
SQL Server Insert 操作效率(堆表 VS 聚集索引表)
“SQL Server的Insert操作在堆表或者聚集索引表的时候,哪个效率更高?为什么高?”
之前有同事问过我这个问题,为了确保日志库的记录效率,于是我做了简单测试了,首先要先强调几点概念:
堆表:没有聚集索引的表,记录通过IAM页以及PFS页来确定哪页有空闲空间。
聚集索引表:有聚集索引的表,记录是根据聚集键值所在页的键值逻辑顺序维护的
Demo:如下
分别对堆表和聚集表进行5个并发线程,每个线程各10000次循环插入
1. 堆表测试
--1. 创建一张堆表 create table Insert_Test (id int identity, name char(200)) go
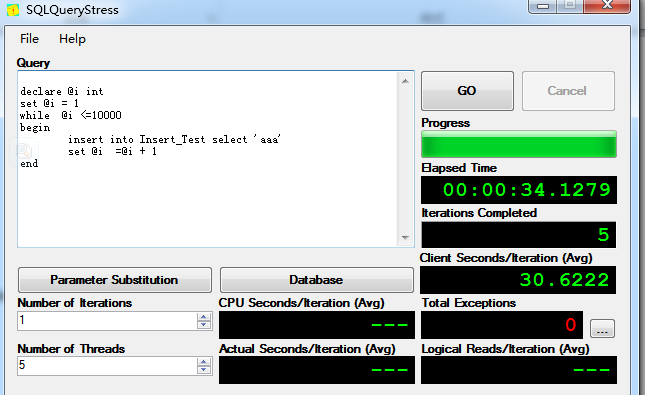
堆表Insert用时:34.127秒
2. 聚集索引表测试
create table Insert_Test2 (id int identity primary key clustered, name char(200)) go

聚集索引表Insert用时:22.885秒
结果:聚集索引的插入速度比堆表要快10秒以上(个人机器配置不同,时间差异也会高或低,我的本子性能较低)
分析
堆表插入:
每一次insert,总是被插入到表的任意可用空间上,通过IAM找到文件中的哪段区间属于目标表,通过PFS页找出这些区间内的哪些页面有可用空间,如果页面没有可用空间,需要通过GAM页和SGAM页查找将分配的某个表的可用区间。
聚集索引:
由于我的聚集键为自增id列,所以每次插入都将集中在最后一个数据页上。
总体来说:由于堆表插入的行的目标位置没有定义,因此确定在堆表中哪里放置行通常比在有聚集索引的表中放置行的效率低。
聚集索引表Insert的弊端
根据上面分析,聚集索引为自增列时,最后的数据页会成为集中insert的目标页,因此会成为热点,通时,SQL Server 使用闩锁,所以预测大并发insert操作会在最终页产生资源阻塞,实测确实如此:
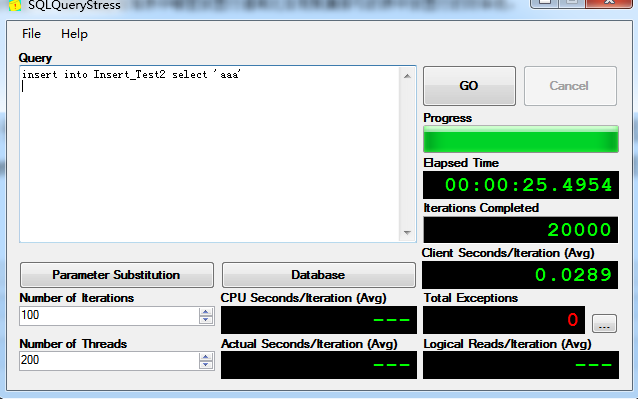
(200个并发线程,每个线程执行100次insert操作)
执行过程中,查看等待资源情况
select wait_type, count(*) as num_waiting_tasks, sum(wait_duration_ms) as total_wait_time_ms from sys.dm_os_waiting_tasks where session_id>50 group by wait_type order by wait_type

和预测情况一样,98个请求在等待闩锁资源。
那么,推断如果使用guid作为主键,插入时会分散各个数据页面,进而将热点页平铺开,这点确实有效果,但是拆分页的成本会相当的高,拆分页也是非常损伤性能的。
继续补充个情况,假如你需要长期大量insert操作,不如采用batch,效果会更快,将上面的脚本改为如下:
declare @i int set @i = 1 while @i <=10000 begin if @i %5000 = 0 begin if (@@TRANCOUNT>0) begin COMMIT TRAN BEGIN TRAN end end insert into Insert_Test2 select 'aaa' set @i =@i + 1 end if (@@TRANCOUNT>0) commit tran
单次执行从原先的8秒降为3秒,有兴趣的朋友可以自己测试
原因简单说下,Insert操作时需要进行预写日志的步骤,每个单独的insert操作都要写一遍ldf文件,这样的性能很低,如果每5000条insert包含在一个事务中后提交,它把很多小的transaction合并成一个大的合适的 transaction来减少磁盘写操作,从而获得极大性能提升。Batch size究竟多大才是最佳的呢?这个取决您的机器,需要你自己测试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号