
简单通用线程池的实现
通用线程池的一般实现思路如下
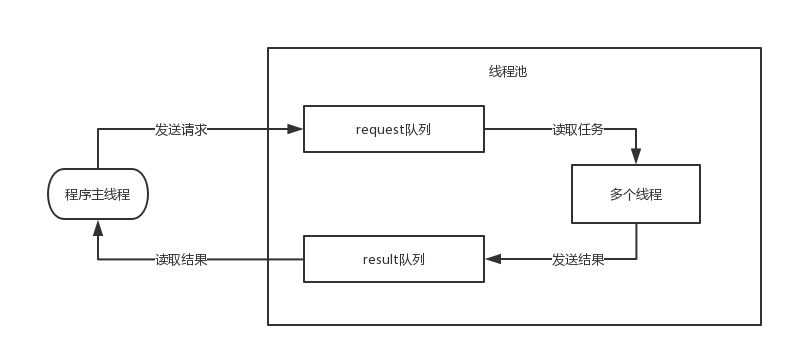
一个简单通用的线程池应该满足以下条件
<1> 线程数可配置,可动态调整。任务队列的大小可配置。这一点是为了让代码更好地适应运用场景。比如这份代码在机器配置非常好,而且机器上几乎没有其他的业务争抢硬件资源,那么提高线程数,提高任务队列的大小可以增加程序的响应速度和吞吐量。反之可以适当地减小二者的大小。
<2> 任务通用,不局限于特定的处理函数。任务队列中每个任务设计为不同的业务逻辑函数和需要用到的参数的结构体,线程拿到任务后直接给逻辑函数传入参数并执行。而不应该把每个任务设计成一份份单独的数据,把业务逻辑实现在线程本身中。否则,换个业务场景改代码是在所难免的。
实例:使用python实现这样一个线程池
这里使用python举例是因为python比较简单明了,并且笔者接触的代码中有现成的实现。其次关于python的多线程,虽然是在GIL全局解释器锁下实现的,无法利用多核cpu的优势,python的一个进程中所有的线程都会运行在一个cpu上,但是python的多线程并非在所有业务场景下都是不可取的。如果你的业务代码是多线程计算密集型的,业务代码编写本身复杂就不说了,而且加上线程切换和锁的开销,效率不一定会比python单线程高。这个时候python的多线程就不可取。但是如果你业务代码中是计算和IO混合或者纯IO,那么使用python多线程就可以提高程序的运行速度和吞吐量。虽然线程都在一个cpu上运行,但是大部分时间都在等待嘛。所以是否使用python的多线程还是要结合业务场景的。
request_task的设计:
class work_request:
def __init__(self, callable, args=None, kwargs=None, request_id=None, callback=None, exc_callback=None):
pass
- callable, 就是task的逻辑代码。因为python中函数也是对象,所以可以直接当一个变量赋值给callable。
- args和kwargs,利用了python中的动态参数机制。callable的定义为了尽可能的通用,会定义为如下形式:
def callable(*args, **kwargs):
pass
当线程拿到task后,就可以直接调用,callable(*task.args, **task.kwargs)。
- request_id, 可以做故障恢复或者返回给发送请求方做进一步逻辑处理。
- callback和exc_callback, 回调函数和出现异常后的回调函数。比如我的task如果处理成功,会在mysql表中根据request_id打一个成功标记。而如果处理过程中发生异常,则在mysql表中打一个失败标记。这两个逻辑就可以做在callback和exc_callback中。callback和exc_callback的函数定义,为了能在callback中获得task的信息,二者应该定义为以下形式:
def callback(request, result)
def ext_callback(request, exc_info)
request_task中还有一个成员是exception,当执行callable出现异常后,会把exception成员设置为True。作用后面会讲到。
线程池中每个线程的设计:
如果业务逻辑实现在task中,那么每个线程的逻辑就很简单了。从request队列中拿到task,调用其中的callable。如果执行成功,把结果放入result队列中。如果执行失败,把task中exception成员设置为True,放入result队列。使用线程池的线程应该负责把任务执行结果从result队列中取出。判断request_task中的exception成员的状态。如果exception为True,那么说明执行过程中出现了异常,调用exc_callback。否则执行callback。
request和result队列的设计:
队列的大小应该可以配置。而且对于put和get应该提供阻塞式接口和非阻塞式接口。并且对于阻塞式接口应该有timeout机制。这样才能适应不同的业务逻辑。
这个在python中已经有现成的实现,Queue.Queue。这是python标准库中实现的线程安全的FIFO。
这里有个坑需要提一下,如果设置了队列大小,同时put和get用的是阻塞式接口,那么可能会形成死锁。比如request队列满了,result队列也满了。那么线程池中的线程可能会阻塞在result队列的put接口上。这时候如果使用线程池的线程把put request和get result实现在一块,那么向request队列put任务的时候因为request队列已满,会发生阻塞,不能去消费result队列中的东西。这时整个程序就卡死在这里了。解决办法就是要么使用非阻塞接口,处理Full异常。要么使用阻塞+timeout的形式。
ThreadPool设计
包括最基本的结构,比如维护各个线程的列表,request_id和对应request的hash表,request_task队列,result队列。
最基本对外的接口,createWorkers,dismissWorkers,joinDismissedWorkers,putRequest。

