ANTLR笔记3 - ANTLRWorks
安装配置
需要JRE或者JDK
下载ANTLRWorks: http://www.antlr.org/works/index.html
查看DFA需要使用Graphviz,下载安装: http://www.graphviz.org/
运行antlrworks-1.1.7.jar,在菜单File -> Preferences中设置DOT path为Graphviz安装路径"bin"dot.exe。这里还可以设置ANTLR的临时工作目录、global options,Java的CLASSPATH、javac路径等。
编辑
打开文章后面给出的Expr.g语法文件。
1. Syntax Diagram。选择一个语法规则,在Syntax Diagram窗口可以看到语法图,例如stat:
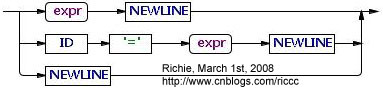
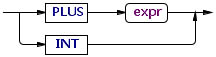
这样可以了解ANTLR是如何解析语法描述的,例如ANTLR笔记2中提到的expr: PLUS expr | INT;,语法图如下,这样就不会理解为expr: PLUS (expr | INT);这种效果。
勾选Syntax Diagram右下角的NFA可以查看NFA,例如stat:

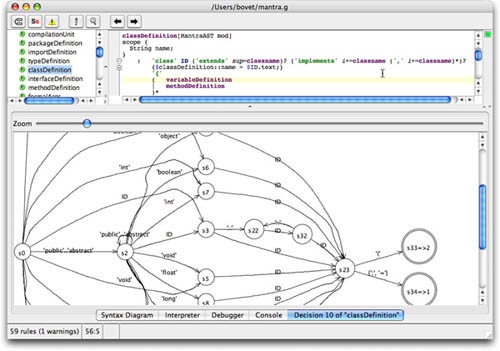
2. DFA。菜单Grammar -> Show Tokens DFA可以查看语法的DFA,例如官方网站的截图:
3. 一些不错的编辑操作。
a.) 查看语法规则的使用状况。选择某个语法规则,Alt+F7。
b.) 快速定位语法规则。Ctrl+Shift+B。
解释
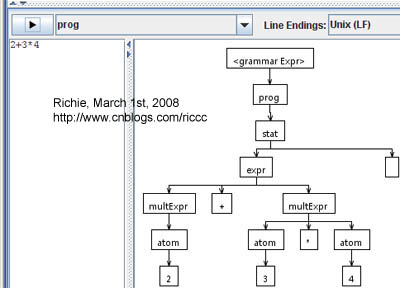
在Interpreter窗口输入2+3*4,并加上一个回车,选择prog语法规则,点击运行按钮,分析结果语法树如下:
调试
Ctrl+D调出调试窗口,文本输入2+3*4,并加上一个回车,Start Rule选择prog,确定。然后就可以单步调试ANTLR语法解析过程,可以看到每个步骤当前执行的一些信息,例如输入字符、分析结果语法树、堆栈情况等。
ANTLR只能调试Java的,C#的调试参考http://www.antlr.org/wiki/display/ANTLR3/Antlr+3+CSharp+Target,我试了一下没有成功。
附示例语法文件Expr.g
需要JRE或者JDK
下载ANTLRWorks: http://www.antlr.org/works/index.html
查看DFA需要使用Graphviz,下载安装: http://www.graphviz.org/
运行antlrworks-1.1.7.jar,在菜单File -> Preferences中设置DOT path为Graphviz安装路径"bin"dot.exe。这里还可以设置ANTLR的临时工作目录、global options,Java的CLASSPATH、javac路径等。
编辑
打开文章后面给出的Expr.g语法文件。
1. Syntax Diagram。选择一个语法规则,在Syntax Diagram窗口可以看到语法图,例如stat:
这样可以了解ANTLR是如何解析语法描述的,例如ANTLR笔记2中提到的expr: PLUS expr | INT;,语法图如下,这样就不会理解为expr: PLUS (expr | INT);这种效果。
勾选Syntax Diagram右下角的NFA可以查看NFA,例如stat:
2. DFA。菜单Grammar -> Show Tokens DFA可以查看语法的DFA,例如官方网站的截图:
3. 一些不错的编辑操作。
a.) 查看语法规则的使用状况。选择某个语法规则,Alt+F7。
b.) 快速定位语法规则。Ctrl+Shift+B。
解释
在Interpreter窗口输入2+3*4,并加上一个回车,选择prog语法规则,点击运行按钮,分析结果语法树如下:
调试
Ctrl+D调出调试窗口,文本输入2+3*4,并加上一个回车,Start Rule选择prog,确定。然后就可以单步调试ANTLR语法解析过程,可以看到每个步骤当前执行的一些信息,例如输入字符、分析结果语法树、堆栈情况等。
ANTLR只能调试Java的,C#的调试参考http://www.antlr.org/wiki/display/ANTLR3/Antlr+3+CSharp+Target,我试了一下没有成功。
附示例语法文件Expr.g
grammar Expr;
@header {
package test;
import java.util.HashMap;
}
@lexer::header {package test;}
@members {
/** Map variable name to Integer object holding value */
HashMap memory = new HashMap();
}
prog: stat+ ;
stat: expr NEWLINE {System.out.println($expr.value);}
| ID '=' expr NEWLINE
{memory.put($ID.text, new Integer($expr.value));}
| NEWLINE
;
expr returns [int value]
: e=multExpr {$value = $e.value;}
( '+' e=multExpr {$value += $e.value;}
| '-' e=multExpr {$value -= $e.value;}
)*
;
multExpr returns [int value]
: e=atom {$value = $e.value;} ('*' e=atom {$value *= $e.value;})*
;
atom returns [int value]
: INT {$value = Integer.parseInt($INT.text);}
| ID
{
Integer v = (Integer)memory.get($ID.text);
if ( v!=null ) $value = v.intValue();
else System.err.println("#ff0000 variable "+$ID.text);
}
| '(' e=expr ')' {$value = $e.value;}
;
ID : ('a'..'z'|'A'..'Z')+ ;
INT : '0'..'9'+ ;
NEWLINE:'"r'? '"n' ;
WS : (' '|'"t')+ {skip();} ;
@header {
package test;
import java.util.HashMap;
}
@lexer::header {package test;}
@members {
/** Map variable name to Integer object holding value */
HashMap memory = new HashMap();
}
prog: stat+ ;
stat: expr NEWLINE {System.out.println($expr.value);}
| ID '=' expr NEWLINE
{memory.put($ID.text, new Integer($expr.value));}
| NEWLINE
;
expr returns [int value]
: e=multExpr {$value = $e.value;}
( '+' e=multExpr {$value += $e.value;}
| '-' e=multExpr {$value -= $e.value;}
)*
;
multExpr returns [int value]
: e=atom {$value = $e.value;} ('*' e=atom {$value *= $e.value;})*
;
atom returns [int value]
: INT {$value = Integer.parseInt($INT.text);}
| ID
{
Integer v = (Integer)memory.get($ID.text);
if ( v!=null ) $value = v.intValue();
else System.err.println("#ff0000 variable "+$ID.text);
}
| '(' e=expr ')' {$value = $e.value;}
;
ID : ('a'..'z'|'A'..'Z')+ ;
INT : '0'..'9'+ ;
NEWLINE:'"r'? '"n' ;
WS : (' '|'"t')+ {skip();} ;

