


Hadoop3 在eclipse中访问hadoop并运行WordCount实例
前言:
毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了。对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环境跑起来,然后在能用的基础上在多想想为什么。
通过这三个礼拜(基本上就是周六周日,其他时间都在加班啊T T)的探索,我目前主要完成的是:
1.在Linux环境中伪分布式部署hadoop(SSH免登陆),运行WordCount实例成功。 http://www.cnblogs.com/PurpleDream/p/4009070.html
2.自己打包hadoop在eclipse中的插件。 http://www.cnblogs.com/PurpleDream/p/4014751.html
3.在eclipse中访问hadoop运行WordCount成功。 http://www.cnblogs.com/PurpleDream/p/4021191.html
所以我下边会分三次记录下我的过程,为自己以后查阅方便,要是能帮助到其他人,自然是更好了!
===============================================================长长的分割线====================================================================
正文:
在之前的两篇文章中,我主要是介绍了自己初次学习hadoop的过程中是如何将hadoop伪分布式模式部署到linux环境中的,以及如何自己编译一个hadoop的eclipse插件。如果大家有需要的话,可以点击我在前言中列出的前两篇文章的链接。
今天,我将在eclipse中,讲解如何使用MapReduce。对于下面的问题,我们首先讲解的是,如何在eclipse中配置DFS Location,然后讲解的是,在配置好的Location上运行WordCount实例。
第一步,配置DFS Location:
1.打开eclipse之后,切换到Map/Reduce模式,点击右下角的“new hadoop Location”图标,弹出一个弹出框,如下图所示,页面中中有两个页签需要配置,分别是General和Advanced Parameters。

2.首先,我们先配置General中内容。General中主要需要我们进行Map/Reduce和HDFS的host的配置。
(1).之前我们在Linux安装hadoop时,曾经修改了两个配置文件,分别是mapred-site.xml和core-site.xml。当时我们再配置的时候,配置的主机就是localhost和端口号。这里由于我们是在eclipse远程访问你Linux服务器中的hadoop,所以我们需要将原来配
置文件中的localhost修改成你服务器的ip地址,端口号不变(当然你可以参考网上的文章,配置host文件)。
(2).然后将eclipse中我们刚才打开的General页签中的Map/Reduce的host配置成你的mapred-site.xml配置的ip地址和端口号;再将HDFS的host配置成你的core-site.xml配置的ip地址和端口号。注意,如果你勾选了HDFS中的那个“Use M/R Master Host”选项,那么HDFS的host将默认与Map/Reduce中配置的ip地址一致,端口号可另行配置。
3.然后,我们要配置的是Advanced Parameters这个选项卡中的内容,这里面的内容比较多,但是不要紧张哦,因为我们在第一次配置时,可以使用他的默认配置。
(1)打开这个选项卡,我们可以浏览一下这里面的内容,着重看下其中选项值包含“/tmp/.....”这种目录结构的选项,如果我们后边自己配置的话,其实要修改的也就是这些项。默认的“dfs.data.dir”是在linux服务器中的“/tmp”目录下,有时会带上你的root账号,这个可以根据自己的需要。
(2).如果你不想使用上边的默认配置,则我们根据自己的需要,在我们安装的hadoop中的hdfs-site.xml文件中,增加对“dfs.data.dir”这个选项的配置,对应的目录自己可以提前建立,我的配置如图:

<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.data.dir</name> <value>/myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/dfs_data_dir</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
(3).以我的配置为例,如果我在hadoop的服务器端做了这样的配置,那么我在Advanced Parameters选项卡中,需要修改下面的的几个选项的value值,注意,其实有个小技巧,你在配置的时候,先找到“hadoop.tmp.dir”这个选项,将这个选项配置成你自定义的目录位置,然后将Location这个弹出框关掉,再选中刚才的那个Location重新点击右下角的“Edit hadoop Location”选项(在“new hadoop Location”旁边),然后再切换到Advanced Parameters选项卡,会发现与之相关的几个选项的目录前缀都会发生改变,这时候你在浏览一下其他选项,确保目录前缀都进行了修改,就ok了。
dfs.data.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/data
dfs.name.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/name
dfs.name.edits.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/name
fs.checkpoint.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/namesecondary
fs.checkpoint.edits.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/dfs/namesecondary
fs.s3.buffer.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/s3
hadoop.tmp.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir
mapred.local.dor => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/local
mapred.system.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/system
mapred.temp.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/temp
mapreduce.jobtracker.staging.root.dir => /myself_setted/hadoop/hadoop-1.0.1/myself_data_dir/hadoop_tmp_dir/mapred/staging
4.经过上边的几步,我们自己的Location已经配置完了,这时候如果没有什么问题的话,会在我们的eclipse的左上角“DFS Location”的下面,显示出我们刚刚配置好的Location,右键点击这个Location的选择“Refresh”或者“ReConnect”,如果之前的配置没有问题的话,会显示我们再第一篇文章中上传的a.txt文件,以及我们之前在linux服务器端运行hadoop成功的output文件夹,如下图。如果没有上传文件,那么只会显示“dfs.data.dir”这个目录。

第二步,运行Word Count实例:
1.Location配置好之后,我们可以在eclipse中建立一个MapReduce项目的工程。
(1).利用反编译软件,从hadoop-1.0.1的安装包中反编译hadoop-examples-1.0.1.jar这个jar包,将其中的Word Count类取出来,放到你刚才建立的工程中。注意,如果你之前参考的在编译eclipse的hadoop插件时,参考的是我的第二篇文章的方法,这里需要加一步,右键点击项目选择buidld Path,对于以“hadoop-”开头的jar包,除了“hadoop-core-1.0.1.jar”和“hadoop-tools-1.0.1.jar”这两个jar包,其余的以“hadoop-”开头的jar包都要删除掉。主要是因为如果不删除,会导致WordCount这个类方法中的有些累引入的不正确。
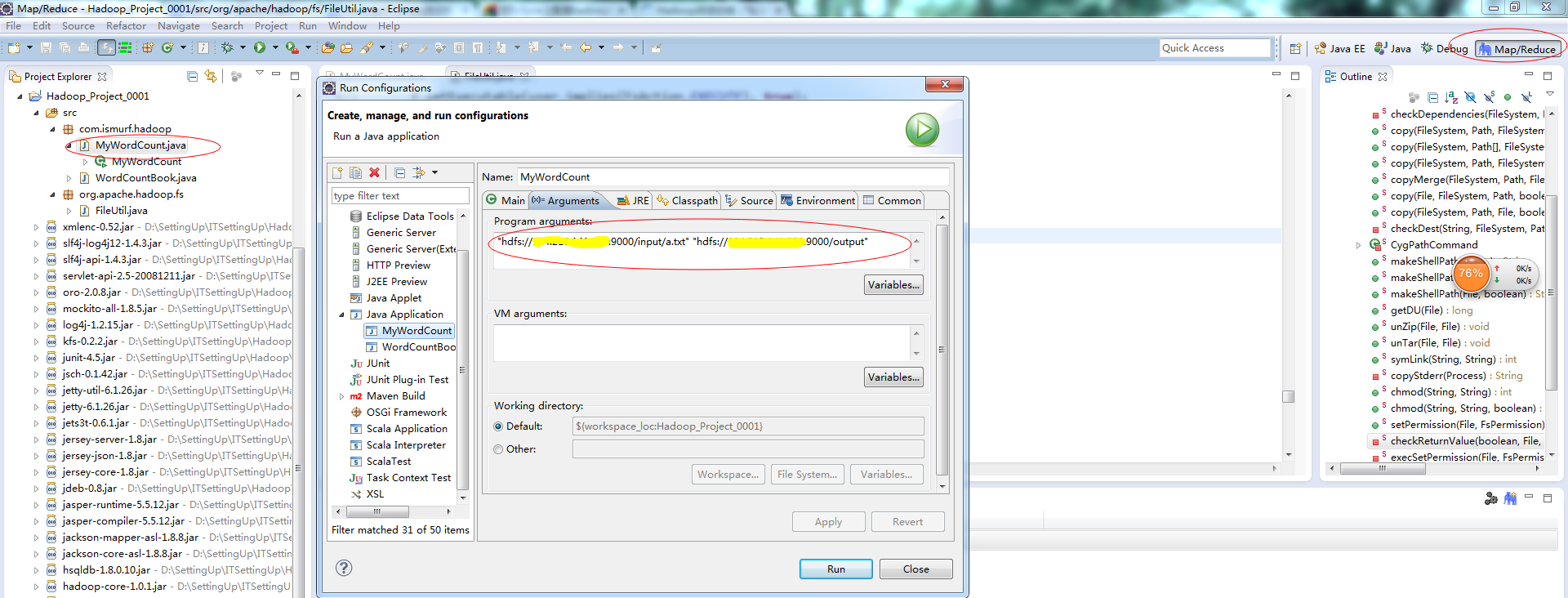
2.项目建立好之后,我们在WordCount类中,右键选择“Run Configurations”弹出一个弹出框,如下图,然后选中“Arguments”选项卡,在其中的“Program arguments”中配置你的hdfs的input文件的目录和output目录,然后点击“run”,运行即可,如果在console中没有抛出异常,证明运行成功,可选择左上角的Location,选择“Refresh”,会显示你的output文件夹以及运行的结果文件。
第三步,错误排除:
1.如果之前的output文件夹存在,你直接在eclipse中运行WordCount方法的话,可能console会报“output文件夹已经存在”这个错误,那么你只需要现将Location中的output文件夹删除,这个错误就不会报了。
2.如果你运行的过程中报了“org.apache.hadoop.security.AccessControlException: Permission denied:。。。。”这个错误,是由于本地用户想要远程操作hadoop没有权限引起的,这时,我们需要在hdfs-site.xml中配置dfs.permissions属性修改为false(默认为true),可以参考本文上边关于“hdfs-site.xml”的配置。
3.如果你运行的过程中报了“Failed to set permissions of path:。。。。”这个错误,解决方法是修改/hadoop-1.0.1/src/core/org/apache/hadoop/fs/FileUtil.java里面的checkReturnValue,注释掉即可(有些粗暴,在Window下,可以不用检查)。注意,此处修改时,网上的一般方法是,重新编译hadoop-core的源码,然后重新打包。其实如果想省事儿一点的话,我们可以在项目中建立一个org.apache.hadoop.fs这个包,将FileUtil.java这个类复制到这个包里面,按照下边图片中的修改方法,修改FileUtil.java就行了。之所以这种方法也行,是因为java运行时,会优先默认在本项目的源码中扫描相同路径的包,然后才是引入的jar文件中的。

经过上边的步骤,我想多数情况下,你已经成功的在eclipse中远程访问了你的hadoop了,也许在你实践的过程中还会碰到其他问题,只要你耐心的在网上搜索资料,相信一定可以解决的,切记不要太着急。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)