

Machine Learning for hackers读书笔记(三)分类:垃圾邮件过滤
#定义函数,打开每一个文件,找到空行,将空行后的文本返回为一个字符串向量,该向量只有一个元素,就是空行之后的所有文本拼接之后的字符串
#很多邮件都包含了非ASCII字符,因此设为latin1就可以读取非ASCII字符
#readLines,读取每一行作为一个元素
#异常捕获是自己加的,书上没有,不加会出错,因为有些邮件没有空行
get.msg <- function(path)
{
con <- file(path, open = "rt",encoding='latin1')
text <- readLines(con)
# The message always begins after the first full line break
msg <- tryCatch(text[seq(which(text == "")[1] + 1, length(text),1)],error=function(e) return(NA))
close(con)
return(paste(msg, collapse = "\n"))
}
#dir读取目录下所有文件
spam.docs<-dir(spam.path)
#去掉目录下的cmds文件
spam.docs<-spam.docs[which(spam.docs!='cmds')]
#利用get.msg函数,读取每个邮件空行后的全部内容并形成文本向量
all.spam<-sapply(spam.docs,function(p) get.msg(paste(spam.path,p,sep='')))
#定义函数get.tdm,输入邮件文本向量,输出词项文档矩阵
#control设定如何提取文件,stopwords表示移除停用词,removePunctuation移除标点,removeNumbers移除数字,minDocFreq=2表示矩阵只包含词频>=2的词
get.tdm <- function(doc.vec)
{
control <- list(stopwords = TRUE,
removePunctuation = TRUE,
removeNumbers = TRUE,
minDocFreq = 2)
doc.corpus <- Corpus(VectorSource(doc.vec))
doc.dtm <- TermDocumentMatrix(doc.corpus, control)
return(doc.dtm)
}
#调用
spam.tdm<-get.tdm(all.spam)
#转矩阵,行为词项,列是文档
spam.matrix<-as.matrix(spam.tdm)
#rowSums创建向量,表示每个词在文档集中的频率
spam.counts<-rowSums(spam.matrix)
spam.df<-data.frame(cbind(names(spam.counts),as.numeric(spam.counts)),stringsAsFactors=FALSE)
names(spam.df)<-c('terms','frequency')
spam.df$frequency<-as.numeric(spam.df$frequency)
#通过sapply将每一行的行号传入一个无名函数,该函数统计该行中值为正数的元素个数,然后除以TDM中列的总数(垃圾邮件语料库中的文档总数),即文档频率/文档总数
spam.occurrence<-sapply(1:nrow(spam.matrix),function(i) {length(which(spam.matrix[i,]>0))/ncol(spam.matrix)})
#统计整个语料库中每个词项的频次,词频/词频总和
spam.density<-spam.df$frequency/sum(spam.df$frequency)
spam.df<-transform(spam.df,density=spam.density,occurrence=spam.occurrence)
#看看情况,截图与书上并不一致
head(spam.df[with(spam.df,order(-occurrence)),])
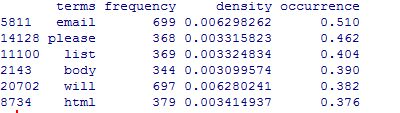
#接下来构造正常邮件的,跟垃圾邮件一样,但要注意限制在500封,因为垃圾邮件也只有500封
easyham.path<-'data\\easy_ham\\'
easyham.docs<-dir(easyham.path)
easyham.docs<-easyham.docs[which(easyham.docs!='cmds')]
easyham.docs<-easyham.docs[1:500]
all.easyham<-sapply(easyham.docs,function(p) get.msg(paste(easyham.path,p,sep='')))
get.tdm <- function(doc.vec)
{
control <- list(stopwords = TRUE,
removePunctuation = TRUE,
removeNumbers = TRUE,
minDocFreq = 2)
doc.corpus <- Corpus(VectorSource(doc.vec))
doc.dtm <- TermDocumentMatrix(doc.corpus, control)
return(doc.dtm)
}
easyham.tdm<-get.tdm(all.easyham)
easyham.matrix<-as.matrix(easyham.tdm)
easyham.counts<-rowSums(easyham.matrix)
easyham.df<-data.frame(cbind(names(easyham.counts),as.numeric(easyham.counts)),stringsAsFactors=FALSE)
names(easyham.df)<-c('terms','frequency')
easyham.df$frequency<-as.numeric(easyham.df$frequency)
easyham.occurrence<-sapply(1:nrow(easyham.matrix),function(i) {length(which(easyham.matrix[i,]>0))/ncol(easyham.matrix)})
easyham.density<-easyham.df$frequency/sum(easyham.df$frequency)
easyham.df<-transform(easyham.df,density=easyham.density,occurrence=easyham.occurrence)
#接下来定义分类器,目的是给出一封邮件,用分类器来判定是正常邮件还是垃圾邮件
#新邮件中有些词已经在分类器中,但有些词不在分类器中,此时将未出现的词的概率c定为0.0001%
#假设是垃圾邮件和是正常邮件的可能性相同,将每一类的先验概率prior都设为50%
#以下函数用于分类
classify.email <- function(path, training.df, prior = 0.5, c = 1e-6)
{
# Here, we use many of the support functions to get the
# email text data in a workable format
msg <- get.msg(path)
msg.tdm <- get.tdm(msg)
msg.freq <- rowSums(as.matrix(msg.tdm))
# Find intersections of words
msg.match <- intersect(names(msg.freq), training.df$term)
# Now, we just perform the naive Bayes calculation
if(length(msg.match) < 1)
{
#没有任何词出现在垃圾邮件集中,length(msg.freq)是词的个数
return(prior * c ^ (length(msg.freq)))
}
else
{
#找出共现词的文档频率放到match.probs
match.probs <- training.df$occurrence[match(msg.match, training.df$term)]
return(prior * prod(match.probs) * c ^ (length(msg.freq) - length(msg.match)))
}
}
#可以应用了
hardham.docs <- dir(hardham.path)
hardham.docs <- hardham.docs[which(hardham.docs != "cmds")]
#应用正常邮件词频,得出是正常邮件的概率
hardham.spamtest <- sapply(hardham.docs,
function(p) classify.email(file.path(hardham.path, p), training.df = spam.df))
#应用垃圾邮件词频,得出是垃圾邮件的概率
hardham.hamtest <- sapply(hardham.docs,
function(p) classify.email(file.path(hardham.path, p), training.df = easyham.df))
#如果一封邮件是正常邮件的概率大于是垃圾邮件的概率,返回TRUE,否则返回FALSE
hardham.res <- ifelse(hardham.spamtest > hardham.hamtest,
TRUE,
FALSE)
summary(hardham.res)
#不能只拿正常邮件来测试,把刚才的正常和垃圾邮件都拿来分类看看效果
#结果分三个列,正常邮件概率,垃圾邮件概率和判别结果
spam.classifier <- function(path)
{
pr.spam <- classify.email(path, spam.df)
pr.ham <- classify.email(path, easyham.df)
return(c(pr.spam, pr.ham, ifelse(pr.spam > pr.ham, 1, 0)))
}
#把所有没分类的文件合并起来
easyham2.docs <- dir(easyham2.path)
easyham2.docs <- easyham2.docs[which(easyham2.docs != "cmds")]
hardham2.docs <- dir(hardham2.path)
hardham2.docs <- hardham2.docs[which(hardham2.docs != "cmds")]
spam2.docs <- dir(spam2.path)
spam2.docs <- spam2.docs[which(spam2.docs != "cmds")]
# 全部分类
easyham2.class <- suppressWarnings(lapply(easyham2.docs,
function(p)
{
spam.classifier(file.path(easyham2.path, p))
}))
hardham2.class <- suppressWarnings(lapply(hardham2.docs,
function(p)
{
spam.classifier(file.path(hardham2.path, p))
}))
spam2.class <- suppressWarnings(lapply(spam2.docs,
function(p)
{
spam.classifier(file.path(spam2.path, p))
}))
# 创建单个数据框包含了全部要分类的数据
easyham2.matrix <- do.call(rbind, easyham2.class)
easyham2.final <- cbind(easyham2.matrix, "EASYHAM")
hardham2.matrix <- do.call(rbind, hardham2.class)
hardham2.final <- cbind(hardham2.matrix, "HARDHAM")
spam2.matrix <- do.call(rbind, spam2.class)
spam2.final <- cbind(spam2.matrix, "SPAM")
class.matrix <- rbind(easyham2.final, hardham2.final, spam2.final)
class.df <- data.frame(class.matrix, stringsAsFactors = FALSE)
names(class.df) <- c("Pr.SPAM" ,"Pr.HAM", "Class", "Type")
class.df$Pr.SPAM <- as.numeric(class.df$Pr.SPAM)
class.df$Pr.HAM <- as.numeric(class.df$Pr.HAM)
class.df$Class <- as.logical(as.numeric(class.df$Class))
class.df$Type <- as.factor(class.df$Type)
# 画图
class.plot <- ggplot(class.df, aes(x = log(Pr.HAM), log(Pr.SPAM))) +
geom_point(aes(shape = Type, alpha = 0.5)) +
stat_abline(yintercept = 0, slope = 1) +
scale_shape_manual(values = c("EASYHAM" = 1,
"HARDHAM" = 2,
"SPAM" = 3),
name = "Email Type") +
scale_alpha(guide = "none") +
xlab("log[Pr(HAM)]") +
ylab("log[Pr(SPAM)]") +
theme_bw() +
theme(axis.text.x = element_blank(), axis.text.y = element_blank())
print(class.plot)
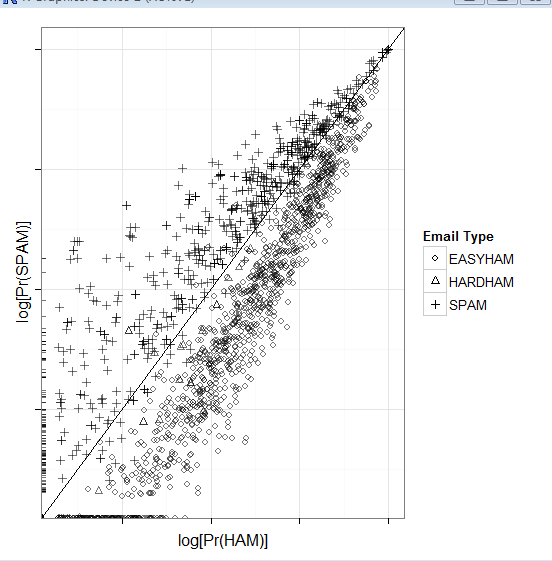
get.results <- function(bool.vector)
{
results <- c(length(bool.vector[which(bool.vector == FALSE)]) / length(bool.vector),
length(bool.vector[which(bool.vector == TRUE)]) / length(bool.vector))
return(results)
}
# 给出正确率
easyham2.col <- get.results(subset(class.df, Type == "EASYHAM")$Class)
hardham2.col <- get.results(subset(class.df, Type == "HARDHAM")$Class)
spam2.col <- get.results(subset(class.df, Type == "SPAM")$Class)
class.res <- rbind(easyham2.col, hardham2.col, spam2.col)
colnames(class.res) <- c("NOT SPAM", "SPAM")
print(class.res)


