


一、模块调用
1.创建一个目录project,并且在目录下面创建两个文件
project/
一 pub.py
L一 count.py
在pub.py文件中创建add函数。
#pub.py
def add(a,b):
return a+b
在相同的目录下再创建一个文件count.py,调用pub.py文件中的add()函数
#count.py from pub import add print (add(4,5))#输出结果为“9”
这样即实现了跨文件的函数调用
2.跨目录模块调用
目录结构如下所示
project/
------model/
L一 pub.py
L一 count. py
#count.py from model.pub import add print (add(4, 5))
在Python 2中将会抛出Impo口Eπor: 找不到名字为model的模块,错误如下图所示, 我们稍后再讨论 Python 2如何才能找到model下面的pub.py文件。

project/
------model/
L一 count.py
L一 new_count.py
L一 test. py
代码如下所示:
#count.py
class A():
def add(self,a,b):
return a+b
#new_count.py
from count import A
class B(A):
def sub(self,a,b):
return a-b
result=B().add(2,5)
print result #输出结果为“7”
目前,都没有问题,接下来创建与model目录平级的test.py
#test.py from model import new_count test=new_count.B() test.add(2,5)
输出结果如下图所示
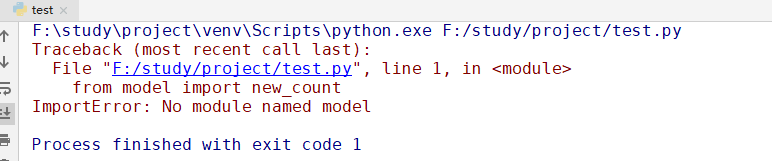
知识延伸: 当Python在执行import语句时,到底进行了什么 操作。按照python的文档, 它执行了如下操作: 第l步, 创建一个新的module对象(它可能包含多个module) ; 第2步, 把这个module对象插到sys.module中; 第3步, 装载module的代码(如果需要,则必须先编译); 第4步, 执行新的module中对应的代码 在执行第3步时, 首先需要找到module程序所在的位直 ,搜索的顺序是:当前路径(以及从当前目录指定的sys.path),PythonPATH,再后是Python 安装时设直的相关的默认路径。 正因为存在这样的顺序 ,所以如果当前路径或 PythonPATH中存在与标准module同样的module,则会覆盖标准module。也就 是说, 如果当前目录下存在xml.py, 那么在执行import xml 时, 导入的是当前目录下的module, 而不是系统标准的xml。 了解了这些后, 我们就可以先构建一个package,以普通module的方式导入,这样即可直接访问此package中的各个 module。 Python 2中的package必须包含一个__init_.py的文件。
调整后的代码如下所示:
#test.py
#coding:utf-8
import sys
sys.path.append("./model")#将model目录添加到系统环境变量path下
from model import new_count
test=new_count.B()
print (test.add(5,5))
但是运行之后,还是报错

我们使用的是python2,因此在model目录下面还需要在.../model/目录下创建一个__init_.py 文件(文件内容可以为空), 用来标识这是一个标准的包含了 Python 模块的目录。如下图所示
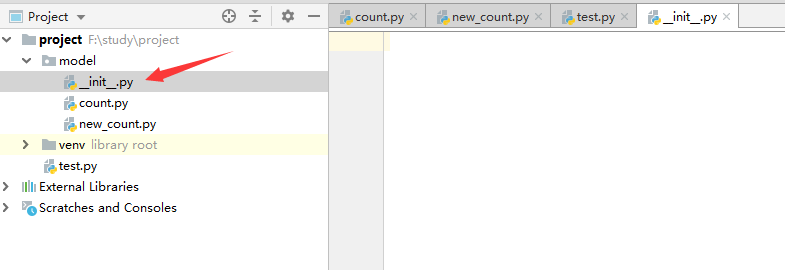
再次运行test.py文件,即可正常运行,输出结果如下图所示

