Oracle 去重查询
Oracle 去重查询
CreateTime--2018年2月28日15:38:45
Author:Marydon
(一)使用distinct
--查询指定区间内表停诊字段的值 SELECT DISTINCT T.CLOSE_TZ FROM CONSULT_SCHEDULE T WHERE T.SCHEDULE_DATE BETWEEN TO_DATE('2018-01-01', 'yyyy-MM-dd') AND TO_DATE('2018-02-28', 'yyyy-MM-dd');
说明:
使用distinct关键字,后面跟一个字段,则只对该字段的值进行去重;
后面跟2个字段,则表示column1+column2两个字段不完全一致进行去重。
(二)对指定字段去重后,再查出该行数据的其他字段信息
UpdateTime--2017年7月10日10:54:20
1.2.5 对某字段进行去重后,根据这个字段查出在表中所对应的记录
实例1: 查询指定医院对应科室下属的医生(需要去重)
查询结果字段:医生id,医生姓名,医疗机构id,科室id
sql1:没有根据医生id进行去重,只查出了所需字段
--查询排班表中字段:医生ID,医生姓名,医疗机构ID,科室ID SELECT T.DOCTOR_ID AS FDOCTORCODE, T.DOCTOR_NAME AS FDOCTORNAME, T.DOCTOR_PHONE AS FDOCTORPHONE, T.ORG_ID AS FORGID, T.DEPENT_ID AS FDEPTCODE FROM CONSULT_SCHEDULE T WHERE ORG_ID = '416211338' AND DEPENT_ID = '1004'
查询结果:有很多重复记录
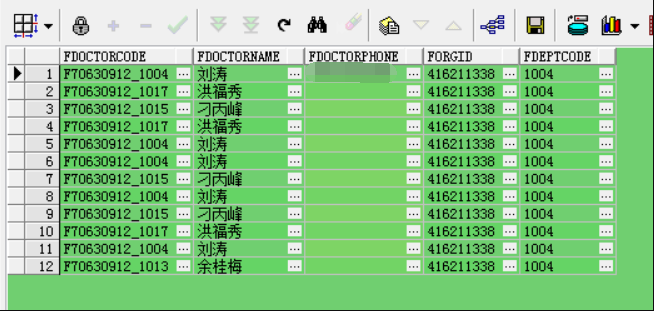
sql2:根据医生id进行去重,没有查出所需字段
--实现效果:根据已知条件对医生id进行去重查询 --查询条件:医疗机构id和科室id --对查询结果进行分组 --查询字段:rowid和计数 --查询结果:查出每组排班信息中取最大的rowid SELECT MAX(ROWID),COUNT(1) FROM CONSULT_SCHEDULE WHERE ORG_ID = '416211338' AND DEPENT_ID = '1004' GROUP BY DOCTOR_ID
查询结果: 按医生id进行分组后,取每组记录中最大的rowid
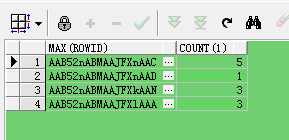
sql3:完美实现
--根据条件(指定医疗机构,指定科室)对医生信息进行去重并查询出指定字段(医生id,医生名称,医生电话,机构id,科室id) SELECT T.DOCTOR_ID AS FDOCTORCODE, T.DOCTOR_NAME AS FDOCTORNAME, T.DOCTOR_PHONE AS FDOCTORPHONE, T.ORG_ID AS FORGID, T.DEPENT_ID AS FDEPTCODE FROM CONSULT_SCHEDULE T WHERE T.ROWID IN (SELECT MAX(ROWID) FROM CONSULT_SCHEDULE WHERE ORG_ID = '416211338' AND DEPENT_ID = '1004' GROUP BY DOCTOR_ID)
sql4:完美实现
SELECT T.DOCTOR_ID AS FDOCTORCODE, T.DOCTOR_NAME AS FDOCTORNAME, T.DOCTOR_PHONE AS FDOCTORPHONE, T.ORG_ID AS FORGID, T.DEPENT_ID AS FDEPTCODE FROM CONSULT_SCHEDULE T, (SELECT MAX(ROWID) ROWID2 FROM CONSULT_SCHEDULE WHERE ORG_ID = '416211338' AND DEPENT_ID = '1004' GROUP BY DOCTOR_ID) T2 WHERE T.ROWID = T2.ROWID2
sql5:推荐使用
SELECT T.DOCTOR_ID AS FDOCTORCODE, max(T.DOCTOR_NAME) AS FDOCTORNAME, max(T.DOCTOR_PHONE) AS FDOCTORPHONE, max(T.ORG_ID) AS FORGID, max(T.DEPENT_ID) AS FDEPTCODE FROM CONSULT_SCHEDULE T WHERE ORG_ID = '134557' AND DEPENT_ID = '1004' GROUP BY DOCTOR_ID
查询结果:

错误实现方式一:
使用distinct实现
--错误方式一 SELECT DISTINCT T.DOCTOR_ID AS FDOCTORCODE, T.DOCTOR_NAME AS FDOCTORNAME, T.DOCTOR_PHONE AS FDOCTORPHONE, T.ORG_ID AS FORGID, T.DEPENT_ID AS FDEPTCODE FROM CONSULT_SCHEDULE T WHERE T.ORG_ID = '416211338' AND T.DEPENT_ID = '1004'
错误结果:
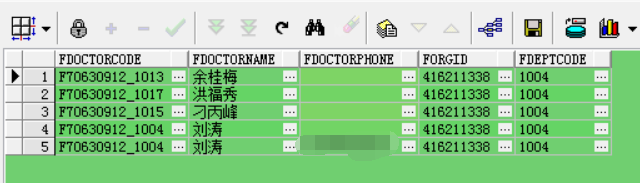
错在哪:
distinct的用法是:
a.distinct + 单个字段,表示对该字段进行去重处理;
b.distinct + column1,column2,。。。,表示的是使用n个字段进行联合去重,即查出来的是这n个字段的值相加结果不一致的数据;
而不是:对第一个字段做去重处理后,再将其他字段查询出来。
错误实现方式二
--错误方式二 SELECT T.DOCTOR_ID AS FDOCTORCODE, T.DOCTOR_NAME AS FDOCTORNAME, T.DOCTOR_PHONE AS FDOCTORPHONE, T.ORG_ID AS FORGID, T.DEPENT_ID AS FDEPTCODE FROM CONSULT_SCHEDULE T WHERE T.DOCTOR_ID IN (SELECT DISTINCT T2.DOCTOR_ID FROM CONSULT_SCHEDULE T2 WHERE T2.ORG_ID = '416211338' AND T2.DEPENT_ID = '1004')
错误结果:
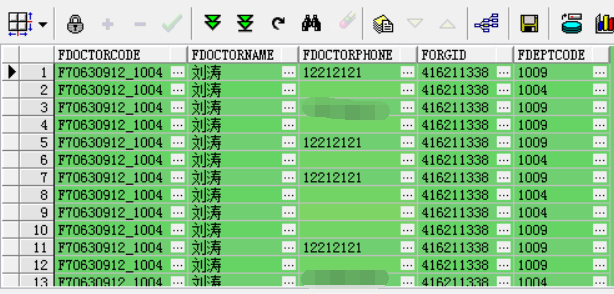
错在哪:
先用distinct虽然查出来的医生id具有唯一性,但是, 根据这个唯一的医生id结果集去查询其他字段数据的结果无法保证数据的唯一性
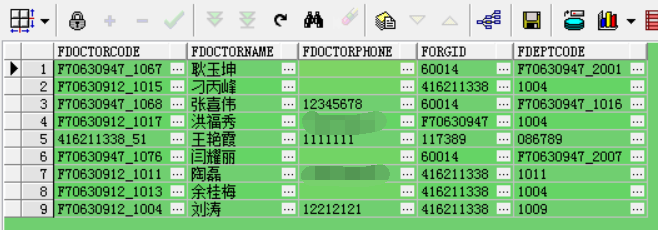
实例2:查CONSULT_SCHEDULE表中字段:医生id,姓名,医疗机构id,科室id并根据医生id去重
sql实现:
SELECT T.DOCTOR_ID AS FDOCTORCODE, T.DOCTOR_NAME AS FDOCTORNAME, T.DOCTOR_PHONE AS FDOCTORPHONE, T.ORG_ID AS FORGID, T.DEPENT_ID AS FDEPTCODE FROM CONSULT_SCHEDULE T, (SELECT MAX(ROWID) ROWID2 FROM CONSULT_SCHEDULE GROUP BY DOCTOR_ID) T2 WHERE T.ROWID = T2.ROWID2
查询结果:
本文来自博客园,作者:Marydon,转载请注明原文链接:https://www.cnblogs.com/Marydon20170307/p/8483992.html

