
〖Python〗-- 模块系列(二)
【模块】
本节目录
- re
- logging
- os
re
re模块提供了正则表达式的相关操作
是直接面向字符串的模糊匹配
元字符包含有 . ^ $ * + ? {} [] | () \
介绍字符
. 通配符,除了换行符之外的任意字符
^ 匹配字符串的开始
$ 匹配字符串的结尾
关于次数的
* 按紧挨着的字符重复无数次 重复零次或更多次
+ 1到无穷次 重复一次或更多次
? (0,1) 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m}重复n到m次
其它的:
[] 字符集 | 或 () 分组 \ 转义

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
. ^ $ * + ? {} 一些用法import reprint(re.findall("a..x","helloalex"))#['alex'] 点匹配任意一个,但是只能匹配一个print(re.findall("^a..x","alexhelloworld"))#['alex'] ^ 匹配以什么开始print(re.findall("a..x$","helloalex"))#['alex'] $ 匹配以什么结尾print(re.findall("alex*","helloalexxxxx"))#['alexxxxx'] * 贪婪匹配 *表示匹配0次或更多次print(re.findall("alex+","helloalexxx"))#['alexxx'] +表示匹配1次或更多次print(re.findall("alex?","helloalexxxx"))#['alex'] ? 表示匹配0到1次print(re.findall("alex{1,2}","alexxxx"))#['alexx'] |
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
元字符之字符集[]存在或的关系 至少匹配一个 在字符集中含有特殊意义的只有三个 ^(非) \(转义) -(范围)print(re.findall('a[bc]d','acd'))#['acd'] []字符集中有或的概念print(re.findall('[a-z]','acd'))#['a', 'c', 'd'] #范围a—z 都可以匹配到print(re.findall('[.*+]','a.cd+'))# ['.', '+']print(re.findall('[1-9]','45dha3'))# ['4', '5', '3']print(re.findall('[^ab]','45bdha3'))# ['4', '5', 'd', 'h', '3'] ^ 代表非的概念print(re.findall('[\d]','45bdha3'))# ['4', '5', '3'] \d 表示0到9的数字 |
|
1
2
3
4
5
6
7
8
9
10
|
关于转义的实例 \import reret=re.findall('c\l','abc\le')print(ret)#[]ret=re.findall('c\\l','abc\le')print(ret)#[]ret=re.findall('c\\\\l','abc\le')print(ret)#['c\\l']ret=re.findall(r'c\\l','abc\le')print(ret)#['c\\l'] # 一张图解释为什么要用到这么多 \ 的原因 |
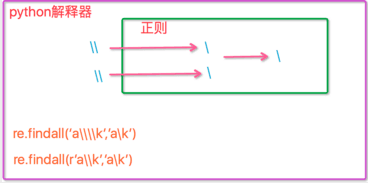
|
1
2
3
4
5
6
7
|
分组() 的用法print(re.findall(r'(ad)+', 'addad')) # ['ad', 'ad']ret=re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com')print(ret.group())#23/comprint(ret.group('id'))#23 |
|
1
2
3
4
|
| 或ret=re.search('(ab)|\d','rabhdg8sd')print(ret.group())#ab 先匹配到哪个取哪个 group表示取值 |
re下面的方法
常用的功能函数包括:compile、search、match、split、findall(finditer)、sub(subn)
comoile
|
1
2
3
|
obj=re.compile('\d{5}') # compile是编译的意思,编译好一个规则,再进行调用它ret=obj.search('abc12345ee')print(ret.group())#12345 |
serch
|
1
2
3
4
|
print(re.search('al','alvin yuan').group()) # al# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 |
findall
|
1
2
3
|
print(re.findall('a','alvin yuan'))# ['a', 'a']# 返回所有满足匹配条件的结果,放在列表里 |
match
|
1
2
|
ret = re.match('a','abc').group() # match只是从开始匹配,匹配成功则返回对象print(ret) |
split
|
1
2
|
ret=re.split('[ab]','abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割print(ret)#['', '', 'cd'] # 结果放在列表中 |
sub(subn)
|
1
2
3
4
|
ret=re.sub('\d','abc','alvin5yuan6',1) # sub里面至少有个三个参数 依次是 匹配规则 替换内容 源数据 也可以有四个,最后一个参数是匹配次数print(ret)#alvinabcyuan6ret=re.subn('\d','abc','alvin5yuan6') # 显示匹配了多少次,替换print(ret)#('alvinabcyuanabc', 2) |
finditer
|
1
2
3
4
5
6
|
ret=re.finditer('\d','ds3sy4784a')print(ret) #<callable_iterator object at 0x10195f940>print(next(ret).group())print(next(ret).group())# 结合迭代器规则,返回的是一个迭代器对象,应用于处理很多的数据,用next的可以逐一取 |
?: 是取消优先级 ?P的含义
|
1
2
|
print(re.search("(?P<name>[a-z]+)(?P<age>\d+)","alex36wusir27").group("name"))# alex 注释 ?P是定义死的 <定义分组名> 后面可根据分组名取值 |
|
1
2
3
4
|
print(re.findall("www\.(baidu|taobao)\.com","sdaswww.baidu.comsdf"))# ['baidu'] 优先给分组的内容,其实已经匹配到了print(re.findall("www\.(?:baidu|taobao)\.com","sdaswww.baidu.comsdf"))# ['www.baidu.com'] ?: 表示去掉括号内的优先级 |
logging
用于便捷记录日志且线程安全的模块
日志级别大小关系为:CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET,当然也可以自己定义日志级别。
level=logging.DEBUG 设置日志级别
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import logginglogging.basicConfig(filename='log.log', format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', level=logging.DEBUG)logging.debug('debug') # 分五个等级logging.info('info')logging.warning('warning')logging.error('error')logging.critical('critical')logging.log(10,'log') |
format 设置输出格式
%(levelno)s: 打印日志级别的数值
%(levelname)s: 打印日志级别名称
%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(threadName)s: 打印线程名称
%(process)d: 打印进程ID
%(message)s: 打印日志信息
datefmt 设置日期格式,同 time.strftime()
%Y 年 %m 月 %D日 %H时 %M分 %S 秒
filename 设置文件路径
filemode 设置文件打开模式
注:没有filename和filemode直接输出
os
用于提供系统级别的操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cdos.curdir 返回当前目录: ('.')os.pardir 获取当前目录的父目录字符串名:('..')os.makedirs('dir1/dir2') 可生成多层递归目录os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirnameos.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirnameos.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 ***os.remove() 删除一个文件os.rename("oldname","new") 重命名文件/目录 ***os.stat('path/filename') 获取文件/目录信息,相关信息的介绍 size 文件大小 atime 上次访问时间 mtime 上次修改时间 ctime 查看创建时间os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"os.pathsep 用于分割文件路径的字符串os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'os.system("bash command") 运行shell命令,直接显示os.environ 获取系统环境变量os.path.abspath(path) 返回path规范化的绝对路径os.path.split(path) 将path分割成目录和文件名二元组返回os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素os.path.exists(path) 如果path存在,返回True;如果path不存在,返回Falseos.path.isabs(path) 如果path是绝对路径,返回Trueos.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回Falseos.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回Falseos.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略,涉及文件路径拼接就用它os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 |

上图所示,是得到
os.path.dirname是返回上一级目录
关于os模块的补充


os.walk(top, topdown=True, onerror=None, followlinks=False) 可以得到一个三元tupple(dirpath, dirnames, filenames), 第一个为起始路径,第二个为起始路径下的文件夹,第三个是起始路径下的文件。 dirpath 是一个string,代表目录的路径, dirnames 是一个list,包含了dirpath下所有子目录的名字。 filenames 是一个list,包含了非目录文件的名字。 这些名字不包含路径信息,如果需要得到全路径,需要使用os.path.join(dirpath, name). 通过for循环自动完成递归枚举 # 做个简单的例子,输出crm目录的下所有文件的路径信息 for a,b,c in os.walk(str(PATH) + os.sep + "crm" ): for item in c: # print(item) print(os.path.join(a,item)) 输出 F:\python\crm\.idea\.name F:\python\crm\.idea\crm.iml F:\python\crm\.idea\encodings.xml F:\python\crm\.idea\misc.xml F:\python\crm\.idea\modules.xml F:\python\crm\.idea\workspace.xml F:\python\crm\bin\bin.py F:\python\crm\bin\__init__.py F:\python\crm\bin\__pycache__\bin.cpython-35.pyc F:\python\crm\core\admin.py F:\python\crm\core\coures.py F:\python\crm\core\grade.py F:\python\crm\core\school.py F:\python\crm\core\student.py F:\python\crm\core\teacher.py F:\python\crm\core\__init__.py F:\python\crm\core\__pycache__\admin.cpython-35.pyc F:\python\crm\core\__pycache__\coures.cpython-35.pyc F:\python\crm\core\__pycache__\grade.cpython-35.pyc F:\python\crm\core\__pycache__\school.cpython-35.pyc F:\python\crm\core\__pycache__\student.cpython-35.pyc F:\python\crm\core\__pycache__\teacher.cpython-35.pyc F:\python\crm\core\__pycache__\__init__.cpython-35.pyc F:\python\crm\db\admin\alex F:\python\crm\db\coures\23eeeb4347bdd26bfc6b7ee9a3b755dd F:\python\crm\db\coures\34d1f91fb2e514b8576fab1a75a89a6b F:\python\crm\db\coures\c71e8d17d41c21de0d260881d69662ff F:\python\crm\db\coures\df5fb5e33c5585bb0c48107c57cece9b F:\python\crm\db\coures\e206a54e97690cce50cc872dd70ee896 F:\python\crm\db\grade\270c42ba7614f1a475f61dfcb397a621 F:\python\crm\db\grade\817ee0b8010393ff3b4483e703663551 F:\python\crm\db\school\17811d3caeff9648f48b5a553c806c63 F:\python\crm\db\school\b035c88ee6f5270ccff67a591d0e21ec F:\python\crm\db\school\bb0ac3d8eb8f2c2f6fe336c5e9957392 F:\python\crm\db\school\e523d5f211747bdfc742f50463577f74 F:\python\crm\db\student\6e7e12c264fb3e1f456b0782f47e4af6 F:\python\crm\db\student\a0b5e2d3a97d7a19ec6d2da830f609b2 F:\python\crm\db\student\a995b03ed63f8c7128a83c984b89aa50 F:\python\crm\db\student\fe01b2ba5ec0146e5d4b0885822556ef F:\python\crm\db\student\ff4916088e836d268a9d72f8929bac06 F:\python\crm\db\teacher\08319d4fed47c8ed828ebabd5a91563b F:\python\crm\db\teacher\0d1d5cd3623144f692fb771580b92288 F:\python\crm\db\teacher\5d00d0762936aedda519d63c2e4a2a40 F:\python\crm\db\teacher\6a7ece82e4ed94a475dab275891d5036 F:\python\crm\lib\ceshi.py F:\python\crm\lib\readme F:\python\crm\lib\readwrite.py F:\python\crm\lib\__init__.py F:\python\crm\lib\__pycache__\readwrite.cpython-35.pyc F:\python\crm\lib\__pycache__\__init__.cpython-35.pyc
import os res = os.path.getsize(os.path.join("F:\python\PycharmProjects\date2017.1.8","path_search.py")) print(res) ret = os.stat(os.path.join("F:\python\PycharmProjects\date2017.1.8","path_search.py")).st_size print(ret) f = open(os.path.join("F:\python\PycharmProjects\date2017.1.8","path_search.py"),"rb") print(len(f.read())) 输出结果相同
