我的python之路【第三章】函数
回顾:
文件操作


#python2 # msg="中国" # msg.decode(encoding="utf-8") # print(msg) #python3中,python解释器是以unicode编码,程序文件存储的是utf-8. #当utf-8格式程序执行时解释器从内存中运行时全部转换成unicode。 ''' python3.X 默认文件是 utf-8 解释器编码是unicode,文件加载到内存后会自动编码成unicode,同时,把字符转换为byte类型 byte=8bit ''' msg="中国" print(msg.encode("gbk")) #输出:b'\xd6\xd0\xb9\xfa' f=open("file",'r+') #省略编码时,默认使用操作系统的默认编码gbk格式。 ''' a :追加 r+ :追加和读。从文件开始追加,可以定长修改。直接在原文内容上写入数据,擦除现有数据 w+ :清空原文件内容,再写入新内容。 a+ :追加+读,从文件末尾追加 f.seek(10),代表移动10个字节,注意汉字占用3个字节。 f.read(6),代表读取6个字符。 rb :以二进制模式打开文件,不能声明encoding。读取显示的时候使用decode wb :以二进制写入文件,必须写入bytes格式。使用write写入时候,可以指定encode编码集 f.fileno() 文件描述符, f.truncate(100) 从头开始截断100个字符,只能从头截断 '''
1、函数
函数的特性:
1、减少重复代码
2、使程序变得可扩展
3、便于维护
创建一个简单的函数:
def sayhi(name): print("hello %s"%name) sayhi('alex') sayhi('memu')
#实参:alex,memu 有确定值的参数,所有的数据类型都可以被当作参数传递给函数
#形参:name 只有在被调用时才分配内存,调用结束后,立刻释放内存。值仅仅在函数内部有效(局部变量)
#形参的作用域,只在当前函数内部
def change(n): print(n) #引用的全局变量 n="changed by func" #局部变量,外部不会调用 n='test' #全局变量 change(n) print(n)
局部变量:作用域只在当前函数内部,外部变量默认不能被函数内部修改,只能引用。
如果想在函数里修改全局变量,必须global,但是强烈的建议不要这样用。
#函数引用全局变量 def change(): print(n) n="test123" change()
#函数内部修改全局变量 def change(): global n #通过global进行声明全局变量 n="changed by func" print(n) n="test123" change() print(n)
注意:函数内部是可以修改列表,字典,集合,实例
原因:函数内部调用的内存地址是没有发生改变的。但是列表内存地址的指向元素,元素也是存入到其它内存地址的。
def change(): names[0]='Mac' #函数内修改全局的列表 pp['age']=22 names=['alex','rain'] pp={'name':"alex"} print(id(names),id(names[0])) #id查看内存编号 change() print(id(names),id(names[0])) print(names) print(pp)
位置参数,按顺序执行
默认参数,必须放在位置参数后面
关键参数,必须放在位置参数后面 age=22
非固定参数,*args =() 以位置参数的形式传入, **kwargs={} 以关键参数形式传入。
def stu_register(name, age, country, course='python_devops',*args,**kwargs):#前面是位置参数,最后面是默认参数, #*args是有位置参数传入的 print("----注册佳佳幼儿园大班信息------") print("姓名:", name) print("age:", age) print("国籍:", country) print("课程:", course) print(args) print(kwargs) #"小个子"属于不固定参数中的位置参数,所以传入到args中下面addr为关键参数,必须放到位置参数的后面。由于函数内没有addr所以会传入到kwargs中。 stu_register("贺山炮", 22, "CN", "python_devops",'小个子',addr='北京市') stu_register("贺磊叫春", 21, "CN", "linux")
二、高阶函数:
#高阶函数就是在函数中调用其它函数。 ''' a.把一个函数名当作实参传给另一个函数 b.返回值中包含函数名 ''' def add(x,y,f): return f(x)+f(y) #abs是系统内置函数,绝对值。3的绝对值加-10的绝对值 res= add(3,-10,abs) print(res)
三、递归函数:
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身。这个函数就是递归函数。
特性:
1、必须有一个明确的结束条件
2、每次进入更深一层递归时,问题规模相比上次递归都应有有所减少
3、递归效率不高,递归层次过多会导致栈溢出,(在计算机中,函数调用通过栈(stack)这种数据结构实现的,
每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会加一层栈帧,每当函数返回,
栈就会减少一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
def calc(n): print(n) if int(n/2) >0: return calc(int(n/2)) calc(10)
四、嵌套函数:
name = "Alex" def change_name(): name = "Alex2" def change_name2(): name = "Alex3" print("第3层打印", name) change_name2() # 调用内层函数 print("第2层打印", name) change_name() print("最外层打印", name)
练习:二分查找,问题如果是汉字怎么查找?
#return 代表函数的结束,返回函数的结果 #二分查找 #mid 中间 data=range(0,100000000000,3) def two_1(str_search,data): mid=int(len(data)/2) #找到data列表中间的位置 if mid ==0: if data[mid] ==str_search: print("find it ",data[mid]) else: print("not find ") elif data[mid]==str_search: print("find it ",data[mid]) elif data[mid] > str_search: #应该去左边查找 print("find to 左边 ",data[0:mid]) two_1(str_search,data[0:mid]) elif data[mid] < str_search: #应该去右边查找 print("find to 右边",data[mid:]) two_1(str_search,data[mid:]) two_1(9999,data)
提示:
#如果是汉字,利用hash算法进行加密,使所有字符变成字符,再进行排序,对字符进行二分查找。
作业
有以下员工信息表
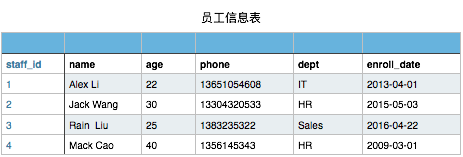
当然此表你在文件存储时可以这样表示
|
1
|
1,Alex Li,22,13651054608,IT,2013-04-01 |
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
