[翻译-收藏] Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005
中文版地址:SQL Server 2005 中的批编译、重新编译和计划缓存问题
翻译了一大段才发现中文版。因为微软经常将知识库的文章移动,还是在自己blog里收藏起来了。
Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005
By Arun Marathe; Revised by Shu Scott
Published: July 2004
Updated: December 2006
摘要:本文讲解SQL Server 2005如何缓存和重用批SQL(batch SQL)的执行计划,为最大限度重用执行计划提供最佳实践。另外也讲解了批SQL重编译的场景,为降低和消除不必要的重编译提供最佳实践。
Goals of this white-paper
本文有几个目的。首先介绍SQL Server 2005如何缓存和重用批SQL的执行计划,为最大限度重用执行计划提供最佳实践。另外也讲解了批SQL重编译的场景,为降低和消除不必要的重编译提供最佳实践,以及SQL Server 2005语句级重编译的特性。文章介绍了很多有用的监测工具,用于分析查询编译、重编译过程,执行计划缓存、重用等。整篇文章通过比较SQL Server 2000和SQL Server 2005的行为,使读者能够较好地理解。文章中的描述适用于SQL Server 2000和SQL Server 2005,对于这两个版本有差异的地方会明确的指出来。
这篇文章主要针对三种读者:
用户:使用、维护、开发SQL Server应用程序的人;不大熟悉SQL Server 2005的人;以及需要从SQL Server 2000进行移植的人,这些人将从本文中找到有用的信息。
开发者:SQL Server开发者将从本文得到有用的背景知识。
Recompilations: Definition
查询语句、批SQL、存储过程、触发器、预处理语句以及动态SQL语句(本文后面将其叫做批SQL)先被编译为执行计划,然后由SQL Server执行,得到结果记录集。
批SQL包含一个或多个SELECT、INSERT、UPDATE和DELETE语句;存储过程可以看作是一行行T-SQL语句,通过SET、IF、WHILE、DECLARE等控制结构粘合起来;象CREATE、DROP等属于DDL语句;GRANT、DENY、REVOKE等是权限操作相关的语句。批SQL中可以包含定义和使用CLR的语句,例如用户自定义类型、函数、存储过程、聚合等。
编译过的执行计划保存在SQL Server执行计划缓存的内存区域,以便重用,节省编译成本。注意在SQL Server文档中,“存储过程缓存”这个词就是指“执行计划缓存”,用“执行计划缓存”更准确,因为它缓存的不仅仅是存储过程的执行计划。
在SQL Server中,编译过程有时也指重新编译。
重编译的定义:一个批SQL可能被编译成一个或多个执行计划集合,SQL Server在执行某个执行计划时,先检查执行计划的有效性和最优性,如果检查失败,相应的语句或者整个批SQL将被重新编译,可能生成另外一个不同的执行计划。这个编译过程称作重编译。
注意特定情况下批SQL的执行计划不需要缓存,实际上某些类型的批SQL执行计划从来不会缓存,但仍然存在重编译过程。例如一个包含超过8kb大文本的批SQL语句。假设这样的批SQL创建一个临时表,向其中插入20条记录,可能第7条插入操作会导致重编译,但因为大文本的存在,整个批SQL并未被缓存。
SQL Server中大部分重编译是基于一些必要的理由,有些为了确保语句的正确性,其它一些是因为数据的变化而试图找出一个更优化的执行计划。然而另外一些时候,重编译会极大的减慢批SQL语句的执行,因此有必要减少重编译。
Comparison of Recompilations in SQL Server 2000 and SQL Server 2005
SQL Server 2000重编译时,批SQL中的所有语句被重新编译,而并不是引起重编译的那一句。SQL Server 2005在这个基础上作了改进,可以只重新编译引起重编译的那一个语句,而并不是整个批SQL,这就是SQL Server 2005的“语句级重编译”特性。另外,SQL Server 2005在重编译时消耗的CPU和内存更少,需要的编译锁也更少。
语句级重编译一个明显的好处是,我们不再需要将一个大的存储过程切分成多个小的存储过程,用这种方式来避免整个大存储过程重编译的时间。
Plan Caching
在理解重编译问题之前,先了解一个相关且重要的内容:查询计划缓存。查询计划缓存用于重用,如果查询计划不被缓存,重用可能性为0,这样在每次执行时都需要编译,导致较差的性能。比较少的情况下,的确没有必要缓存,文章后面会指出一些这样的场景。
SQL Server可以缓存很多类型的查询计划,下面列举了一些不同的类型。对每一种类型,我们描述了重用的必要条件,注意这些条件并不一定全面,读者将在文章的后续部分获得全面的了解。
1. Ad-hoc queries
一个ad-hoc查询包含一个SELECT、INSERT、UPDATE或者DELETE语句,SQL Server对两个ad-hoc查询执行文本比较确定是否可以重用,比较过程是大小写和空格敏感的。例如下面两个查询不会采用同一个查询计划(本文中所有的T-SQL代码片断根据SQL Server 2005的AdventureWorks数据库编写)。
FROM Sales.SalesOrderDetail
GROUP BY ProductID
HAVING AVG(OrderQty) > 5
ORDER BY ProductID
SELECT ProductID
FROM Sales.SalesOrderDetail
GROUP BY ProductID
HAVING AVG(OrderQty) > 5
ORDER BY ProductId
2. Auto-parameterized queries
对于某些查询,SQL Server 2005将文本常量替换成变量,编译成查询计划,如果随后的查询只是这些常量的值不相同,将匹配上这个自动参数化的查询。通常,SQL Server 2005将对那些常量值不会影响查询计划的查询进行自动参数化处理。
附录A包含一个SQL Server 2005不会进行自动参数化处理的语句类型列表。
作为SQL Server 2005自动参数化的示例,下面两个查询将重用同一个查询计划:
FROM Sales.SalesOrderDetail
WHERE ProductID > 1000
ORDER BY ProductID
SELECT ProductID, SalesOrderID, LineNumber
FROM Sales.SalesOrderDetail
WHERE ProductID > 2000
ORDER BY ProductID
上面查询的自动参数化形式如下:
FROM Sales.SalesOrderDetail
WHERE ProductID > @p1
ORDER BY ProductID
如果查询中的常量会影响查询计划,这样的查询不会被自动参数化处理。这样的查询计划也会被缓存,但其中嵌入了常量,并不是使用类似@p1参数替代。
SQL Server的"showplan"特性可以用来确定一个查询是否被自动参数化处理了,例如,可以在"set showplan_xml on"模式下提交查询,如果showplan的结果包含类似@p1、@p2这样的参数占位符,那么这个查询就被自动参数化处理了,否则就没有。SQL Server xml形式的showplan既有编译时刻('showplan_xml'和'statistics xml' 模式)也有执行时刻(仅'statistics xml'模式)的参数值信息。
3. sp_executesql procedure
这是促进查询计划重用的方法之一,使用sp_executesql时,用户或应用程序明确的将参数指定出来,例如:
FROM Production.Product p
INNER JOIN Production.ProductDescription pd
ON p.ProductID = pd.ProductDescriptionID
WHERE p.ProductID = @a', N'@a int', 170
EXEC sp_executesql N'SELECT p.ProductID, p.Name, p.ProductNumber
FROM Production.Product p INNER JOIN Production.ProductDescription pd
ON p.ProductID = pd.ProductDescriptionID
WHERE p.ProductID = @a', N'@a int', 1201
可以用一个接一个排列的方式指定多个参数,实际的参数值跟在参数定义之后,计划的重用根据查询文本(sp_executesql后面的第一个参数)和查询文本后面所有的参数(上面示例中的N'@a int')确定。参数值(170和1201)不会用来匹配,因此前面的示例中,两个sp_executesql的查询计划可以被重用。
4. Prepared queries
这个方法跟sp_executesql方法一样,是促进查询计划重用的方法。批SQL语句在预处理(prepare)时发送,SQL Server 2005返回一个句柄,用于执行时刻调用这个批SQL语句,在执行时刻,句柄和参数值被发送给服务器。ODBC和OLE DB通过SQLPrepare/SQLExecute和ICommandPrepare暴露这个功能,例如一个使用ODBC的代码片断看起来是这样:
FROM Sales.SalesOrderDetail sod
WHERE SalesOrderID < ?
GROUP BY SalesOrderID
ORDER BY SalesOrderID", SQL_NTS)
SQLExecute(hstmt)
5. Stored procedures (including triggers)
存储过程用来促进查询计划重用,计划重用基于存储过程或者触发器的名称(无法直接调用触发器)。SQL Server内部将存储过程名字转换成ID,后续计划重用基于这个ID值。触发器的计划缓存和重编译行为与存储过程有点差别,我们会在适当的时候指出这种差异。
存储过程第一次编译之后,后续执行时提供的参数值用来优化存储过程中的语句,这个处理叫做参数嗅探。如果参数值是典型的,对这个存储过程的大部分调用将从这个有效的查询计划受益。文章的后续部分将讨论一些技巧,防止非典型的参数值降低查询计划重用效率。
6. Batches
批SQL语句的文本能够匹配时查询计划可以被重用,这个匹配也是大小写和空格敏感的。
7. Executing queries via EXEC ( ... )
SQL Server 2005能够对使用EXEC执行的语句,即"动态SQL",的查询计划进行缓存,例如:
INNER JOIN Production.ProductPhoto ph' + '
ON pr.ProductID = ph.ProductPhotoID' +
' WHERE pr.MakeFlag = ' + @mkflag )
这个示例中,查询计划缓存基于执行时刻使用变量@mkflag的实际值拼接之后的SQL字符串。
Multiple levels of caching
多层次的缓存匹配彼此间是独立的,理解这一点很重要。下面是一个示例,假设批SQL 1(不是存储过程)包含下面这个语句:
EXEC dbo.procA
批SQL 2(也不是存储过程)跟批SQL 1的文本不匹配,但也包含"EXEC dbo.procA"这一句,引用同一个存储过程。这种情况下,批SQL 1和批SQL 2的查询计划并不能匹配,然而不管这两个批SQL在什么时候执行"EXEC dbo.procA",如果其中一个在另一个之前执行这一句,并且procA的查询计划还在缓存中,就有可能重用这个查询计划(以及执行上下文重用-execution context reuse,这点在后面解释)。每个procA的调用都有自己的执行上下文,这些执行上下文可能是重新创建的(如果所有已经存在的执行上下文都在使用中),也可能是重用的(如果存在可用的执行上下文)。使用EXEC执行动态SQL,或者两个批SQL中存在相同的自动参数化语句等,这种重用也可能发生。简言之,下面三种类型的批SQL在自身层级上拥有查询缓存,它们可能命中缓存,而与包含它们的批SQL是否命中缓存没有关系。
● 象"EXEC dbo.stored_proc_name"这样执行存储过程
● 象"EXEC query_string"这样执行动态SQL
● 自动参数化的查询
上面提到的规则对于存储过程是个特例,例如如果两个不同的存储过程都包含语句"EXEC procA",procA的查询计划和执行上下文不会重用。
Query plans and execution contexts
可缓存的批SQL提交给SQL Server 2005执行时,先编译成查询计划,放入缓存。查询计划是一份只读、可重入的数据,在多个用户间共享。缓存中的查询计划在任何时候基本都存在两个实例,一个用于串行执行,另一个用于并行执行,用于并行的适用于所有并行度(degrees of parallelism)。(严格的讲,如果一个用户在两个不同的会话中,使用相同的会话设置同时提交同一个查询,并发的到达SQL Server 2005,它们在执行时会存在两份查询计划,但执行结束后,只有一份被放入缓存中)
从执行计划引申出执行上下文(execution context)的概念,执行上下文是用于执行产生结果集的东西,也被缓存和重用。每个执行的批SQL都拥有一个执行上下文,用于保存数据(例如参数的值)。虽然执行上下文可重用,但不可重入(只支持单线程),就是说任何时候,一个执行上下文只能用于一个批SQL的执行,执行开始后,这个执行上下文不会分配给其它会话或用户。
查询计划和派生的执行上下文之间的关系如下图所示,图中有一个查询计划,三个派生的执行上下文,执行上下文包含参数值以及用户相关的信息,而查询计划并不了解这些信息。
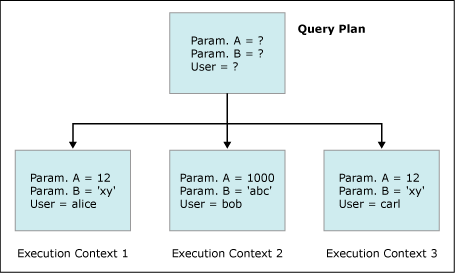
缓存中查询计划可以有多个对应的执行上下文,但执行上下文不能脱离查询计划而存在。从缓存中删除查询计划时,相关的执行上下文也被删除。
当从缓存中搜索可重用的查询计划时,匹配处理基于查询计划,而不是执行上下文。如果发现可以重用的查询计划,当存在可用的执行上下文时将重用执行上下文,否则重新创建一个执行上下文。因此查询计划重用并不依赖于执行上下文的重用。
执行上下文采用"动态"的方式从查询计划派生,在批SQL执行开始时创建执行上下文的主要结构,随着执行过程的继续,将创建其它必要的部分,加入到执行上下文的主要结构上。这意味着就算将用户信息和参数值都删除了,执行上下文也不一定相同。因为从同一个查询计划派生的执行上下文结构可以彼此不同,它们用于某个查询执行过程时性能上也存在细微的差异,当缓存中的查询计划使用频繁时,这种差异会缩小,最后达到一个稳定状态。
示例:假设一个批SQL包含一个"if"语句,当B开始执行时,将为B创建一个执行上下文。假设第一次执行时执行了"if"的"true"分支,然后在第一次执行时另一个连接也提交B,因为仅有的一个执行上下文正被使用,因此将创建另一个执行上下文分配给第二个连接。假设第二个连接执行的是"if"的"false"分支,在两个连接执行结束后,第三个连接提交了B。如果第三个连接需要执行B的"true"分支,SQL Server选择第一个连接的执行上下文分配给它,比选择第二个连接的执行上下文会稍微快一点。
就算对一个分支S的调用顺序不同,它的执行上下文也可以被重用。例如一个调用顺序可能是"stored proc 1 --> stored proc 2 --> S",而另外一个调用顺序可能是"stored proc 3 --> S",第一个执行S的执行上下文也可以在第二个S的执行时重用。
如果批SQL执行时产生的错误等级为11或者更高,执行上下文会被销毁,如果产生警告(错误等级为10),执行上下文并不会被销毁,因此,即使没有内存压力(会导致收缩查询计划缓存),缓存中执行上下文的数量(对于某个查询计划的)也会增加或减少。
并行计划的执行上下文不会缓存。SQL Server编译一个并行计划的必要条件是,排出处理器邦定屏蔽(processor affinity mask)设置后剩余的最小处理器数量,和服务器端选项最大并行度(max degree of parallelism)的值(可以使用存储过程"sp_configure"设置)大于1。即使编译了一个并行查询计划,SQL Server的"查询执行"组件还可能从它生成串行的执行上下文,从并行计划派生的任何执行上下文,包括并行的和串行的,都不会被缓存。但是并行查询计划是被缓存的。
Query plan caching and various SET options (showplan-related and others)
各种SET选项,大部分和显示执行计划相关的,会通过复杂的方式影响查询计划和执行上下文的编译、缓存以及重用,下面的表格总结了细节方面。
这个表格应当这样阅读:批SQL通过第一列指定的方式提交给SQL Server服务器,缓存中可能存在或者不存在相应的查询计划,第2、3列指出了缓存中存在时的情况,第4、5列指出了缓存中不存在时的情况。对于每种类型,查询计划和执行上下文间的关系是独立的,表格中的文本描述了这些结构(查询计划或者执行上下文)将会发生什么情况。
| Mode name | When a cached query plan exists | When a cached query plan exists | When a cached query plan does not exist | When a cached query plan does not exist |
| Query plan | Exec context | Query plan | Exec context | |
| showplan_text, showplan_all, showplan_xml | Reused (no compilation) | Reused | Cached (compilation) | One exec context is generated, not used, and cached |
| statistics profile, statistics xml, statistics io, statistics time | Reused (no compilation) | Not reused. A fresh exec context is generated, used, and not cached | Cached (compilation) | One exec context generated, used, and not cached |
| noexec | Reused (no compilation) | Reused | Cached (compilation) | Execution context is not generated (because of the "noexec" mode). |
| parseonly (e.g., pressing "parse" button in Query Analyzer or Management Studio) | n/a | n/a | n/a | n/a |
Costs associated with query plans and execution contexts
对应每个查询计划和执行上下文,都保存了一个成本值,这个成本值在一定程度上控制了查询计划或者执行上下文在缓存中保留的时间。在SQL Server 2000和SQL Server 2005中,成本值的计算和使用不一样,下面是详细描述。
SQL Server 2000:对于查询计划,成本值是查询优化器优化批SQL所需的服务器资源(CPU时间和I/O)数量。ad-hot查询的成本为0。对于执行上下文,成本值是服务器初始化执行上下文,使某个语句可以用于执行所需的服务器资源(CPU时间和I/O)数量。注意,执行上下文成本值并不包含批SQL执行过程中产生的成本(CPU和I/O)。一般执行上下文成本低于查询计划成本。
下面是SQL Server 2000计算批SQL查询计划成本的方法,影响成本的四个因素是:生成查询计划花费的CPU时间(cputime);从磁盘读取的页数(ioread);向磁盘写入的页数(iowrite);批SQL的查询计划占用的内存页数量(pagecount)。查询计划成本可以这样表示(f是一个数学函数):
Query plan cost c = f(cputime, ioread, iowrite) / pagecount
接下来是SQL Server 2000中批SQL的执行上下文成本计算方法,对批SQL中的每个语句用上面的等式计算出一个成本值,然后相加。注意每个成本是语句初始化的成本,而不是语句编译或执行的成本。
惰性写入器进程(lazy-writer process)不时地扫描查询计划缓存进行清理工作,减少成本值。每次成本值被除以4,如果必要会向下圆整(成整数,例如25->6->1->0)。内存压力过大时,成本值为0的查询计划和执行上下文从查询计划缓存中删除。当查询计划或执行上下文被重用时,成本值被重置为编译(或者是执行上下文的生成)成本。ad-hoc查询的成本每次只是固定增加1。因此,频繁执行的批SQL的查询计划在查询计划缓存中生存的时间比较少执行的批SQL要长。
SQL Server 2005:ad-hoc查询的成本为0,其它的查询及哈成本为产生它所需要的资源数量,成本基于最大值为31的"单位数量(number of ticks)"计算出来,由三部分组成:
成本=I/O成本+上下文切换成本(一种CPU成本的度量)+内存成本
成本的各个部分如下计算:
● 2个I/O为一个单位(tick),最大值为19。
● 2次上下文切换为一个单位,最大值为8。
● 16个内存页(128kb)为一个单位,最大值为4。
SQL Server 2005中,查询计划缓存与数据缓存是分离的,另外还有其它功能相关的缓存区。SQL Server 2005中惰性写入器进程不会减少成本值,当查询计划缓存体积到达缓存区容量的50%后,下一次查询计划缓存存取操作时将其中所有计划的成本减去1个单位。注意这个减少操作是由某个搜索查询计划的线程在存取查询计划缓存区时完成的,也可以将这个减少操作看作是惰性写入方式时发生的情况。如果SQL Server 2005中所有缓存的大小达到或超过缓存区容量的75%,一个专用的资源监测线程被激活,它对所有缓存区中的所有对象减少成本单位数量(因此这个线程的行为类似于SQL Server 2000中的惰性写入器线程)。查询计划重用时导致成本值重设为它的初始值。
Roadmap to the rest of the paper
现在读者应当清楚,为了获得SQL Server批SQL良好的执行性能,需要具备两件事情:
● 尽可能重用查询计划。这避免了不必要的查询编译成本,查询计划重用也更好的利用了查询计划缓存,以获得更好的服务器性能。
● 避免那些可能增加查询重编译的行为。减少重编译次数节约了服务器资源(CPU和内存),为批SQL的执行带来可观的性能提升。
下面的章节描述了查询计划重用的细节方面,适当的地方给出了改善查询计划重用的最佳实践。然后我们给出了一些导致和增加重编译的普通场景,给出了避免这些情况的最佳实践。
Query plan reuse
查询计划缓存中包含查询计划和执行上下文,查询计划链接到相关的执行上下文。对批SQL S的查询计划重用依赖于S本身(例如查询文本或者存储过程名字),以及其它一些外部因素(例如产生S的用户名、应用程序、S相关连接的SET选项设置等)。一些外部因素是查询计划重用相关的(plan-reuse-affecting),如果两个相同的查询有一个因素不一样,也就无法重用查询计划,其它一些外部因素是查询计划重用无关的。
大部分查询计划重用相关的因素通过sys.syscacheobjects虚拟表的字段反映出来了,下面的列表描述了典型应用场景中的一些因素,某些情况下,列举的条目只是简单的指出查询计划什么情况下不会被缓存(也就无法重用),并没有解释为什么。
一般情况下,如果当前连接的服务器、数据库以及连接设置等,与缓存查询计划的连接设置一样,查询计划就可以被重用。另外,批SQL引用的对象不要去进行名称解析,例如Sales.SalesOrderDetail不需要进行名称解析,而SalesOrderDetail需要,应为可能多个数据库中会存在SalesOrderDetail这个表,一般情况下,完整的名称将带来更的查询计划重用机会。
Factors that affect plan-reuse
注意如果查询计划没有被缓存,就无法被重用,因此我们只是明确的指出无法缓存的情况,这样也就暗示着无法被重用。
1. 如果在数据库D1中执行了某个存储过程,在另一个数据库中执行同一个存储过程时无法重用它的查询计划。注意这个行为只针对存储过程,而不包括ad-hoc、预处理、动态SQL查询。
2. 对于触发器,执行时影响的行数(1到n,以inserted或者deleted表中的行数为准)是另外一个决定查询计划命中率的因素。注意这个行为只对触发器有效,不适用于存储过程。
SQL Server 2005中,对于替代触发器(INSTEAD OF triggers),"1-plan"适用于那些影响了0和1行的情况,而对于非替代触发器(后触发器-after triggers),"1-plan"仅用于影响了1行的情况,而"n-plan"适用于影响了0或者n(n>1)行的情况。
3. 大批次的插入(buld insert)语句不会被缓存,但相关的触发器会被缓存。
4. 包含超过8KB文本的批SQL不会被缓存,因此这样的查询计划无法重用(文本长度以应用了常量处理后的长度为准)。
5. Batches flagged with the "replication flag" (which is associated with a replication user) are not matched with batches without that flag.
6. A batch called from SQL Server 2005's common-language runtime (CLR) is not matched with the same batch submitted from outside of CLR. However, two CLR-submitted batches can reuse the same plan. The same observation applies to:
• CLR triggers and non-CLR triggers
• Notification queries and non-notification queries
7. Query plans for queries submitted via sp_resyncquery are not cached. Therefore, if the query is resubmitted (via sp_resyncquery or otherwise), it needs to be compiled again.
8. SQL Server 2005 allows cursor definition on top of a T-SQL batch. If the batch is submitted as a separate statement, then it does not reuse (part of the) plan for that cursor.
9. The following SET options are plan-reuse-affecting.
| Number | SET option name |
| 1 | ANSI_NULL_DFLT_OFF |
| 2 | ANSI_NULL_DFLT_ON |
| 3 | ANSI_NULLS |
| 4 | ANSI_PADDING |
| 5 | ANSI_WARNINGS |
| 6 | ARITHABORT |
| 7 | CONCAT_NULL_YIELDS_NULL |
| 8 | DATEFIRST |
| 9 | DATEFORMAT |
| 10 | FORCEPLAN |
| 11 | LANGUAGE |
| 12 | NO_BROWSETABLE |
| 13 | NUMERIC_ROUNDABORT |
| 14 | QUOTED_IDENTIFIER |
Further, ANSI_DEFAULTS is plan-reuse-affecting because it can be used to change the following SET options together (some of which are plan-reuse-affecting): ANSI_NULLS, ANSI_NULL_DFLT_ON, ANSI_PADDING, ANSI_WARNINGS, CURSOR_CLOSE_ON_COMMIT, IMPLICIT_TRANSACTIONS, QUOTED_IDENTIFIER.
The above SET options are plan-reuse-affecting because SQL Server 2000 and SQL Server 2005 perform "constant folding" (evaluating a constant expression at compile time to enable some optimizations) and because settings of these options affects the results of such expressions.
Settings of some of these SET options are exposed through columns of sys.syscacheobjects virtual table — for example, "langid" and "dateformat."
Note that values of some of these SET options can be changed using several methods:
• Using sp_configure stored procedure (for server-wide changes)
• Using sp_dboption stored procedure (for database-wide changes)
• Using SET clause of the ALTER DATABASE statement
In case of conflicting SET option values, user-level and connection-level SET option values take precedence over database and sever-level SET option values. Further, if a database-level SET option is effective, then for a batch that references multiple databases (which could potentially have different SET option values), the SET options of the database in whose context the batch is being executed takes precedence over SET options of the rest of the databases.
Best Practice: To avoid SET option-related recompilations, establish SET options at connection time, and ensure that they do not change for the duration of the connection.
10. Batches with unqualified object names result in non-reuse of query plans. For example, in "SELECT * FROM MyTable", MyTable may legitimately resolve to Alice.MyTable if Alice issues this query, and she owns a table with that name. Similarly, MyTable may resolve to Bob.MyTable. In such cases, SQL Server does not reuse query plans. If, however, Alice issues "SELECT * FROM dbo.MyTable", there is no ambiguity because the object is uniquely identified, and query plan reuse can happen. (See the uid column in sys.syscacheobjects. It indicates the user ID for the connection in which the plan was generated. Only query plans with the same user ID are candidates for reuse. When uid = -2, it means that the query does not depend on implicit name resolution, and can be shared among different user IDs.)
11. When a stored procedure is created with "CREATE PROCEDURE ...WITH RECOMPILE" option, its query plan is not cached whenever that stored procedure is executed. No opportunity of plan reuse exists: every execution of such a procedure causes a fresh compilation.
12. Best Practice: "CREATE PROCEDURE ... WITH RECOMPILE" can be used to mark stored procedures that are called with widely varying parameters, and for which best query plans are highly dependent on parameter values supplied during calls.
13. When a stored procedure P is executed using "EXEC ... WITH RECOMPILE", P is freshly compiled. Even if a query plan for P preexists in plan cache, and could be reused otherwise, reuse does not happen. The freshly compiled query plan for P is not cached.
Best Practice: When executing a stored procedure with atypical parameter values, "EXEC ... WITH RECOMPILE" can be used to ensure that the fresh query plan does not replace an existing cached plan that was compiled using typical parameter values.
"EXEC ... WITH RECOMPILE" can be used with user-defined functions as well, but only if the EXEC keyword is present.
1. To avoid multiple query plans for a query that is executed with different parameter values, execute the query using sp_executesql stored procedure. This method is useful if the same query plan is good for all or most of the parameter values.
2. Query plans of temporary stored procedures (both session-scoped and global) are cached, and therefore, can be reused.
3. In SQL Server 2005, plans for queries that create or update statistics (either manually or automatically) are not cached.
Causes of Recompilations
Recall that recompilation of a batch B occurs when after SQL Server begins executing statements in B, some (or all) of them are compiled again. Reasons for recompilation can be broadly classified into two categories:
• Correctness-related reasons. A batch must be recompiled if not doing so would result in incorrect results or actions. Correctness-related reasons fall into two sub-categories.
• Schemas of objects. A batch B may reference many objects (tables, views, indexes, statistics, UDFs, and so on), and if schemas of some of the objects have changed since B was last compiled, B needs to be recompiled for statement-correctness reasons.
• SET options. Some of the SET options affect query results. If the setting of such a plan-reuse-affecting SET option is changed inside of a batch, a recompilation happens.
• Plan optimality-related reasons. Data in tables that B references may have changed considerably since B was last compiled. In such cases, B may be recompiled for obtaining a potentially faster query execution plan.
The following two sections describe the two categories in detail.
Correctness-related reasons of batch recompilations
An enumeration of specific actions that cause correctness-related recompilations follows. Because such recompilations must happen, the choice for a user is to not take those actions, or to take them during off-peak hours of SQL Server operation.
Schemas of objects
1. Whenever a schema change occurs for any of the objects referenced by a batch, the batch is recompiled. "Schema change" is defined by the following:
• Adding or dropping columns to a table or view
• Adding or dropping constraints, defaults, or rules to/from a table
• Adding an index to a table or an indexed view
• Dropping an index defined on a table or an indexed view (only if the index is used by the query plan in question)
• (SQL Server 2000). Manually updating or dropping a statistic (not creating!) on a table will cause a recompilation of any query plans that use that table. Such recompilations happen the next time the query plan in question begins execution.
• (SQL Server 2005). Dropping a statistic (not creating or updating!) defined on a table will cause a correctness-related recompilation of any query plans that use that table. Such recompilations happen the next time the query plan in question begins execution. Updating a statistic (both manual and auto-update) will cause an optimality-related (data related) recompilation of any query plans that uses this statistic.
2. Running sp_recompile on a stored procedure or a trigger causes them to be recompiled the next time they are executed. When sp_recompile is run on a table or a view, all of the stored procedures that reference that table or view will be recompiled the next time they are run. sp_recompile accomplishes recompilations by incrementing the on-disk schema version of the object in question.
3. The following operations flush the entire plan cache, and therefore, cause fresh compilations of batches that are submitted the first time afterwards:
• Detaching a database
• Upgrading a database to SQL Server 2000 (on SQL Server 2000)
• Upgrading a database to SQL Server 2005 (on SQL Server 2005 server)
• DBCC FREEPROCCACHE command
• RECONFIGURE command
• ALTER DATABASE ... MODIFY FILEGROUP command
• Modifying a collation using ALTER DATABASE ... COLLATE command
The following operations flush the plan cache entries that refer to a particular database, and cause fresh compilations afterwards.
• DBCC FLUSHPROCINDB command
• ALTER DATABASE ... MODIFY NAME = command
• ALTER DATABASE ... SET ONLINE command
• ALTER DATABASE ... SET OFFLINE command
• ALTER DATABASE ... SET EMERGENCY command
• DROP DATABASE command
• When a database auto-closes
• When a view is created with CHECK OPTION, the plan cache entries of the database in which the view is created is flushed.
• When DBCC CHECKDB is run, a replica of the specified database is created. As part of DBCC CHECKDB's execution, some queries against the replica are executed, and their plans cached. At the end of DBCC CHECKDB's execution, the replica is deleted and so are the query plans of the queries posed on the replica.
The concept "plan cache entries that refer to a particular database" needs explanation. Database ID is one of the keys of the plan cache. Suppose that you execute the following command sequence.
go
<-- A query Q that references a database called db1 -->
go
Suppose that Q is cached in the plan cache. The database ID associated with Q's plan will be that of the "master," and not that of "db1."
When SQL Server 2005's transaction-level snapshot isolation level is on, plan reuse happens as usual. Whenever a statement in a batch under snapshot isolation level refers to an object whose schema has changed since the snapshot isolation mode was turned on, a statement-level recompilation happens if the query plan for that statement was cached and was reused. The freshly compiled query plan is cached, but the statement itself fails (as per that isolation level's semantics). If a query plan was not cached, a compilation happens, the compiled query plan is cached, and the statement itself fails.
SET options
As already mentioned in Section 6, changing one or more of the following SET options after a batch has started execution will cause a recompilation: ANSI_NULL_DFLT_OFF, ANSI_NULL_DFLT_ON, ANSI_NULLS, ANSI_PADDING, ANSI_WARNINGS, ARITHABORT, CONCAT_NULL_YIELDS_NULL, DATEFIRST, DATEFORMAT, FORCEPLAN, LANGUAGE, NO_BROWSETABLE, NUMERIC_ROUNDABORT, QUOTED_IDENTIFIER.
Plan optimality-related reasons of batch recompilations
SQL Server is designed to generate optimal query execution plans as data in databases changes. Data changes are tracked using statistics (histograms) in SQL Server's query processor. Therefore, plan optimality-related reasons have close association with the statistics.
Before describing plan optimality-related reasons in detail, let us enumerate the conditions under which plan optimality-related recompilations do not happen.
• When the plan is a "trivial plan." A trivial plan results when the query optimizer determines that given the tables referenced in the query and the indexes existing on them, only one plan is possible. Obviously, a recompilation would be futile in such a case. A query that has generated a trivial plan may not always generate a trivial plan, of course. For examples, new indexes might be created on the underlying tables, and so multiple access paths become available to the query optimizer. Additions of such indexes would be detected as mentioned in Section 7.1, and a correctness-related recompilation might replace the trivial plan with a non-trivial one.
• When a query contains "KEEPFIXED PLAN" hint, its plan is not recompiled for plan optimality-related reasons.
• When all of the tables referenced in the query plan are read-only, the plan is not recompiled.
• This point is only applicable to SQL Server 2000. Consider a query plan is being compiled (not recompiled), and as a part of compilation, the query processor decides to update a statistic S on a table T. The query processor attempts to obtain a special "statistic lock" on T. If some other process is updating some statistic on T (not necessarily S!), the query processor cannot obtain a statistic lock on T. In such a case, the query processor does not update S. Furthermore, the query plan in question is never recompiled again for plan optimality-related reasons. It is as if the query were submitted with a "KEEPFIXED PLAN" hint.
• This case is identical to the one mentioned in the previous bullet except that in this case, the query plan is cached. In other words, this case is about a recompilation, as opposed to the previous case which is about a compilation. In case of such a recompilation, suppose that the query processor attempts to obtain a "statistic lock" on T and fails. In this case, the query processor skips updating the statistic S; uses a stale statistic S; and proceeds with the other recompilation steps/checks as usual. Thus, a recompilation is avoided at the cost of a potentially slower query execution plan.
High-level overview of query compilation
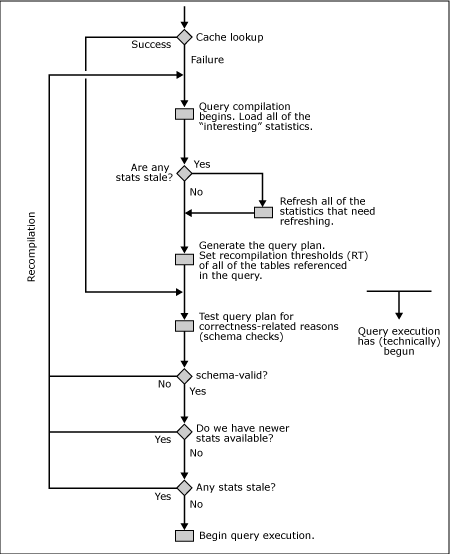
The following flowchart succinctly describes the batch compilation and recompilation process in SQL Server. The main processing steps are as follows (individual steps will be described in detail later on in this document):
1. SQL Server begins compiling a query. (As mentioned previously, a batch is the unit of compilation and caching, but individual statements in a batch are compiled one after another.)
2. All of the "interesting" statistics that may help to generate an optimal query plan are loaded from disk into memory.
3. If any of the statistics are outdated, they are updated one-at-a-time. The query compilation waits for the updates to finish. An important difference between SQL Server 2000 and SQL Server 2005 regarding this step is that in SQL Server 2005, statistics may optionally be updated asynchronously. That is, the query compilation thread is not blocked by statistics updating threads. The compilation thread proceeds with stale statistics.
4. The query plan is generated. Recompilation thresholds of all of the tables referenced in the query are stored along with the query plan.
5. At this point, query execution has technically begun. The query plan is now tested for correctness-related reasons. Those reasons were described in Section 7.1.
6. If the plan is not correct for any of the correctness-related reasons, a recompilation is started. Notice that because query execution has technically begun, the compilation just started is a recompilation.
7. If the plan is "correct," then various recompilation thresholds are compared with either table cardinalities or various table modification counters (rowmodctr in SQL Server 2000 or colmodctr in SQL Server 2005).
8. If any of the statistics are deemed out-of-date as per the comparisons performed in Step 7, a recompilation results.
9. If all of the comparisons in Step 7 succeed, actual query execution begins.
Plan optimality-related recompilations: The Big Picture
Each SELECT, INSERT, UPDATE, and DELETE statement accesses one or more tables. Table contents change because of such operations as INSERT, UPDATE, and DELETE. SQL Server's query processor is designed to adapt to such changes by generating potentially different query plans, each optimal at the time it is generated. Table contents are tracked directly using table cardinality, and indirectly using statistics (histograms) on table columns.
Each table has a recompilation threshold (RT) associated with it. RT is a function of the number of rows in a table. During query compilation, the query processor loads zero or more statistics defined on tables referenced in a query. These statistics are known as interesting statistics. For every table referenced in a query, the compiled query plan contains:
• Recompilation threshold
• A list of all of the statistics loaded during query compilation. For each such statistic, a snapshot value of a counter that counts the number of table modifications is stored. The counter is called rowmodctr in SQL Server 2000, and colmodctr in SQL Server 2005. A separate colmodctr exists for each table column (except computed non-persisted columns).
The threshold crossing test — which is performed to decide whether to recompile a query plan — is defined by the formula:
| modctr(snapshot) – modctr(current) | >= RT
modctr(current) refers to the current value of the modification counter, and modctr(snapshot) refers to the value of the modification counter when the query plan was last compiled. If threshold crossing succeeds for any of the interesting statistics, the query plan is recompiled. In SQL Server 2000, the entire batch containing the query is recompiled; in SQL Server 2005, only the query in question is recompiled.
If a table or an indexed view T has no statistic on it, or none of the existing statistics on T are considered "interesting" during a query compilation, the following threshold-crossing test, based purely on T's cardinality, is still performed.
card(current) denotes the number of rows in T at present, and card(snapshot) denotes the row count when the query plan was last compiled.
The following sections describe the important concepts introduced in the "big picture."
Concept of "interesting" statistics
With every query plan P, the optimizer stores the IDs of the statistics that were loaded to generate P. Note that the "loaded" set includes both:
• Statistics that are used as cardinality estimators of the operators appearing in P
• Statistics that are used as cardinality estimators in query plans that were considered during query optimization but were discarded in favor of P
In other words, the query optimizer considers all of the loaded statistics as "interesting" for one reason or another.
Recall that statistics can be created or updated either manually or automatically. Statistics updates also happen because of executions of the following commands:
• CREATE INDEX ... WITH DROP EXISTING
• sp_createstats stored procedure
• sp_updatestats stored procedure
• DBCC DBREINDEX (but not DBCC INDEXDEFRAG!)
Recompilation threshold (RT)
The recompilation threshold for a table partly determines the frequency with which queries that refer to the table recompile. RT depends on the table type (permanent versus temporary), and the number of rows in the table (cardinality) when a query plan is compiled. The recompilation thresholds for all of the tables referenced in a batch are stored with the query plans of that batch.
RT is calculated as follows. (n refers to a table's cardinality when a query plan is compiled.)
• Permanent table
• If n <= 500, RT = 500.
• If n > 500, RT = 500 + 0.20 * n.
• Temporary table
• If n < 6, RT = 6.
• If 6 <= n <= 500, RT = 500.
• If n > 500, RT = 500 + 0.20 * n.
• Table variable
• RT does not exist. Therefore, recompilations do not happen because of changes in cardinalities of table variables.
Table modification counters (rowmodctr and colmodctr)
As mentioned previously, RT is compared against the number of modifications that a table has undergone. The number of modifications that a table has undergone is tracked using counters called rowmodctr (in SQL Server 2000) and colmodctr (in SQL Server 2005). Neither of these counters is transactional. For example, if a transaction starts, inserts 100 rows into a table, and then is rolled back, the changes to the modification counters will not be rolled back.
Rowmodctr (SQL Server 2000)
One rowmodctr is associated with each table. Its value is available from sysindexes system table. A snapshot value of the rowmodctr is associated with every statistic created on one or more columns of a table or an indexed view T. Whenever this statistic is updated — either manually or automatically (by SQL Server's auto-stats feature) — the snapshot value of the rowmodctr is also refreshed.
Rowmodctr(current), mentioned in the "threshold-crossing" test, is the value persisted in the sysindexes system table (for either heap or clustered index) when the test is performed during query compilation.
rowmodctr is available in SQL Server 2005 servers, but its values is always 0.
As an aside, in SQL Server 2000, when a rowmodctr is 0, it cannot cause a recompilation.
Colmodctr (SQL Server 2005)
Unlike rowmodctr, a colmodctr value is stored for each table column (except for computed non-persisted columns). Persisted computed columns have colmodctrs, just like ordinary columns do. Using colmodctr values, changes to a table can be tracked on a finer granularity. Colmodctr values are not available to users; they are only available to the query processor.
When a statistic is created or updated (either manually or automatically by the auto-stats feature) on one or more columns of a table or indexed view T, the snapshot value of the colmodctr of the leftmost column is stored in the stats-blob.
Colmodctr(current), mentioned in the "threshold-crossing" test, is the value persisted in SQL Server 2005's metadata when the test is performed during query compilation.
Unlike rowmodctr's, colmodctr's values are an ever-increasing sequence: colmodctr values are never reset to 0.
Colmodctr values for non-persisted computed columns do not exist. They are derived from the columns that participate in the computation.
Tracking changes to tables and indexed views using rowmodctr and colmodctr
Because rowmodctr and colmodctr values are used to make recompilation decisions, their values are modified as a table changes. In the following description, we only refer to tables. However, identical observations apply to indexed views. A table can change because of the following statements: INSERT, DELETE, UPDATE, bulk insert, and table truncation. The following table defines how rowmodctr and colmodctr values are modified.
| Statement | SQL Server 2000 | SQL Server 2005 |
| INSERT | rowmodctr += 1 | All colmodctr += 1 |
| DELETE | rowmodctr += 1 | All colmodctr += 1 |
| UPDATE | rowmodctr += 2 or 3. Rationale for "2": 1 for delete + 1 for insert. |
If the update is to non-key columns: colmodctr += 1 for all of the updated columns. If the update is to key columns: colmodctr += 2 for all of the columns. |
| Bulk insert | No change. | Like n INSERTs. All colmodctr += n. (n is the number of rows bulk inserted.) |
| Table truncation | No change. | Like n DELETEs. All colmodctr += n. (n is the table's cardinality.) |
Two special cases
Plan optimality-related recompilations are handled differently in the following two special cases.
Special case 1: Statistics created on an empty table or indexed view
SQL Server 2005 handles the following scenario differently from SQL Server 2000. A user creates an empty table T. She then creates a statistic S on one or more columns of T. Because T is empty, the stats-blob (histogram) is NULL, but the statistic has been created on T. Suppose that S has been found "interesting" during a query compilation. As per the "500 row" rule for recompilation threshold, T will cause recompilations on SQL Server 2000 only after T contains at least 500 rows. Therefore, a user may suffer from sub-optimal plans until T contains at least 500 rows.
SQL Server 2005 detects this special case, and handles it differently. In SQL Server 2005, recompilation threshold for such a table or indexed view is 1. In other words, even the insertion of one row in T can cause a recompilation. When such a recompilation happens, S is updated, and the histogram for S is no longer NULL. After this recompilation, however, the usual rule for recompilation threshold (500 + 0.20 * n) is followed.
In SQL Server 2005, the recompilation threshold is 1 even when: (1) T has no statistics; or (2) T has no statistics that are considered "interesting" during a query compilation.
Special case 2: Trigger recompilations
All of the plan optimality-related reasons for recompilations are applicable to triggers. In addition, plan optimality-related recompilations for triggers can also happen because of the number of rows in the inserted or deleted tables changing significantly from one trigger execution to the next.
Recall that triggers that affect one row versus multiple rows are cached independently of each other. The numbers of rows in the inserted and deleted tables are stored with the query plan for a trigger. These numbers reflect the row counts for the trigger execution that caused plan caching. If a subsequent trigger execution results in inserted or deleted table having "sufficiently different" row counts, then the trigger is recompiled (and a fresh query plan with the new row counts is cached).
In SQL Server 2005, "sufficiently different" is defined by:
| log10(n) – log10(m) | > 2.1 otherwise
As an example of the calculation, a row count change from 10 to 100 does not cause a recompilation, whereas a change from 10 to 101 does.
In SQL Server 2000, "sufficiently different" is defined by:
Identifying statistics-related recompilations
Statistics-related recompilations can be identified by the "EventSubClass" column of the profiler trace (to be described later in this paper) containing the string "Statistics changed".
Closing remarks
An issue not directly related to the topic of this document is: given multiple statistics on the same set of columns in the same order, how does the query optimizer decide which ones to load during query optimization? The answer is not simple, but the query optimizer uses such guidelines as: Give preference to recent statistics over older statistics; Give preference to statistics computed using FULLSCAN option to those computed using sampling; and so on.
There is a potential of confusion regarding the "cause and effect" relationship between plan optimality-related compilations, recompilations, and statistics creation/updates. Recall that statistics can be created or updated manually or automatically. Only compilations and recompilations cause automatic creation or updates of statistics. On the other hand, when a statistic is created or updated (manually or automatically), there is an increased chance of recompilation of a query plan which might find that statistic "interesting."
Best practices
Four best practices for reducing plan optimality-related batch recompilations are given next:
Best Practice: Because a change in cardinality of a table variable does not cause recompilations, consider using a table variable instead of a temporary table. However, because the query optimizer does not keep track of a table variable's cardinality and because statistics are not created or maintained on table variables, non-optimal query plans might result. One has to experiment whether this is the case, and make an appropriate trade-off.
Best Practice: The KEEP PLAN query hint changes the recompilation thresholds for temporary tables, and makes them identical to those for permanent tables. Therefore, if changes to temporary tables are causing many recompilations, this query hint can be used. The hint can be specified using the following syntax:
FROM dbo.PermTable A INNER JOIN #TempTable B ON A.col1 = B.col2
WHERE B.col3 < 100
GROUP BY B.col4
OPTION (KEEP PLAN)
Best Practice: To avoid recompilations due to plan optimality-related (statistic update-related) reasons totally, KEEPFIXED PLAN query hint can be specified using the syntax:
FROM Sales.Store s INNER JOIN Sales.Customer c
ON s.CustomerID = c.CustomerID
WHERE s.Name LIKE '%Bike%' AND c.SalesPersonID > 285
GROUP BY c.TerritoryID, c.SalesPersonID
ORDER BY Number DESC
OPTION (KEEPFIXED PLAN)
With this option in effect, recompilations can only happen because of correctness-related reasons — for example, schema of a table referenced by a statement changes, or a table is marked with sp_recompile procedure.
In SQL Server 2005, there is a slight change in behavior as described below. Suppose that a query with OPTION(KEEPFIXED PLAN) hint is being compiled for the first time, and compilation causes auto-creation of a statistic. If SQL Server 2005 can get a special "stats lock," a recompilation happens and the statistic is auto-created. If the "stats lock" cannot be obtained, there is no recompilation, and the query is compiled without that statistic. In SQL Server 2000, a query with OPTION(KEEPFIXED PLAN) is never recompiled because of statistics-related reasons, and therefore, in this scenario, no attempt is made to get a "stats lock" or to auto-create the statistic.
Best Practice: Turning off automatic updates of statistics for indexes and statistics defined on a table or indexed view will ensure that plan optimality-related recompilations caused by those objects will stop. Note, however, that turning off the "auto-stats" feature using this method is usually not a good idea because the query optimizer is no longer sensitive to data changes in those objects, and sub-optimal query plans might result. Adopt this method only as a last resort after exhausting all of the other alternatives.
Compilations, Recompilations, and Concurrency
In SQL Server 2000, compilations and recompilations of stored procedures, triggers, and dynamic SQL are serialized. For example, suppose that a stored procedure is submitted for execution using "EXEC dbo.SP1". Suppose that while SQL Server is compiling SP1, another request "EXEC dbo.SP1" referring to the same stored procedure is received. The second request will wait for the first request to complete the compilation of SP1, and will attempt to reuse the resulting query plan. In SQL Server 2005, compilations are serialized, but recompilations are not serialized. In other words, two concurrent recompilations of the same stored procedures may continue. The recompilation request that finishes last will replace the query plan generated by the other one.
Compilations, Recompilations, and Parameter Sniffing
"Parameter sniffing" refers to a process whereby SQL Server's execution environment "sniffs" the current parameter values during compilation or recompilation, and passes it along to the query optimizer so that they can be used to generate potentially faster query execution plans. The word "current" refers to the parameter values present in the statement call that caused a compilation or a recompilation. Both in SQL Server 2000 and SQL Server 2005, parameter values are sniffed during compilation or recompilation for the following types of batches:
• Stored procedures
• Queries submitted via sp_executesql
• Prepared queries
In SQL Server 2005, the behavior is extended for queries submitted using the OPTION(RECOMPILE) query hint. For such a query (could be SELECT, INSERT, UPDATE, or DELETE), both the parameter values and the current values of local variables are sniffed. The values sniffed (of parameters and local variables) are those that exist at the place in the batch just before the statement with the OPTION(RECOMPILE) hint. In particular, for parameters, the values that came along with the batch invocation call are not sniffed.
Identifying Recompilations
SQL Server's Profiler makes it easy to identify batches that cause recompilations. Start a new profiler trace and select the following events under Stored Procedures event class. (To reduce the amount of data generated, it is recommended that you de-select any other events.)
• SP:Starting
• SP:StmtStarting
• SP:Recompile
• SP:Completed
In addition, to detect statistics-update-related recompilations, the "Auto Stats" event under "Objects" class can be selected.
Now start SQL Server 2005 Management Studio, and execute the following T-SQL code:
go
drop procedure DemoProc1
go
create procedure DemoProc1 as
create table #t1 (a int, b int)
select * from #t1
go
exec DemoProc1
go
exec DemoProc1
go
Pause the profiler trace, and you will see the following sequence of events.
| EventClass | TextData | EventSubClass |
|
SP:Starting |
exec DemoProc1 |
|
|
SP:StmtStarting |
-- DemoProc1 create table #t1 (a int, b int) |
|
|
SP:StmtStarting |
-- DemoProc1 select * from #t1 |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtStarting |
-- DemoProc1 select * from #t1 |
|
|
SP:Completed |
exec DemoProc1 |
|
|
SP:Starting |
exec DemoProc1 |
|
|
SP:StmtStarting |
-- DemoProc1 create table #t1 (a int, b int) |
|
|
SP:StmtStarting |
-- DemoProc1 select * from #t1 |
|
|
SP:Completed |
exec DemoProc1 |
The event sequence indicates that "select * from #t1" was the statement that caused the recompilation. The EventSubClass column indicates the reason for the recompilation. In this case, when DemoProc1 was compiled before it began execution, the "create table" statement could be compiled. The subsequent "select" statement could not be compiled because it referred to a temporary table #t1 that did not exist at the time of the initial compilation. The compiled plan for DemoProc1 was thus incomplete. When DemoProc1 started executing, #t1 got created and then the "select" statement could be compiled. Because DemoProc1 was already executing, this compilation counts as a recompilation as per our definition of recompilation. The reason for this recompilation is correctly given as "deferred compile."
It is interesting to note that when DemoProc1 is executed again, the query plan is no longer incomplete. The recompilation has inserted a complete query plan for DemoProc1 into the plan cache. Therefore, no recompilations happen for the second execution.
An identical behavior is observed in SQL Server 2000.
Batches causing recompilations can also be identified by selecting the following set of trace events.
| • |
SP:Starting |
| • |
SP:StmtCompleted |
| • |
SP:Recompile |
| • |
SP:Completed |
If the above example is run after selecting this new set of trace events, the trace output looks like the following.
| EventClass | TextData | EventSubClass |
|
SP:Starting |
exec DemoProc1 |
|
|
SP:StmtCompleted |
-- DemoProc1 create table #t1 (a int, b int) |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtCompleted |
-- DemoProc1 select * from #t1 |
|
|
SP:Completed |
exec DemoProc1 |
|
|
SP:Starting |
exec DemoProc1 |
|
|
SP:StmtCompleted |
-- DemoProc1 create table #t1 (a int, b int) |
|
|
SP:StmtCompleted |
-- DemoProc1 select * from #t1 |
|
|
SP:Completed |
exec DemoProc1 |
Notice that in this case, the statement causing the recompilation is printed after the SP:Recompile event. This method is somewhat less obvious than the first one. Therefore, we shall trace the first set of profiler trace events henceforth.
To see all of the possible recompilation reasons reported for SP:Recompile event, issue the following query on SQL Server 2005:
select v.subclass_name, v.subclass_value
from sys.trace_events e inner join sys.trace_subclass_values v
on e.trace_event_id = v.trace_event_id
where e.name = 'SP:Recompile'
The output of the above query is as follows. (Only the unshaded columns are output; the shaded column is for additional details.)
| SubclassName | SubclassValue | Detailed reason for recompilation |
|
Schema changed |
1 |
Schema, bindings, or permissions changed between compile and execute. |
|
Statistics changed |
2 |
Statistics changed. |
|
Deferred compile |
3 |
Recompile because of DNR (Deferred Name Resolution). Object not found at compile time, deferred check to run time. |
|
Set option change |
4 |
Set option changed in batch. |
|
Temp table changed |
5 |
Temp table schema, binding, or permission changed. |
|
Remote rowset changed |
6 |
Remote rowset schema, binding, or permission changed. |
|
Query notification environment changed |
8 |
(NEW in SQL Server 2005!) |
|
Partition view changed |
9 |
SQL Server 2005 sometimes adds data-dependent implied predicates to WHERE clauses of queries in some indexed views. If the underlying data changes, such implied predicates become invalid, and the associated cached query plan needs recompilation. (NEW in SQL Server 2005!) |
In SQL Server 2000, the EventSubClass column contains integer values 1 through 6 with the same meanings as those mentioned in the above table. The last two categories are new in SQL Server 2005.
For both of the examples presented in this section, trace output on SQL Server 2000 is identical to that on SQL Server 2005, except that on SQL Server 2000, EventSubClass column contains 3, not the string "Deferred compile". Internally, statement-level recompilations happen on SQL Server 2005. Thereby, only the "select * from #t1" is recompiled on SQL Server 2005, whereas on SQL Server 2000, the entire DemoProc1 is recompiled.
Recompilations due to mixing DDL and DML
Mixing Data Definition Language (DDL) and Data Manipulation Language (DML) statements within a batch or stored procedure is a bad idea because it can cause unnecessary recompilations. The following example illustrates this using a stored procedure. (The same phenomenon happens for a batch also. However, because SQL Server 2005 Profiler does not provide the necessary tracing events, we cannot observe it in action.) Create the following stored procedure.
drop procedure MixDDLDML
go
create procedure MixDDLDML as
create table tab1 (a int) -- DDL
select * from tab1 -- DML
create index nc_tab1idx1 on tab1(a) -- DDL
select * from tab1 -- DML
create table tab2 (a int) -- DDL
select * from tab2 -- DML
go
exec MixDDLDML
go
In the profiler trace output, the following sequence of events can be observed.
| EventClass | TextData | EventSubClass |
|
SP:Starting |
exec MixDDLDML |
|
|
SP:StmtStarting |
-- MixDDLDML create table tab1 (a int) --DDL |
|
|
SP:StmtStarting |
-- MixDDLDML select * from tab1 -- DML |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtStarting |
-- MixDDLDML select * from tab1 -- DML |
|
|
SP:StmtStarting |
-- MixDDLDML create index nc_tab1idx1 on tab1(a) -- DDL |
|
|
SP:StmtStarting |
-- MixDDLDML select * from tab1 -- DML |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtStarting |
-- MixDDLDML select * from tab1 -- DML |
|
|
SP:StmtStarting |
-- MixDDLDML create table tab2 (a int) --DDL |
|
|
SP:StmtStarting |
-- MixDDLDML select * from tab2 -- DML |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtStarting |
-- MixDDLDML select * from tab2 -- DML |
|
|
SP:Completed |
exec MixDDLDML |
Here is how the MixDDLDML is compiled.
|
1. |
During the first compilation (not recompilation) of MixDDLDML, a skeleton plan for it is generated. Because tables tab1 and tab2 do not exist, plans for the three "select" statements cannot be produced. The skeleton contains plans for the two "create table" statements and the one "create index" statement. |
|
2. |
When the procedure begins execution, table tab1 is created. Because there is no plan for the first "select * from tab1", a statement-level recompilation happens. (In SQL Server 2000, a plan for the second "select * from tabl" will also be generated by this recompilation.) |
|
3. |
The second "select * from tab1" causes a recompilation because a plan for that query does not yet exist. In SQL Server 2000, this recompilation happens but for a different reason: the schema for "tab1" has changed because of the creation of a non-clustered index on "tab1". |
|
4. |
Next, "tab2" gets created. "select * from tab2" causes a recompilation because a plan for that query did not exist. |
In conclusion, three recompilations happen in both SQL Server 2000 and SQL Server 2005 for this example. The SQL Server 2005 recompilations, however, are cheaper than SQL Server 2000 ones because they are statement-level rather than stored procedure-level.
If the stored procedure is written as follows, an interesting phenomenon is observed.
create procedure DDLBeforeDML as
create table tab1 (a int) -- DDL
create index nc_tab1idx1 on tab1(a) -- DDL
create table tab2 (a int) -- DDL
select * from tab1 -- DML
select * from tab1 -- DML
select * from tab2 -- DML
go
exec DDLBeforeDML
go
In the profiler trace output, the following sequence of events can be observed.
| EventClass | TextData | EventSubClass |
|
SP:Starting |
exec DDLBeforeDML |
|
|
SP:StmtStarting |
-- DDLBeforeDML create table tab1 (a int) -- DDL |
|
|
SP:StmtStarting |
-- DDLBeforeDML create index nc_tab1idx1 on tab1(a) -- DDL |
|
|
SP:StmtStarting |
-- DDLBeforeDML create table tab2 (a int) -- DDL |
|
|
SP:StmtStarting |
-- DDLBeforeDML select * from tab1 --DML |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtStarting |
-- DDLBeforeDML select * from tab1 --DML |
|
|
SP:StmtStarting |
-- DDLBeforeDML select * from tab1 --DML |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtStarting |
-- DDLBeforeDML select * from tab1 --DML |
|
|
SP:StmtStarting |
-- DDLBeforeDML select * from tab2 -- DML |
|
|
SP:Recompile |
Deferred compile |
|
|
SP:StmtStarting |
-- DDLBeforeDML select * from tab2 -- DML |
|
|
SP:Completed |
exec DDLBeforeDML |
In SQL Server 2005, because of statement-level recompilations, three recompilations still happen. When compared with the MixDDLDML stored procedure, the number of recompilations has not reduced. If the same example is tried on SQL Server 2000, the number of recompilations is reduced from 3 to 1. In SQL Server 2000, recompilations are stored procedure-level, and therefore, the three "select" statements could be compiled in one shot. In conclusion, in SQL Server 2005, the recompilation effort has not increased but the number of recompilations has increased when compared to SQL Server 2000.
Next, consider the following T-SQL code snippet:
-- dbo.someTable will be used to populate a temp table
-- subsequently.
create table dbo.someTable (a int not null, b int not null)
go
declare @i int
set @i = 1
while (@i <= 2000)
begin
insert into dbo.someTable values (@i, @i+5)
set @i = @i + 1
end
go
-- This is the stored procedure of main interest.
create procedure dbo.AlwaysRecompile
as
set nocount on
-- create a temp table
create table #temp1(c int not null, d int not null)
select count(*) from #temp1
-- now populate #temp1 with 2000 rows
insert into #temp1
select * from dbo.someTable
-- create a clustered index on #temp1
create clustered index cl_idx_temp1 on #temp1(c)
select count(*) from #temp1
go
In SQL Server 2000, when this stored procedure is executed the first time, the first SP:Recompile event is generated for the first "select" statement. This is a deferred compile, and not a true recompilation. The second SP:Recompile event is for the second "select". When the first recompilation happened, the second "select" was also compiled because compilations are batch-level in SQL Server 2000. Then, during execution, schema of #temp1 changed because of the newly created clustered index. Therefore, reason for the second SP:Recompile is schema change.
Recompilations due to number of row modifications
Consider the following stored procedure and its execution.
use AdventureWorks -- or say "use pubs" on SQL Server 2000
go
create procedure RowCountDemo
as
begin
create table #t1 (a int, b int)
declare @i int
set @i = 0 while (@i < 20)
begin
insert into #t1 values (@i, 2*@i - 50)
select a
from #t1
where a < 10 or ((b > 20 or a >=100) and (a < 10000))
group by a
set @i = @i + 1
end
end
go
exec RowCountDemo
go
Recall that the recompilation threshold for a temporary table is 6 when the table is empty when the threshold is calculated. When RowCountDemo is executed, a "statistics changed"-related recompilation can be observed after #t1 contains exactly 6 rows. By changing the upper bound of the "while" loop, more recompilations can be observed.
Recompilations due to SET option changes
Consider the following stored procedure.
use AdventureWorks
go
create procedure SetOptionsDemo as
begin
set ansi_nulls off
select p.Size, sum(p.ListPrice)
from Production.Product p
inner join Production.ProductCategory pc
on p.ProductSubcategoryID = pc.ProductCategoryID
where p.Color = 'Black'
group by p.Size
end
go
exec SetOptionsDemo -- causes a recompilation
go
exec SetOptionsDemo -- does not cause a recompilation
go
When SetOptionsDemo is executed, the "select" query is compiled with "ansi_nulls" ON. When SetOptionsDemo begins execution, the value of that SET option changes because of "set ansi_nulls off", and therefore the compiled query plan is no longer "valid." It is therefore recompiled with "ansi_nulls" OFF. The second execution does not cause a recompilation because the cached plan is compiled with "ansi_nulls" OFF.
Another example of more recompilations in SQL Server 2005 than in SQL Server 2000
Consider the following stored procedure.
use AdventureWorks -- say "use pubs" on SQL Server 2000
go
create procedure CreateThenReference as
begin
-- create two temp tables
create table #t1(a int, b int)
create table #t2(c int, d int)
-- populate them with some data
insert into #t1 values (1, 1)
insert into #t1 values (2, 2)
insert into #t2 values (3, 2)
insert into #t2 values (4, 3)
-- issue two queries on them
select x.a, x.b, sum(y.c)
from #t1 x inner join #t2 y on x.b = y.d
group by x.b, x.a
order by x.b
select *
from #t1 z cross join #t2 w
where w.c != 5 or w.c != 2
end
go
exec CreateThenReference
go
In SQL Server 2005, CreateThenReference's first execution causes six statement-level recompilations: four for the "insert" statements and two for the "select" queries. When the stored procedure starts executing, the initial query plan does not contain plans for either "insert" or "select" statements because the objects that they reference — temporary tables #t1 and #t2 — do not yet exist. After #t1 and #t2 are created, query plans for "insert" and "select" are compiled, and these compilations count as recompilations. In SQL Server 2000, because the entire stored procedure is recompiled at once, only one (stored procedure level) recompilation — the one that is caused when the first "insert" begins execution — happens. At that time, the entire stored procedure is recompiled, and because #t1 and #t2 already exist, the subsequent "insert"s and "select"s can all be compiled in one attempt. Obviously, the number of statement-level recompilations in SQL Server 2005 can be increased without bound by adding more statements that reference such objects as #t1 and #t2.
Tools and Commands
This section contains descriptions of various tools and commands that exist in observing and debugging recompilation-related scenarios.
Sys.syscacheobjects virtual table
This virtual table conceptually exists only in the master database, although it can be queried from any database. The cacheobjtype column of this virtual table is particularly interesting. When cacheobjtype = "Compiled Plan", the row refers to a query plan. When cacheobjtype = "Executable Plan", the row refers to an execution context. As we have explained, each execution context must have its associated query plan, but not vice versa. One other column of interest is the objtype column: it indicates the type of object whose plan is cached (for example, "Adhoc", "Prepared", and "Proc"). The setopts column encodes a bitmap indicating the SET options that were in effect when the plan was compiled. Sometimes, multiple copies of the same compiled plan (that differ in only setopts column) are cached in a plan cache. This indicates that different connections are using different sets of SET options, a situation that is often undesirable. The usecounts column stores the number of times a cached objects has been reused since the time the object was cached.
Please refer to BOL for more information on this virtual table.
DBCC FREEPROCCACHE
This command removes all of the cached query plans and execution contexts from the plan cache. It is not advisable to run this command on a production server because it can adversely affect performance of running applications. This command is useful to control plan cache's contents when troubleshooting a recompilation issue.
DBCC FLUSHPROCINDB( db_id )
This command removes all of the cached plans from the plan cache for a particular database. It is not advisable to run this command on a production server because it can adversely affect performance of running applications.
Profiler Trace Events
The following profiler trace events are relevant for observing and debugging plan caching, compilation, and recompilation behaviors.
| • |
'Cursors: CursorRecompile' (new in SQL Server 2005) for observing recompilations caused by cursor-related batches. |
| • |
'Objects: Auto Stats' for observing the statistics updates caused by SQL Server's "auto-stats" feature. |
| • |
'Performance: Show Plan All For Query Compile' (new in SQL Server 2005) is useful for tracing batch compilations. It does not distinguish between a compilation and a recompilation. It produces showplan data in textual format (similar to the one produced using "set showplan_all on" option). |
| • |
'Performance: Show Plan XML For Query Compile' (new in SQL Server 2005) is useful for tracing batch compilations. It does not distinguish between a compilation and a recompilation. It produces showplan data in XML format (similar to the one produced using "set showplan_xml on" option). |
| • |
'Stored Procedures: SP: Recompile' fires when a recompilation happens. Other events in the "Stored Procedures" category are also useful — for example, SP:CacheInsert, SP:StmtStarting, SP:CacheHit, SP:Starting, and so on. |
Perfmon Counters
Values of the following perfmon counters are relevant when debugging performance problems that may be caused by excessive compilations and recompilations.
| Performance object | Counters |
|
SQLServer: Buffer Manager |
Buffer cache hit ratio, Lazy writes/sec, Procedure cache pages, Total pages |
|
SQLServer: Cache Manager |
Cache Hit Ratio, Cache Object Counts, Cache Pages, Cache Use Counts/sec |
|
SQLServer: Memory Manager |
SQL Cache Memory (KB) |
|
SQLServer:SQL Statistics |
Auto-Param Attmpts/sec, Batch Requests/sec, Failed Auto-Params/sec, Safe Auto-Params/sec, SQL Compilations/sec, SQL Re-Compilations/sec, Unsafe Auto-Params/sec |
Conclusion
SQL Server 2005 caches query plans for a variety of statement types submitted to it for execution. Query plan caching causes query plan reuse, avoids compilation penalty, and utilizes plan cache better. Some coding practices hinder query plan caching and reuse, and therefore, should be avoided. SQL Server detects opportunities for query plan reuse. In particular, query plans can get non-reusable for two reasons: (a) Schema of an object appearing in a query plan can change thereby making the plan invalid; and (b) Data in tables referred to by a query plan can change enough to make a plan sub-optimal. SQL Server detects these two classes of conditions at query execution time, and recompiles a batch or pieces of it as necessary. Bad T-SQL coding practices can increase recompilation frequency and adversely affect SQL Server's performance. Such situations can be debugged and corrected in many cases.
Appendix A: When does SQL Server 2005 not auto-parameterize queries?
Auto-parameterization is a process whereby SQL Server replaces literal constants appearing in a SQL statement with such parameters as @p1 and @p2. The SQL statement's compiled plan is then cached in plan cache in parameterized form so that a subsequent statement that differs only in the values of the literal constants can reuse the cached plan. As mentioned in Section 4, only those SQL statements for which parameter values do not affect query plan selection are auto-parameterized.
SQL Server's LPE (Language Processing and Execution) component auto-parameterizes SQL statements. When QP (query processor) component realizes that values of literal constants does not affect query plan choice, it declares LPE's attempt of auto-parameterization "safe" and auto-parameterization proceeds; otherwise, auto-parameterization is declared "unsafe" and is aborted. Values of some of the perfmon counters mentioned in Section 11.5 ('SQLServer: SQL Statistics' category) report statistical information on auto-parameterization.
The following list enumerates the statement types for which SQL Server 2005 does not auto-parameterize.
| • |
Queries with IN clauses are not auto-parameterized. For example: |
||||||||||||||||||||||
| • |
WHERE ProductID IN (707, 799, 905) |
||||||||||||||||||||||
| • |
BULK INSERT statement. |
||||||||||||||||||||||
| • |
UPDATE statement with a SET clause that contains variables. For example: UPDATE Sales.Customer |
||||||||||||||||||||||
| • |
A SELECT statement with UNION. |
||||||||||||||||||||||
| • |
A SELECT statement with INTO clause. |
||||||||||||||||||||||
| • |
A SELECT or UPDATE statement with FOR BROWSE clause. |
||||||||||||||||||||||
| • |
A statement with query hints specified using the OPTION clause. |
||||||||||||||||||||||
| • |
A SELECT statement whose SELECT list contains a DISTINCT. |
||||||||||||||||||||||
| • |
A statement with the TOP clause. |
||||||||||||||||||||||
| • |
A WAITFOR statement. |
||||||||||||||||||||||
| • |
A DELETE or UPDATE with FROM clause. |
||||||||||||||||||||||
| • |
When FROM clause has one of the following:
|
||||||||||||||||||||||
| • |
When a SELECT query contains a sub-query |
||||||||||||||||||||||
| • |
When a SELECT statement has GROUP BY, HAVING, or COMPUTE BY |
||||||||||||||||||||||
| • |
Expressions joined by OR in a WHERE clause. |
||||||||||||||||||||||
| • |
Comparison predicates of the form expr <> non-null-constant. |
||||||||||||||||||||||
| • |
Full-text predicates. |
||||||||||||||||||||||
| • |
When the target table in an INSERT, UPDATE, or DELETE is a table-valued function. |
||||||||||||||||||||||
| • |
Statements submitted via EXEC string. |
||||||||||||||||||||||
| • |
Statements submitted via sp_executesql, sp_prepare, and sp_prepexec without parameters are auto-parameterized under TF 447. |
||||||||||||||||||||||
| • |
When query notification is requested. |
||||||||||||||||||||||
| • |
When a query contains a common table expression list. |
||||||||||||||||||||||
| • |
When a query contains FOR UPDATE clause. |
||||||||||||||||||||||
| • |
When an UPDATE contains an ORDER BY clause. |
||||||||||||||||||||||
| • |
When a query contains the GROUPING clause. |
||||||||||||||||||||||
| • |
INSERT statement of the form: INSERT INTO T DEFAULT VALUES. |
||||||||||||||||||||||
| • |
INSERT ... EXEC statement. |
||||||||||||||||||||||
| • |
When a query contains comparison between two constants. For example: WHERE 20 > 5 |
||||||||||||||||||||||
| • |
If by doing auto-parameterization, more than 1000 parameters can be created. |

