通往性能优化的天堂-地狱 JOIN方法说明
前言
不管是博客园还是CSDN,看到很多朋友对数据库的理解、认识还是没有突破一个瓶颈,而这个瓶颈往往只是一层窗纸,越过了你将看到一个新世界。
04、05年做项目的时候,用SQL Server 2000,核心表(大部分使用频繁的关键功能每次都要用到)达到了800万数据量,很早以前查过一些相关表,有的达到了3000多万,磁盘使用的光纤盘,100G空间,每周必须备份转移数据,否则100G空间一周会满掉,这个系统几年来,目前仍然保持非常良好的性能。还听说过朋友的SQL Server 2000数据库工作在几十TB的环境下,高并发量,对这种级别的驾驭能力我还是差的很遥远。
想当年,也是一提SQL Server,就觉得它的性能没法跟Oracle相比,一提到大数据处理就想到Oracle。自己一路走来,在本地blog上记录了很多优化方面的post,对的错的都有,没有时间系列的整理出来,这篇文章将join方法的概念稍微整理在一起,给大家个参考。通过查资料了解里面提到的各种概念,在实际中不断验证总结,完全可以对数据库一步步深入理解下去的。
我只对SQL Server 2000比较了解,但这并不阻碍我在Oracle、MySql进行SQL调优、产品架构,因为在数据库理论原理上,各大数据库基本出入不大,对数据库的深入理解,也不会影响你架构设计思想变坏,相反给你带来的是更深层次的思考。
RicCC:2007.06.26
关于执行计划的说明
在SQL Server查询分析器的Query菜单中选择Show Execution Plan,运行SQL查询语句,在结果窗口中有Grid、Execution Plan、Messages三个Tab。看图形形式的执行计划,顺序是从右到左,这也是执行的顺序。执行计划中的每一个图标表示一个操作,每一个操作都会 有一个或多个输入,也会有一个或多个输出。输入和输出,有可能是一个物理数据表、索引数据结构,或者是执行过程中的一些中间结果集/数据结构。鼠标移动到 图标上,会显示这个操作的具体信息,例如逻辑和物理操作名称、记录的数量和大小、I/O成本、CPU成本、操作的具体表达式(参数Argument)。鼠 标移动到连接箭头上,会显示箭头起始端的操作输出结果集的记录数、记录的大小,一般情况下可以将这个输出结果集理解为箭头结束端的输入。
另外关于执行计划的一些补充说明:1. 执行计划中显示的信息,都是一个“评估”的结果,不是100%准确的信息,例如记录数量是取自统计信息,I/O成本、CPU成本来自执行计划生成过程中基 于统计信息等得出的评估结果。2. 执行计划不一定准确,一方面受SQL Server维护的统计信息准确性的影响,另一方面SQL语句编译时刻与执行时刻的环境(内存使用状况、CPU状况等)可能会不一样。
关于统计信息、I/O成本和CPU成本的评估、SQL语句的编译和执行过程,这里不再深入。另外尽管执行计划不一定准确,但它仍是SQL语句分析最重要的依据,因为你可以理解为,绝大部分情况下,SQL Server是以这种方式来执行的。
JOIN方法说明
数据库中,象tableA inner join tableB、tableA left out join tableB这样的SQL语句是如何执行join操作的?就是说SQL Server使用什么算法实现两个表数据的join操作?
SQL Server 2000有三种方式:nested loop、merge、hash。Oracle也是使用这三种方式,不过Oracle选择使用nested loop的条件跟SQL Server有点差别,内存管理机制跟SQL Server不一样,因此查看执行计划,Oracle中nested loop运用非常多,而merge和hash方式相对较少,SQL Server中,merge跟hash方式则是非常普遍。
以SQL Server 2000为例对这三种方式进行说明,穿插在里面讲解执行计划的一些初级使用。
1. nested loop join
1.1 示例SQL
select ... from tableA inner join tableB on tableA.col1=tableB.col1 where tableA.col2=? and tableB.col2=?
tableA中没有建立任何索引,tableB中在col1上有建立一个主键(聚集索引)。
1.2 算法伪代码描述
foreach rowA in tableA where tableA.col2=?
{
search rowsB from tableB where tableB.col1=rowA.col1 and tableB.col2=? ;
if(rowsB.Count<=0)
discard rowA ;
else
output rowA and rowsB ;
}
join操作有两个输入,上面例子中tableA是outer input,用于外层循环;tableB是inner input,用于循环内部。下面针对执行计划描述一下SQL Server完成这个操作的具体步骤。
1.3 查看执行计划方法 移到文章最前面。
1.4 执行步骤
下面是示例SQL的执行计划图。nested loop操作的右边,位于上面的是outer input,位于下面的是inner input。你不能够根据join中哪个表出现在前面来确定outer input和inner input关系,而必须从执行计划中来确定,因为SQL Server会自动选择哪个作为inner input。
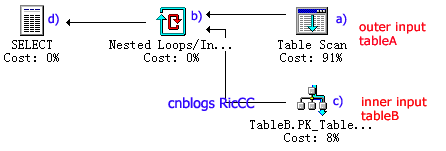
a) 对tableA执行Table Scan操作。这个操作的输入是tableA表中的数据,这些数据位于磁盘上,操作过程中被加载到内存;输出是符合条件的记录集,将作为b)的outer input。在这个操作中,tableA.col1=?的条件会被使用。
b) 执行上面伪代码描述的nested loop操作。对a)中的每个输出记录,执行步骤c)。
c) 对tableB执行Clustered Index Seek操作。这个操作是在nested loop循环里面执行的,输入是tableB表的聚集索引数据。它使用tableB.col1=rowA.col1和tableB.col2=?这两个条件,从tableB的聚集索引中选择符合条件的结果。
d) 构造返回结果集。从nested loop的输出中,整理出select中指定的字段,构造最终输出结果集。
1.5 进阶说明
上面例子对inner input使用的是聚集索引,下面看一下非聚集索引的情况,加强对执行计划的理解、分析能力。
把tableB col1上的主键修改为非聚集方式,示例的SQL语句执行计划如下:
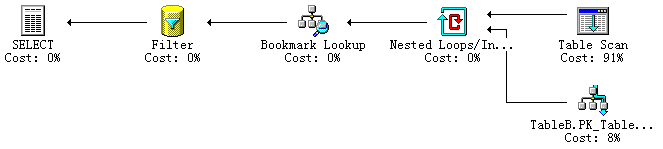
前面三个执行步骤a)、b)、c)跟1.4中一样,有一点需要注意的是,步骤c)是执行Index Seek操作,它跟Clustered Index Seek有区别。聚集索引的根节点是每一条实际数据记录,而非聚集索引的根节点是对聚集索引根结点键值的引用(如果表存在聚集索引),或者是对实际数据记录rowid的引用(指没有聚集索引的表,这种表称为heap表)。Clustered Index Seek执行之后,实际的物理数据记录已经被加载到内存中,而Index Seek操作之后,并没有加载实际的物理数据记录,而只是非聚集索引的根结点数据,其中只包含了索引字段数据以及引用的聚集索引键值或者rowid。SQL Server在这个步骤中使用非聚集索引根结点数据中的索引字段值,与outer input中的记录(rowA)关联字段进行匹配,判断是否是符合条件的结果,如果是,则将非聚集索引根结点数据结构保存到nested loop操作的输出数据结构中,并且会创建一个书签(Bookmark),指示在必要的时候需要根据这个书签去获取引用的数据。
d) 执行Bookmark Lookup操作。nested loop操作的输出是一个内存数据结构,在从这个内存数据结构中整理出整个查询语句的输出结果集之前,需要处理前面的书签引用问题,Bookmark Lookup操作就是根据书签中引用的聚集索引键值或者rowid获取具体记录数据。
e) Filter过滤操作。回顾前面几个操作,在执行nested loop时只是使用非聚集索引的索引字段(tableB.col1)跟outer input的关联字段进行匹配,到目前为止还没有使用tableB.col2=?这个条件,这个操作就是使用tableB.col2=?对Bookmark Lookup的输出进行过滤。
看的仔细的人到这里后可能会有几个疑问,1. tableA.col2=?怎么没有一个Filter操作?2. 在1.4中为什么没有出现Filter操作?解释如下:1. 在tableA上面执行的是Table Scan操作,是直接对每条实际数据进行扫描,在这个扫描过程中可以使用tableA.col2=?这个条件进行过滤,避免一个额外的Filter操作。鼠标移动到Table Scan操作上,从提示信息的参数(Argument)里面可以看到tableA.col2=?的条件已经被运用上了。2. 前面说过,聚集索引的根节点是实际数据记录,执行Clustered Index Seek的时候,最终也是扫描到了实际数据记录,在这个过程中运用tableB.col2=?这个条件,同样避免一个额外的Filter操作。这就是1.4中没有Filter操作的原因。
f) 构造返回结果集。跟1.4步骤d)一样。
1.6 nested loop使用条件
任何一个join操作,如果满足nested loop使用条件,查询优化过程中SQL Server就会对nested loop的成本(I/O成本、CPU成本等)进行评估,基于评估结果确定是否使用这种join方式。
使用nested loop方式的条件是:a) outer input的记录数不大,最好是在1000-2000以下,一般超过3000就很难说了,基本不大会选择nested loop。b) 作为inner input的表中,有可用于这个查询的索引。
这是因为outer input记录数不大,意味着外层循环次数比较小;inner input上有可用的索引,意味着在循环里面搜索inner input表中是否存在匹配的记录时,效率会很高,哪怕inner input表实际记录数有几百万。基于这两个条件,nested loop的执行效率非常高,在三种join方式里面,是内存和CPU消耗最少的一种(不合理的强制指定nested loop方式除外)。
关于使用条件另外的说明:outer input的记录数,并不是指outer input表中实际记录数,例如示例SQL中,如果tableA在col2上有维护统计信息(存在col2的索引或者是单独维护的统计信息),并且tableA.col2=?的条件值符合SARG(可搜索参数)形式,那么查询编译时刻SQL Server就能够利用统计信息和条件值评估出符合条件的记录数,查询执行时刻符合条件tableA.col2=?的记录才被用于外层循环。inner input表中有可用的索引,是指inner input表中用于和outer input表关联的字段(一个或多个字段)能够命中某个索引(这些字段的部分或者全部出现在某个索引字段的前面)。
符合上面的条件,也不是说SQL Server 100%就会选择nested loop。因为SQL Server的查询优化器是基于成本评估的,如果其它方案评估出的成本胜过这个,SQL Server会选择其它的join方式。举个例子,如果inner input上符合条件的索引是非聚集索引,这样SQL Server可能需要一个额外的Bookmark Lookup操作获取实际记录数据,如果inner input表数据量非常大,索引碎片程度很高等情况,可能导致Bookmark Lookup成本非常高,SQL Server会尝试其它join方案的评估选择。
1.7 强制指定nested loop方式
使用loop关键字实现,例如tableA inner loop join tableB,将强制SQL Server使用nested loop方式执行这个join操作。或者使用option选项,例如tableA inner join tableB option(loop join)
nested loop算法有它适用的范围,在这个范围之内效率是最高的,超出这个范围效率反而很差,除非你有十分的把握,不要随意强制指定join方式。
接下来就不再象上面这样详细的讲述了。
2. merge join
merge join第一个步骤是确保两个关联表都是按照关联的字段进行排序。如果关联字段有可用的索引,并且排序一致,则可以直接进行merge join操作;否则,SQL Server需要先对关联的表按照关联字段进行一次排序(就是说在merge join前的两个输入上,可能都需要执行一个Sort操作,再进行merge join)。
两个表都按照关联字段排序好之后,merge join操作从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。
在多对多的关联表上执行merge join时,通常需要使用临时表进行操作。例如A join B使用merge join时,如果对于关联字段的某一组值,在A和B中都存在多条记录A1、A2...An、B1、B2...Bn,则为A中每一条记录A1、A2...An,都必须在B中对所有相等的记录B1、B2...Bn进行一次匹配。这样,指针需要多次从B1移动到 Bn,每一次都需要读取相应的B1...Bn记录。将B1...Bn的记录预先读出来放入内存临时表中,比从原数据页或磁盘读取要快。
merge join操作本身是非常快的,但是merge join前进行的排序可能会相当耗时(SQL Server最消耗内存和CPU的操作,一个是大数据排序,一个是大数据的hash运算,这都是指查询计划里面的Sort以及Hash相关的操作,例如hash join、使用hash算法实现的Distinct操作等,而不是指你的SQL中order by关键字),尤其是对数据量非常大的记录集,因此导致使用merge join的查询成本变得非常高。对于数据量非常大的表,如果merge join的关联字段可以使用聚集索引,merge join是最快的Join方法之一。因此优化方案是在表结构设计层面良好的设计关联关系和表的索引结构,SQL语句充分利用索引,尽可能减少merge join前的排序操作,减少Bookmark Lookup操作。
一般情况下,如果无法满足nested loop条件,会考虑对merge join方法的评估。merge join的选择,主要是考虑两个输入的数据量,以及分别对应于关联字段是否能够命中索引。例如tableA join tableB,关联字段在两个表中都能命中索引,数据量超过了nested loop的选择范围,则会考虑使用merge join方法。当然,如果tableA和tableB的数据量过大导致评估出来的成本过高,则会放弃merge join而评估hash join了。
使用inner merge join或者option(merge join)强制使用merge join方法。
3. hash join
hash join有两个输入:build input(也叫做outer input)和probe input(也叫做inner input),不仅用于inner/left/right join等,象union/group by等也会使用hash join进行操作,在group by中build input和probe input都是同一个记录集。
同nested loop,在执行计划中build input位于上方,probe input位于下方。
hash join操作分两个阶段完成:build(构造)阶段和probe(探测)阶段。
Build阶段
这个阶段主要构造hash table。在inner/left/right join等操作中,表的关联字段作为hash key;在group by操作中,group by的字段作为hash key;在union或其它一些去除重复记录的操作中,hash key包括所有的select字段。
Build操作从build input输入中取出每一行记录,将该行记录关联字段的值使用hash函数生成hash值,这个hash值对应到hash table中的hash buckets(哈希表目)。如果一个hash值对应到多个hash buckts,则这些hash buckets使用链表数据结构连接起来。当整个build input的table处理完毕后,build input中的所有记录都被hash table中的hash buckets引用/关联了。
Probe阶段
在这个阶段,SQL Server从probe input输入中取出每一行记录,同样将该行记录关联字段的值,使用build阶段中相同的hash函数生成hash值,根据这个hash值,从build阶段构造的hash table中搜索对应的hash bucket。hash算法中为了解决冲突,hash bucket可能会链接到其它的hash bucket,probe动作会搜索整个冲突链上的hash bucket,以查找匹配的记录。
关于hash算法的细节,可以查看数据结构的一些资料。hash算法主要是用于大数据量的搜索,为了避免每次都象merge join一样在全部的数据中进行搜索匹配,通过合适的 hash函数,先给要搜索的数据根据hash key建立hash值作为索引,在搜索时,先通过hash值定位到一个较小的搜索范围,然后在这个范围中搜索匹配符合条件的结果,以提高效率。
SQL Server将数据量较小的表作为build input,尽量使根据build input构造的hash table能够完全放在内存中,这样probe阶段的匹配操作就完全是在内存中进行,这样的hash join叫做In-Memory Hash Join。
如果build input记录数非常大,构建的hash table无法在内存中容纳时,SQL Server分别将build input和probe input切分成多个分区部分(partition),每个partition都包括一个独立的、成对匹配的build input和probe input,这样就将一个大的hash join切分成多个独立、互相不影响的hash join,每一个分区的hash join都能够在内存中完成。SQL Server将切分后的partition文件保存在磁盘上,每次装载一个分区的build input和probe input到内存中,进行一次hash join。这种hash join叫做Grace Hash Join,使用的Grace Hash Join算法。
伴随着大数据的hash join运算,还会有standard external merge sorts、multiple merge levels、multiple partitioning steps、multiple partitioning levels,SQL Server还可能会使用Recursive Hash Join等算法或其它的优化手段。
hash join一般都用于大数据量的操作,例如join中某个表的数据达到一定程度或者无法一次加载到内存,另外如果你的关联字段在两个join表中都不能够命中索引,也是使用hash join来处理。因此一般情况下,hahs join处理代价非常高,是数据库服务器内存和CPU的头号杀手之一,尤其是涉及到分区(数据量太大导致内存不够的情况,或者并发访问很高导致当前处理线程无法获得足够的内存,那么数据量不是特大的情况下也可能需要进行分区),为了尽快的完成所有的分区步骤,将使用大量异步的I/O操作,因此期间单一一个线程就可能导致多个磁盘驱动器出于忙碌状态,这很有可能阻塞其它线程的执行。
使用inner hash join或者option (hash join)强制使用hash join方法。
建议
三种join方法,都是拥有两个输入。优化的基本原则:1. 避免大数据的hash join,尽量将其转化为高效的merge join、nested loop join。可能使用的手段有表结构设计、索引调整设计、SQL优化,以及业务设计优化。例如冗余字段的运用,将统计分析结果用service定期跑到静态表中,适当的冗余表,使用AOP或类似机制同步更新等。2. 尽量减少join两个输入端的数据量。这一点比较常犯的毛病是,条件不符合SARG(光这一点就有很多高超的技巧可以发挥),在子查询内部条件给的不充分(SQL过于复杂情况下SQL Server查询优化器经常犯傻,写在子查询外部的条件不会被用在子查询内部,影响子查询内部的效率或者是跟子查询再join时候的效率)。另外也是设计、业务端尽量限制这两个输入的数据量了。
关于业务设计方面的优化,参考以前写的一篇post:系统分析设计 一个JOIN问题解决方案的感想 重视业务分析设计。
补充(2007.06.27):关于SQL Server 2005
大致看了下SQL Server 2005,执行计划的显示确实有一些不一样,但主要部分或者说原理上是差不多的,不会有多少偏差。上面的示例SQL,在tableB上面使用非聚集索引时,SQL Server 2005的执行计划图如下:
一个主要的不同点是SQL Server 2000下面Bookmark Lookup操作,在2005下面显示成一个RID Lookup操作 + 一个Nested Loops操作实现,其实这也是很好理解的,可以说这样显示执行计划更合理一点,让你一看到这个操作,就知道它是通过一个循环机制到tableB中获取实际数据。
另外一点是,将鼠标移动到执行计划的图标上面后,弹出的提示信息的一些改变,例如2005里面会显示每个操作的输出列表(output list),而我上面的文章中基本都使用“输出数据结构”这样一个词汇在表达。通过查看output list,你更能明白RID Lookup(Bookmark Lookup)这样的操作存在的理由了。
最后,2005里面可以将图形显示的执行计划保存下来,以后可以打开再以图形方式进行查看分析,这个在2000下面是不行的,2000只能保存执行计划的文本。这样一些小功能对于分析SQL性能非常有用,在图形界面上的分析更直观。
不管是博客园还是CSDN,看到很多朋友对数据库的理解、认识还是没有突破一个瓶颈,而这个瓶颈往往只是一层窗纸,越过了你将看到一个新世界。
04、05年做项目的时候,用SQL Server 2000,核心表(大部分使用频繁的关键功能每次都要用到)达到了800万数据量,很早以前查过一些相关表,有的达到了3000多万,磁盘使用的光纤盘,100G空间,每周必须备份转移数据,否则100G空间一周会满掉,这个系统几年来,目前仍然保持非常良好的性能。还听说过朋友的SQL Server 2000数据库工作在几十TB的环境下,高并发量,对这种级别的驾驭能力我还是差的很遥远。
想当年,也是一提SQL Server,就觉得它的性能没法跟Oracle相比,一提到大数据处理就想到Oracle。自己一路走来,在本地blog上记录了很多优化方面的post,对的错的都有,没有时间系列的整理出来,这篇文章将join方法的概念稍微整理在一起,给大家个参考。通过查资料了解里面提到的各种概念,在实际中不断验证总结,完全可以对数据库一步步深入理解下去的。
我只对SQL Server 2000比较了解,但这并不阻碍我在Oracle、MySql进行SQL调优、产品架构,因为在数据库理论原理上,各大数据库基本出入不大,对数据库的深入理解,也不会影响你架构设计思想变坏,相反给你带来的是更深层次的思考。
RicCC:2007.06.26
关于执行计划的说明
在SQL Server查询分析器的Query菜单中选择Show Execution Plan,运行SQL查询语句,在结果窗口中有Grid、Execution Plan、Messages三个Tab。看图形形式的执行计划,顺序是从右到左,这也是执行的顺序。执行计划中的每一个图标表示一个操作,每一个操作都会 有一个或多个输入,也会有一个或多个输出。输入和输出,有可能是一个物理数据表、索引数据结构,或者是执行过程中的一些中间结果集/数据结构。鼠标移动到 图标上,会显示这个操作的具体信息,例如逻辑和物理操作名称、记录的数量和大小、I/O成本、CPU成本、操作的具体表达式(参数Argument)。鼠 标移动到连接箭头上,会显示箭头起始端的操作输出结果集的记录数、记录的大小,一般情况下可以将这个输出结果集理解为箭头结束端的输入。
另外关于执行计划的一些补充说明:1. 执行计划中显示的信息,都是一个“评估”的结果,不是100%准确的信息,例如记录数量是取自统计信息,I/O成本、CPU成本来自执行计划生成过程中基 于统计信息等得出的评估结果。2. 执行计划不一定准确,一方面受SQL Server维护的统计信息准确性的影响,另一方面SQL语句编译时刻与执行时刻的环境(内存使用状况、CPU状况等)可能会不一样。
关于统计信息、I/O成本和CPU成本的评估、SQL语句的编译和执行过程,这里不再深入。另外尽管执行计划不一定准确,但它仍是SQL语句分析最重要的依据,因为你可以理解为,绝大部分情况下,SQL Server是以这种方式来执行的。
JOIN方法说明
数据库中,象tableA inner join tableB、tableA left out join tableB这样的SQL语句是如何执行join操作的?就是说SQL Server使用什么算法实现两个表数据的join操作?
SQL Server 2000有三种方式:nested loop、merge、hash。Oracle也是使用这三种方式,不过Oracle选择使用nested loop的条件跟SQL Server有点差别,内存管理机制跟SQL Server不一样,因此查看执行计划,Oracle中nested loop运用非常多,而merge和hash方式相对较少,SQL Server中,merge跟hash方式则是非常普遍。
以SQL Server 2000为例对这三种方式进行说明,穿插在里面讲解执行计划的一些初级使用。
1. nested loop join
1.1 示例SQL
select ... from tableA inner join tableB on tableA.col1=tableB.col1 where tableA.col2=? and tableB.col2=?
tableA中没有建立任何索引,tableB中在col1上有建立一个主键(聚集索引)。
1.2 算法伪代码描述
foreach rowA in tableA where tableA.col2=?
{
search rowsB from tableB where tableB.col1=rowA.col1 and tableB.col2=? ;
if(rowsB.Count<=0)
discard rowA ;
else
output rowA and rowsB ;
}
join操作有两个输入,上面例子中tableA是outer input,用于外层循环;tableB是inner input,用于循环内部。下面针对执行计划描述一下SQL Server完成这个操作的具体步骤。
1.3 查看执行计划方法 移到文章最前面。
1.4 执行步骤
下面是示例SQL的执行计划图。nested loop操作的右边,位于上面的是outer input,位于下面的是inner input。你不能够根据join中哪个表出现在前面来确定outer input和inner input关系,而必须从执行计划中来确定,因为SQL Server会自动选择哪个作为inner input。
a) 对tableA执行Table Scan操作。这个操作的输入是tableA表中的数据,这些数据位于磁盘上,操作过程中被加载到内存;输出是符合条件的记录集,将作为b)的outer input。在这个操作中,tableA.col1=?的条件会被使用。
b) 执行上面伪代码描述的nested loop操作。对a)中的每个输出记录,执行步骤c)。
c) 对tableB执行Clustered Index Seek操作。这个操作是在nested loop循环里面执行的,输入是tableB表的聚集索引数据。它使用tableB.col1=rowA.col1和tableB.col2=?这两个条件,从tableB的聚集索引中选择符合条件的结果。
d) 构造返回结果集。从nested loop的输出中,整理出select中指定的字段,构造最终输出结果集。
1.5 进阶说明
上面例子对inner input使用的是聚集索引,下面看一下非聚集索引的情况,加强对执行计划的理解、分析能力。
把tableB col1上的主键修改为非聚集方式,示例的SQL语句执行计划如下:
前面三个执行步骤a)、b)、c)跟1.4中一样,有一点需要注意的是,步骤c)是执行Index Seek操作,它跟Clustered Index Seek有区别。聚集索引的根节点是每一条实际数据记录,而非聚集索引的根节点是对聚集索引根结点键值的引用(如果表存在聚集索引),或者是对实际数据记录rowid的引用(指没有聚集索引的表,这种表称为heap表)。Clustered Index Seek执行之后,实际的物理数据记录已经被加载到内存中,而Index Seek操作之后,并没有加载实际的物理数据记录,而只是非聚集索引的根结点数据,其中只包含了索引字段数据以及引用的聚集索引键值或者rowid。SQL Server在这个步骤中使用非聚集索引根结点数据中的索引字段值,与outer input中的记录(rowA)关联字段进行匹配,判断是否是符合条件的结果,如果是,则将非聚集索引根结点数据结构保存到nested loop操作的输出数据结构中,并且会创建一个书签(Bookmark),指示在必要的时候需要根据这个书签去获取引用的数据。
d) 执行Bookmark Lookup操作。nested loop操作的输出是一个内存数据结构,在从这个内存数据结构中整理出整个查询语句的输出结果集之前,需要处理前面的书签引用问题,Bookmark Lookup操作就是根据书签中引用的聚集索引键值或者rowid获取具体记录数据。
e) Filter过滤操作。回顾前面几个操作,在执行nested loop时只是使用非聚集索引的索引字段(tableB.col1)跟outer input的关联字段进行匹配,到目前为止还没有使用tableB.col2=?这个条件,这个操作就是使用tableB.col2=?对Bookmark Lookup的输出进行过滤。
看的仔细的人到这里后可能会有几个疑问,1. tableA.col2=?怎么没有一个Filter操作?2. 在1.4中为什么没有出现Filter操作?解释如下:1. 在tableA上面执行的是Table Scan操作,是直接对每条实际数据进行扫描,在这个扫描过程中可以使用tableA.col2=?这个条件进行过滤,避免一个额外的Filter操作。鼠标移动到Table Scan操作上,从提示信息的参数(Argument)里面可以看到tableA.col2=?的条件已经被运用上了。2. 前面说过,聚集索引的根节点是实际数据记录,执行Clustered Index Seek的时候,最终也是扫描到了实际数据记录,在这个过程中运用tableB.col2=?这个条件,同样避免一个额外的Filter操作。这就是1.4中没有Filter操作的原因。
f) 构造返回结果集。跟1.4步骤d)一样。
1.6 nested loop使用条件
任何一个join操作,如果满足nested loop使用条件,查询优化过程中SQL Server就会对nested loop的成本(I/O成本、CPU成本等)进行评估,基于评估结果确定是否使用这种join方式。
使用nested loop方式的条件是:a) outer input的记录数不大,最好是在1000-2000以下,一般超过3000就很难说了,基本不大会选择nested loop。b) 作为inner input的表中,有可用于这个查询的索引。
这是因为outer input记录数不大,意味着外层循环次数比较小;inner input上有可用的索引,意味着在循环里面搜索inner input表中是否存在匹配的记录时,效率会很高,哪怕inner input表实际记录数有几百万。基于这两个条件,nested loop的执行效率非常高,在三种join方式里面,是内存和CPU消耗最少的一种(不合理的强制指定nested loop方式除外)。
关于使用条件另外的说明:outer input的记录数,并不是指outer input表中实际记录数,例如示例SQL中,如果tableA在col2上有维护统计信息(存在col2的索引或者是单独维护的统计信息),并且tableA.col2=?的条件值符合SARG(可搜索参数)形式,那么查询编译时刻SQL Server就能够利用统计信息和条件值评估出符合条件的记录数,查询执行时刻符合条件tableA.col2=?的记录才被用于外层循环。inner input表中有可用的索引,是指inner input表中用于和outer input表关联的字段(一个或多个字段)能够命中某个索引(这些字段的部分或者全部出现在某个索引字段的前面)。
符合上面的条件,也不是说SQL Server 100%就会选择nested loop。因为SQL Server的查询优化器是基于成本评估的,如果其它方案评估出的成本胜过这个,SQL Server会选择其它的join方式。举个例子,如果inner input上符合条件的索引是非聚集索引,这样SQL Server可能需要一个额外的Bookmark Lookup操作获取实际记录数据,如果inner input表数据量非常大,索引碎片程度很高等情况,可能导致Bookmark Lookup成本非常高,SQL Server会尝试其它join方案的评估选择。
1.7 强制指定nested loop方式
使用loop关键字实现,例如tableA inner loop join tableB,将强制SQL Server使用nested loop方式执行这个join操作。或者使用option选项,例如tableA inner join tableB option(loop join)
nested loop算法有它适用的范围,在这个范围之内效率是最高的,超出这个范围效率反而很差,除非你有十分的把握,不要随意强制指定join方式。
接下来就不再象上面这样详细的讲述了。
2. merge join
merge join第一个步骤是确保两个关联表都是按照关联的字段进行排序。如果关联字段有可用的索引,并且排序一致,则可以直接进行merge join操作;否则,SQL Server需要先对关联的表按照关联字段进行一次排序(就是说在merge join前的两个输入上,可能都需要执行一个Sort操作,再进行merge join)。
两个表都按照关联字段排序好之后,merge join操作从每个表取一条记录开始匹配,如果符合关联条件,则放入结果集中;否则,将关联字段值较小的记录抛弃,从这条记录对应的表中取下一条记录继续进行匹配,直到整个循环结束。
在多对多的关联表上执行merge join时,通常需要使用临时表进行操作。例如A join B使用merge join时,如果对于关联字段的某一组值,在A和B中都存在多条记录A1、A2...An、B1、B2...Bn,则为A中每一条记录A1、A2...An,都必须在B中对所有相等的记录B1、B2...Bn进行一次匹配。这样,指针需要多次从B1移动到 Bn,每一次都需要读取相应的B1...Bn记录。将B1...Bn的记录预先读出来放入内存临时表中,比从原数据页或磁盘读取要快。
merge join操作本身是非常快的,但是merge join前进行的排序可能会相当耗时(SQL Server最消耗内存和CPU的操作,一个是大数据排序,一个是大数据的hash运算,这都是指查询计划里面的Sort以及Hash相关的操作,例如hash join、使用hash算法实现的Distinct操作等,而不是指你的SQL中order by关键字),尤其是对数据量非常大的记录集,因此导致使用merge join的查询成本变得非常高。对于数据量非常大的表,如果merge join的关联字段可以使用聚集索引,merge join是最快的Join方法之一。因此优化方案是在表结构设计层面良好的设计关联关系和表的索引结构,SQL语句充分利用索引,尽可能减少merge join前的排序操作,减少Bookmark Lookup操作。
一般情况下,如果无法满足nested loop条件,会考虑对merge join方法的评估。merge join的选择,主要是考虑两个输入的数据量,以及分别对应于关联字段是否能够命中索引。例如tableA join tableB,关联字段在两个表中都能命中索引,数据量超过了nested loop的选择范围,则会考虑使用merge join方法。当然,如果tableA和tableB的数据量过大导致评估出来的成本过高,则会放弃merge join而评估hash join了。
使用inner merge join或者option(merge join)强制使用merge join方法。
3. hash join
hash join有两个输入:build input(也叫做outer input)和probe input(也叫做inner input),不仅用于inner/left/right join等,象union/group by等也会使用hash join进行操作,在group by中build input和probe input都是同一个记录集。
同nested loop,在执行计划中build input位于上方,probe input位于下方。
hash join操作分两个阶段完成:build(构造)阶段和probe(探测)阶段。
Build阶段
这个阶段主要构造hash table。在inner/left/right join等操作中,表的关联字段作为hash key;在group by操作中,group by的字段作为hash key;在union或其它一些去除重复记录的操作中,hash key包括所有的select字段。
Build操作从build input输入中取出每一行记录,将该行记录关联字段的值使用hash函数生成hash值,这个hash值对应到hash table中的hash buckets(哈希表目)。如果一个hash值对应到多个hash buckts,则这些hash buckets使用链表数据结构连接起来。当整个build input的table处理完毕后,build input中的所有记录都被hash table中的hash buckets引用/关联了。
Probe阶段
在这个阶段,SQL Server从probe input输入中取出每一行记录,同样将该行记录关联字段的值,使用build阶段中相同的hash函数生成hash值,根据这个hash值,从build阶段构造的hash table中搜索对应的hash bucket。hash算法中为了解决冲突,hash bucket可能会链接到其它的hash bucket,probe动作会搜索整个冲突链上的hash bucket,以查找匹配的记录。
关于hash算法的细节,可以查看数据结构的一些资料。hash算法主要是用于大数据量的搜索,为了避免每次都象merge join一样在全部的数据中进行搜索匹配,通过合适的 hash函数,先给要搜索的数据根据hash key建立hash值作为索引,在搜索时,先通过hash值定位到一个较小的搜索范围,然后在这个范围中搜索匹配符合条件的结果,以提高效率。
SQL Server将数据量较小的表作为build input,尽量使根据build input构造的hash table能够完全放在内存中,这样probe阶段的匹配操作就完全是在内存中进行,这样的hash join叫做In-Memory Hash Join。
如果build input记录数非常大,构建的hash table无法在内存中容纳时,SQL Server分别将build input和probe input切分成多个分区部分(partition),每个partition都包括一个独立的、成对匹配的build input和probe input,这样就将一个大的hash join切分成多个独立、互相不影响的hash join,每一个分区的hash join都能够在内存中完成。SQL Server将切分后的partition文件保存在磁盘上,每次装载一个分区的build input和probe input到内存中,进行一次hash join。这种hash join叫做Grace Hash Join,使用的Grace Hash Join算法。
伴随着大数据的hash join运算,还会有standard external merge sorts、multiple merge levels、multiple partitioning steps、multiple partitioning levels,SQL Server还可能会使用Recursive Hash Join等算法或其它的优化手段。
hash join一般都用于大数据量的操作,例如join中某个表的数据达到一定程度或者无法一次加载到内存,另外如果你的关联字段在两个join表中都不能够命中索引,也是使用hash join来处理。因此一般情况下,hahs join处理代价非常高,是数据库服务器内存和CPU的头号杀手之一,尤其是涉及到分区(数据量太大导致内存不够的情况,或者并发访问很高导致当前处理线程无法获得足够的内存,那么数据量不是特大的情况下也可能需要进行分区),为了尽快的完成所有的分区步骤,将使用大量异步的I/O操作,因此期间单一一个线程就可能导致多个磁盘驱动器出于忙碌状态,这很有可能阻塞其它线程的执行。
使用inner hash join或者option (hash join)强制使用hash join方法。
建议
三种join方法,都是拥有两个输入。优化的基本原则:1. 避免大数据的hash join,尽量将其转化为高效的merge join、nested loop join。可能使用的手段有表结构设计、索引调整设计、SQL优化,以及业务设计优化。例如冗余字段的运用,将统计分析结果用service定期跑到静态表中,适当的冗余表,使用AOP或类似机制同步更新等。2. 尽量减少join两个输入端的数据量。这一点比较常犯的毛病是,条件不符合SARG(光这一点就有很多高超的技巧可以发挥),在子查询内部条件给的不充分(SQL过于复杂情况下SQL Server查询优化器经常犯傻,写在子查询外部的条件不会被用在子查询内部,影响子查询内部的效率或者是跟子查询再join时候的效率)。另外也是设计、业务端尽量限制这两个输入的数据量了。
关于业务设计方面的优化,参考以前写的一篇post:系统分析设计 一个JOIN问题解决方案的感想 重视业务分析设计。
补充(2007.06.27):关于SQL Server 2005
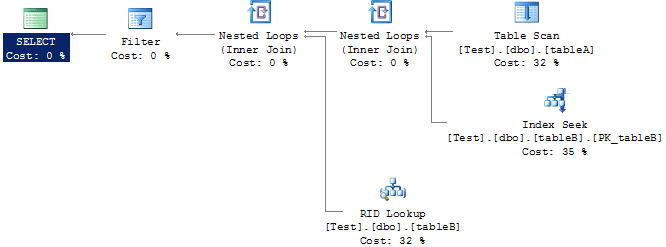
大致看了下SQL Server 2005,执行计划的显示确实有一些不一样,但主要部分或者说原理上是差不多的,不会有多少偏差。上面的示例SQL,在tableB上面使用非聚集索引时,SQL Server 2005的执行计划图如下:
一个主要的不同点是SQL Server 2000下面Bookmark Lookup操作,在2005下面显示成一个RID Lookup操作 + 一个Nested Loops操作实现,其实这也是很好理解的,可以说这样显示执行计划更合理一点,让你一看到这个操作,就知道它是通过一个循环机制到tableB中获取实际数据。
另外一点是,将鼠标移动到执行计划的图标上面后,弹出的提示信息的一些改变,例如2005里面会显示每个操作的输出列表(output list),而我上面的文章中基本都使用“输出数据结构”这样一个词汇在表达。通过查看output list,你更能明白RID Lookup(Bookmark Lookup)这样的操作存在的理由了。
最后,2005里面可以将图形显示的执行计划保存下来,以后可以打开再以图形方式进行查看分析,这个在2000下面是不行的,2000只能保存执行计划的文本。这样一些小功能对于分析SQL性能非常有用,在图形界面上的分析更直观。


