[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<2>
前言:上篇[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<1>中介绍了ES ,Kibana的单机到分布式的安装,这里主要是介绍Elasticsearch5.3.1的一些概念。官方示例的基本数据导入,数据查询以及ES,kibana的功能组件的认识和熟悉。
一、Elasticsearch中的基本概念:
Elasticsearch所涉及到的每一项技术都不是创新或者革命性的,全文检索,分析系统以及分布式数据库这些早就已经存在了。它的革命性在于将这些独立且有用的技术整合成一个一体化的、实时的应用。它对新用户的门槛很低,当然它也会跟上你技能和需求增长的步伐。-《Elasticsearch权威指南》
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档 (document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在 Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之 一。 -《Elasticsearch权威指南》
在数据库的学习中我们就知道了索引这个概念,索引是为提高查询效率而诞生的。索引让我们更快的定位需要查询的关键字。以Mysql来说:[从索引的数据结构划分]Mysql数据库中包含FULLTEXT,HASH,BTREE,RTREE这几种索引,分别是全文索引(全文索引是MyISAM的一个特殊索引类型,主要用于全文检索),hash索引(只有Memory存储引擎显示支持hash索引),B-tree B树索引(目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构),R-tree 空间索引(MyISAM支持空间索引,主要用于地理空间数据类型)。
全文索引(FULL-TEXT):用于全文检索(在一个文件中搜索匹配的词),又被称为倒排文档索引,是现代搜索引擎的关键技术。这也是ES的核心侧重点,致力于用户以前所未有的速度检索和分析大数据。
1、Mapping:相当于数据库表的schema,即定义这张表的字段和类型
2、Index:索引相当于数据库
3、Type:相当于数据库的表
4、Document:行数据
5、Fileds:字段
6、Id:相当于记录的编号
7、shared:分片,这是ES提供分布式搜索的基础,其含义为将一个完整的index分成若干部分存储在相同或不同的节点上,这些组成index的部分就叫做shard
二、Elasticsearch官方示例数据的导入:[localhost换成本机IP即可]
1、获取示例数据:
-
wget https://download.elastic.co/demos/kibana/gettingstarted/shakespeare.json wget https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip wget https://download.elastic.co/demos/kibana/gettingstarted/logs.jsonl.gz
解压缩:
-
unzip accounts.zip gunzip logs.jsonl.gz
2、导入示例数据:随便选取一个节点导入,这里为分布式环境,单机版同理。
- 创建mapping: 以下下指令可以直接在终端运行,也可以在Kibana的控制台运行。
-
curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/shakespeare -d ' {"mappings" : { "_default_" : { "properties" : { "speaker" : {"type": "string", "index" : "not_analyzed" }, "play_name" : {"type": "string", "index" : "not_analyzed" }, "line_id" : { "type" : "integer" }, "speech_number" : { "type" : "integer" } } } } }';
curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/logstash-2015.05.18 -d ' {"mappings": { "log": { "properties": { "geo": { "properties": { "coordinates": { "type": "geo_point" } } } } } } }';
curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/logstash-2015.05.19 -d ' {"mappings": { "log": { "properties": { "geo": { "properties": { "coordinates": { "type": "geo_point" } } } } } } }';
curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/logstash-2015.05.20 -d ' {"mappings": { "log": { "properties": { "geo": { "properties": { "coordinates": { "type": "geo_point" } } } } } } }';
- 导入数据:
-
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl
3、查看是否导入成功:
-
curl 'localhost:9200/_cat/indices?v'

三、ES-head集群管理:
1、分布式环境中只需选取一个节点启动ES-head,无论是不是Master节点,都能连接到整个集群,这里选取node-1(192.168.230.150)导入。导入之后重新访问192.168.230.150:9100查看head界面可得到如下:
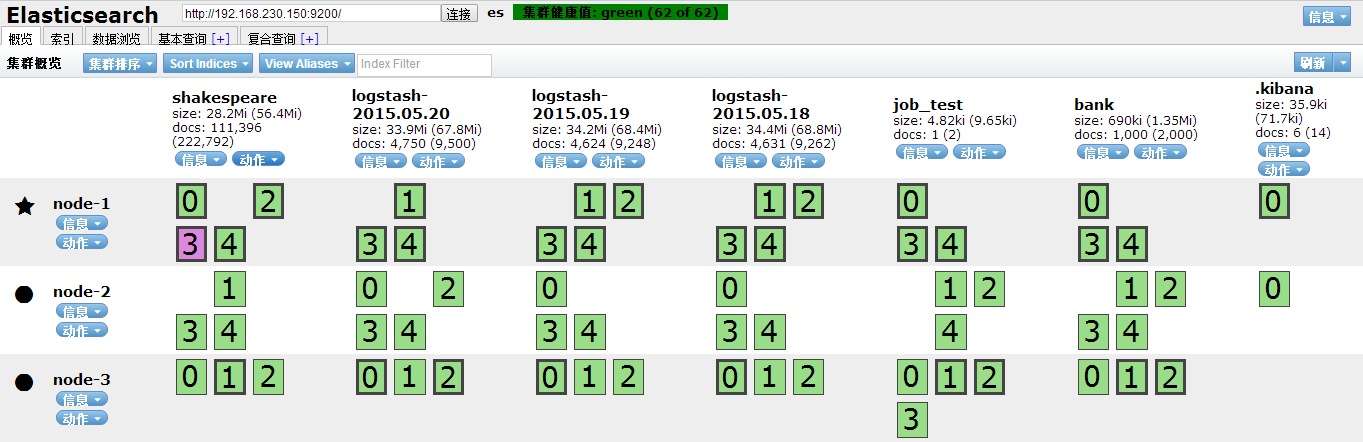
2、所有数据导入后会分片存储在不同的节点上,默认是5个分片,一个副本。每一个分片的副本都不会和本体存在一个节点上从而保证一个节点数据丢失可已得到恢复。我们可以修改连接的节点:结果同上,说明无论连接哪个节点都能获取集群的信息。


3、关闭其中一个节点(这里关闭node-1,master节点看看会出现什么结果)

我们发现集群健康值由green变为了yellow,重新选举了node-3为主节点Master。我们重新启动node-1查看:
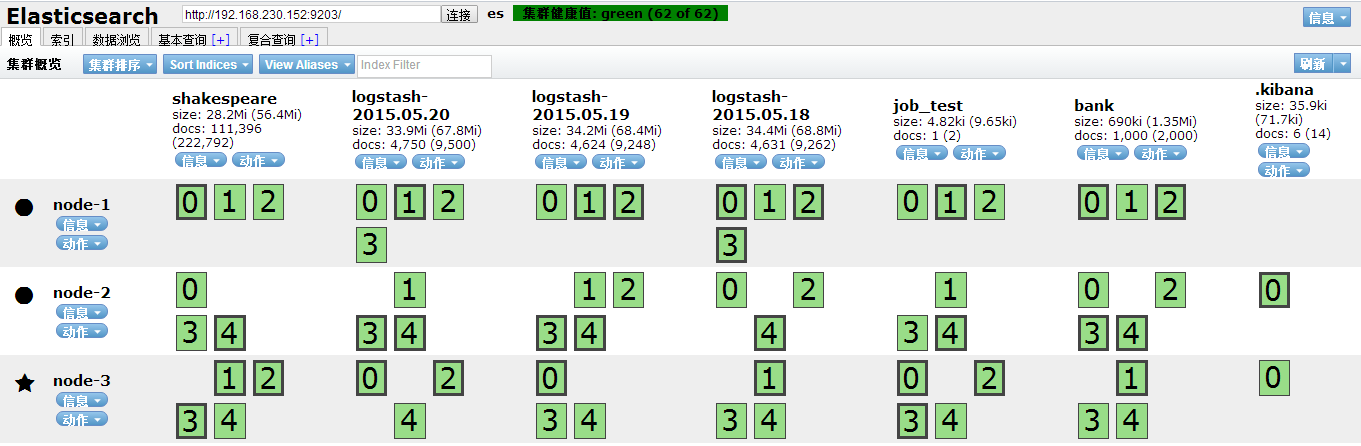
node-1节点恢复了,所存储的数据分片也恢复了,node-3仍是Master。
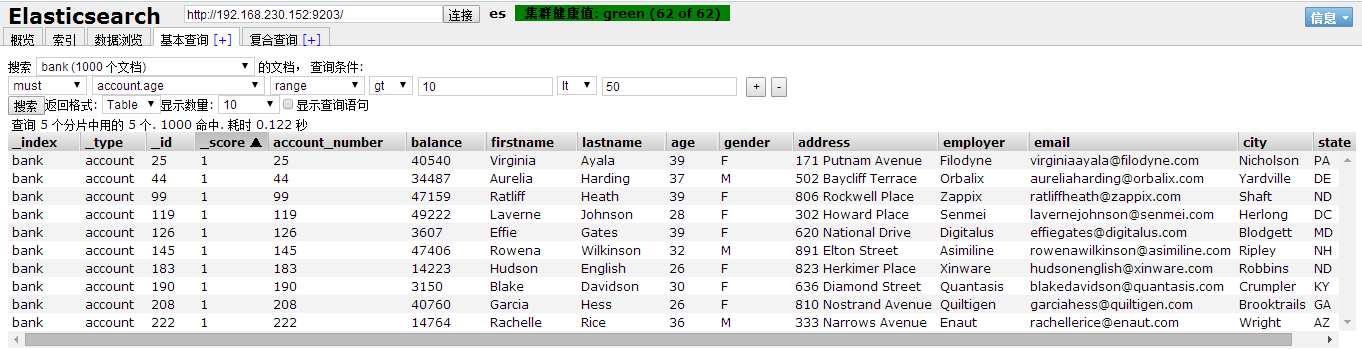
4、ES-head做一个简单的查询示例:
ES-head可以清楚的查看集群的各种信息,节点,索引,数据。这里简单示例一个查询,具体功能后面在探索。查询type为account的数据条件是年龄范围在10-50之间。
四、Kibana功能组件:
1、开启Kibana,访问5601端口:http://ip:5601 创建Index pattern :ba*,log*,sh*(Management->Index Patterns->add New->取消所有选项->Create)

2、Discover数据查询展示:根据条件过滤选择要展示的字段右侧点击add,点开数据详情可以选择table和json两种格式展示。

3、Visualize可视化:多种可选择图形可视化。
- 可选图形有:饼状图,折线图,条形图,坐标图。。。等。

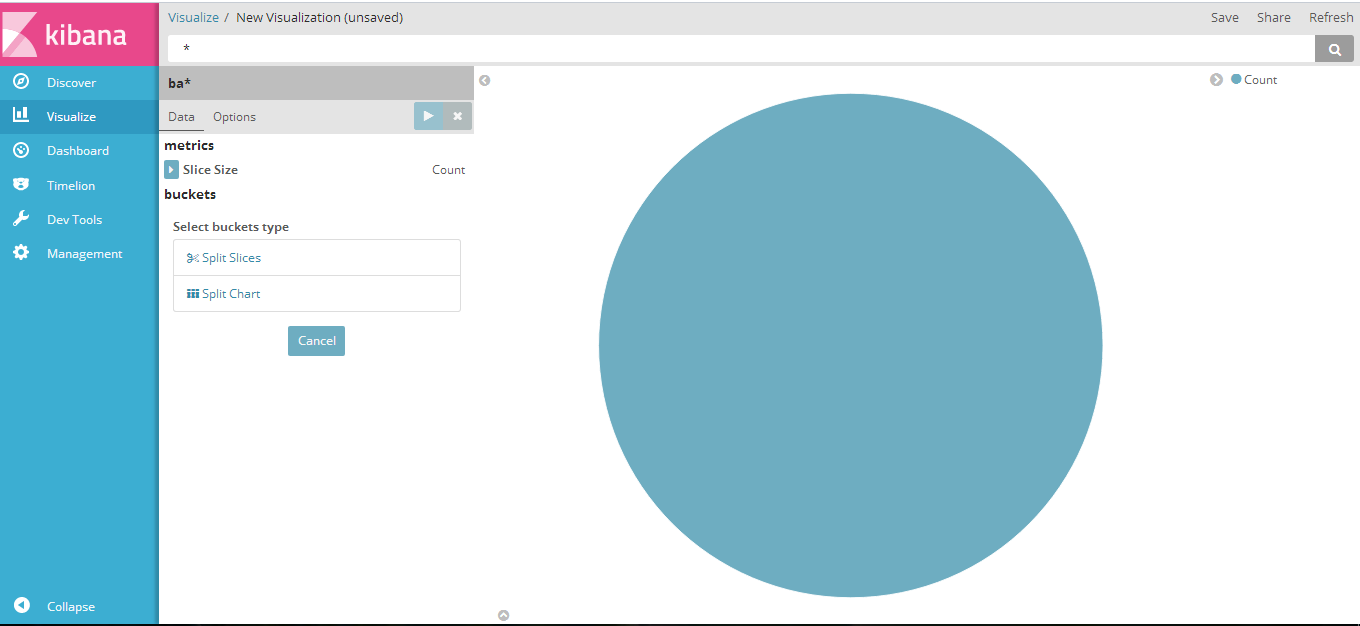
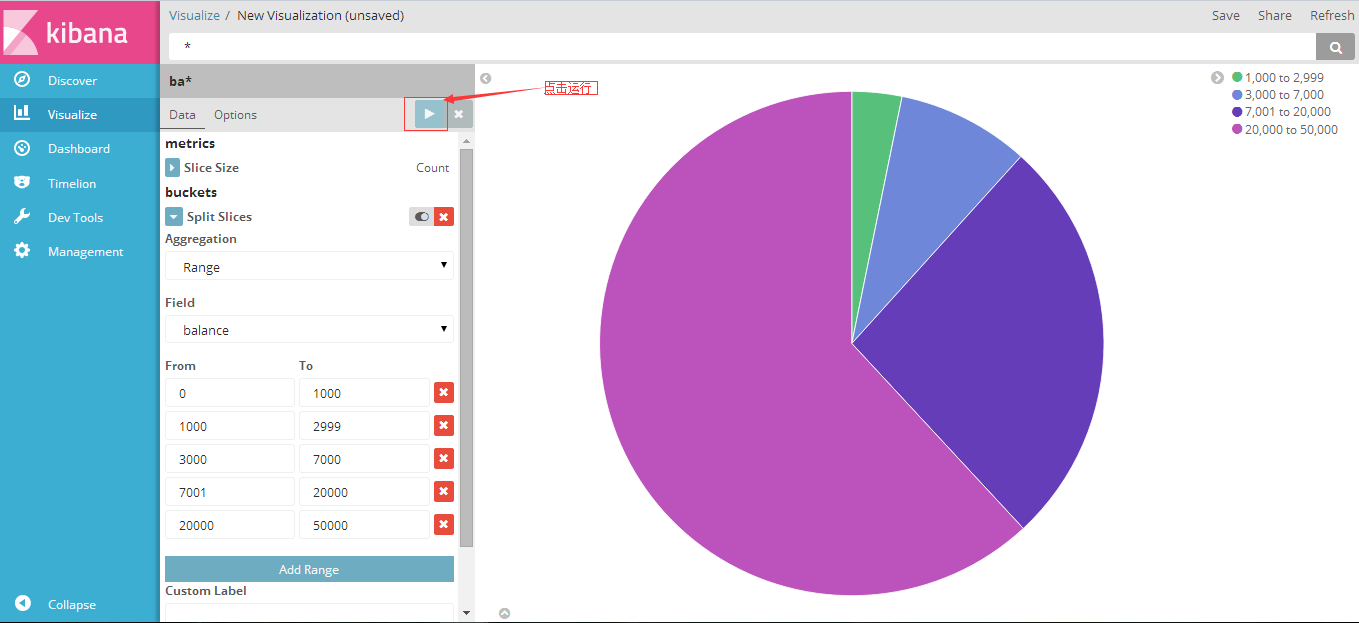
- 下面根据示例创建一个饼状图:(Visualizer->Create a Visualizer->pie chart->From a New Search, Select Index选择ba*)得到下图:
-
选择过滤条件和聚合函数:(buckets:Split Slices->Aggregation->Range->Field->balance-add Range选择数据的范围 )
-
在此基础上再添加条件:(Add sub-buckets->Split Slices->aggregation ->Terms ->field ->age ->Apply changes运行):
-

-
点击右上角的save保存为pie-ba-example.
- 创建条形图:参考官方文档https://www.elastic.co/guide/en/kibana/current/tutorial-visualizing.html得到结果如下:

- 保存为log-Vertical-example。
- 创建坐标图:参考官方文档https://www.elastic.co/guide/en/kibana/current/tutorial-visualizing.html得到结果如下:
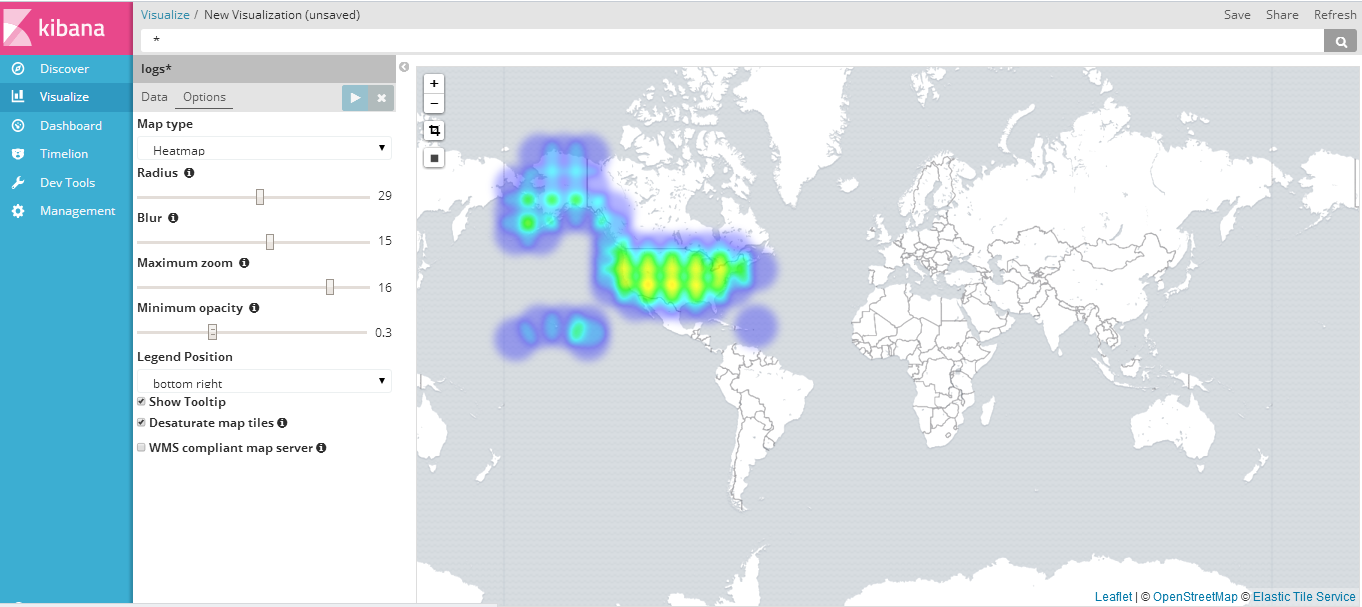
- 保存为log-map-example
4、dashboard:仪表盘,进行多图组合展示。
- dashboard->create a dashboard->add,然后根据过滤条件选择我们需要的图点击图选择,可将多图放在一起展示。将上几步做的进行展示如下:

- 保存为dashboard-example。
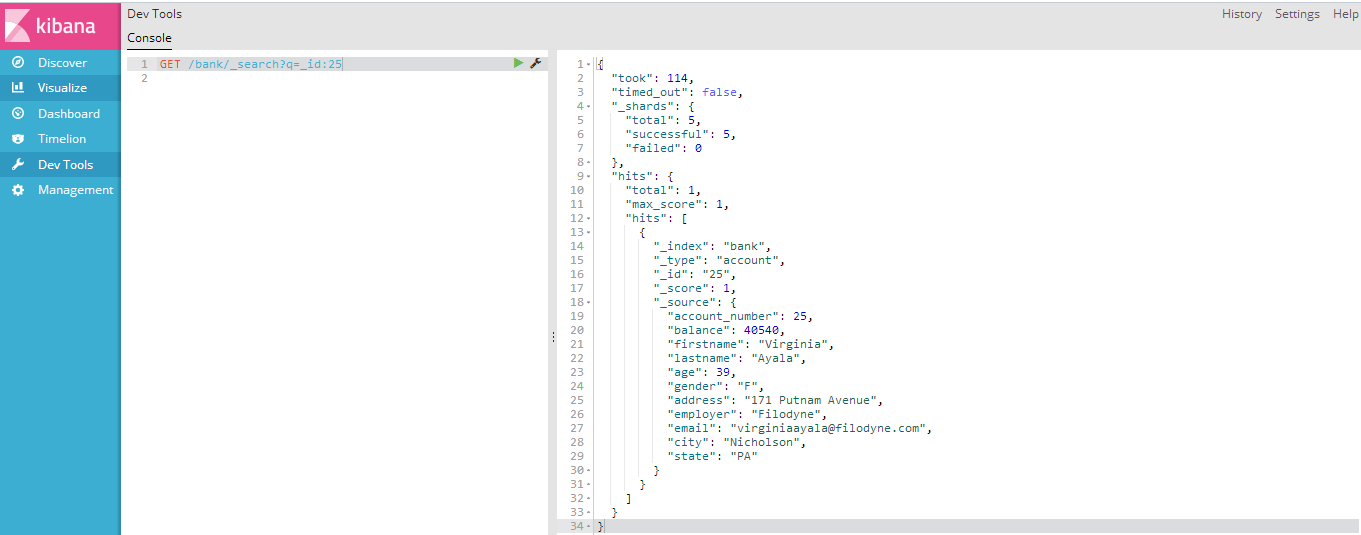
5、Dev Tools:控制台,可以发送http请求,用Curl可以做的请求,在这里都可以做。只要能和ES的REST API对接,都可以在这里做。
- GET:
-
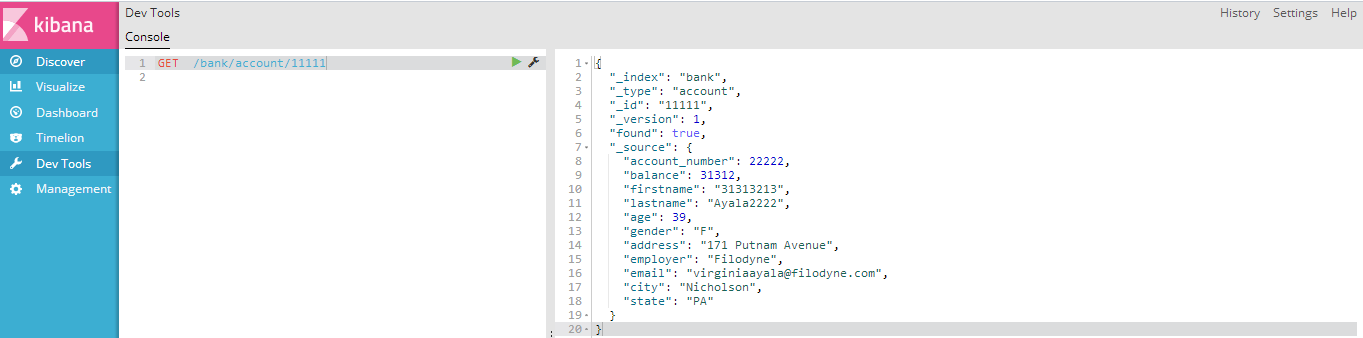
PUT:
-

-
-
DELETE:
-

6、Management:管理Index Pattern,Object (创建保存的图像),系统的一些配置文件可以进行编辑,略过(暂时还没有细细研究)。
到这里,EK的安装和使用的基本介绍就完了。
注意:
我们在DB中创建数据库的时候是先配置schema在填写数据库的名字然后保存,这样一个数据库就建好了,这里在创建Mapping的时候其中就包含index的命名。其中Json参数包含type也就是表名,以及字段的定义。
Kibana主要做可视化展示,需要将可视化的组件多熟悉,了解过滤条件和聚合函数如此才能和业务结合。
❤如果这篇文章对你有一点点的帮助请给一份推荐! 谢谢!你们的鼓励是我继续前进的动力。更多内容欢迎访问我的个人博客
❤本博客只适用于研究学习为目的,大多为学习笔记,如有错误欢迎指正,如有误导概不负责(本人尽力保证90%的验证和10%的猜想)。

