deeplearning.ai神经网络与深度学习 第二章15-18notes
目录
Numpy中的广播
Python/numpy的一些说明
关于逻辑回归代价函数的理论推导
Numpy中的广播
定义:
广播是numpy对不同shape的array进行数值计算的方式,符合一定规则的前提下,将较小的array“广播”成更大的、可以计算的array。
广播的规则:
1.让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分都通过在前面加1补齐
2.输出数组的shape是输入数组shape的各个轴上的最大值
3.如果输入数组的某个轴和输出数组的对应轴的长度相同或者其长度为1时,这个数组能够用来计算,否则出错
4.当输入数组的某个轴的长度为1时,沿着此轴运算时都用此轴上的第一组值
解释:
例1
example 1:
A (2d array): 2 x 3 B (1d array): 3 Result (2d array): 2 x 3
如上例子所示,A是一个2x3的矩阵,B是一个3个元素的数组(3,),根据规则1,B中不足的地方应该用1来补齐,所以补齐完的结果是1x3矩阵
根据规则2可知,输出数组的shape是输入各轴的最大值,所以轴0的最大值来自A数组为2,轴1的最大值来自A和B是3,所以输出是一个2x3的数组
例2
example 2: A (3d array) : 2 x 3 x 4 B (2d array) : 1 x 4 result(3d array) : 2 x 3 x 4 A (3d array) : 2 x 3 x 4 B (2d array) : 2 x 4 error!
如上图第一个例子,B数组的轴0为0,根据规则1,应该用1补齐;轴1为1,满足规则3中两个数组的对应轴长度不相等但是其中一个长度为1,故可以计算;轴2为4,与A数组的轴2长度相等,满足规则3;综上两个数组可以进行广播;根据规则2,结果是一个2x3x4的数组
上图第二个例子中,B的轴1长度为2,与A的长度不相等且长度不为1,根据规则3无法进行广播
例 3
>>> import numpy as np >>> a = np.arange(0, 6).reshape(6, 1) >>> a array([[ 0], [1], [2], [3], [4], [5]]) >>> a.shape (6, 1) >>> b = np.arange(0, 5) >>> b.shape (5,) >>> c = a + b >>> print c [[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8] [5 6 7 8 9]]
上图实例援引自官网文档
a是一维列矩阵(6,1),b是一维行矩阵(1,5),这里b是经过规则1补充得到的。在行和列方向上分别取最大值,根据规则2结果就应该是(6,5)的矩阵。a和b在参与计算之前都要先进行广播,即复制延伸。根据规则4,a延伸成了: [[0, 0, 0, 0, 0], [1, 1, 1, 1, 1], [2, 2, 2, 2, 2], [3, 3, 3, 3, 3], [4, 4, 4, 4, 4], [5, 5, 5, 5, 5]] b延伸成了: [[0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4], [0, 1, 2, 3, 4]] 现在经过广播之后a和b都是(6,5)的矩阵了,然后按照对应元素相加就得到最终结果了。
Python/numpy的一些说明
建议在写神经网络时候不要写秩为1的数组
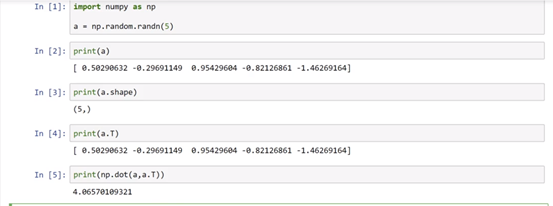
如上图所示,a = np.random.randn(5) 生成的是一个随机产生的5个变元的数组,它既不是行向量也不是列向量,如果你打印出a的shape的话,它实际是(5, )这种结构,这种结构的存在可能会对我们编程产生一些意想不到的错误。比如你打印a的转置,你不会得到一个列向量,它的shape仍然是(5, );所以这也不难明白为什么后面的矩阵乘法无法打印出正确结果了。
综上所述,在进行神经网络编程的时候,我们应该尽量使用行向量和列向量,尽量避免引入秩为1的数组结构,那么行向量和列向量如何表示呢?
行向量:a = np.random.randn((1,5)) 这代表随机生成一个1x5的矩阵也就是行向量
列向量:a = np.random.randn(5,1)) 这代表随机生成一个5x1的矩阵也就是列向量
建议使用assert函数
assert(condition)函数是一个判断括号内部条件是否正确的函数,如果后面的条件错误,则程序停止运行,运用这个函数实时检验自己矩阵的shape是否正确是保障程序正常的好方法
建议使用reshape函数
reshape((m,n))函数,是一个将矩阵调整成一个mxn的矩阵,吴恩达老师说这是一个好习惯,因为复杂度为O(1),所以不要吝惜使用它哦QAQ。
关于逻辑回归代价函数的理论推导
首先我们来看, θ 函数的值有特殊的含义,它表示 hθ(x)结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
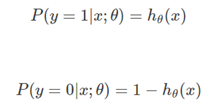
根据上式,接下来我们可以使用概率论中极大似然估计的方法去求解损失函数,首先得到概率函数为:
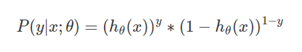
因为样本数据(m个)独立,所以它们的联合分布可以表示为各边际分布的乘积,取似然函数为:
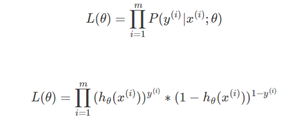
取对数似然函数: