我的正则表达式学习记录
2011-09-02 19:51 音乐让我说 阅读(302) 评论(0) 编辑 收藏 举报在线正则表达式测试网站:https://regex101.com/
工具 RegexTester 下载:https://files.cnblogs.com/Music/RegexTester.zip
1>
“.”可以匹配任意的 单个 字符、英文字母、数字、特殊字符(比如:%、$、#等等)、空格,以及它本身。
NOTE:很多情况下,“.”不匹配换行。但在RegexTester这个工具中,它匹配换行, 所以,这里有个值得注意的匹配,就是 回车符+exp,我在上面的代码中用绿色粗体标识出了(回车符难以标识)。
2>
[td] 表示匹配单个t字符,或者是单个d字符。
3>
[0-9] 可以匹配单个0到9之间的数字。 起始字符 和 结束字符,依据的是它的 ASCⅡ值的大小, 即是说,将会匹配其ASCⅡ码位于 起始字符 和 结束字符 的ASCⅡ之间的所有字符(包含起始、结束字符)。
4>
[^0-9a-z] 匹配单个字符既不是0到9之间的数字,也不是a到z之间的英文字母。
5>
\d 所有单个数字,与 [0-9] 相同
\D 所有非数字,与 [^0-9] 相同
\w 所有单个大小写字母、数字、下划线,还有汉字,与 [a-zA-Z0-9_] 相同
\W 所有单个非大小写字母、非数字、非下划线,与 [^a-zA-Z0-9_] 相同
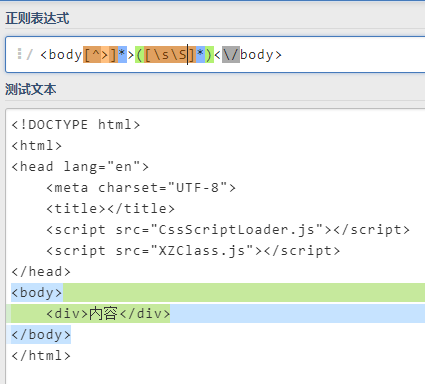
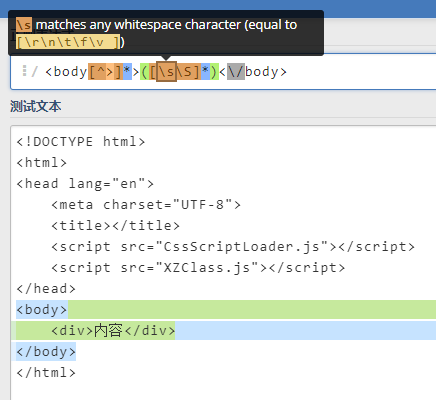
\s 所有单个空字符,与 [\f\n\r\t\v] 相同
\S 所有单个非空字符,与 [^\f\n\r\t\v] 相同。
比如下图:
////////////////////分割线////////////////////
////////////////////分割线////////////////////
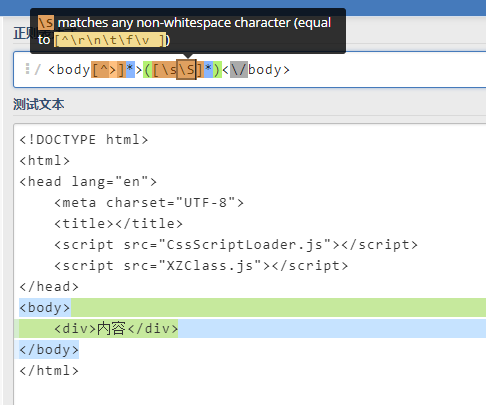
Regex:<body[^>]*>([\s\S]*?)<\/body>
Replace:<html>$1</html>
////////////////////分割线////////////////////
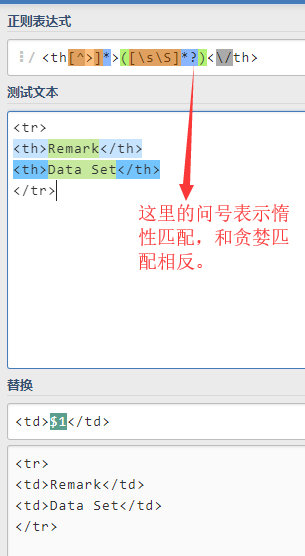
其中小写的 \s 表示 \r\n 等符号,也就是匹配换行符。大写的 \S 表示 非 \r\n 等符号,也就是非换行符。
Regex:<th[^>]*>([\s\S]*?)<\/th>
Replace:<td>$1</td>
////////////////////分割线////////////////////
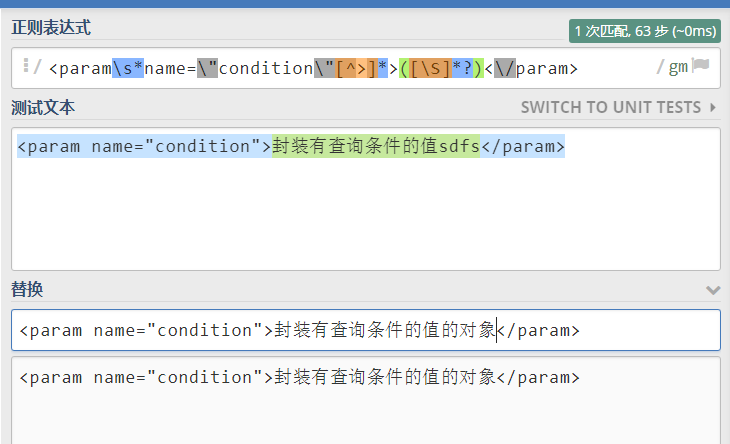
Regex:<param\s*name=\"condition\"[^>]*>([\S]*?)<\/param>
Replace:<param name="condition">封装有查询条件的值的对象</param>
6>
匹配一个或多个,用'+'
j+ 匹配一个或多个j
[abc]+ 可以匹配中括号内,一个或多个的组合
\d+ 匹配一个或多个数字
.+ 匹配任意多个字符
匹配零个或多个,用 '*'
j* 匹配零个或多个j
[abc]* 可以匹配中括号内,一个或多个的组合
\d* 匹配零个或多个数字
.* 匹配任意多个字符
匹配零个或一个,用'?'
flowers? 可以匹配flower、flowers
7>
匹配固定数目的字符,用'{数字}'
例如:使用“\d{3}”,可以匹配从 000 到 999,这1000(10*10*10=1000)个数。 而使用“a{6}”,则可以匹配“aaaaaa”(也只能匹配它,因为“a”是固定字符)。
8>
匹配区间以内数目的字符,用'{最小数目,最大数目}'
Text : 0、10、111、001、789、1234 are all matched numbers. 0d、0h、1xx、99. are not matched.
Regex: \d{1,3}
Result :
0、10、111、001、789、1234
注意:它匹配了1234,是因为是作为123和4两个匹配的结果
特例:
最小数目可以是0,所以 “{0,1}”,相当于 “?”。 如果不限制最大数目,可以将最大数目设为空,所以“\d{1,}”相当于“+”;而“{0,}”相当于“*”。
9>
贪婪匹配 惰性匹配 匹配描述 ? ?? 匹配0个或1个 + +? 匹配1个或多个 * *? 匹配0个或多个 {n} {n}? 匹配n个 {n,m} {n,m}? 匹配n个或m个 {n,} {n,}? 匹配n个或多个
注意 {n} 与 {n}? 是一样的,因为{n}已经限制了匹配n个字符,所以无所谓的贪婪还是惰性
10>
在 字符 前加“\b”,来匹配其 后面 的字符位于字符串首位的字符。
Text The cat s cattered its food all over the room. RegEx \bcat Result cat
在 字符 后加“\b”,来匹配其 前面 的字符位于字符串末位的字符。
Text The cat s cattered its food all over the room. RegEx cat\b Result cat
所以为了不匹配是不完整的cat ,需要这样写正则表达式:\bcat\b
\B 用来匹配不在边界的字符。
11>
^ 是匹配文本首的结果,而 $ 是匹配文本末的结果,用法与 ^ 相同
Text city.jpg、city1.jpg are all beautiful pictures except city9.jpg RegEx ^city\d?\.jpg (即在city\d?\.jpg中搜索位于文本首的结果,如果找到就删除其他的匹配结果) Result city.jpg
12>
\s 匹配一个空格
\s* 匹配零个或多个空格
13>
匹配子模式:在正则表达式中,可以使用“(”和“)”将模式中的子字符串括起来,以形成一个子模式。 将子模式视为一个整体时,那么它就相当于一个单个字符。
Text
This is the first line.<br><br /> This is the second line.<br><br/><br /> This is the third line.<br>>>>>
Regex
(<br\s*/?>){2,}
Result <br><br /> <br><br/><br />
在正则表达式中,可以使用“|”将一个表达式拆分成两部分“reg1|reg2”, 它的意思是:匹配所有符合表达式reg1的文本 或者 符合表达式reg2的文本。
Text
The <b>text of</b> this row is bold. The <i>text of</i> this row is italic.
Regex
</?i>|</?b>
Result <b> </b> <i> </i>
14>断言:用来声明一个应该为真的事实。正则表达式中只有当断言为真时才会继续进行匹配。
No.1 - 匹配以ing结尾的单词的前面部分(除了ing以外的部分)
Regex: \b\w+(?=ing\b)
Source: I'm singing while you're dancing
Result: sing danc
No.2 - 匹配以re开头的单词的后半部分(除了re以外的部分)
Regex: (?<=\bre)\w+\b
Source: reading a book
Result: ading
No.3 - 匹配两边都有空格的数字(仅仅匹配除了空格以外的数字)
Regex: (?<=\s)\d+(?=\s)
Source: 1 22 333 444 555 666
Result: 分别为 new Group[] { "22", "333", "444", "555" }
\d{3}(?!\d)
断言非:表示不能出现什么规则
No.4 - 匹配三位数字,而且这三位数字的后面不能是数字;
Regex: \d{3}(?!\d)
Source: 1 22 333 4444 55555 666666 777,777 8888.888 99999*9999
Result: 省略
No.5 - 匹配不包含属性的简单HTML标签内里的内容
Regex: (?<=<(\w+)>).*(?=<\/\1>)
Source:
<span>群莺乱飞<b>吴</b></span> <span >Hello World</span> <span>你嘴上有残留物</span> <span id="message">保存成功</span>
Result: 分别为 new Group[] { "群莺乱飞<b>吴</b>", "你嘴上有残留物" }
No.6 - 非获取匹配,即不保存结果到 Group 中。
Regex: (?:ing|es|ies)
Source: hello word doing happies does
Result: ing es ies
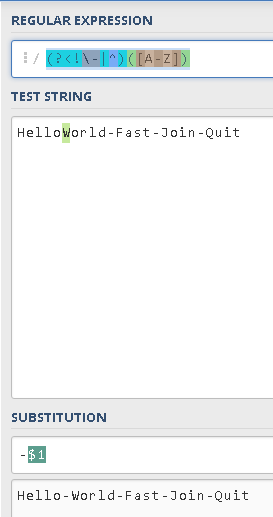
No.7 - 匹配前面不包含"杆"字符,也不是开头(即:第一个字母)的大写字母
Regex:(?<!\-|^)([A-Z])
备注:比如核心是 (?<!\-|\#)(A-Z) 这个正则匹配 大写字母前 既不是 “杆”字符,也不是 “井号” 字符的 大写字母
Source:HelloWorld-Fast-Join-Quit
Replace Regex:-$1
Result: -Hello-World-Fast-Join-Quit
15> 替换从网上复制的代码中前面的序号:
用 Editplus 的替换功能(貌似 Editplus 不支持 \d 语法)

16> 查找包含在双引号中的中文
"[^>]*?[\u4e00-\u9fa5][^>]*?"
比如:
Text: abc类似的"def 王五gHi "上上网"是"
Result:
结果1:"def 王五gHi "
结果2:"是"
17> 油管播放列表替换
替换前:1080p\s*\-\s*\d+
替换后:1080p
替换前:(\d{4}-\d{2}-\d{2})(.*?) - 1080p
替换后:$1 (1080p)$2
谢谢浏览!
作者:音乐让我说(音乐让我说 - 博客园)
出处:http://music.cnblogs.com/
文章版权归本人所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
