课程回顾-Structuring Machine Learning Projects
正交化 Orthogonalization
单一评价指标
保证训练、验证、测试的数据分布一致
不同的错误
错误分析
数据分布不一致
迁移学习 transfer learning
多任务学习 Multi-task learning
端到端的深度学习系统
好处
坏处
Reference
单一评价指标
保证训练、验证、测试的数据分布一致
不同的错误
错误分析
数据分布不一致
迁移学习 transfer learning
多任务学习 Multi-task learning
端到端的深度学习系统
好处
坏处
Reference
这门课不是具体的技术,而是帮助你决定现在最有价值做的应该是什么
正交化 Orthogonalization

简单的说就是有些调整是不相互影响的,所以可以分开做
单一评价指标
一般来说有一个单一数值作为评价指标会更好
如果存在多个指标,一般可以优化一个,其他几个满足一定条件就好
除了通用的一些指标,我们可以通过给样本加权的方式,使得获得更加适合我们应用的评价指标
保证训练、验证、测试的数据分布一致
不同的错误
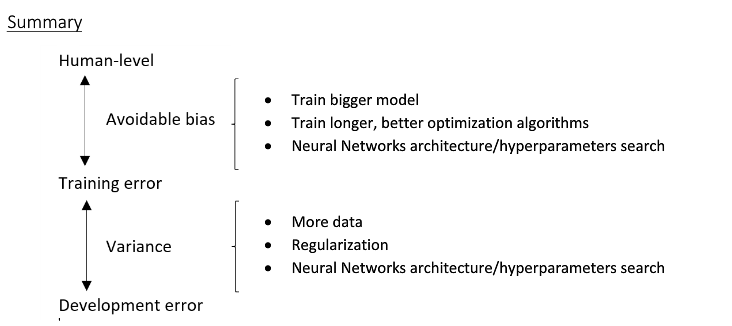
- 任务的理论上限: bayes optimal error
- 人类的水平: human error
假设一个图像识别的任务
| Humans | 1% | 7.5% |
|---|---|---|
| Training error | 8% | 8% |
| Dev Error | 10% | 10% |
- 左边的例子,如果人类的错误率是1%,那么我们应该关注的是bias
- 右边的例子,如果说人类错误率是7.5%,那么我们应该关注的是variance
- 在这个例子中我们能够用人类错误率来代替理论上限是因为人类在图像识别的任务上做的非常好
错误分析
可以通过手动随机抽样分析一些数据,看哪类的数据它出错最多,从而做针对性改进。
也可以分析一些他分对的业务和没对的业务,从而得到他的不足
数据分布不一致
数据分布不一致会导致上面的分析存在问题,所以这时候需要引入类似train-dev机制来实现
迁移学习 transfer learning
典型的就是fine-tunning
多任务学习 Multi-task learning
同时做多个任务,并且这多个任务可以互相帮助
端到端的深度学习系统
好处
- 充分利用数据
- 设计简单
坏处
- 需要更多数据
- 无法利用手工设计的有效特征(在小数据的情况下他们可能是很有效的)
Reference
https://github.com/mbadry1/DeepLearning.ai-Summary


