
〖Python〗-- Django进阶
【Django进阶】
Django路由映射FBV 和 CBV
django中请求处理方式有2种:FBV(function base views) 和 CBV(class base views),换言之就是一种用函数处理请求,一种用类处理请求。
FBV


# url.py from django.conf.urls import url, include from mytest import views urlpatterns = [ url(r‘^index/‘, views.index), ] # views.py from django.shortcuts import render def index(req): if req.method == ‘POST‘: print(‘method is :‘ + req.method) elif req.method == ‘GET‘: print(‘method is :‘ + req.method) return render(req, ‘index.html‘)
CBV
# urls.py from mytest import views urlpatterns = [ # url(r‘^index/‘, views.index), url(r‘^index/‘, views.Index.as_view()), ] # views.py from django.views import View class Index(View): def get(self, req): print(‘method is :‘ + req.method) return render(req, ‘index.html‘) def post(self, req): print(‘method is :‘ + req.method) return render(req, ‘index.html‘) # 注:类要继承 View ,类中函数名必须小写。
关于CBV模式下的一个拓展
# cbv 模式下继承了django的view类 # 在请求来临的时候,会调用继承类的 dispatch 方法 # 通过反射的方法它会去调用自己写的视图函数, 那么这便是一个切入点,可以在自己的 cbv 视图中,重写这个方法。 class View(object): def dispatch(self, request, *args, **kwargs): # Try to dispatch to the right method; if a method doesn't exist, # defer to the error handler. Also defer to the error handler if the # request method isn't on the approved list. if request.method.lower() in self.http_method_names: handler = getattr(self, request.method.lower(), self.http_method_not_allowed) else: handler = self.http_method_not_allowed return handler(request, *args, **kwargs)
分页
一、Django内置分页
from django.shortcuts import render from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger L = [] for i in range(999): L.append(i) # 模拟数据库 生成数据 def index(request): current_page = request.GET.get('page') # 通过get请求得到当前请求的页数 paginator = Paginator(L, 10) # 实例化传入俩个参数(所有数据,当页显示条数) # per_page: 每页显示条目数量 # count: 数据总个数 # num_pages:总页数 # page_range:总页数的索引范围,如: (1,10),(1,200) # page: page对象 try: posts = paginator.page(current_page)# 传入当前页码,观源码可得实例化了一个Page对象 # has_next 是否有下一页 # next_page_number 下一页页码 # has_previous 是否有上一页 # previous_page_number 上一页页码 # object_list 分页之后的数据列表 # number 当前页 # paginator paginator对象 except PageNotAnInteger: # 不是数字 posts = paginator.page(1) except EmptyPage: # 超出页码范围 posts = paginator.page(paginator.num_pages) return render(request, 'index.html', {'posts': posts}) # posts封装了一些方法
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> <ul> {% for item in posts %} <li>{{ item }}</li> {% endfor %} </ul> <div class="pagination"> <span class="step-links"> {% if posts.has_previous %} <a href="?p={{ posts.previous_page_number }}">上一页</a> {% endif %} <span class="current"> Page {{ posts.number }} of {{ posts.paginator.num_pages }}. </span> {% if posts.has_next %} <a href="?p={{ posts.next_page_number }}">下一页</a> {% endif %} </span> </div> </body> </html>
那么、Django的内置分页基本俩个类实现、并封装了一些方法来使用、此时并不能满足有一些的需求
二、Django内置分页的拓展
from django.shortcuts import render from django.core.paginator import Paginator, EmptyPage, PageNotAnInteger user = [] for i in range(1, 1001): dic = {'name': 'root' + str(i), 'pwd': i} user.append(dic) class DiyPaginator(Paginator): def __init__(self, current_page,max_pager_num, *args, **kwargs): """ :param current_page: 当前页码 :param max_pager_num: 显示页码个数的最大值 :param args: :param kwargs: """ self.current_page = int(current_page) self.max_pager_num = int(max_pager_num) super(DiyPaginator,self).__init__(*args,**kwargs) def pager_num_range(self): # 需要的参数 # 当前页码 self.current_page # 页码数量 self.max_pager_num # 总页数 self.num_pages # 如果总页数小于页码个数最大值的情况 if self.num_pages < self.max_pager_num: return range(1,self.num_pages+1) # 返回 从 1 到 总页数 # 如果总页数大于页码数量且当前所选页码小于页码数量的一半 part = self.max_pager_num//2 if self.current_page <= part: return range(1,self.max_pager_num+1) # 返回 从 1 到 页码个数最大值 # 如果当前页码加一半的页码 大于 总页数 if (self.current_page+part) > self.num_pages: # 返回 从总页数-最大页码数 到 总页数 range的用法在此不作解释 # 例如 96页+5页 超出总页数 则返回的范围是 从 总页数-最大页码数量+1 到 总页数+1 return range(self.num_pages-self.max_pager_num+1,self.num_pages+1) # 其余情况从 当前页码减去显示页码的平均值开始 到 当前页码加显示页码的平均值(并加一)结束 return range(self.current_page-part,self.current_page+part+1) def index(request): p = request.GET.get('page') start = (int(p)-1)*10 end = int(p)*10 data = user[start:end] return render(request,'index.html',{'data':data,'user':user}) def index1(request): current_page = request.GET.get('page') paginator = DiyPaginator(current_page, 9, user, 10) # Paginator所封装的方法 # per_page: 每页显示条目数量 # count: 数据总个数 # num_pages:总页数 # page_range:总页数的索引范围,如: (1,10),(1,200) # page: page对象 try: posts = paginator.page(current_page) # has_next 是否有下一页 # next_page_number 下一页页码 # has_previous 是否有上一页 # previous_page_number 上一页页码 # object_list 分页之后的数据列表 # number 当前页 # paginator paginator对象 except PageNotAnInteger: # 不是整形数字 posts = paginator.page(1) except EmptyPage: # 如果是空值 posts = paginator.page(paginator.num_pages) return render(request,'index1.html',{'posts':posts})
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <ul> {% for row in posts.object_list %} <li>{{ row.name }}-{{ row.pwd }}</li> {% endfor %} </ul> {% include 'include/pager.html' %} </body> </html> ################################## include 组件代码 {% if posts.has_previous %} <a href="/index1?page={{ posts.previous_page_number }}">上一页</a> {% endif %} {% for num in posts.paginator.pager_num_range %} {% if num == posts.number %} <a style="color: red;font-size: 20px" href="/index1?page={{ num }}">{{ num }}</a> {% else %} <a href="/index1?page={{ num }}">{{ num }}</a> {% endif %} {% endfor %} {% if posts.has_next %} <a href="/index1?page={{ posts.next_page_number }}">下一页</a> {% endif %} <span> 当前页:{{ posts.number }} 总页数:{{ posts.paginator.num_pages }} </span>
三、自定义分页(适用于任何地方)
- 创建处理分页数据的类
- 根据分页数据获取数据
- 输出分页HTML,即:[上一页][1][2][3][4][5][下一页]或者额外的作出一些拓展也可以
创建处理分页数据的类时,大致也需要四个参数(详情观看类构造方法)
1、为了减少服务器内存的负载,不再获取所有数据的,而是获得所有数据的总个数,然后再根据索引查数据库的内容
2、当前页码
3、每页显示的行数
4、页码显示的数量
对于页数的显示大致也可以归类为三种情况(详情观看类中page_num_range函数)
1、计算的总页数小于页码显示的数量
2、计算的总页数大于页码显示的数量
A、当前页数小于页码数量的一半
B、当前页数加页码数量的一半超出总页数的范围
3、正常情况
从 当前页数 减 一半页码数量 到 当前页数 加 一半页码数量
class Pagination(object): def __init__(self,totalCount,currentPage,perPageItemNum=10,maxPageNum=9): """ :param totalCount: 所有数据总个数 :param currentPage: 当前页数 :param perPageItemNum: 每页显示行数 :param maxPageNum: 最多显示页码个数 """ self.total_count = totalCount # 对当前的页码进行一次异常捕获 try: currentPage = int(currentPage) if currentPage <= 0: currentPage = 1 self.current_page = currentPage except Exception: self.current_page = 1 self.per_page_item_num = perPageItemNum self.max_page_num = maxPageNum @property def start(self): # 数据索引开始的值 return (self.current_page-1) * self.per_page_item_num @property def end(self): # 数据索引结束的值 return self.current_page * self.per_page_item_num @property def num_pages(self): """ 总页数 :return: """ # 得商取余得内置函数 x, o = divmod(self.total_count,self.per_page_item_num) if o == 0: return x return x + 1 @property def page_num_range(self): if self.num_pages < self.max_page_num: return range(1, self.num_pages+1) part = self.max_page_num//2 if self.current_page <= part: return range(1,self.max_page_num+1) if (self.current_page+part) > self.num_pages: return range(self.num_pages-self.max_page_num+1, self.num_pages+1) return range(self.current_page-part, self.current_page+part+1) def page_str(self): page_list = [] first = "<li><a href='/index2/?page=1'>首页</a></li>" page_list.append(first) if self.current_page == 1: prev_page = "<li><a href='#'>上一页</a></li>" else: prev_page = "<li><a href='/index2/?page=%s'>上一页</a></li>" %(self.current_page-1) page_list.append(prev_page) for i in self.page_num_range: if i == self.current_page: temp = "<li class='active'><a href='/index2/?page=%s'>%s</a></li>" %(i,i) else: temp = "<li><a href='/index2/?page=%s'>%s</a></li>" % (i, i) page_list.append(temp) if self.current_page == self.num_pages: next_page = "<li><a href='#'>下一页</a></li>" else: next_page = "<li><a href='/index2/?page=%s'>下一页</a></li>" %(self.current_page+1) page_list.append(next_page) last = "<li><a href='/index2/?page=%s'>尾页</a></li>" %self.num_pages page_list.append(last) return ''.join(page_list)
def index2(request): from page.diypage import Pagination current_page = request.GET.get('page') page_obj = Pagination(1000,current_page) data_list = user[page_obj.start:page_obj.end] return render(request,'index2.html',{ 'data' : data_list, 'page_obj' : page_obj })
# 本页面引用了bootstrap样式 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> <link rel="stylesheet" href="/static/bootstrap/css/bootstrap.css" /> </head> <body> <ul> {% for row in data %} <li>{{ row.name }}-{{ row.pwd }}</li> {% endfor %} </ul> {% for i in page_obj.pager_num_range %} <a href="/index2/?page={{ i }}">{{ i }}</a> {% endfor %} <hr/> <ul class="pagination pagination-sm"> {{ page_obj.page_str|safe }} </ul> <div style="height: 300px;"></div> </body> </html>
序列化
序列化是将对象状态转换为可保持或传输的格式的过程
反序列化是指将存储在存储媒体中的对象状态装换成对象的过程
例如游戏都有存档的功能、再次开始的时候只需读档即可(这即是一个序列化与反序列的过程)
序列化也可以将一个对象传递到另一个地方的
关于Django中的序列化主要应用在将数据库中检索的数据返回给客户端用户,特别的Ajax请求一般返回的为Json格式。
1、serializers
from django.core import serializers
ret = models.BookType.objects.all()
data = serializers.serialize("json", ret)
2、json.dumps
import json
#ret = models.BookType.objects.all().values('caption')
ret = models.BookType.objects.all().values_list('caption')
ret=list(ret)
result = json.dumps(ret)
3、from django.http import JsonResponse
django JsonResponse不支持返回列表形式的序列化。例如看看这个类的构造方法是怎么样执行的...
class JsonResponse(HttpResponse): """ 将数据序列化成为JSON的Http响应类 :param data: Data to be dumped into json. By default only ``dict`` objects are allowed to be passed due to a security flaw before EcmaScript 5. See the ``safe`` parameter for more information. :param encoder: Should be an json encoder class. Defaults to ``django.core.serializers.json.DjangoJSONEncoder``. :param safe: Controls if only ``dict`` objects may be serialized. Defaults to ``True``. :param json_dumps_params: A dictionary of kwargs passed to json.dumps(). """ def __init__(self, data, encoder=DjangoJSONEncoder, safe=True, json_dumps_params=None, **kwargs): # 如果safe为True 和 data 不是 dict的实例对象 则抛出异常 if safe and not isinstance(data, dict): raise TypeError( 'In order to allow non-dict objects to be serialized set the ' 'safe parameter to False.' ) if json_dumps_params is None: json_dumps_params = {} kwargs.setdefault('content_type', 'application/json') data = json.dumps(data, cls=encoder, **json_dumps_params) super(JsonResponse, self).__init__(content=data, **kwargs)
Cookies
Cookie是存储在用户浏览器上的一个键值对
A、获取Cookies
request.COOKIES['key'] request.get_signed_cookie(key, default=RAISE_ERROR, salt='', max_age=None) 参数: default: 默认值 salt: 加密盐 max_age: 后台控制过期时间
B、设置Cookies

rep = HttpResponse(...) 或 rep = render(request, ...) rep.set_cookie(key,value,...) rep.set_signed_cookie(key,value,salt='加密盐',...) 参数: key, 键 value='', 值 max_age=None, 超时时间 expires=None, 超时时间(IE requires expires, so set it if hasn't been already.) path='/', Cookie生效的路径,/ 表示根路径,特殊的:跟路径的cookie可以被任何url的页面访问 domain=None, Cookie生效的域名 secure=False, https传输 httponly=False 只能http协议传输,无法被JavaScript获取(不是绝对,底层抓包可以获取到也可以被覆盖)
C、由于Cookies保存在客户端的电脑上,所以,JavaScript和jquery也可以操作cookie.
更多详情更新中...
Session
cookies虽然也能完成认证工作,但是cookies是保存在浏览器端数据,所以这就导致这种操作有极强的不安全性。并且通常认证操作的话,需要在cookies中写数据,这就避免不了要写一些敏感的信息。这样直接就造成了cookies存放数据的不安全性。因此:我们想若是把数据放在服务器端,仅是给客户端cookies写入简单的但足以明确标志的信息,就避免了不安全的问题。所以就有了session这个东东,此处就跟大家谈谈session。
Session(django自带的操作机制)
Cookie是什么? 保存在客户端浏览器上的键值对 缺点:会暴露敏感信息! Session是什么? 是保存在服务器端的数据(类型不确定)<本质是键值对>应用:依赖于cookie作用:保持会话(Web网站)记录登录状态,用来做信息检测!好处:敏感信息不会直接给客户端PS:在执行语句,创建数据库的过程中,会初始化创建一个叫做django_session的表,用以存放创建的键值对(已经过加密处理)。也就是说session数据的增,删,查都是通过这张表来操作。 实质:每个用户来访问服务器都会给客户分配一个ID。用户请求访问,服务器端就会将这个访问保存成一份ID唯一的数据(这份数据对应一个独一无二的ID), 这个ID,服务器会通过set cookie 的方式告诉给客户端。然后客户端请求的时候会把这个ID带上,服务端的session就可以和客户端关联起来了。Session是存储在服务器的一组键值对,且它依赖于Cookie,且安全系数比Cookie高
Django中默认支持Session,其内部提供了5种类型的Session供开发者使用:
- 数据库(默认)
- 缓存
- 文件
- 缓存+数据库
- 加密cookie
1、数据库Session
Django默认支持Session,并且默认是将Session数据存储在数据库中,即:django_session 表中。 a. 配置 settings.py SESSION_ENGINE = 'django.contrib.sessions.backends.db' # 引擎(默认) SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串(默认) SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径(默认) SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名(默认) SESSION_COOKIE_SECURE = False # 是否Https传输cookie(默认) SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输(默认) SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周)(默认) SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期(默认) SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存(默认) b. 使用 def index(request): # 获取、设置、删除Session中数据 request.session['k1'] request.session.get('k1',None) request.session['k1'] = 123 request.session.setdefault('k1',123) # 存在则不设置 del request.session['k1'] # 所有 键、值、键值对 request.session.keys() request.session.values() request.session.items() request.session.iterkeys() request.session.itervalues() request.session.iteritems() # 用户session的随机字符串 request.session.session_key # 将所有Session失效日期小于当前日期的数据删除 request.session.clear_expired() # 检查 用户session的随机字符串 在数据库中是否 request.session.exists("session_key") # 删除当前用户的所有Session数据 request.session.delete("session_key") request.session.set_expiry(value) * 如果value是个整数,session会在些秒数后失效。 * 如果value是个datatime或timedelta,session就会在这个时间后失效。 * 如果value是0,用户关闭浏览器session就会失效。 * 如果value是None,session会依赖全局session失效策略。
2、缓存Session
a. 配置 settings.py SESSION_ENGINE = 'django.contrib.sessions.backends.cache' # 引擎 SESSION_CACHE_ALIAS = 'default' # 使用的缓存别名(默认内存缓存,也可以是memcache),此处别名依赖缓存的设置 SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串 SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径 SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名 SESSION_COOKIE_SECURE = False # 是否Https传输cookie SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输 SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周) SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期 SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存 b. 使用 同上
3、文件Session
a. 配置 settings.py SESSION_ENGINE = 'django.contrib.sessions.backends.file' # 引擎 SESSION_FILE_PATH = None # 缓存文件路径,如果为None,则使用tempfile模块获取一个临时地址tempfile.gettempdir() # 如:/var/folders/d3/j9tj0gz93dg06bmwxmhh6_xm0000gn/T SESSION_COOKIE_NAME = "sessionid" # Session的cookie保存在浏览器上时的key,即:sessionid=随机字符串 SESSION_COOKIE_PATH = "/" # Session的cookie保存的路径 SESSION_COOKIE_DOMAIN = None # Session的cookie保存的域名 SESSION_COOKIE_SECURE = False # 是否Https传输cookie SESSION_COOKIE_HTTPONLY = True # 是否Session的cookie只支持http传输 SESSION_COOKIE_AGE = 1209600 # Session的cookie失效日期(2周) SESSION_EXPIRE_AT_BROWSER_CLOSE = False # 是否关闭浏览器使得Session过期 SESSION_SAVE_EVERY_REQUEST = False # 是否每次请求都保存Session,默认修改之后才保存 b. 使用 同上
4、缓存+数据库Session
数据库用于做持久化,缓存用于提高效率 a. 配置 settings.py SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db' # 引擎 b. 使用 同上
5、加密cookie Session
a. 配置 settings.py SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies' # 引擎 b. 使用 同上
扩展:Session用户验证
def login(func): def wrap(request, *args, **kwargs): # 如果未登陆,跳转到指定页面 if request.path == '/test/': return redirect('http://www.baidu.com') return func(request, *args, **kwargs) return wrap
Model进阶的更多操作
一、字段
AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列 from django.db import models class UserInfo(models.Model): # 自动创建一个列名为id的且为自增的整数列 username = models.CharField(max_length=32) class Group(models.Model): # 自定义自增列 nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) SmallIntegerField(IntegerField): - 小整数 -32768 ~ 32767 PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正小整数 0 ~ 32767 IntegerField(Field) - 整数列(有符号的) -2147483648 ~ 2147483647 PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正整数 0 ~ 2147483647 BigIntegerField(IntegerField): - 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 BooleanField(Field) - 布尔值类型 NullBooleanField(Field): - 可以为空的布尔值 CharField(Field) - 字符类型 - 必须提供max_length参数, max_length表示字符长度 TextField(Field) - 文本类型 EmailField(CharField): - 字符串类型,Django Admin以及ModelForm中提供验证机制 IPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 GenericIPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6 - 参数: protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6" unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启刺功能,需要protocol="both" URLField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField) - 字符串类型,格式必须为逗号分割的数字 UUIDField(Field) - 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field) - 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能 - 参数: path, 文件夹路径 match=None, 正则匹配 recursive=False, 递归下面的文件夹 allow_files=True, 允许文件 allow_folders=False, 允许文件夹 FileField(Field) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage width_field=None, 上传图片的高度保存的数据库字段名(字符串) height_field=None 上传图片的宽度保存的数据库字段名(字符串) DateTimeField(DateField) - 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] DateField(DateTimeCheckMixin, Field) - 日期格式 YYYY-MM-DD TimeField(DateTimeCheckMixin, Field) - 时间格式 HH:MM[:ss[.uuuuuu]] DurationField(Field) - 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field) - 浮点型 DecimalField(Field) - 10进制小数 - 参数: max_digits,小数总长度 decimal_places,小数位长度 BinaryField(Field) - 二进制类型
class UnsignedIntegerField(models.IntegerField): def db_type(self, connection): return 'integer UNSIGNED' PS: 返回值为字段在数据库中的属性,Django字段默认的值为: 'AutoField': 'integer AUTO_INCREMENT', 'BigAutoField': 'bigint AUTO_INCREMENT', 'BinaryField': 'longblob', 'BooleanField': 'bool', 'CharField': 'varchar(%(max_length)s)', 'CommaSeparatedIntegerField': 'varchar(%(max_length)s)', 'DateField': 'date', 'DateTimeField': 'datetime', 'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)', 'DurationField': 'bigint', 'FileField': 'varchar(%(max_length)s)', 'FilePathField': 'varchar(%(max_length)s)', 'FloatField': 'double precision', 'IntegerField': 'integer', 'BigIntegerField': 'bigint', 'IPAddressField': 'char(15)', 'GenericIPAddressField': 'char(39)', 'NullBooleanField': 'bool', 'OneToOneField': 'integer', 'PositiveIntegerField': 'integer UNSIGNED', 'PositiveSmallIntegerField': 'smallint UNSIGNED', 'SlugField': 'varchar(%(max_length)s)', 'SmallIntegerField': 'smallint', 'TextField': 'longtext', 'TimeField': 'time', 'UUIDField': 'char(32)',
二、字段参数
null 数据库中字段是否可以为空 db_column 数据库中字段的列名 default 数据库中字段的默认值 primary_key 数据库中字段是否为主键 db_index 数据库中字段是否可以建立索引 unique 数据库中字段是否可以建立唯一索引 unique_for_date 数据库中字段【日期】部分是否可以建立唯一索引 unique_for_month 数据库中字段【月】部分是否可以建立唯一索引 unique_for_year 数据库中字段【年】部分是否可以建立唯一索引 verbose_name Admin中显示的字段名称 blank Admin中是否允许用户输入为空 editable Admin中是否可以编辑 help_text Admin中该字段的提示信息 choices Admin中显示选择框的内容,用不变动的数据放在内存中从而避免跨表操作 如:gf = models.IntegerField(choices=[(0, '何穗'),(1, '大表姐'),],default=1) error_messages 自定义错误信息(字典类型),从而定制想要显示的错误信息; 字典健:null, blank, invalid, invalid_choice, unique, and unique_for_date 如:{'null': "不能为空.", 'invalid': '格式错误'} validators 自定义错误验证(列表类型),从而定制想要的验证规则 from django.core.validators import RegexValidator from django.core.validators import EmailValidator,URLValidator,DecimalValidator,\ MaxLengthValidator,MinLengthValidator,MaxValueValidator,MinValueValidator 如: test = models.CharField( max_length=32, error_messages={ 'c1': '优先错信息1', 'c2': '优先错信息2', 'c3': '优先错信息3', }, validators=[ RegexValidator(regex='root_\d+', message='错误了', code='c1'), RegexValidator(regex='root_112233\d+', message='又错误了', code='c2'), EmailValidator(message='又错误了', code='c3'), ] )
三、多表关系及参数
ForeignKey(ForeignObject) # ForeignObject(RelatedField) to, # 要进行关联的表名 to_field=None, # 要关联的表中的字段名称 on_delete=None, # 当删除关联表中的数据时,当前表与其关联的行的行为 - models.CASCADE,删除关联数据,与之关联也删除 - models.DO_NOTHING,删除关联数据,引发错误IntegrityError - models.PROTECT,删除关联数据,引发错误ProtectedError - models.SET_NULL,删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空) - models.SET_DEFAULT,删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值) - models.SET,删除关联数据, a. 与之关联的值设置为指定值,设置:models.SET(值) b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象) def func(): return 10 class MyModel(models.Model): user = models.ForeignKey( to="User", to_field="id" on_delete=models.SET(func),) related_name=None, # 反向操作时,使用的字段名,用于代替 【表名_set】 如: obj.表名_set.all() related_query_name=None, # 反向操作时,使用的连接前缀,用于替换【表名】 如: models.UserGroup.objects.filter(表名__字段名=1).values('表名__字段名') limit_choices_to=None, # 在Admin或ModelForm中显示关联数据时,提供的条件: # 如: - limit_choices_to={'nid__gt': 5} - limit_choices_to=lambda : {'nid__gt': 5} from django.db.models import Q - limit_choices_to=Q(nid__gt=10) - limit_choices_to=Q(nid=8) | Q(nid__gt=10) - limit_choices_to=lambda : Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root') db_constraint=True # 是否在数据库中创建外键约束 parent_link=False # 在Admin中是否显示关联数据 OneToOneField(ForeignKey) to, # 要进行关联的表名 to_field=None # 要关联的表中的字段名称 on_delete=None, # 当删除关联表中的数据时,当前表与其关联的行的行为 ###### 对于一对一 ###### # 1. 一对一其实就是 一对多 + 唯一索引 # 2.当两个类之间有继承关系时,默认会创建一个一对一字段 # 如下会在A表中额外增加一个c_ptr_id列且唯一: class C(models.Model): nid = models.AutoField(primary_key=True) part = models.CharField(max_length=12) class A(C): id = models.AutoField(primary_key=True) code = models.CharField(max_length=1) ManyToManyField(RelatedField) to, # 要进行关联的表名 related_name=None, # 反向操作时,使用的字段名,用于代替 【表名_set】 如: obj.表名_set.all() related_query_name=None, # 反向操作时,使用的连接前缀,用于替换【表名】 如: models.UserGroup.objects.filter(表名__字段名=1).values('表名__字段名') limit_choices_to=None, # 在Admin或ModelForm中显示关联数据时,提供的条件: # 如: - limit_choices_to={'nid__gt': 5} - limit_choices_to=lambda : {'nid__gt': 5} from django.db.models import Q - limit_choices_to=Q(nid__gt=10) - limit_choices_to=Q(nid=8) | Q(nid__gt=10) - limit_choices_to=lambda : Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root') symmetrical=None, # 仅用于多对多自关联时,symmetrical用于指定内部是否创建反向操作的字段 # 做如下操作时,不同的symmetrical会有不同的可选字段 models.BB.objects.filter(...) # 可选字段有:code, id, m1 class BB(models.Model): code = models.CharField(max_length=12) m1 = models.ManyToManyField('self',symmetrical=True) # 可选字段有: bb, code, id, m1 class BB(models.Model): code = models.CharField(max_length=12) m1 = models.ManyToManyField('self',symmetrical=False) through=None, # 自定义第三张表时,使用字段用于指定关系表 through_fields=None, # 自定义第三张表时,使用字段用于指定关系表中那些字段做多对多关系表 from django.db import models class Person(models.Model): name = models.CharField(max_length=50) class Group(models.Model): name = models.CharField(max_length=128) members = models.ManyToManyField( Person, through='Membership', through_fields=('group', 'person'), ) class Membership(models.Model): group = models.ForeignKey(Group, on_delete=models.CASCADE) person = models.ForeignKey(Person, on_delete=models.CASCADE) inviter = models.ForeignKey( Person, on_delete=models.CASCADE, related_name="membership_invites", ) invite_reason = models.CharField(max_length=64) db_constraint=True, # 是否在数据库中创建外键约束 db_table=None, # 默认创建第三张表时,数据库中表的名称
四、更多ORM操作
################################################################## # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET # ################################################################## def all(self) # 获取所有的数据对象 def filter(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 model.tb.objects.all().select_related() model.tb.objects.all().select_related('外键字段') model.tb.objects.all().select_related('外键字段__外键字段') def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 # 获取所有用户表 # 获取用户类型表where id in (用户表中的查到的所有用户ID) models.UserInfo.objects.prefetch_related('外键字段') from django.db.models import Count, Case, When, IntegerField Article.objects.annotate( numviews=Count(Case( When(readership__what_time__lt=treshold, then=1), output_field=CharField(), )) ) students = Student.objects.all().annotate(num_excused_absences=models.Sum( models.Case( models.When(absence__type='Excused', then=1), default=0, output_field=models.IntegerField() ))) def annotate(self, *args, **kwargs) # 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')) # SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1) # SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1) # SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names) # 用于distinct去重 models.UserInfo.objects.values('nid').distinct() # select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names) # 用于排序 models.UserInfo.objects.all().order_by('-id','age') def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) def reverse(self): # 倒序 models.UserInfo.objects.all().order_by('-nid').reverse() # 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields): models.UserInfo.objects.defer('username','id') 或 models.UserInfo.objects.filter(...).defer('username','id') #映射中排除某列数据 def only(self, *fields): #仅取某个表中的数据 models.UserInfo.objects.only('username','id') 或 models.UserInfo.objects.filter(...).only('username','id') def using(self, alias): 指定使用的数据库,参数为别名(setting中的设置) ################################################## # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS # ################################################## def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default") ################### 原生SQL ################### from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields): # 获取每行数据为字典格式 def values_list(self, *fields, **kwargs): # 获取每行数据为元祖 def dates(self, field_name, kind, order='ASC'): # 根据时间进行某一部分进行去重查找并截取指定内容 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) # order只能是:"ASC" "DESC" # 并获取转换后的时间 - year : 年-01-01 - month: 年-月-01 - day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') def datetimes(self, field_name, kind, order='ASC', tzinfo=None): # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 # kind只能是 "year", "month", "day", "hour", "minute", "second" # order只能是:"ASC" "DESC" # tzinfo时区对象 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC) models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """ pip3 install pytz import pytz pytz.all_timezones pytz.timezone(‘Asia/Shanghai’) """ def none(self): # 空QuerySet对象 #################################### # METHODS THAT DO DATABASE QUERIES # #################################### def aggregate(self, *args, **kwargs): # 聚合函数,获取字典类型聚合结果 from django.db.models import Count, Avg, Max, Min, Sum result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid')) ===> {'k': 3, 'n': 4} def count(self): # 获取个数 def get(self, *args, **kwargs): # 获取单个对象 def create(self, **kwargs): # 创建对象 def bulk_create(self, objs, batch_size=None): # 批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs): # 如果存在,则获取,否则,创建 # defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs): # 如果存在,则更新,否则,创建 # defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1}) def first(self): # 获取第一个 def last(self): # 获取最后一个 def in_bulk(self, id_list=None): # 根据主键ID进行查找 id_list = [11,21,31] models.DDD.objects.in_bulk(id_list) def delete(self): # 删除 def update(self, **kwargs): # 更新 def exists(self): # 是否有结果
五、小结
# Model操作
.related_name # 设置反向查找的别名 例如 Book_set ==> xx
.related_query_name # 设置表的别名 例如 Book_set ==> xx_set
.all
.values
.values_list
.delete
.filter
.update
.create
# 多对多字段操作
.m.add # 添加关系
.m.set # 重置关系
.m.clear # 清空关系
.m.remove # 删除关系
.only # 仅取某几列数据
.defer # 排除某几列数据
# 执行原生SQL语句的三种方式
# from django.db import connection, connections
# cursor = connection.cursor() 或 cursor = connections['default'].cursor()
# cursor.execute("""SELECT * from auth_user where id = %s""", [1]) # 将1进行字符串拼接
# row = cursor.fetchone()
models.UserInfo.objects.raw('select id,name from userinfo')
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# 涉及到查表效率
# 在使用all filter 查询表时,涉及到第三张表的查询时、
# 会再次执行查询,数据量很庞大的时候,会影响执行效率、因此下方俩条可较为有效的解决此问题
select_related('跨表字段') # 一次连表查询获取所有数据
prefetch_related # 不连表、会进行俩次查询
六、OneToOneField、ForeignKey、ManyToManyField And Model联合索引
Django基础篇中,详解了一对一、一对多、多对多的一些操作且多数情况下都是与其它表作的关联
那么它们在一些应用场景下作自关联从而达到要求。
A、OneToOneField
场景:
分析:
试验:
B、ForeignKey
场景:在评论微信朋友圈时,可以直接回复该人的朋友圈,或者可以在某条评论下评论其它的一些内容,至此形成了所谓的评论楼
分析:评论与评论之间有着某种联系、一条评论下且可以有多个评论回复,至此评论表可以对自己进行绑定一对多的自关联
试验:代码更新中...
PS:on_delete的参数上方有详解
C、ManyToManyField
场景:博客园中,一个用户可以关注多人、同时也可以被多人关注、自而形成多对多的关系
分析:一张用户表的可以有多对多的字段、在第三张表中可以绑定关系
试验:代码更新中...
D、Model联合索引
在多对多操作中,通常情况下在某张表中增加多对多字段即可以让Django自动生成第三张关系表
新建第三表也可以通过别的方式实现
1、自动 2、手动 3、自动+手动
from django.db import models class Person(models.Model): name = models.CharField(max_length=32) def __str__(self): return self.name class Addr(models.Model): name = models.CharField(max_length=20) m = models.ManyToManyField def __str__(self): return self.name class AddrToPerson(models.Model): p = models.ForeignKey( to='Person' ) a = models.ForeignKey( to='Addr' ) class Meta: # 联合索引建立方式 unique_together=[ ('p', 'a'), ]
Form
django中的Form一般有两种功能:
- 输入html
- 验证用户输入
#!/usr/bin/env python # -*- coding:utf-8 -*- import re from django import forms from django.core.exceptions import ValidationError def mobile_validate(value): mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])[0-9]{8}$') if not mobile_re.match(value): raise ValidationError('手机号码格式错误') class PublishForm(forms.Form): user_type_choice = ( (0, u'普通用户'), (1, u'高级用户'), ) user_type = forms.IntegerField(widget=forms.widgets.Select(choices=user_type_choice, attrs={'class': "form-control"})) title = forms.CharField(max_length=20, min_length=5, error_messages={'required': u'标题不能为空', 'min_length': u'标题最少为5个字符', 'max_length': u'标题最多为20个字符'}, widget=forms.TextInput(attrs={'class': "form-control", 'placeholder': u'标题5-20个字符'})) memo = forms.CharField(required=False, max_length=256, widget=forms.widgets.Textarea(attrs={'class': "form-control no-radius", 'placeholder': u'详细描述', 'rows': 3})) phone = forms.CharField(validators=[mobile_validate, ], error_messages={'required': u'手机不能为空'}, widget=forms.TextInput(attrs={'class': "form-control", 'placeholder': u'手机号码'})) email = forms.EmailField(required=False, error_messages={'required': u'邮箱不能为空','invalid': u'邮箱格式错误'}, widget=forms.TextInput(attrs={'class': "form-control", 'placeholder': u'邮箱'}))
def publish(request): ret = {'status': False, 'data': '', 'error': '', 'summary': ''} if request.method == 'POST': request_form = PublishForm(request.POST) if request_form.is_valid(): request_dict = request_form.clean() print request_dict ret['status'] = True else: error_msg = request_form.errors.as_json() ret['error'] = json.loads(error_msg) return HttpResponse(json.dumps(ret))
扩展:ModelForm
在使用Model和Form时,都需要对字段进行定义并指定类型,通过ModelForm则可以省去From中字段的定义
class AdminModelForm(forms.ModelForm): class Meta: model = models.Admin #fields = '__all__' fields = ('username', 'email') widgets = { 'email' : forms.PasswordInput(attrs={'class':"alex"}), }
跨站请求伪造
一、简介
django为用户实现防止跨站请求伪造的功能,通过中间件 django.middleware.csrf.CsrfViewMiddleware 来完成。而对于django中设置防跨站请求伪造功能有分为全局和局部。
全局:
中间件 django.middleware.csrf.CsrfViewMiddleware
局部:
- @csrf_protect,为当前函数强制设置防跨站请求伪造功能,即便settings中没有设置全局中间件。
- @csrf_exempt,取消当前函数防跨站请求伪造功能,即便settings中设置了全局中间件。
注:from django.views.decorators.csrf import csrf_exempt,csrf_protect
二、应用
1、普通表单
veiw中设置返回值: return render_to_response('Account/Login.html',data,context_instance=RequestContext(request)) 或者 return render(request, 'xxx.html', data) html中设置Token: {% csrf_token %}
2、Ajax
对于传统的form,可以通过表单的方式将token再次发送到服务端,而对于ajax的话,使用如下方式。
view.py
from django.template.context import RequestContext # Create your views here. def test(request): if request.method == 'POST': print request.POST return HttpResponse('ok') return render_to_response('app01/test.html',context_instance=RequestContext(request))
text.html
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8"> <title></title> </head> <body> {% csrf_token %} <input type="button" onclick="Do();" value="Do it"/> <script src="/static/plugin/jquery/jquery-1.8.0.js"></script> <script src="/static/plugin/jquery/jquery.cookie.js"></script> <script type="text/javascript"> var csrftoken = $.cookie('csrftoken'); function csrfSafeMethod(method) { // these HTTP methods do not require CSRF protection return (/^(GET|HEAD|OPTIONS|TRACE)$/.test(method)); } $.ajaxSetup({ beforeSend: function(xhr, settings) { if (!csrfSafeMethod(settings.type) && !this.crossDomain) { xhr.setRequestHeader("X-CSRFToken", csrftoken); } } }); function Do(){ $.ajax({ url:"/app01/test/", data:{id:1}, type:'POST', success:function(data){ console.log(data); } }); } </script> </body> </html>
Django中间件
django 中的中间件(middleware),在django中,中间件其实就是一个类,在请求到来和结束后,django会根据自己的规则在合适的时机执行中间件中相应的方法。
在django项目的settings模块中,有一个 MIDDLEWARE_CLASSES 变量,其中每一个元素就是一个中间件,如下图。

例如,可以在项目中的任何地方创建一个middleware.py的文件(可随意创建, 注册中间件的时候配置好路径即可)
中间件中可以定义四个方法,分别是:
- process_request(self,request)
- process_view(self, request, callback, callback_args, callback_kwargs)
- process_template_response(self,request,response)
- process_exception(self, request, exception)
- process_response(self, request, response)
以上方法的返回值可以是None和HttpResonse对象,如果是None,则继续按照django定义的规则向下执行,如果是HttpResonse对象,则直接将该对象返回给用户。
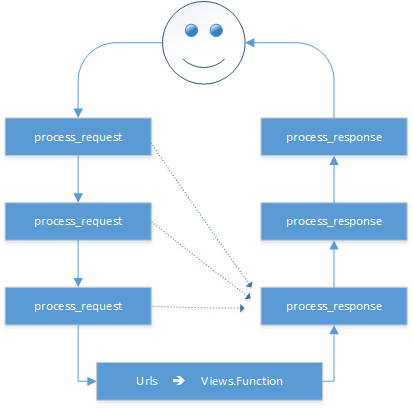
自定义中间件
1、创建中间件
class CustomMiddleware(object):
def process_request(self,request):
pass
def process_view(self, request, callback, callback_args, callback_kwargs):
i =1
def process_exception(self, request, exception):
pass
def process_response(self, request, response):
return response
2、注册中间件
如第一图所示最后一条,可根据自身业务去自定义一些中间件操作。
Django信号
Django框架内部,实际上在每一块都预留了钩子【可以理解为节点】,在这个钩子上注册某个或是几个函数,当执行某个模块进行操作的时候,都会触发执行注册的自定义函数。
用途:以models举例,不管对数据库执行什么操作,都会触发钩子函数【注意它作用的是所有数据库,不管操作哪个库都会触发】。我们可以自定义日志操作,用以记录操作的哪个库,执行的某个操作!
Django中提供了“信号调度”,用于在框架执行操作时解耦。通俗来讲,就是一些动作发生的时候,信号允许特定的发送者去提醒一些接受者。
1、Django内置信号
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
Model signals pre_init # django的modal执行其构造方法前,自动触发 post_init # django的modal执行其构造方法后,自动触发 pre_save # django的modal对象保存前,自动触发 post_save # django的modal对象保存后,自动触发 pre_delete # django的modal对象删除前,自动触发 post_delete # django的modal对象删除后,自动触发 m2m_changed # django的modal中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发 class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发Management signals pre_migrate # 执行migrate命令前,自动触发 post_migrate # 执行migrate命令后,自动触发Request/response signals request_started # 请求到来前,自动触发 request_finished # 请求结束后,自动触发 got_request_exception # 请求异常后,自动触发Test signals setting_changed # 使用test测试修改配置文件时,自动触发 template_rendered # 使用test测试渲染模板时,自动触发Database Wrappers connection_created # 创建数据库连接时,自动触发 |
对于Django内置的信号,仅需注册指定信号,当程序执行相应操作时,自动触发注册函数:
from django.core.signals import request_finished from django.core.signals import request_started from django.core.signals import got_request_exception from django.db.models.signals import class_prepared from django.db.models.signals import pre_init, post_init from django.db.models.signals import pre_save, post_save from django.db.models.signals import pre_delete, post_delete from django.db.models.signals import m2m_changed from django.db.models.signals import pre_migrate, post_migrate from django.test.signals import setting_changed from django.test.signals import template_rendered from django.db.backends.signals import connection_created def callback(sender, **kwargs): print("xxoo_callback") print(sender,kwargs) xxoo.connect(callback) # xxoo指上述导入的内容
from django.core.signals import request_finished from django.dispatch import receiver @receiver(request_finished) def my_callback(sender, **kwargs): print("Request finished!")
2、自定义信号
a. 定义信号
|
1
2
|
import django.dispatchpizza_done = django.dispatch.Signal(providing_args=["toppings", "size"]) |
b. 注册信号
|
1
2
3
4
5
|
def callback(sender, **kwargs): print("callback") print(sender,kwargs) pizza_done.connect(callback) |
c. 触发信号
|
1
2
3
|
from 路径 import pizza_done pizza_done.send(sender='seven',toppings=123, size=456) |
由于内置信号的触发者已经集成到Django中,所以其会自动调用,而对于自定义信号则需要开发者在任意位置触发。
更多:猛击这里
