main(String... args) { List<Apple> inventory = Arrays.asList(new Apple(80, "yellow"), new Apple(155, "green"), new Apple(120, "red")); Predicate<Apple> redApple = (apple) -> apple.getColor() == "red"; Predicate<Apple> notRedApple = redApple.negate().and(apple -> apple.getWeight() > 150) .or(apple -> apple.getColor() == "yellow"); var result = getNotRedApple(inventory, notRedApple); System.out.println(result); } static List<Apple> getNotRedApple(List<Apple> inventory, Predicate<Apple> p) { List<Apple> result = new ArrayList<>(); for(Apple apple: inventory){ if(p.test(apple)){ result.add(apple); } } return result; } }
Function接口,有两个方法,andThen和compose()。f = x -> x + 1; g = g-> g +1; h= f.andThen(g) 就是f的输出变成了g的输入, 相当于g(f(x)). h= f.compose(g), 相当于 f(g(x))
Lambda表达式有一个特殊的void 适配,如果lambda表达式方法体只有一句(statement),不管这一句返回什么,它都能赋值给返回值是void的函数接口,当然入参要一致。
// Consumer 是 T -> void, list.add 是 返回的boolean Consumer<String> b = (String s) -> list.add(s)
Streams
Streams:用声明式的方式操作集合数据,你只表达想要什么,而不用管实现方法,并且它还提供了并行处理的能力,不用写多线程代码,因为streams从源中获取到数据后,支持数据处理的方法(a sequence of elements from a source that supports data-processsing operations)。源就是集合,数组,甚至I/O,stream中也是源中的数据,只不过它支持 filter, map, reduce, find, match, sort, distinct(),limit(), skip等声明的操作。也就是说,操作stream,首先是从源中获取stream,从而获取到操作的数据,进行调用操作数据的方法。操作数据的方法分为两种, 一种是中间操作,比如filter过滤,sort排序,过滤完了,排序好了,什么都不做,那不白干了,至少要收集起来,供下次使用。收集起来,称为终止操作。流一定要提供终止操作,要不然不会执行,因为执行了也是白执行。中间操作有个好处,它们返回的也是流,可以链式调用。流的操作就变成了流水线的操作方法,最开始的中间操作,从流中取出一个数据,操作完了,然后流到下一个中间操作,直到终止操作,每一个中间操作每次只操作一个数据,那么终止操作也就变成了,只要不返回流的操作都是终止操作。
filter过滤,接收一个Predict, 流中的数据调用predcit中的test方法,只要返回true, 就留在流中,返回false,就从流中剔除。distinct()就是去重,如果流中元素是对象,要实现hashCode和equals方法。limit则是只取流中的多少个数据,skip则是跳过流中的多少个数据,如果跳过的太多,超边的流中的数据,则返回空流。
var nums = Arrays.asList(1, 2, 3, 4, 5, 6, 6, 3, 8, 10, 10); List<Integer> list = nums.stream().filter(i -> i % 2 == 0).distinct() .skip(2).limit(2) .collect(Collectors.toList());
如果takeWhile遇到一个不满足条件的元素,就会跳出检查,不再检查剩下的元素。TakeWhile操作符被调用时,会将source序列中的每一个元素作为参数顺序传入委托predicate中执行一遍,执行结果为true将会被添加到结果集中,结果为false,则立即跳出循环。dropWhile 正好相反
var nums = Arrays.asList(10, 1, 2, 3, 3, 3, 4, 5, 6); nums.stream().takeWhile(i -> i > 3) .forEach(System.out::println);
map转换,流中每一个元素都是对象,但只想取对象中的某个属性(比如name),经过转化,对象流转化成了字符串流,map返回转换后的流,所以map要接收一个函数,对流中的每一个元素进行转换
var nums = Arrays.asList("Hello", "World");
nums.stream().map(item -> item.length()).forEach(System.out::println);
flatMap方法接受一个函数, 函数的返回值必须是一个stream类型,flatMap方法最终会把所有返回的stream合并,形成一个流。数组工具类也有一个stream方法,把数组转化成每个元素的流。
String[] arrayOfwords = {"goodbye", "World"};
Stream<String> streamofWords = Arrays.stream(arrayOfwords);
import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class Test { public static void main(String[] args) { List<String> words = Arrays.asList("Hello", "World"); List<String> uniqueCharacters = words.stream() .map(word -> word.split("")) .flatMap(Arrays::stream) .distinct() .collect(Collectors.toList()); System.out.println(uniqueCharacters); } }
flatMap把给它的元素都转化成流,然后再把转化后流进行合并,形成一个流。再举一个例子
var num1 = Arrays.asList(1, 2, 3); var num2 = Arrays.asList(4, 5); var pairs = num1.stream(). flatMap(i -> num2.stream() .filter( j -> (i + j) % 3 ==0) .map(j -> new int[] {i, j}) ).collect(Collectors.toList()); for(int[] array: pairs) { System.out.println(Arrays.toString(array)); }
anyMatch,allMatch, noneMatch,findFirst, findAny。anyMatch : 只要有一个匹配就返回true,否则返回false,就像JS中的数组的some。allMatch,所有元素都匹配成功,就像JS中的数组的every, noneMatch 就是allMatch取反。findAny找到一个就可以,findFirst找到第一个,它们都返回Optional,可能有,也可能没有。为什么会有findFirst和 findAny? 因为并行处理。找到第一个元素,在并行处理上更为受限。如果只关心找到一个,就是findany,并行处理不太受限。Option是一个容器,它可能有值,也可能没有值,如果要从它里面获到数据,必须强制检查有没有。而如果返回null的时候,你可能不检查就直接从null中读取数据了,所以避免了空指针异常。
reduce:把多个值变成一个值,比如计算集合中元素的个数。
var stringList = Arrays.asList("Apple", "Orange"); int count = stringList.stream().map(item -> 1).reduce(0, (a, b) -> a + b);
为此stream 都有一个count方法
long count = stringList.stream().count();
基本数据类型stream,就是流中是基本数据类型,intStream,LongStream,DoubleStream,这主要解决计算时的自动装箱和拆箱,mapToInt, mapToDouble, mapToLong, 可以流转化成基本数据类型。
var stringList = Arrays.asList("Apple", "Orange"); Stream<Integer> length = stringList.stream().map(s -> s.length()); // 返回的Stream of Integer. // 如果要进行算术运算, Integer类型就要每次都自动拆箱成int类型。 int count = length.reduce(0, (a, b) -> a + b );
var stringList = Arrays.asList("Apple", "Orange"); IntStream length = stringList.stream().mapToInt(s -> s.length()); // 返回的Stream of int. int count = length.sum(); // int类型可以直接进行算术运算
对于三种基本类型的流,也提供了三种对应的OptionalInt,OptionalDouble, OptionalLong.
var stringList = Arrays.asList("Apple", "Orange"); OptionalInt max = stringList.stream().mapToInt(s -> s.length()).max();
创建Stream的更多的方法
Stream<String> streamStr = Stream.of("Modern", "Java", "In", "Action"); // 使有of方法 Stream<String> emptyStream = Stream.empty(); // empty()创建空流 // ofNullable 可以从空对象创建流 Stream<String> homeValueStream = Stream.ofNullable(System.getProperty("home")); int[] nums = {2, 3, 5}; IntStream numStream = Arrays.stream(nums); // 使用数组创建流 // java.nio.file.Files 的一些静态方法,返回流,比如Files.lines, 用流操作I/O try(Stream<String> lines = Files.lines(Path.of("data.text"))) { long uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" "))) .distinct().count(); } catch (IOException e) { throw new RuntimeException(e); }
再把int stream转换成对象stream,要调用box()或mapToObj。
IntStream.rangeClosed(1, 100).filter(i -> i % 3 == 0) .boxed() // 返回 Stream<Integer> .map(i -> new int[]{i}); IntStream.rangeClosed(1, 100).filter(i -> i % 3 == 0) .mapToObj(i -> new int[]{i});
Stream有一个collect()方法,把stream中的元素进行收集,到底收集到什么地方,是list中,还是map中,还是一个单一的值,是由传递给它的Collector接口的实现决定的。Collector接口定义了怎么从stream中收集数据,Collectors( java.util.stream.Collectors)提供了Collector接口的实现,比如Collectors.toList收集成list,对steam中的每一个元素进行操作,放到list中。更为一般意义上,只要想把stream中的所有元素组合成或合并到一个结果中,就可以使用collect()。
var nums = Stream.of(30, 10, 20, 50, 100); long howMany = nums.collect(Collectors.counting()); //求元素个数,.count() Optional<Integer> max = nums.collect(Collectors.maxBy((a, b) -> a - b)); int total = nums.collect(Collectors.summingInt((i) -> Integer.valueOf(i))); // 求和 // summarizingInt, summarizingDouble summarizingLong,
// 一次获取到sum,count。IntSummaryStatistics{count=5, sum=210, min=10, average=42.000000, max=100} IntSummaryStatistics numStat = nums.collect(Collectors.summarizingInt(i -> Integer.valueOf(i)));
// 字符串拼接, 调用流中每一个对象的toString
var strs = Stream.of("dish", "fish");
var strConcat = strs.collect(Collectors.joining(", "));
分组,主要确定分组的key,然后Java会自动把合适的数据与key相关联,所以返回是map,map的key,就是分组的key,map的value就是一个list,把key相关联的数据放到list中,怎么确定分组的key,Collectors.groupBy,接受一个lambda,参数是stream中的每一个元素,返回值就是分组的key。
var nums = Stream.of(30, 11, 25, 50, 99); Map<String, List<Integer>> group = nums.collect(Collectors.groupingBy(i -> i >= 50 ? "big": "small")); // {small=[30, 10, 20], big=[50, 100]}
如果想对分组的后数据,每一组的内容分别进行操作,groupby接受第二个参数,对组内的内容进行重新组装。
var nums = Stream.of(30, 11, 25, 50, 99); Map<String, List<Integer>> group = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.filtering(i -> i % 2 == 0, Collectors.toList()))); Map<String, Set<Boolean>> groupBool = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.mapping(i -> i % 2 == 0, Collectors.toSet())));
第二个参数也可以是另外一个groupby,层级分组
var nums = Stream.of(30, 11, 25, 50, 99); Map<String, Map<String, List<Integer>>> group = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.groupingBy(i -> i % 2 == 0 ? "even": "odd")));
第二个参数是任意的集合,比如计数
Map<String, Long> group = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.counting()));
每组里面的最大值,
var nums = Stream.of(30, 11, 25, 50, 99); Map<String, Optional<Integer>> group = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.maxBy((a, b) -> a -b )));
分组的时候,如果某个组内没有元素,这个组是不会显示到结果中的。把nums改成只有50, 99
var nums = Stream.of( 50, 99); Map<String, Optional<Integer>> group = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.maxBy((a, b) -> a - b ))); System.out.println(group);
输出{big=Optional[99]},结果只有big分组,没有small分组。返回Optional 意义不太,想要获到它里面的数据,使用collectioningAndThen进行转化
var nums = Stream.of(30, 11, 25, 50, 99); var group = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.collectingAndThen(Collectors.maxBy((a, b) -> a - b ), Optional::get) ) );
另外两个和group结合,是对 每一个group进行求和
var nums = Stream.of(30, 11, 25, 50, 99); var group = nums.collect( Collectors.groupingBy(i -> i >= 50 ? "big" : "small", Collectors.summingInt((a) -> a) ) );
对每一组元素进行转化。
var nums = Stream.of(30, 11, 25, 50, 99); var group = nums.collect( Collectors.groupingBy(i -> i % 2 == 0 ? "even" : "old", Collectors.mapping(integer -> { if(integer >= 30) return "big"; else return "small"; }, Collectors.toSet()) ) );
toSet方法,是转化成任意的set,可以指定转化成hashSet,变成Collectors.toCollection(HashSet::new)
Partitioning 是特殊的分组,它接受一个返回true或false的函数,把流最多分为两组,返回的map中,key是boolean值,value是流中的值。比如奇数和偶数。
var nums = Stream.of(30, 11, 25, 50, 99); Map<Boolean, List<Integer>> partitionedGroup = nums.collect( Collectors.partitioningBy(i -> i % 2 == 0));
partitionedGroup.get(true)就能获取到所有的偶数。
The Collector 接口
public interface Collector<T, A, R> { Supplier<A> supplier(); BiConsumer<A, T> accumulator(); Function<A, R> finisher(); BinaryOperator<A> combiner(); Set<Characteristics> characteristics(); }
T is the generic type of the items in the stream to be collected.
A is the type of the accumulator, the object on which the partial result will be
accumulated during the collection process.
R is the type of the object (typically, but not always, the collection) resulting
from the collect operation.
For instance, you could implement a ToListCollector<T> class that gathers all the
elements of a Stream<T> into a List<T> having the following signature
public class ToListCollector<T> implements Collector<T, List<T>, List<T>>
where, as we’ll clarify shortly, the object used for the accumulation process will also be
the final result of the collection process.
Inerface 5个方法:1,supplier: return a Supplier of an empty accumulator
public Supplier<List<T>> supplier() { return () -> new ArrayList<T>(); }
2, accumulator method returns the function that performs the reduction operation. The function returns void because the accumulator is modified in place, meaning that its internal state is changed by the function application to reflect the effect of the traversed element
public BiConsumer<List<T>, T> accumulator() { return (list, item) -> list.add(item);
The finisher method has to return a function that’s invoked at the end of the accumulation process, after having completely traversed the stream, in order to transform the accumulator object into the final result of the whole collection operation. Often, as in the case of the ToListCollector , the accumulator object already coincides with the final expected result. As a consequence, there’s no need to perform a transformation, so the finisher method has to return the identity function:
public Function<List<T>, List<T>> finisher() { return Function.identity(); }
The combiner method, return a function that defines how the accumulators resulting from the reduction of different subparts of the stream are combined when the subparts are processed in parallel. In the toList case, the implementation of this method is simple; add the list containing the items gathered from the second subpart of the stream to the end of the list obtained when traversing the first subpart:
public BinaryOperator<List<T>> combiner() { return (list1, list2) -> { list1.addAll(list2); return list1; } }
The last method, characteristics , returns an immutable set of Characteristics ,
defining the behavior of the collector—in particular providing hints about whether
the stream can be reduced in parallel and which optimizations are valid when doing
so. Characteristics is an enumeration containing three items:
UNORDERED —The result of the reduction isn’t affected by the order in which the
items in the stream are traversed and accumulated.
CONCURRENT —The accumulator function can be called concurrently from mul-
tiple threads, and then this collector can perform a parallel reduction of the
stream. If the collector isn’t also flagged as UNORDERED , it can perform a parallel
reduction only when it’s applied to an unordered data source.
IDENTITY_FINISH —This indicates the function returned by the finisher method
is the identity one, and its application can be omitted. In this case, the accumu-
lator object is directly used as the final result of the reduction process. This also
implies that it’s safe to do an unchecked cast from the accumulator A to the
result R .
The ToListCollector developed so far is IDENTITY_FINISH , because the List used to
accumulate the elements in the stream is already the expected final result and doesn’t
need any further transformation, but it isn’t UNORDERED because if you apply it to an
ordered stream you want this ordering to be preserved in the resulting List . Finally,
it’s CONCURRENT , but following what we just said, the stream will be processed in paral-
lel only if its underlying data source is unordered.
A parallel stream is a stream that splits its elements into multiple chunks, processing each chunk with a different thread. 在一个顺序流上调用parallel() 把它变成并行流,并行流,就是.parallel() 方法后面所有的操作都变成并行的。
public long parallelSum(long n) { return Stream.iterate(1L, i -> i + 1) .limit(n) .parallel() .reduce(0L, Long::sum); }
.reduce方法是并行的。在一个并行流的基础上,调用sequential(),再变成一个顺序流,它后面的方法是顺序执行的。
Note that you might think that by combining these
two methods you could achieve finer-grained control over which operations you want
to perform in parallel and which ones sequentially while traversing the stream. For
example, you could do something like the following:
stream.parallel()
.filter(...)
.sequential()
.map(...)
.parallel()
.reduce();
But the last call to parallel or sequential wins and affects the pipeline globally. In
this example, the pipeline will be executed in parallel because that’s the last call in the
pipeline.
Parallel streams internally use the default ForkJoinPool,which by default has as many threads as you have processors, as returned by Runtime.getRuntime().available-Processors()
Measuring stream performance: Java Microbenchmark Harness (JMH), 有时候并行流,并不比序列流快,这和流的产生方式有关,Stream.iterate is difficult to divide into independent chunks to execute in parallel. 也就是说some stream operations are more parallelizable than others.
the whole list of numbers isn’t available at the beginning of the reduction process, making it impossible to efficiently partition the stream in chunks to be processed in parallel. By flagging the stream as parallel, you’re adding the overhead of allocating each sum operation on a different thread to the sequential processing.
This demonstrates how parallel programming can be tricky and sometimes coun-
terintuitive. When misused (for example, using an operation that’s not parallel-
friendly, like iterate ) it can worsen the overall performance of your programs, so it’s
mandatory to understand what happens behind the scenes when you invoke that
apparently magic parallel method.
Nevertheless, keep in mind that parallelization doesn’t come for free. The paral-
lelization process itself requires you to recursively partition the stream, assign the
reduction operation of each substream to a different thread, and then combine the
results of these operations in a single value. But moving data between multiple cores is
also more expensive than you might expect, so it’s important that work to be done in
parallel on another core takes longer than the time required to transfer the data from
one core to another. In general, there are many cases where it isn’t possible or conve-
nient to use parallelization. But before you use a parallel stream to make your code
faster, you have to be sure that you’re using it correctly; it’s not helpful to produce a
result in less time if the result will be wrong. Let’s look at a common pitfall, 如果并行,就不能改变共享数据


A record is designed to provide an efficient, easy-to-use way to hold a group of values.
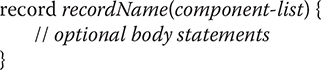
notice that the body is optional. This is made possible because the compiler will automatically provide the elements necessary to store the data; construct a record; create getter methods to access the data; and override toString( ), equals( ), and hashCode( ) inherited from Object.
record Employee(String name, int idNum) {}
存储 Employee 的姓名和 idNum。Employee emp = new Employee("Doe, John", 1047); 可以通过name()和 idNum()来获取到值。emp.name(),emp.idNum()
A key point about a record is that its data is held in private final fields and only getter methods are provided. Thus, the data that a record holds is immutable. In other words, once you construct a record, its contents cannot be changed. However, if a record holds a reference to some object, you can make a change to that object, but you cannot change to what object the reference in the record refers. Thus, in Java terms, records are said to be shallowly immutable.
可以自定义构造函数,构造函数分为两种:Canonical Constructor 和non-canonical。 Canonical Constructor: 构造函数的参数名和类型必须与record 中声明的类型一样,这是因为参数名自动链接到自动创建 的字段和get方法。还有就是所有参数都必须在构造函数中初始化。
record Employee(String name, int idNumb) { public Employee(String name, int idNumb) { this.name = name.trim(); this.idNumb = idNumb; } }
简单写法
record Employee(String name, int idNum) { public Employee { name = name.trim(); } }
Non-canonical Constructor: The key requirement is that any non-canonical constructor must first call another constructor in the record via this. The constructor invoked will often be the canonical constructor. Doing this ultimately ensures that all fields are assigned.
record Employee(String name, int idNum) { static int pedningID = -1; public Employee { name = name.trim(); } public Employee(String name) { this(name, pedningID); } }
As explained earlier, instance fields are not allowed in a record declaration, but a static field is legal. 可以添加get方法,比如:从name中截取last name。
record Employee(String name, int idNum) { static int pedningID = -1; public Employee { name = name.trim(); } public Employee(String name) { this(name, pedningID); } String lastName() { return name.substring(0, name.trim().indexOf(',')); } }
模式匹配 instanceof: objref instanceof type pattern-var , 如果objref 是type类型, 就会创建 pattern-var ,把objref 赋值给pattern-var , 如果不是type,就不会创建pattern-var。
public class Test { public static void main(String[] args) { Number myOb = Integer.valueOf(9); // Number 类 if(myOb instanceof Integer iObj) { // myObj可以强制转化Integer,iObj创建 System.out.println("iObj: " + iObj); } } }
相当于
public class Test { public static void main(String[] args) { Number myOb = Integer.valueOf(9); // Number 类 if (myOb instanceof Integer) { Integer iObj = (Integer) myOb; System.out.println("iObj refers to an integer: " + iObj); } } }
switch 加强:1,case 常量列表;
public class Test { public static void main(String[] args) { int priorityLevel; int eventCode = 6000; switch (eventCode) { case 1000, 2000, 3000: priorityLevel = 1; break; case 4000, 5000, 6000: priorityLevel = 2; break; default: priorityLevel = 0; } System.out.println(priorityLevel); } }
switch 表达式,它可以返回一个值,就是每一个case yield一个值。
public class Test { public static void main(String[] args) { int eventCode = 6000; int priorityLevel = switch (eventCode) { case 1000, 2000, 3000: yield 1; case 4000, 5000, 6000: yield 2; default: yield 0; } System.out.println(priorityLevel); } }
case中使用箭头:
public class Test { public static void main(String[] args) { int eventCode = 6000; int priorityLevel = switch (eventCode) { case 1000, 2000, 3000 -> 1; case 4000, 5000, 6000 -> { System.out.println("Warning"); yield 2; } default -> 0; }; System.out.println(priorityLevel); } }

NIO 有两个基本元素:buffers和channels。buffer存储数据,channel代表一个打开 连接,比如连接文件或socket. 使用NIO,就是获取一个channel代表I/O设备和buffer 来存储数据,然后操作buffer,写入或读取数据。Buffer类定义了buffer的所有核心功能:当前位置,上限(limit)和capacity(容量)。当前位置就是下一次读或写要发生的地方,它的移动是由读或写操作完成。limit 就是超过了buffer的最后一个有效位置,容量就是buffer的大小,通常 limit和capacity相等 。所有buffer 都有get或put方法,用于读写。FileInputStream和FileOutputStream,Socket都支持Channel,调用getChannel() 返回 一个channel,有read和write方法来操作I/O. charset,decoder, encoder用来转换字节和字符。Selector 用来操作多个channel来操作I/O,主要用于socket channel. Path(java.nio.file包下)代表文件路径。files用来操作文件。
用channel来读取文件, 就是创建一个channel关联文件,然后channel 的read方法,把文件读到buffer中,buffer也要提前创建,然后从buffer中读取内容。写文件也是一样,创建一个channel 来关联写文件, write 接收的是buffer, 把bffer中的内容写到文件。
In the NIO library, all data is handled with buffers. When data is read, it is read directly into a buffer. When data is written, it is written into a buffer. Anytime you access data in NIO, you are pulling it out of the buffer.
Reading and writing are the fundamental processes of I/O. Reading from a channel is simple: we simply create a buffer and then ask a channel to read data into it. Writing is also fairly simply: we create a buffer, fill it with data, and then ask a channel to write from it.
import java.nio.*;
import java.nio.file.*; public class Test { public static void main(String[] args) { Path filePath = Path.of("test.txt"); Path writePath = Path.of("destination.txt"); // 创建 读写的channel try (SeekableByteChannel readChannel = Files.newByteChannel(filePath); FileChannel writeChannel = (FileChannel) Files.newByteChannel(writePath, StandardOpenOption.WRITE, StandardOpenOption.CREATE)) { // 创建 buffer 来接受数据 ByteBuffer mBuf = MappedByteBuffer.allocate(128); while (true) { // 在读之前,重置buffer,新的数据可以读进来, mBuf.clear(); int r = readChannel.read(mBuf); // 如果读取不到文件内容,返回-1 if(r == -1) { break; } // 在写之前,复置buffer的postion到buffer的开始位置,从而让新读取到的数据写入到其它地方 mBuf.flip(); writeChannel.write(mBuf); } } catch (Exception e) { System.out.println("I/O Error"); } } }
NIO 下的Files直接提供了copy的方法,
import java.nio.file.*; public class Test { public static void main(String[] args) { Path filePath = Path.of("test.txt"); Path writePath = Path.of("destination.txt"); try { Files.copy(filePath, writePath, StandardCopyOption.REPLACE_EXISTING); } catch (Exception e) { System.out.println("I/O ERRor" + e); } } }
使用NIO,也可以打开一个I/O stream,使用文件流的方式来操作文件。Files.newInputStream,和Files.newOutputStream.
public class Test { public static void main(String[] args) { Path filePath = Path.of("test.txt"); try(var fin = Files.newInputStream(filePath)) { while (true) { int i = fin.read(); if(i == -1) break; System.out.println((char)i); } } catch (Exception e) { System.out.println("I/O ERRor" + e); } } }
集合
JDK9中,List, Set, Map增加了.of工厂方法,用来创建简单的集合,不过,它们都是不可变的。
List<String> friends = List.of("Raphael", "Olivia"); Set<String> books = Set.of("Java"); Map<String, Integer> ageWithFriends = Map.of("Raphael", 30, "Olivia", 20); // k,v Map<String, Integer> AnotherAgeWithFriends = Map.ofEntries( Map.entry("Raphael", 30), Map.entry("Olivia", 20) );
JDK8,List增加了removeIf, replaceAll和sort方法,改变原List。Set也增加removeIf。 当用增强for循环去迭代集合的时候,是不能执行删除操作的,
var list = new ArrayList<String>(); list.addAll(List.of("a", "b", "c", "d")); for (String str : list) { if(str.equals("a")) { list.remove(str); // 从list删除元素 } }
上面的代码会报错,因为在for循环底层使用的是Iterator对象
var list = new ArrayList<String>(); list.addAll(List.of("a", "b", "c", "d")); var iterator = list.iterator(); while (iterator.hasNext()) { var str = iterator.next(); if(str.equals("a")) { list.remove(str); } }
两个分别的对象来操作集合,一个是迭代器对象,使用next和hasNext 查询集合,一个是集合本身,它调用remove进行删除元素,最终两个对象的状态不同步。为了解决这个问题,使用迭代器remove方法, list.remove(str)改成iterator.remove(); 现在可以使用removeIf了
var list = new ArrayList<String>(List.of("a", "b", "c", "d")); list.removeIf(item -> item.equals("a"));
replaceAll则是替换所有元素
var list = new ArrayList<String>(List.of("a", "b", "c", "d")); list.replaceAll(item -> item + " word");
Map增加了forEach迭代方式,用来比较的Entry.ComparingByValue和Entry.ComparingByKey,
Map<String, Integer> ageWithFriends = Map.of("Raphael", 30, "Olivia", 20); ageWithFriends.forEach((friend, age) -> System.out.println(friend + " " + age)); ageWithFriends.entrySet().stream().sorted(Map.Entry.comparingByKey()).forEachOrdered(System.out::println);
Map 的getOrDefault, 当get一个key的时候,如果没有这个key,会返回null,要判断null,getOrDefault则是提供key的默认值,如果get的key存在,则返回key对应value的值,如果get的key不存在,则返回默认值,需要注意的是默认值都会进行计算,不是短路操作(只有不存在,才计算)。
ageWithFriends.getOrDefault("Thibuat", 50); // 输出50
如果key不存在或者key对应的value是null,就执行某个计算,把计算结果作为value存到map中,并把value返回,如果key存在,则返回value,使用computeIfAbsent,还有computeIfPresnt则和它相反,compute则是纯计算。
var map = new HashMap<String, List<String >>(); var list = map.computeIfAbsent("Raphael", (name) -> new ArrayList<>()); list.add("Star War");
remove(key, value), 删除某个特定key的特定的value,如要不存在,就什么都不做。
var map = new HashMap<String, String>(); map.put("Jason", "Star"); map.remove("Jason", "Star");
ReplaceAll,Replace
var map = new HashMap<String, String>(); map.put("Jason", "Star"); map.replaceAll((name, movie) -> movie.toUpperCase());
merge()
var family = Map.ofEntries(Map.entry("Teo", "star War"), Map.entry("christina", "James Bond")); var friends = Map.ofEntries(Map.entry("Ra", "Star War"), Map.entry("christina", "James Bond")); var everyone = new HashMap<String, String>(family); friends.forEach((key, value) -> { everyone.merge(key, value, (movie1, movie2) -> movie1 + " & " + movie2); // 后面的函数相当于value的reduce });
Option: 如果用null来代表值的缺失,有很大的问题,每次都需要判断是不是null,不是null,才开始操作,如果忘记check,就会出现空指针异常。用什么来代表值的缺失和存在?Optional。声明一个变量是Optional,就表示它可能不存在值,可能不会给它赋值。如果声明一个引用类型的变量,允许给它赋值null,那就需要记得它可能为null,要进行判断,null可以赋值给任意类型。有了optional之后,如果一个引量没有用opitonal声明,那它一定是有值的,不会是null,如果程序中把null赋值给它,那就是程序有问题了。如果是optional 要取里面的值 ,需要使用方法。以前的时候,当声有一个引用类型的变量时,你不知道它的值是不是为null,是
创建Opitonal对象
Optional<String> emptyName = Optional.empty(); // 创建空的optional对象 Optional<String> name = Optional.of("book"); // 创建非空的optional对象,of的参数不能是null,否则报错 Optional<String> optName = Optional.ofNullable(null); // 可能包含null的Optional对象。
从Optional中获取值:Optional有一个map方法,如果Optinal有值,就调用它的参数(函数),如果Optional没有值,就不调用。flatmap则不会对它的参数返回值做Optional的包装,直接返回。还有get, orElse, ifPresent等。除了map还有filter方法
时间和日期(java.time)
时光如箭,我们可以轻松地设定一个起点,并以秒为单位向前和向后计数。 那么为什么处理时间这么难呢? 问题在于人。 如果我们能告诉对方:“请在1523793600秒与我会面,不要迟到!”一切都会变得很容易。 但我们希望时间与日光和季节相关。 这就是事情变得复杂的地方。In Java, an Instant represents a point on the time line, The static method call Instant.now() gives the current instant. You can compare two instants with the equals and compareTo methods in the usual way, so you can use instants as timestamps. To find out the difference between two instants, use the static method Duration.between. A Duration is the amount of time between two instants. You can get the length of a Duration in conventional units by calling toNanos, toMillis, toSeconds, toMinutes, toHours, or toDays.
nstant start = Instant.now(); for (int i = 0; i < 100000000; i++) { System.out.println(i); } Instant end = Instant.now(); Duration timeElapsed = Duration.between(start, end); long millis = timeElapsed.toSeconds(); // 建议用getSeconds,不是toSeconds System.out.printf("%d milliseconds\n", millis);
Now let us turn from absolute time to human time, There are two kinds of human time in the Java API, local date/time and zoned time. An example of a local date is June 14, 1903. Since that date has neither a time of day nor time zone information, it does not correspond to a precise instant of time. In contrast, July 16, 1969, 09:32:00 EDT (the launch of Apollo 11) is a zoned date/time, representing a precise instant on the time line.
There are many calculations where time zones are not required, and in some cases they can even be a hindrance. Suppose you schedule a meeting every week at 10:00. If you add 7 days (that is, 7 × 24 × 60 × 60 seconds) to the last zoned time, and you happen to cross the daylight savings time boundary, the meeting will be an hour too early or too late!
For that reason, the API designers recommend that you do not use zoned time unless you really want to represent absolute time instances. Birthdays, holidays, schedule times, and so on are usually best represented as local dates or times. LocalDate( 年月日),使用now或of构建对象
LocalDate date = LocalDate.of(2017, 9, 21); // 2017-09-21 LocalDate today = LocalDate.now();
Recall that the difference between two time instants is a Duration. The equivalent for local dates is a Period, which expresses a number of elapsed years, months, or days. The until method yields the difference between two local dates. For example,
LocalDate independenceDay = LocalDate.of(2018, Month.JULY, 4); LocalDate christmas = LocalDate.of(2018, Month.DECEMBER, 25); System.out.println("Until christmas: " + independenceDay.until(christmas)); // P5M21D period of 5 months and 21 days System.out.println("Until christmas: " + independenceDay.until(christmas, ChronoUnit.DAYS)); // 174 days
LocalTime(时分秒),比如15:30:00
LocalTime time = LocalTime.of(13, 45, 20);
The plus and minus operations wrap around a 24-hour day.
LocalTime bedtime = LocalTime.of(22, 30); // or LocalTime.of(22, 30, 0) LocalTime wakeup = bedtime.plusHours(8); // wakeup is 6:30:00
LocalDateTime( 年月日,时分秒)
LocalDateTime dt1 = LocalDateTime.of(2017, Month.SEPTEMBER, 21, 13, 45, 20);
格式花输出和解析
LocalDate churchsBirthday = LocalDate.parse("1903-06-14"); // parse可以使用字符串创建 // DateTimeFormatter formatter = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG); 需要时区 var formatter = DateTimeFormatter.ofPattern("E yyyy-MM-dd"); String formatted = formatter.format(churchsBirthday); System.out.println(formatted);
As humans, we’re used to thinking of dates and time in terms of weeks, days, hours,
and minutes. Nonetheless, this representation isn’t easy for a computer to deal with.
From a machine point of view, the most natural format to model time is a single large
number representing a point on a continuous timeline. This approach is used by the
new java.time.Instant class, which represents the number of seconds passed since
the Unix epoch time, set by convention to midnight of January 1, 1970 UTC.
Date 提供了plus 和minus方法,比如plusWeeks(1)
formate 格式,返回是字符串
LocalDate date = LocalDate.of(2014, 3, 18); String s1 = date.format(DateTimeFormatter.BASIC_ISO_DATE); // "20140318" String s2 = date.format(DateTimeFormatter.ISO_LOCAL_DATE); // "2014-03-18"
解析String 到时间
LocalDate date1 = LocalDate.parse("20140318", DateTimeFormatter.BASIC_ISO_DATE); LocalDate date2 = LocalDate.parse("2014-03-18", DateTimeFormatter.ISO_LOCAL_DATE);
自定义格式
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("dd/MM/yyyy"); LocalDate date1 = LocalDate.of(2014, 3, 18); String formattedDate = date1.format(formatter); LocalDate date2 = LocalDate.parse(formattedDate, formatter);
新的时间和日期API 和旧的java.util.Date, java.sql.Date/Time/Timestamp, java.time.Instant replaces java.util.Date 和java.time.LocalDate replaces java.sql.Date。You may exchange java.time objects directly with your database. Use a JDBC driver compliant with JDBC 4.2 or later. No need for strings, no need for java.sql.* classes.
异步:CompletableFutures
1, 实现一个异步的api:方法返回一个Future,Future的泛型就是方法返回值的类型。
public class Shop { public Future<Double> getPriceAsync(String product) { // The supplyAsync method accepts a Supplier as argument and returns a Completable- //Future that will be asynchronously completed with the value obtained by invoking //that Supplier return CompletableFuture.supplyAsync(() -> calculatePrice(product)); } public static void delay() { try { Thread.sleep(1000L); } catch (InterruptedException e) { throw new RuntimeException(e); } } public double calculatePrice(String product) { delay(); return Math.random() * product.charAt(0) + product.charAt(1); } }
2, 异步的方式消费同步代码。
public class Shop { private String name; public Shop(String name) { this.name = name; } public double getPrice(String product) { return calculatePrice(product); } public static void delay() { try { Thread.sleep(1000L); } catch (InterruptedException e) { throw new RuntimeException(e); } } public double calculatePrice(String product) { delay(); return Math.random() * product.charAt(0) + product.charAt(1); } public String getName() { return this.name; } public static void main(String[] args) { List<Shop> shops = List.of(new Shop("BestPrice"), new Shop("LetsSaveBig"), new Shop("MyFavoriteShop"), new Shop("BuyItAll")); List<CompletableFuture<String>> priceFutures = shops.stream().map( shop -> CompletableFuture.supplyAsync(() -> shop.getName() + shop.getPrice(shop.getName())) ).collect(Collectors.toList()); // join, get 都是从异步中获取数据,如果有,就获取,如果没有就等待阻塞。 var result = priceFutures.stream().map(CompletableFuture::join).collect(Collectors.toList()); System.out.println(result); } }
异步也是使用的线程池,线程池默认有Runtime.getRuntime().availableProcessors 个线程
pipeline异步操作 thenApply 后面跟的是同步操作,thenCompose后面跟的是异步操作 wait for the completion of CompletableFuture s and extract their values by using join , 还有一个 thenComposeAsync。 thenCompose 是和调用它的CompletableFuture 在同一个线程中执行,thenComposeAsync是和调用它的CompletableFuture 在不同的线程执行,如要两个CompletableFuture 是依赖关系,thenCompose 好一点,因为不用上下文切换。
thenCombine, 两个没有关系的异步操作合在一起,它接收两个参数,第二个参数是对两个不相关异步返回的数据怎样进行合并,合并的操作是和thenCombine的调用者在同一个线程,如果想在另外一个线程做合并操作,需要使用 thenCombineAsync
Future<Double> futurePriceInUSD = CompletableFuture.supplyAsync(() -> shop.getPrice(product)) .thenCombine( CompletableFuture.supplyAsync( () -> exchangeService.getRate(Money.EUR, Money.USD)), (price, rate) -> price * rate ));

reacting to the completion of a CompletableFuture instead of invoking get or join on it and thereby remaining blocked until the CompletableFuture itself completes. f.thenAccept
CompletableFuture[] futures = findPricesStream("myPhone")
.map(f -> f.thenAccept(System.out::println))
.toArray(size -> new CompletableFuture[size]);
CompletableFuture.allOf(futures).join();
allof 相当于js中的promise.All,还有anyof,相当于promise.race
Log:在每一个类中都可以定义一个Logger, 调用Looger的getLogger方法,参数就是包名或全限定类句,如果是包名,在它上面的调置的日志level 信息会被继承
private static final Logger myLogger = Logger.getLogger("com.mycompany.myapp");
Logger 有7个level, SEVER, WARNING, INFO, CONFIG, FINE, FINER, FINEST, 默认情况下,只有 前三种leleve会被记录下来,不过,可以设置level, 调用setLevel方法,比如 myLogger.setLevel(Level.FINE); 调用 .warning 或 .fine 等对应的level的方法,来记录日志,比如 myLogger.warning("error")
Java 序列化和反序列化:在Java 中,如果想要序列化和反序列化,类必须实现Serializable,然后ObjectOutputStream 和ObjectInputStream。Behind the scenes, an ObjectOutputStream looks at all the fields of the objects and saves their contents. For example, when writing an Employee object, the name, date, and salary fields are written to the output stream. 但是这有一种情况需要考虑,如果多个对象共享一个对象,比如Manage 有一个 secretary属性
class Manager extends Employee { private Employee secretary; . . . } var harry = new Employee("Harry Hacker", . . .); var carl = new Manager("Carl Cracker", . . .); carl.setSecretary(harry); var tony = new Manager("Tony Tester", . . .); tony.setSecretary(harry);
序列化的时候,肯定不能保存内存地址。因为harrry 重新加载到内存后,地址是会变化的。这时,存储对象的时候存储一个序列化数字代替内存地址,第一次碰到对象,写到outputStream中,如果再碰到相同的对象,以前已经存储过了,就不存储了,直接写same as the previously saved object with serial number x.

当反序列化的时候,过程,正好相反,
When an object is specified in an object input stream for the first time, construct it, initialize it with the stream data, and remember the association between the serial number and the object reference.
When the tag “same as the previously saved object with serial number x” is encountered, retrieve the object reference for the sequence number.
很少会使用java提供的序列化,主要是因为JDK默认的序列化存在着一些非常严重的缺陷,比如它是无法实现跨平台和跨语言的,意思是我们在java中序列化的对象是无法被其他语言或者是被浏览器反序列的。为了解决这一问题通常将Java对象转换为XML或Json格式进而实现网络传输。
反射
反射可以在运行时获取到类的信息。Java在运行时会加载每一个.class文件,然后创建对象。.class文件也是一个对象,被抽象成Class类型。对应的,有三个类 Field, Method, 和Constructor 分别描述一个类的字段、方法和构造函数。

获取Class类的对象的三种方式:1,对象.getClass(), 2.类的.class, 3,Class.forName() 手动加载类。无论用什么方式获取到类本身这个对象,类本身这个对象是唯一的。Class对象,newInstance(相当于调用空参构造函数)



Method invoke和 JS中的call 和apply 一样, 因为方法有this,所以要创建一个对象,作为第一个参数,然后,传参。
Java中的正则表达式,竟然是字符串。

网络连接
UDP: 把数据放到DATAGgramPacket中,和地址一起进行发送,而在接收端, 要把接收到的数据放到DATAGgramPacket中,从DATAGgramPacket中,getdata,进行解析,因为UDP是无连接,
TCP: socket是有连接的,所以建立连接后,客户端要从连接中获取到输入输出流,进行读取和写入,所有的操作都在一个连接中完成。

而在服务端, 由于无数的客户端都连接到服务端,服务端需要和客户端建立一一对应的关系,所以它只accept客户端,获取连接过来的客户端,从客户端获取socket流,读取客户端发送过来的数据。

注解:
注解只是代码中加的标记,本身对代码没有影响,要选择处理注解的工具,比如@test本身不会做任何事情,需要Junit测试工具。@interface 注解名 {方法} 创建注解,方法是注解的元素
@interface MyAnno { String str(); int val() }
注解可以加到方法上(@注解名),给注解元素赋值
@MyAnno(str = "Annotation Example", val = 100) public void MyMeth() {}
注解本身没有作用,需要一个处理注解的工具,可以自己写一个,使用的是反射
@interface MyAnno { String str(); int val(); } class Anno { public static void processAnnotations(Object obj) { try { Class<?> c = obj.getClass(); Method m = c.getMethod("myMeth"); MyAnno anno = m.getAnnotation(MyAnno.class); System.out.println(anno.str() + " " + anno.val()); } catch (Exception e) { System.out.println("Method No Found"); } } } public class Main { @MyAnno(str = "Annotation Example", val = 100) public void myMeth() {} public static void main(String[] args) { Anno.processAnnotations(new Main()); } }
代码有一个问题,涉及注解的留存策略,注解要保留到什么时候, SOURCE, CLASS, and RUNTIME. 因为MyAnno注解是程序运行时还要使用,所以要留存到runtime
@Retention(RetentionPolicy.RUNTIME) @interface MyAnno { String str(); int val(); }
成功运行。如果注解没有成员,称为标记注解,仅起标注作用。当注解仅有一个成员时,把它定义为 类型 value(), 使用时,在()中直接提供值。注解的成员是value时,可以提供其它成员,不过成员要加默认值。
@Retention(RetentionPolicy.RUNTIME)
@interface Mysingle {
int value();
}
@Retention(RetentionPolicy.RUNTIME)
@interface SomeAnno {
int value();
int xyz() default 0;
}
@Retention(RetentionPolicy.RUNTIME)
@interface myMarker {}
public class Test {
@Mysingle(100)
@myMarker
// @SomeAnno(100) 或@SomeAnno(value = 100, xyz = 99)
public static void myMeth() {
Test ob = new Test();
try {
Class<?> c = ob.getClass();
Method m = c.getMethod("myMeth", String.class, int.class);
if(m.isAnnotationPresent(myMarker.class)) // 使用 isAnnotationPresent判断有没有。
System.out.println("maker 存在");
Annotation[] annos = m.getAnnotations();
for (Annotation annotation : annos) {
System.out.println(annotation);
}
} catch (Exception e) {
System.out.println("Method No Found");
}
}
public static void main(String[] args) {
myMeth();
}
}
repeating 注解,一个注解,可以在同一个元素(比如方法)上面使用多次。此时注解上要@Repeatable, 并且,有一个容器注解。 getAnnotation( ) 获取容器注解
// MyAnno 是可重复注解
@Retention(RetentionPolicy.RUNTIME)
@Repeatable(MyRepeatedAnnos.class)
@interface MyAnno {
String str() default "Testing";
int val() default 9000;
}
// 容器注解
@Retention(RetentionPolicy.RUNTIME)
@interface MyRepeatedAnnos {
MyAnno[] value();
}
public class Test {
@MyAnno(str = "First annotation", val = -1)
@MyAnno(str = "Second annotation", val = 100)
public static void myMeth() {
Test ob = new Test();
try {
Class<?> c = ob.getClass();
Method m = c.getMethod("myMeth");
// 第一种获取重复注解的方法,使用容器注解
Annotation anno = m.getAnnotation(MyRepeatedAnnos.class);
System.out.println(anno);
// 第二种方式:getAnnotationsByType
Annotation[] annos = m.getAnnotationsByType(MyAnno.class);
for (Annotation annotation : annos) {
System.out.println(annotation);
}
} catch (Exception e) {
System.out.println("Method No Found");
}
}
public static void main(String[] args) {
myMeth();
}
}

