
Linux就这个范儿 第11章 独霸网络的蜘蛛神功
Linux就这个范儿 第11章 独霸网络的蜘蛛神功 第11章
应用层 (Application):
网络服务与最终用户的一个接口。
协议有:HTTP FTP TFTP SMTP SNMP DNS
表示层(Presentation Layer):
数据的表示、安全、压缩。(在五层模型里面已经合并到了应用层)
格式有,JPEG、ASCll、DECOIC、加密格式等
会话层(Session Layer):
建立、管理、终止会话。(在五层模型里面已经合并到了应用层)
对应主机进程,指本地主机与远程主机正在进行的会话
传输层 (Transport):
定义传输数据的协议端口号,以及流控和差错效验。
协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层
网络层 (Network):
进行逻辑地址寻址,实现不同网络之间的路径选择。
协议有:ICMP IGMP IP(IPV4 IPV6) ARP RARP
数据链路层 (Link):
建立逻辑连接、进行硬件地址寻址、差错校验等功能。(由底层网络定义协议)
将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正。
物理层(Physical Layer):
建立、维护、断开物理连接。(由底层网络定义协议)
更有趣的是我们能把所有物品通过射频识别信息传感设备与互联网连接起来,实现智能
化地识别和管理。Linux这个开发平台,通过模块化的驱动,对Zigbee无线传感网络、蓝牙、
WiFi、射频识别RFID、远程网络和多网络融合技术的有力的支持,可实现许多令人向往的
应用场景:出家门时大门提醒主人需要带什么东西;衣服“告诉”洗衣机对颜色和水温的要
求;坐在家里可以检测身体的情况并接受远程医生的治疗等等。
更神奇的是在2010年底,思科在不利用任何地面基站的情况下,完成了业界首次网络
通话,让互联网走出了地球。看来网络的未来发展空间将是整个宁宙,不久的将来“马丁叔
叔①’也能在火星上浏览网页了。
现如今,Linux凭借其精湛的“蜘蛛神功”,联网特性极其刚猛,加之深厚的内核功力,
“织网”能力日臻纯熟。Linux独霸网络一统江湖只在朝夕,这主要表现在:
(1)内建了HTTP、FTP,DNS等功能,支持所有常见的网络服务。加上超强的稳定性,
让很多ISP (Internet Service Providers)都乐意采用Linux来架设邮件、FTP以及
Web等各种服务器。
(2) 支持几乎所有的通用网络协议。比如IPv4、IPv6、AX.25、X.25、IPX、DDP (Appletalk)、
NetBEUI、Netrom等。
(3) 通过一些简单的Linux命令就能完成内部信息或文件的传输,系统管理员和技术人
员通过系统提供的远程访问功能可有效地为多个系统服务。
(4) 支持Netware的客户机和服务器,甚至支持让用户共享Microsoft Network资源的
Samba服务。
有这么多创新的应用,这么神奇的服务,你还在等什么?万丈高楼平地起,虽然“蜘蛛
神功”很好很强大,可我们还得从基础学起。
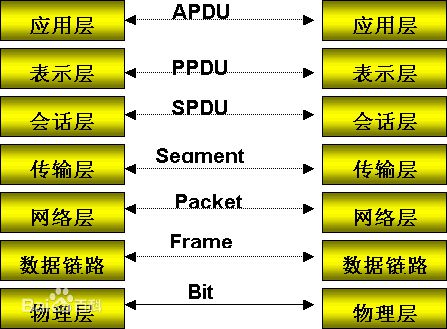
11.1 功夫理论:网络知识
首先声明:若练神功,不必自宫。但是没有网络方面的理论基础则是万万不行。提到网
络理论基础,无一例外地我们都会想到OSI七层模型和TCP/IP网络参考模型。这两个模型
都具有网络结构化分层的特点。现在形形色色的系统框架都提倡分层和组件化。那么分层究
竟有什么好处呢?网络分层的主要好处就是可以屏蔽其他层的实现细节,各层只需提供与自
己相邻层的接口即可。在各层之问接口标准化的另一个好处是不同的产品可以提供不同层次
的功能,这样就简化了设计,例如路由器只实现一到三层。除此之外,分层还创造了更好的
集成环境,减少复杂性,每层都有headers和tailers,可以利用它们进行排错。这种分层的
思想在软件架构设计当中也是非常普遍的。
我们知道中国人是很讲究论资排辈的,那么OSI和TCP/IP两个谁的辈分更大呢?论时
间它们年纪相仿,但严格说来应该是TCP/IP资格更老。因为在OSI的七层模型诞生之前,
ARPANET已经存在了。TCP/IP生于20世纪60年代,是从美国国防部研究所计划局DARPA
开发异种网络互连与互通项目中诞生的。它是从实践中走来,先有协议后有4层模型的。它
的模型主要起解释作用,象征意义大于实际作用。为了更好地推广TCP/IP,DARPA还资肋
一些机构在UNIX操作系统上开发TCP/IP协议。而OSI模型则生于20世纪70年代,全称是开
放系统互联,由国际标准化组织ISO提出。它相当’F学院派的作品,设计先于实现,许多设计也过于理想化。OSI强调提供可靠的数据传输服务,每一层都要进行检测和处理错误。在这方面,TCP/IP和OSJ观点不同。TCP/IP认为可靠要由端对端来保证,不要把系统搞得太复杂。传输层利用检验和、ACK和超时等手段实现错误检测和恢复来保证可靠性控制就可以了。随着岁月的流逝,证明简单才是硬道理,TCP/IP已成为国际互连事实上的国际标准和工业标准。
但以发展的眼光来看,OSI也有它积极的意义,它适用于更多类型的网络,而不仅仅是
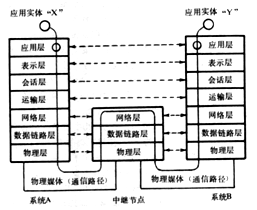
计算机网络。OSI与TCP/IP也有一定的对应关系,具体可参考表11-1:
表11-1 0SI与TCP/IP的对应关系
|
OSI |
TCP/IP |
|
|
分 层 |
描 述 |
分 层 |
|
实体层 |
以二进制数据形式在物理媒体上传输数据 |
网络接口层 |
|
数据链路层 |
传输有地址的帧以及错误检测功能 |
|
|
网络层 |
为数据包选择路由 |
网络互联层(IP层) |
|
传输层 |
提供端对端的接口 |
传输层 |
|
会话层 |
解除或建立与别的接点的联系 |
应用层 |
|
表示层 |
数据格式化,代码转换,数据加密 |
|
|
应用层 |
文件传输,电子郎件,文件服务,虚拟终端 |
|
OSI七层模型
物理层
数据链路层
网络层
传输层
会话层
表示层
应用层
11.2 “蜘蛛神功”第一层:网络工具
我们现在开始修炼第一层的功夫,是基本功。需要从最基本的“马步”开始练起,增加
你的耐力和身体的稳定性。在这之后我们就要开始学习“套路”了,这包括“掌法”、“腿功”、
“眼力”和“身法”。闲话不多说,马上开始。
11 .2.1 马步:ifconfig
ifconfig是一个用来查看、配置和开关网络接口的常用工具,属于最基本的工具。只有
掌握了它的使用,你才能驾驭好“蜘蛛神功”。我们可以利用它临时性地配置网卡的IP地址、
子网掩码、广播地址、网关等。也可以把它写入/etc/rc.d/rc.local文件中,在系统引导时为网
卡设置IP地址。
首先我们看一下“马步”的基本架势,用它查看一下网络接口状态:
# ifconfig
etho Link encap : Ethernet HWaddr 00 : CO : 9F : 94 : 78 : OE
inet addr : 192 . 168 .1. 88 Bcast : 192 . 168 .1. 255 Mask : 255 . 255 .255 . 0
inet6 addr : fe80 : : 2c0 : 9fff : fe94 : 780e/64 Scope : Link
UP BROADCAST RUNNING MULTICAST MTU : 1500 Metric : 1
RX packets : 850 errors : 0 dropped : 0 0verruns : 0 frame : 0
TX packets : 628 errors : 0 dropped : 0 0verruns : 0 carrier: 0
collisions : 0 txqueuelen : 1000
RX bytes:369135 (360.4 KiB) TX bytes:75945 (74.1 KiB)
lo Link encap: Local Loopback
inet addr: 127.0.0.1 Mask: 255.0.0.O
inet6 addr: ::1/128 Scope: Host
UP LOOPBACK RUNNING MTU: 1643 6 Metric:1
RX packets: 57 errors:O dropped:0 0verruns:0 frame:O
TX packets: 57 errors:0 dropped:O overruns:0 carrier:O
collisions:0txqueuelen:0
RX bytes: 8121 (7.9 KiB) TX bytes: 8121 (7.9 KiB)
达个命令的输出信息量还是很大的。大致分为上下两个部分,上面是eth0酌信息,下面是lo的信息(在你的实际系统中可能会有更多部分)。其中IP地址、子网掩码、MAC地址等重要信息基本上也是一目了然的。但是也有一些是看不懂的,比如RX和TX后面那些都代表什么呢?lo又代表什么呢?
在搞清楚这些问题前,我们首先要搞清楚第四行中的内容,也就是:
UP BROADCAST RUNNING MULTICAST
这样的内容都代表什么含义。这其实是代表网卡的状态。有些状态是可以同时出现的,
有些则不能,表11-2列举了能够出现的状态标志,你可以分析一下哪些是能共存的,哪些
不能。
表11-2网卡能够出现的状态标志
|
状态标志 |
说 明 |
|
UP |
这个标志指出这个接口是开放的,可以发送和接收数据 |
|
DOWN |
个标志指出这个接口是关闭的,也就是说,此时不能为主机发送和转发包 |
|
NOTRAILERS |
这个标志指出了一个报文尾不包括以太帧的尾部。报文尾是在Berkerley Unix系 统中使用的把信息头加到包尾的一种方式。在Solaris2.x系统中已经不支持 |
|
RUNNING |
这个标志指出,该接口已经被系统识别 |
|
MULTICAST |
这表示接口支持多路传送地址 |
|
BROADCAST |
这表示接口支持广播地址 |
现在我们来看RX和TX。它们代表这块网卡从启动到现在的封包收发情况,RX是收,
TX是发。packets就代表包数,多少都没事儿;其他的各代表一种错误,数值应该越少越好,
0是最好的。至于这些错误都代表什么,由什么引起的则不属于本书负责的范围。
从ifconfig的输出的格式上看,Io和eth0应该具有同等地位,都是网络设备。其实不然,
Io表示的是主机的回环地址。这个一般是用来测试一个网络程序,但又不想让局域网或外网
的用户能够查看,只能在此台主机上运行和查看所用的网络接口。比如把httpd服务器的地
址指定为回环地址,在浏览器输入127.0.0.1就能看到你所架设的Web网站了。
基本的“马步”架式已经掌握,接下来就要折腾一些花样,使用ifconfig配置网络接口
让网络通起来:
# ifconfig eth0 192. 168.1.252 hw ether 00: 11: 00: 00: 11: 11\ > netmask 255 .255.255.O broadcast 192. 168 .1.255 up
这个例子中我们为eth0设置了IP地址、子网掩码、广播地址,MAC地址,并且激活了
它。这里比较让人头痛的可能就是“hw”这个参数,其后面所接的是网络接口类型,ether
表示以太网。
有时我们为了满足不同的需求还需要给一个网络接口指定多个IP地址,比如我们期望在同一台机器上用不同的IP地址来运行多个httpd服务器。这就要用到“虚拟网络接口”这个概念了。虚拟网络接口就是在网络接口名后面接着冒号“:”和数字,比如:eth0:0、eth0:1、eth0:2......ethO:N。假设真实的网络接口是eth0的话,我们可以用下面的方法配置虚拟网络接口。
# ifconfig eth0 :0 192 . 168 .1.250 netmask 255 .255 .255 . 0 # ifconfig eth0 :1 192 .168 . 1. 249 netmask 255 .255 .255 . 0
但是用ifconfig为网卡指定IP地址只是用来调试网络用的,并不会更改系统关于网卡
的配置文件。若要把IP地址固定下来,请参考第2章中解决上网问题那节我们所讲述的三
种配置IP地址的方法。
在虚拟网络接口上配置的IP地址实际上并没有与这台计算机做绑定。换句话说,不同
的计算机上的虚拟网络接口可以配置相同的IP地址。而这个时候的IP地址还有一个专用的
名称——VIP,即虚拟IP。VIP是非常有用的,本书在后面介绍LVS的时候还要用到。
好了,如果你已经把ifconfig用熟了,那么就证明你的“马步”已经练成扎稳了。在面
对接下来的各种套路招式的时候,就应该不会手忙脚乱走火入魔了。
11 .2.2掌法:route
首先我们要学习的是“掌法”路由的概念。路由是此网和彼网沟通的纽带,route命令
用于查询和设置路由表。在同一个子网内的主机通信不需要路由,比如192.168.1.2/24和
192.168.1.3/24之间的沟通;不同的子网络内的主机通信才需要路由比如192.168.1.1/24和
192.168.2.1/24之间的沟通。路由器(或者称网关)就是用来给不同子网内的主机之间的数
掘包规划“传输路径”的网络设备。
我们先小试一下:
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255 .255.0.0 U 1002 0 0 eth0
0.0.0.0 192 .168 .1. 254 0.0.0.0 UG 0 0 0 eth0
这个命令就是查看我机器的路由表信息。这个路由表各字段的含义如下:
● Destination、Genmask共同组合成一个完整的子网。
● Gateway定义从哪个gateway连接出去。如果是0.0.0.0表示该路由是直接由本机
传送;如果显示有IP的话,表示该路由需要得到路由器的帮忙才能够传送出去。
● Flags可能出现的标志及其意义如下:
□ U (route is up):该路由是启动的。
□ H (target is a host):目标是一部主机(IP)而非网域。
□ G (use gateway):需要透过外部的主机(gateway)来通信。
□ R (reinstate route for dynamic routing):使用动态路由时,恢复路由信息的标志。
□ D (dynamically installed by daemon or redirect):已经由服务或转pofl功能设定为
动态路由。
□ M (modified from routing daemon or redirect):路由已经被修改了。
□ ! (reject route):这条路由将不会被接受(用来抵挡不安全的网域!)。
本例中Destination 0.0.0.0行中的Flags列中显示UG,表示这条路由已启动,
需要通过外部主机192.168.1.254来通信。
● Metric路由的跃点数,范围是0-9999。这个相当于是路由的权重,决定路由优先
级,数值越小优先级就越高。这是一个比较高级话题,可以参考专门的著作。
● Ref路由引用计数。这个值恒为0,因为在Linux系统中就没有实现它。
● Use该路由被使用的次数,可以粗略估计通向指定网络地址的网络流量。但是在本
书中是0,因为还要取决于“一F”和“-C”参数。
● iface数据传递出去的硬件接L]。
路由的排列顺序是从小网域(192.168.1.0/24是Class C),逐步到大网域(169.254.0.0/16
Class B)最后到默认路由(0.0.0.0/0.0.0.0)。当我们要判断某个数据包应该如何传送的时候,可经过这个路由过程来判断!
本例中的三条路由,如果有一个目的地址为192.168.1.66的数据包要发出去,首选找到
了192.168.1.0/24遮个网域的路由,就直接由eth0发出去了!那么从我这台机器上发送到
www.alibaba.com主机的数据的路由情况又是怎样的呢?假设其IP是110.75.216.92,第一和第二条路由都不符合,结果到达第三条default=0.0.0.0/0.0.0.0默认路由时满足条件。这时就通过eth0将数据包传给192.168.1.254那部gateway主机,求它帮忙把数据包传到外网。我们可以利用traceroute命令来跟踪一下发往www.alibaba.com的数据包所要经历的路径,其输出结果的第1行就是离我们最近的路由器的192.168.1.254这个IP地址。
route命令除了可以查看路由,还可以用来添加和删除路由。比如:
# route del -net 169 .254.0.0 netmask 255 .255.0.0 dev eth0
删除掉169.254.0.0/16这个网域。别偷懒,netmask和dev等参数一定要写全!
# route add -net 192. 168.1.0 netmask 255 .255 .255.0 dev eth0
增加一条路由!路由的设定必须能够与你的网段能够互通。如果你的主机仅有
192.168.1.X这个IP,添加下面的路由就会显示错误:
# route add -net 192. 168.2.0 netmask 255 .255 .255.O gw 192. 168.2.254
下面是增加默认路由的方法!默认路由一个就够了。
# route add default gw 192.168.1.250
还有你的主机要和192.168.1.250能够通信才行,否则路由被重置后果自负。
11 .2.3腿功:netstat
掌上的功夫练好了就可以练习“腿功”netstat命令了。netstat命令可以显示路由表、实际的网络连接以及每一网络接口设备的状态信息。
如果你想查看本机都启动了什么服务,端口是什么以及当前网络状态的话,netstat就可以帮你搞定。如果启动了某个服务它却表现异常,netstat也可帮你找出原因。
事实上,netstat并不是一个人在战斗,是若干工具的汇总 包括/etc/services文件。
netstat -r 跟route -n是一样的
[root@steven ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0 192.168.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 0.0.0.0 192.168.1.1 0.0.0.0 UG 0 0 0 eth0 [root@steven ~]# netstat -r Kernel IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface link-local * 255.255.0.0 U 0 0 0 eth0 192.168.0.0 * 255.255.0.0 U 0 0 0 eth0 default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
现在我们用netstat查看当前的网络连接信息:
# netstat -nta Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0 .0.1:2208 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:1002 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:111 0.0.0.O:* LISTEN tcp 0 0 127.0.0.1: 631 0.0.0.O:* LISTEN tcp 0 0 127.0.0.1: 25 0.0.0.O:* LISTEN tcp 0 0 127 .0.0 .1:2207 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:3306 :::* LISTEN
netstat输出可以分为两大部分:一个是TCP/IP的网络部分,另一个Unix socket部分。
Unix socket只能用于本机内的进程间通信。由于Unix socket连接非常多,为了更清楚地查看
网络情况,本例使用-nta要求只列出所有TCP的网络情况。各字段的解释如下:
● Proto连接的封包协议。
● Recv-Q非连接本Socket的用户程序所复制的总bytes数。
● Send-Q没有被远端主机ACK的总bytes数,主要指SYN或其他标志的数据包所占
的bytes数。
● Local Address本地地址与端口
● Foreign Address远程地址与端口
● Stat内部地址与外部地址的连接状态:
□ ESTABLISED:经过TCP三次握手已建立连接。
□ SYN—SENT:表示请求连接。SYN SENT状态应该是非常短暂。
□ SYN—RECV:接收到一个要求连线的主动连线封包。
□ FIN—WAIT1:socket已中断,该连线正在断线中。
□ FIN—WAIT2:该连线已挂断,但正在等待对方回应断线确认包。
□ CLOSE-WAIT:当客户端向服务器发送请求等待超时后,客户端就会发FIN包到服务端,但FIN包因为服务器没有空闲线程池而得不到及时处理,所以TCP连接请求只能处于CLOSE-WAIT状态,同时新请求也被阻塞,有了这个基础之后,再通过代码调试跟踪,最后发现处理逻辑是同步的,要改为异步。 (蜘蛛神功第二层 套接字)
□ TIME—WAIT:该连线已挂断,但socket还在网络上等待结束。
□ LISTEN:表示处于侦听状态,该端口是歼放的,等待连接。可使用专门的“-ll”
参数单独查阅。
SYN_SENT状态应该是非常短暂。如果发现SYN_SENT非常多且在向不同的机器发出,
那你的机器可能中了冲击波或震荡波之类的病毒。这类病毒为了感染别的计算机,它就要扫描别的计算机,在扫描的过程中对每个要扫描的计算机都要发出同步请求,这就是出现许多
SYN_SENT的原因。当然,这些情况大多是发生在Windows下,既然你已经选择了Linux,
应该是很少再为病毒所恼的。
作为服务器,重点要看的是LISTEN状态和ESTABLISHED状态。LISTEN是本机开了
哪些端口;ESTABLISHED是谁在访问你的机器,从哪个地址访问的,是不是一个正常程序
发起的。在Windows系统上看ESTABLISHED状态时一定要注意是不是IEXPLORE.EXE程
序(IE)发起的连接,如果是IEXPLORE.EXE之类的程序发起的连接,也许是你的计算机
中了木马。
在本例中我们通过netstat查看到了当前所打开的端口号。那么顺便提一下Linux服务端
口的设置问题。在大多数Linux发行版下都能够找到/etc/services这个文件,它实际上是一个
字典文件,用来说明服务与端口的对应关系。有如下类似的内容:
ftp 20/tcp ftp 20/tcp ssh 22/tcp telnet 23/tcp
这看起来是给服务分配端口用,但是实际上这个文件并没有这个作用。它只是给netstat
命令参考的,因为当你不给它传递“-n”这个命令选项时,足能够输出服务名的。netstat之所以能够做到这一点,就是/etc/services文件起的作用。
为了验证这一点,你可以尝试着修改一下它。
11 .2.4 眼力:DNS二把刀
到目前为止你已经习得了“蜘蛛神功”的“掌法”和“腿功”,已经可以列入“一等一
高手”的行列里了,只是还缺乏一些临战经验。其实所谓的临战经验也不过就是一个“快”
字,只有出手快才能占据主动权。而要“快”就必须有非常好的“眼力”去洞察目标。“蜘
蛛神功”有专门的套路来提升“眼力”,那就是DNS二把刀。Linux上的DNS二把刀就是:
host和nslookup。这两个命令都是非常常用的DNS工具。
既然说到了DNS,顺便就介绍一下与DNS有关的东东吧。主要有三个:一是主机自己
的名字;二是DNS服务器;三是HOST文件。
在Linux中可以用hostname命令来查看主机自己的名字。设置主机自己的名字一般可
以通过/etc/sysconfig/network文件完成。它的主要内容一般是:
/etc/sysconfig/network NETWORKING=yes HOSTNAME=localhost.localdomain
HOSTNAME后面紧跟的是主机名,这里是系统默认的localhost.localdomain,更改主机
名后需要重新启动才能生效。
为了能够正常上网,DNS服务器是必不可少的设置环节。/etc/resolv.conf文件就是用来
设置固定DNS服务器的,其主要内容如下:
/etc/resolv.conf nameserver 8 . 8 . 8 . 8 nameserver 202 . 96 . 128 . 86
nameserver后面紧跟着的就是DNS服务器了。如果你通过nameserver指定了几个DNS
服务器,则先后顺序决定主从服务器。目前最多支持3个域名服务器。
所谓HOST文件,实际上就是主机名静态查询表。在Linux下是/etc/hosts文件,它告诉
本主机哪些域名或主机名对应哪些IP,其内容差不多是这样:
#网络IP 主机名或域名 主机名别名(可选)
/etc/hosts 127 . 0 . 0 .1 localhost. Localdomain localhost 192 168 . 21. 100 webserver. cn77888.com webserver 192 .168 . 21. 111 ftp.cn7788.com ftp
主机名通常在局域网内使用,通过hosts文件被解析到对应的IP地址上。而域名通常在
Internet上使用。Linux做域名解析的时候先查hosts文件,所以如果本机不想使用Internet
土的域名解析,可以更改hosts文件,加入自己的域名解析。
host命令非常简单,功能也很单一,就是查询某个域名或丰机名所对应的所有IP地址,
比如:
# host www. google.com www. google. com has address 74. 125. 31. 106 www. google. com has address 74. 125.31. 147 www. google. com has address 74. 125.31. 99 www. google. com has address 74. 125.31. 103 www. google. com has address 74. 125.31. 104 www. google. com has address 74. 125.31. 105 www. google. com has IPv6 address 2404: 6800: 4008: c01::63
这是我能解析到的google这个域名所对应的所有IP。一个域名绑定多个IP最直接的作
用就是
(1)容灾:当某个IP不可用时可以立即换用其他lP,防DDOS攻击;
另外一作用就是
(2)使得用户能够就近访问,给用户提供最为流畅的体验,因为可以根据用户的不同来源提供不同的IP地址。
nslookup和host墓本是一样的,用来查询一台机器的IP地址和其对应的域名。这个命令有两种模式:交互式和非交互式。如果你不给它传递任何参数,它就会进入交互模式,例如:
# nslookup > WWW . taobao . com Server: 10 . 0 . 1. I Address : 10 . 0 . I . 1#53 Non-authoritative answer: www. taobao. com canonical name=www. gslb.taobao. com. danuoyi. tbcache. com. www. gslb.taobao. com. danuoyi. tbcache. com canonical name: scorpio. danuoyi.tbcache. com. Name: scorpio. danuoyi.tbcache. com Address:124. 193. 226.251 Name: scorpio. danuoyi.tbcache. com Address:124. 193. 226. 241 > nslookup比较特别的地方就是可以手动指定DNS服务器来得到不同解析结果,例如: # nslookup www. sina. com. cn Server: 10.0-1.1 Address: 10.0.1.1#53 Non-authoritative answer : www . sina . com . cn canonical name = j upiter . sina . com . cn . jupiter . sina . com _ cn canonical name = polaris . sina . com . cn . Name : polaris . sina . com. cn Address : 202 . 108 . 33 . 60 # nslookup www. sina . com. cn 8 . 8 . 8 . 8 Server : 8 . 8 . 4 . 4 Address : 8 . 8 . 4 . 4#53 Non-authoritative answer : www . sina . com . cn canonical name = j upiter . sina . com . cn . jupiter . sina . com . cn canonical name = ara . sina . com _ cn . Name : ara . sina . com . cn Address : 58. 63 .236 . 50 Name : ara . sina . com . Cn Address : 58 . 63 . 236 . 26 ...... Name : ara . sina . com. cn Address : 58 . 63 .236 .41
11 .2.5身法:tcpdump
做网络开发和维护的工程师如果说自己不会用tcpdump就真没法在江湖上混了,因为那是“蜘蛛神功”的“身法”。段誉之所以每次都能够逢凶化吉,就是因为练就了“凌波微步”那曼妙的身法。
tcpdump是网络运维人员查找问题的利器。通过不同的命令行选项来改变抓包状态。利
用正则表达式组合成多种过滤报文的条件,数据包满足表达式的条件就会被捕获。如果没有
给出任何条件,那么网络上所有的数据包将会被截获。
举个例子,如果想捕获119.75.219.38接收或发送的http包,将其结果生成详细报告,
可以使用如下命令:
# tcpdump tcp port 80 and host 119 .75.219. 38>net_stat. txt
这样你就可以使用V1等工具读取net_stat.txt文件来分析问题了。不知道你是否感觉到使用VI等工具来阅读抓包文件不太直观。
其实比较好的办法是把tcpdump抓下来的内容存成pcap文件(-w选项),然后使用图形界面的网络协议分析工具例如Wireshark(它的前身就是很黄很暴力的开源网络协议分析工具Ethereal)进行数据包分析。例如,某家电子商务网站曾经碰到过一次很严重的线上故障,造成了N百万的资损,最终是通过tcpdump在相关服务器上抓包排查出问题的。比如在Apache服务器上监控80端口的数据包,可使用如下命令:
#tcpdump tcp port 80 -S 0 -w http .pcap
然后将截获到的http.pcap数据包文件使用Wireshark或Packetyzer之类的工具打开
查看。
当然,工具只是帮助你解决问题的一种手段。使用好抓包工具的关键还是要对网络协
议有深入的理解,根据实际情况列出过滤条件,快速找到自己想要的数据包进行分析。例
如我要分析WLAN设备的工作情况,若是对802.11的探测、身份验证、关联过程、控制
以及数据包的协议格式都不了解的话,就算把抓到的数据包给我,我也看不懂,如同看火
星文一样。
曾经遇到过这么一个情况,公司网络突然变得非常慢,近乎瘫痪。请来网络运维的人员,
他要做的事情就是在网络内一台主机上运行抓包软件,捕获所有到达本机的数据包进行分
析。如果是Linux主机的话,使用tcpdump就可以执行监听网络数据的任务。网络变慢常常
和由ARP病毒造成带宽资源耗尽有关。ARP病毒很狡猾,它欺骗网关或网内的所有主机。
在网关的ARP缓存表中,网内所有活动主机的MAC地址均为中毒主机的MAC地址;网内
所有主机的ARP缓存表中,网关的MAC地址也成为中毒主机的MAC地址。前者保证了从
网关到网内主机的数据包被发到中毒主杌。后者相反,使得主机发往网关的数据包均发送到
中毒主机。
tcpdump是一个非常强大的命令,就算利用整本书去讲解它也未必就能做到面面俱到。
本书在这个地方只能起到抛砖引玉的作用,期望继续深入的你还需寻找更为专业的著作来满
足你那求知若渴的心。
11.3 “蜘蛛神功”第二层:套接字
有了网络基础知识,学会了操作命令,我们就要开始修炼第二层功夫,尝试一下网络编程了。
搞过网络编程的人都接触过Socket。
这东西年头久远了,可追溯到20世纪60年代,那个时候网络才刚刚起步。Berkeley计算机研究组就开始研究如何编写网络程序,如何回调网
络应用,从而开发出了Socket的原始版本。Socket的这个原始版本经过多个厂商与组织的
共同努力,最后形成一套成熟的Socket API。不能不说Socket API是经典中的经典,数十年后的今天我们还在使用。
但由于历史原因,经典中稍微带有那么一点点小瑕疵。比如说,Socket里面有PF开头的一组枚举值来表示协议簇,还有AF开头的一组枚举值来表示地址簇,
有点多余。到目前为止所有的协议簇和地址簇都是一一对应的,还没有出现一个协议簇支持多个地址簇的情况。
事实上现在我们也不认为同时需要这两个概念,但在写程序的时候我们却要生生地区分它们。
又比如说,sockaddr这个结构体类型,它的存在只是为方便传递一个结构指针,但是用户却从来没有真正使用过这个类型。
尽管Socket API有上面小个的瑕疵,但这并不影响它在网络编程中的生命力,在网络协
议栈中可以看作是独立的一个Socket层。这个Socket层设计得非常巧妙,不服不行,它和网络协议层联系起来,屏蔽了网络协议的不同,
只把数据部分通过系统调用接口呈献给应用层。
这种协议无关性,让程序员用起来感觉很方便,一个网络程序只需要几个简单的socket系统调用,整体的资源就都可以使用了。
socket->connect->read->write->close构成了一个TCP客户端;
而在这个客户端上加入bind、listen、accept三个调用就构成了一个TCP服务器程序。
天下没有完美的事情。尽管Socket API使用很方便,但是网络非常不稳定,可能随时崩溃。
操作系统也不是万能的,应用程序不仅要完成自己的业务,还要关心网络可能出现的各种情况。做好网络流量控制、异常监控和故障转移等工作,是每一个拥有联网功能程序的基
本义务。网络本身的复杂性,也给程序员带来了很大的挑战,写好Socket网络程序从来就不是一件容易的事情。
下面是一段关于网络出现异常的真实故事······
很多年以前,我在开发一个网络服务器的时候,发现服务器某个端口堆积着大量
CLOSE_WAIT状态。有时应用能够恢复,有时应用就瘫痪了,不能响应TCP请求。
我第一反应就是要搞清楚导致CLOSE_WAIT状态是在什么情况下发生的?理论上分析:
当客户端向服务器发送请求等待超时后,客户端就会发FIN包到服务端。但FIN包因
为服务器没有空闲的线程而得不到及时处理,所以TCP的连接请求只能处于CLOSE_WAIT
状态,同时新请求也被阻塞。有了这个基础后,再通过对代码的调试跟踪。最后我发现请求
处理逻辑是同步的,这个做法是有问题的。如果业务处理得慢,就会造成拥塞。我用异步方
式处理业务请求把I/O线程解放出来,问题随之解决。
好了,有关“蜘蛛神功”第二层的东西我们暂时就介绍到这里,因为本书已经将epoll
编为“七种武器”中的一种武器——碧玉刀,在后面的章节中会有更详尽的介绍。接下来我们还要修炼一下内功心法!
11.4 内功心法:TCP/IP协议栈初探①
“我们一直在克服这样或那样的障碍,好像在翻山越岭一样,爬到顶,然后落下来,再释放能量。”
——TCP/IP发明人Vinton G Cerf博士
十几年前第一次下载Linux内核源码,研读net和drivers/net里面代码时的那种剪不断
理还乱的复杂心情依然在胸。那时候中国网络还不算那么发达,关于Linux内核方面的资料
少之又少。我只能告诫自己沉下心来,从变量定义和数据结构开始,然后从上层调用到底层
调用,从底层调用再到上层调用,一点一点地研究。学习的过程是艰苦的,也是有收状的。
在利用列车供电线传输组播视频流的项目中,我就利用对Linux TCP/IP协议栈的理解,在
电力猫设备上定制实现了自己的Linux TCP/IP协议栈以提高传输数据的质量,解决了马赛克
问题(牛)。其实,就算不做内核开发的工作,对协议栈酌理解也会对你写好网络应用程序
有所帮助的。
掌握Linux TCP/IP栈需要理解系统调用、socketfs文件系统和sk_buff这三个关键知识点。
理解它们之后,我们就比较容易看懂Linux TCP/IP方面的内核代码了。在此基础上依靠个人
修炼,逐步释放能量,在领悟大师们的设计思想的过程中不断进步!
11.4.1 枯树盘根:系统调用
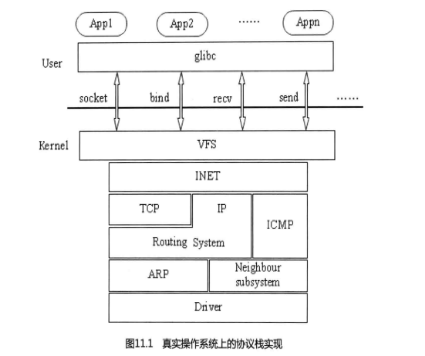
图11.1描述了Linux的TCP/IP协议栈的实现方式。看了以后,希望能够帮助你在协议
栈的理解上增加点感性认识。
①没有网络编程经验的工程师要绩悸这仃有一定难度,fH足领会Linux TCP/IP协议栈的设计
思想还是大有好处。
glibc库是什么?没有glibc库,就没有Linux。我们平时用过的malloc和strcpy等函数
都是glibc这位仁兄提供的。除此之外,它还提供了网络编程中要用到的Socket API接口。之前曝光的glibc库漏洞
glibc版本
rpm -qa |grep glibc glibc-2.12-1.166.el6_7.3.x86_64 glibc-headers-2.12-1.166.el6_7.3.x86_64 glibc-2.12-1.166.el6_7.3.i686 glibc-devel-2.12-1.166.el6_7.3.x86_64 glibc-common-2.12-1.166.el6_7.3.x86_64
glibc CVE-2015-7547漏洞的分析和修复方法
http://bbs.qcloud.com/thread-13780-1-1.html
漏洞概述
glibc中处理DNS查询的代码中存在栈溢出漏洞,远端攻击者可以通过回应特定构造的DNS响应数据包导致glibc相关的应用程序crash或者利用栈溢出运行任意代码。应用程序调用使用getaddrinfo 函数将会收到该漏洞的影响。
这样TCP/IP接口通过INET层就能访问各种操作,这些操作要在网络初始化时注册。socket、
bind、connect、send和recv等系统接口超有能力,不仅支持你上网(AF INET),还支持你
的应用程序之间的通信(AF_ UNIX),以及内核与用户程序之间的通信(AF- NETLINK),
就连比较少见的协议,例如AF_IPX也支持。有一点需要注意的是,IP层不完全在TCP之
下,应用程序可以绕过TCP层而直接5IP层协作,比如ping命令。
下面我们来揭开网络系统调用的神秘面纱,请看图11.2。
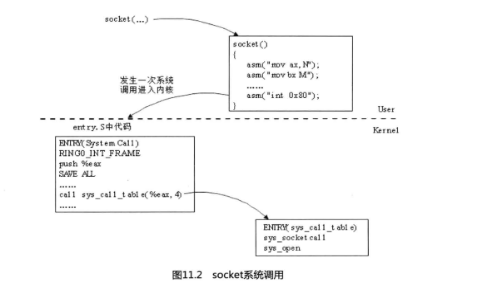
我们平时编写的网络程序运行在用户模式( user mode)下,它有自己的内存映射(即地
址空间)。而TCP/IP栈运行在内核模式(kemel mode)下,在不同的地址空间里运行。这样分开的好处是系统调用主要考虑如何更好地满足实时性和多处理机的并行处理,而用户的主要精力就是把自己的网络应用逻辑做好。那么应用层程序与Linux系统内核如何进行交互通
信的呢?让我来告诉你这个秘密Ⅱ巴。它是通过一个软中断,中断号是0x80。通过int 0x80指令就可使用内核资源了。不过,通常应用程序都是使用具有标准接口定义的C函数库。它间接使用内核的系统调用,即应用程序调用C函数库中的函数,C函数库中再通过int Ox80进行系统调用。所以,系统调用过程是这样的:
1. 应用程序调用glibc中的函数;
2. glibc中的函数引用系统调用宏;
3. 系统调用宏中使用int Ox80完成系统调用并返回。
程序-》glibc-》系统调用宏-》系统调用
在上面系统调用的步骤中出现了汇编语言。汇编是最接近计算机底层的语言,学习汇编
能让你明白底层编程的原理。具有汇编知识才可能真正看懂内核启动部分的伐码。如果你想
进·步提高自己的内力,学习和使用汇编还是很有用的。
11 .4.2凝神静态:sockfs文件系统
Linux的文件无处不在,设备有设备文件,嘲络有网络文件……创建一个套接口就是在sockfs文件系统中创建一个特殊文件,并建立起为实现套接口功能的相关数据结构。
首先sock_init函数将socket注册为一个伪文件系统,并mount在相应的mount点上。挂载完系统后,就要创建socket了。
每次创建一个socket,都要依赖于当前的protocol family类型的。
protocol family类型有AF_INET、AF_NETLINK和AF_UNIX等。在内核中,每种类型的protocol family都会有一个相对应的net_proto_family结构,然后将这个结构注册到内核的net_families数组中。我们创建socket的时候,实际上就是调用这个数组来创建socket。
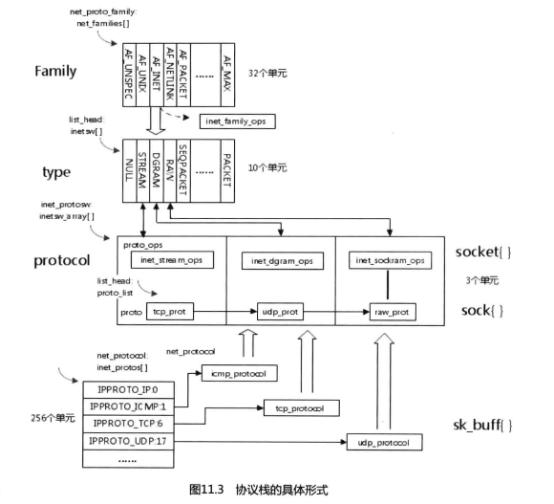
如图11.3所示,每个协议簇和相应的套接口都对应有好多种组合,在协议簇的实现中保存了一个相应的结构来保存这些组合。通过family和套接口类型来得到这个结构,并赋值
给sock。需要郑重声明的是内核里的socket和sock是两个不同的数据结构,其中socket是
一个general BSD socket,也就是应用程序和4层协议之间的一个接口,屏蔽掉了相关的4
层协议部分。而sock结构保存了socket所需要使用的4层协议的全部相关信息。socket和
sock这两个结构体现了接口和实现分开的策略,Ross Bir00(① Linux内核级网络代码最早开发者。)还有意将socket和sock这两个结
构都保存了对方的联系方式——对方的指针,使得开发者很容易地从一方存取另一方。一个
完整的socket包含两方面的信息:socket和inode。
struct socket_alloc (
struct socket socket;
struct inode vfs_inode;
);
当你open 一个socket的时候,系统会返回一个文件描述符fd,如何找到其对应的fd呢?我们可以使用“netstat -tunp”查看在文件中打开的tcp以及udp连接的进程以及本地和远程的IP地址:
# netstat -taunp Active Internet connections (only servers) Proto Recv-QSend-Q Local Address Foreign Address State PID/Program name tcp 0 0 0. O . 0 . 0 :22 0.0.0.0 : * LISTEN 4024/sshd ...... tcp 0 0 :::22 : ::* LISTEN 4024/sshd
sshd所对应的PID是4024,然后在/proc目录下通过find命令就可以找到相应的fd。
# find /proc 2>/dev/null I grep "/4024/fd/1" /proc/4024/task/4024/fd/1 /proc/4024/fd/1
ll /proc/4024/fd total 0 lrwx------ 1 root root 64 Mar 30 10:24 0 -> /dev/null 前三个文件描述符固定是标准输入 标准输出 标准错误 lrwx------ 1 root root 64 Mar 30 10:24 1 -> /dev/null lrwx------ 1 root root 64 Mar 30 10:24 2 -> /dev/null lrwx------ 1 root root 64 Mar 30 10:24 3 -> socket:[11669] lrwx------ 1 root root 64 Mar 30 10:24 4 -> socket:[11671] [root@steven ~]# cat /proc/4024/fd/3 cat: /proc/1531/fd/3: No such device or address [root@steven ~]# cat /proc/4024/fd/4 cat: /proc/1531/fd/4: No such device or address
参考 lsof命令:http://www.cnblogs.com/MYSQLZOUQI/p/4856977.html
11 .4.3气沉丹田:sk_buff
sk_ buff是Linux网络代码中最重要的数据结构,含义为“套接字缓冲区”,用于在Linux
网络子系统中的各层之间传递数据,相当于Linux TCP/IP的“丹田”所在。它的创建者是
Linux的二号功臣Alan Cox。我搜索了一下内核代码,发现有近八百处打了Alan Cox的标签。
他原创了许多Linux下的网络子系统的程序,并将编码提供给不同的内核进行发布。可以说
没有他,就没有现在的Linux系统,没有Linux系统上跑的TCP/IP协议。
一个好的系统离不开好的数据绪构,sk_buff提供很多成员变量供网络代码中各个子系统方便快捷地使用。sk_buff生命开始于网卡驱动接收函数,结束于socket应用层接口
① Linux内核级网络代码最早开发者。
(sock->port->sendmsg),也就是在接收和发送报文时Linux为sk_buff申请一整块内存空间来放这个结构。结构里的众多指针定义了不同协议的包头,使得协议回溯、向前查找都可以直接进行。在实现中还包含了各种各样的复制技巧,比如:克隆、共享数据、共享skb_buff等,节省了CPU操作时间。可能有的人抱怨sk buff结构定义过于庞大,有的变量在一些子系统中并不需要,但是计算机发展到今天,为了拥有更好的适应性和灵活性,牺牲部分空间是值得的。
由于操作系统每时每刻都有可能接收和发送大量报文,就需要频繁申请释放sk_buff。
sk_buff本身比较小,频繁申请释放内存就容易产生碎片。为了避免这个问题,sk_buff在申
请内存时也做了特殊的考虑,采用重复利用的原则。申请的skb buff内存在释放时并没有真
正释放,而是放在一个缓存区中,以后有新的skb_buff中请时,就从缓存区中提取。
虽然sk_buff里的参数和指针定义众多,但是由J:它的定义层次分明所以结构设计得清晰分明,其中主要有skb_buff链表参数、协议指针参数和数据缓存指针参数三大方面。掌握好这三个方面墓本上对它就有了整体的认识。图11.4的sk_ buff结构图对你理解sk_buff参数会有所帮助。
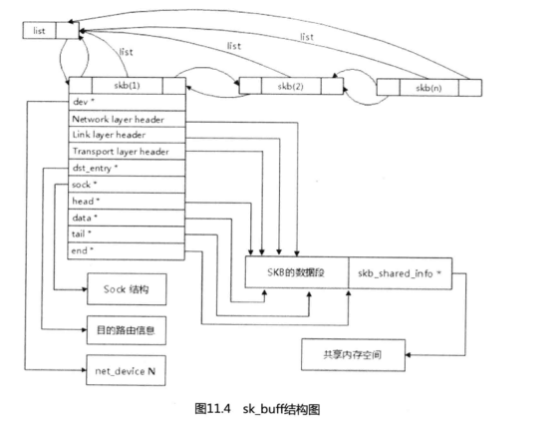
skb_buff像很多其他数据结构一样被链表化,其作用是方便查找或者是连接数据结构本
身。内核可以把sk buff组织成一个双向链表,结构要比常见的双向链表的结构要复杂一点。
就像任何一个双向链表一样,sk _buff中有两个指针next和prev,其中,next指向下一
个节点,而prev指向上一个节点。但是,这个链表还有另一个需求:每个sk_buff结构都必
须能够很快找到链表头节点。为了满足这个需求,在第一个节点前面会插入另一个结构
sk_ buff_ head。这是一个辅助节点,它的定义如下:
struct sk_buf f_head {
/*These two members must be first. */
struct sk_buff * next;
struct sk—buff * prev;
___ u32 qlen;
spinlock_t lock;
};
sk_buff和sk_buff_head的前两个元素是一样的:next和prev指针,尽管 sk_buff_head要比sk_buff小得多。它们可以放到同一个链表中,要求这两个指针必须放到结构定义的最前面。另外,相同的函数可以同样应用于sk_buff和 sk_buff_head,qlen域表示了当前的sk _buff链上包含多少个skb。lock域是自旋锁用于防止对链表的并发访问。
为了使这个数据结构更灵活,每个sk_buff结构都包含一个指向 sk_buff_head的指针。
这个指针的名字是list。图11.5会帮助你理解它们之间的关系。
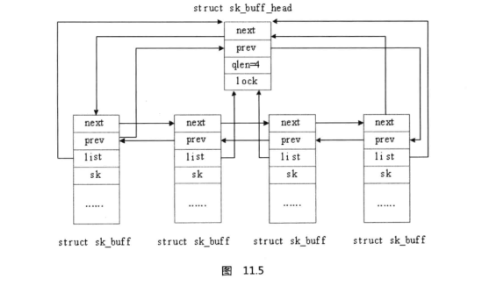
图11.6你也一定不会陌生,掌握链路层、网络层和传输层的数据格式是做好网络设计开发的基础。Sk_buff里的协议指针和它们的数据长度有关。
链路层帧格式
|
前导码 8 bytes |
目的mac地址6 bytes |
源mac地址 6 bytes |
帧类型 2 bytes |
帧数据 46-1500bytes |
Crc校验 4 bytes |
网络层数据包格式
|
4 bits |
4 bits |
8 bits |
3 bits |
13 bits |
|
Version |
IHL |
Type of Service |
Total Length |
|
|
Identification |
Flags |
Fragmentation Offset |
||
|
Time To Live |
Protocol |
Header Checksum |
||
|
Source Address |
||||
|
Destination Address |
||||
|
Options |
Padding |
|||
|
Data |
||||
传输层数据报文格式
|
4 bits |
6 bits |
6 bits |
16 bits |
|
Source Port |
Destination Port |
||
|
Sequence Number |
|||
|
Acknowledge Munber |
|||
|
Data Offset |
Reserved |
Code |
Window |
|
Checksum |
Urgent Pointer |
||
|
Options |
Padding |
||
|
Data |
|||
图11.6
sk_ buff定义了四个网络层次,依次为1、传输层、2、网络层、3、链路层和4、物理层,每个层次的
参数都是独立的变量。sk buff对协议层次并没有严格按照经典的网络协议划分,为了程序
处理的方便,TCP、UDP和ICMP分成一个层次,因为它们都是IP层协议号分出来的。
dev指向物理层,变量的类型是net_device,代表一个网络设备。dev的作用取决于这个数据包是准备发出的包还是刚接收的包。当收到一个包时,设备驱动会把sk_buff的dev指针指向收到这个包的设备的数据结构。当一个包被发送时,这个变量代表将要发送这个包的设备。在发送网络包时设置这个值的代码要比接收网络包时设置这个值的代码复杂。为什么呢?因为有些网络功能可以把多个网络设备组成一个虚拟的网络设备,这些设备没有和物理设备直接关联,并由一个虚拟网络设备驱动管理。当虚拟设备被使用时,dev指针指向虚拟设备的net_device结构。而虚拟设备驱动会在一组设备中选择一个设备并把dev指针修改为这个设备的net_device结构。因此,在某些情况下,指向传输设备的指针会在包处理过程中被改变。
transport_header、network_ header和mac_header分别是传输头、网络头以及mac头相对于sk_buff头的偏移。这三个成员为内核编程人员提供了更便利的获取传输层、网络层和MAC层头的偏移,偏移值的获取和设置是通过偏移接口函数来实现的。
sk_buff的数据缓存区有七个变量:len、data_ len、true_size、head、data、tail、end,下图可以帮你理解它们之间的联系:
Head data tail End
|
|
|
|
Skb_shared_info |
←h e a d r o o m → ← t a i l r o o m →
图11.7 sk_buff结构的数据指针
● len:全部的数据长度,它的计算公式为len= (tail - data)+ data_len。
● data_len:共享数据的长度,也就是skb_shared_ info结构里面保存的数据长度,可
以通过看data len的长度是否为0来判断这个skb buff是否线性化。
● true_size:这是缓冲区的总长度,包括sk buff结构和数据部分。如果申请一个len
字节的缓冲区,alloc_skb函数会把它初始化成len+sizeof(sk_buff)。
head、end、data、tail,它们表示缓冲区和数据部分的边界。在每一层申请缓冲区时,
它会分配比协议头或协议数据大的空间。head和end指向缓冲区的头部和尾部,而data和
tail指向实际数据的头部和尾部。
headroom是指skb->data与skb->head之间的内存空间。每一层在head和data之间填充协议头。
tailroom是指skb->end与skb->tail之间的内存空间。可以包含一个附加的头部,添加新
的协议数据。
每个skb_buff结构的尾部空间都包含一个skb_shared_info结构,在申请内存空间时特别加上sizeof(skb_shared_info)。skb->end代表数据段的结尾,同时也是指向共享数据的指针,
这样设计是有道理的。因为如果sk_buff没有数据就无所谓共享数据了。所以end指针不代
表是真正的结尾,它指向一个skb_ shared_ info结构。把end从char转换成skb shared_ info*
就能访问这个结构,进行paged data和分片的管理。Linux捉供一个宏来做这种转换:
#defne skb_shinfo(SKB) ((struct skb_shared_info *)(skb_end_pointer(SKB)))
在这里提醒大家一定要使用skb结构提供的宏或函数操作指针,自己移动指针很容易
出错。
在缓冲区数据的末尾,有一个数据结构skb_shared_info,它保存了数据块的附加信息。
这个数据结构紧跟在end指针所指的地址之后(end指针指示数据的末尾)。下面是这个结构的定义:
struct skb_shared_info { atomic_t dataref; unsigned int nr_frags; unsigned short tso_size; unsigned short tso_seqs; struct sk_buff *frag_list; skb_frag_t frags[ MAX_SKB_FRAGS]; };
dataref表示数据块的“用户”数,nf_frags、frag_list和frags用于存储IP分片。skb_is nonlinear函数用于测试一个缓冲区是否是分片的,而skb_linearize可以把分片组合成一个单一的缓冲区。组合分片涉及数据拷贝,它将严重影响系统性能。为了提高性能,有些网卡硬件可以计算L3和L4和校验和,甚至可以维护L4协议的状态机。
需要注意的是:sk_buff中没有指向skb_shared_info结构的指针。如果要访问这个结构,
就需要使用skb_info宏,这个宏简单地返回end指针:
#defrne_skb_shinfo(SKB) ((struct skb_shared_info*)((SKB)->end))
例如使用这个宏来增加结构中的某个成员变量的值:
skb_shinfo( skb) ->dataref++;
Skb_shared info结构也可以包含一个sk_buff的链表(链表名称是frag_list)。这个链表
在pskb_copy和skb_copy中的处理方式与frags数组的处理方式相同。
在include/linux/skbuff.h和net/core/skbuffc中每个函数基本上都有两个版本,名字分别
是do_something和_do_something。通常第一种函数是一个包装函数,它会在第二种函数的
基础上增加合法性检查或者锁。一般来说,类似_do_something的函数不能被直接调用。
操作函数分为内存操作函数、数据段操作函数和链表管理函数三大类,其中内存操作函
数有alloc_ skb、dev_alloc_skb、kfree_skb、dev_ kfree_ skb、skb_clone、pskb_copy、skb_copy
和skb_copy_expand等;数据段操作函数有skb_put、skb_push、skb_pull相skb_reserve等:
链表管理函数有skb_queue_head_init、skb_queue_head、skb_queue_tail、skb_dequeue、
skb_dequeue_ tail、skb_queue_purge和skb_queue_walk等。结合上面对参数的讲解,对照函数实现源码,操作函数的具体含义还是不难理解的,这里就不赘述了。
11.5 临战杂谈
再霸气的神功缺乏临战经验的话,也有可能被人揍得满头包。为了避免这种问题的发生,
我不得不列举一些我经历过的事儿。如果你不认同的话,就当我是闲扯吧。
11 .5.1 对UDP的错误的认识
我发现很多人不太爱用UDP,对UDP存有偏见,爱憎分明的我不得不为它吐吐槽。
比起TCP来,UDP的优势在于速度快,而且不需要维护数据流,还能防止意想不到的欺骗。
我遇到这么一个项目,在nginx上设计一个add-on模块做局域网转发。由于最终实现的服务部署在本机或局域网中,我建议通过UDP方式实现服务的调用。当时就有人跳起来跟我争论,反对使用UDP。理由是UDP是无连接的,容易丢包,有时序问题,不可靠。这是彻头彻尾的教条主义,没有调查研究就没有发言权!
首先,在本地或局域网中不存在时序问题。时序问题的产生是因为数据包可能走过不同路由。
局域网内不存在这种情况,也就不用理会它。另外我可以负责任地说,虽然UDP是无连接,
但它在局域网中传输丢包的概率是微乎其微的。局域网使用的交换机对数据有很强
的恢复功能。如果在局域网中你的程序出现丢包的现象,你还是先检查一下自己程序写得是
否合理。一般的丢包都是应用写得不合理造成的,比如接收不及时导致接收缓冲区满了,后
面的包覆盖了前面的包,从而导致‘丢包”。接收UDP数据包的函数尽量不要和处理UDP数据包的函教在一个线程,否则就可能导致收包不及时的问题发生。收包线程的全部工作就是不停地读,把接收完的数据放在队列中。
还有人提出峰值数据量过大会引起计算机忙而丢包。我做过24路1080p 30mbps码流的
视频直播服务,画面清晰不丢帧,没有马赛克。运算设计得简单,如果是CBR的视频流,
使用720mbps带宽,在干兆网环境下是没有任何问题的。到目前为止我做的转发服务还没有超过这个峰值数据量。有人使用tcpdump验证我的说法,向我反映即便是局域网也有“x
packets dropped by kernel”。但是造成这种丢包的原因是由于libpcap抓到包后,tcpdump上
层没有及时地取出,导致libpcap缓冲区溢出,从而覆盖了未处理包。虽然tcpdump工具显
示被kernel丢弃,但是并不是说真正是被Linux内核抛弃的,而是被其所使用的动态库libpcap
抛弃。这时候如果是你写的服务,还是可以正常获取数据的。当然我们是有办法来改善tcpdump上层的处理效率减少丢包。例如抓包时最小化抓取过滤范围,即通过指定网卡、端口、包流向、包大小来减少处理包的数量;添加-n参数,禁止反向域名解析;调节/proc/sys/net/core/rmem一default和/proc/sys/netjcore/rmem_max参数改变sk_ rcvbuf的大小等。
tcpdump
-nn :来源ip和目标ip都用数字显示
-i :指定网卡 默认是第一个网卡
host:可以写源ip 也可以写目标ip
port :指定端口
dst 192.168.31.147
src dst 192.168.31.147
可能还有人会问:“很多教科书上都说UDP容易丢包呀。”这要看在什么应用场景下。
不能生搬硬套。在经过路由器的情况有时是会出现丢包的。依我的实际经验,在过二三级路
由以后,由于数据流量繁忙和TTL等原因可能会出现丢包的现象。
所以凡涉及本机或局域网内通信的案例,都可以考虑使用UDP。因为这个东西无连接,
处理起来相当简单,性能极高。这种情况下使用TCP很浪费CPU资源。因为根本都不丢包,
每次TCP的流控还要评估网络环境。
11 .5.2事半功倍,调节内核参数①
Linux标准的发行版不可能知道你目前运行的网络环境,所以还得靠你自己利用可以调
节的内核参数动态优化TCP[IP栈。例如长连接会占用大量资源,在大并发的情况下,连接
过多将导致无数的连接失败。通常Apache采用短连接,nginx采用短连接,MySQI采用短
连接。但是短连接可能会导致TIME_ WAIT增多。TIME_WAIT的增多一般不会有太大的问题,但是大量的TIME—WAIT套接字也会把squid等网络应用给拖死。这时,调节几个内核参数就能搞定:
tw:time_wait # ehc0 1> /proc/sys/net/ipv4/tcp_tw_reuse # ehc0 1>/proc/sys/net/ipv4/tcp_tw_recycle # ech0 6000>/proc/sys/net/ipv4/tcp_max_tw_buckets
reuse是表示是否允许新的TCP连接重新应用处于TIME_WAIT状态的socket; recycle
是加速TIME_WAIT sockets回收;max _tw _buckets表示TIME_WAIT套接字的最大数量,如
果超过这个数字,TIME_WAIT饔接字将立刻被清除并打印警告信息。这些设置提高了处理
效率,还能把TIME_WAIT所占用内存控制在一定范围。
表11-3列出了一些内核可以调节的参数,帮助你了解内核参数的含义。在后面的章节
中,我会利用nginx的实际案例说明调节内核参数的重要作用。
TCP连接状态图
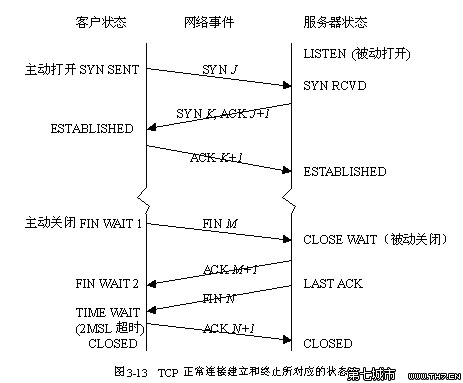
三次握手
客户端 主动syn sent 一次握手
服务器端 syn rcvd 一次握手
客户端 established 一次握手 syn+ack服务器端
服务器端 established
四次挥手
客户端 主动fin wait1 一次挥手
服务器端 close wait 一次挥手
客户端 fin wait2 一次挥手
客户端 time wait 一次挥手 last ack服务器端
服务器端 closed
表11-3 一些内核可以调节的参数
|
可调节的参数 |
默认值 |
选项说明 |
|
/proc/sys/net/core/rmem_ default |
"110592" |
定义默认的接收窗口大小 |
|
/proc/sys/net/core/rmem_max |
"110592" |
定义接收窗口的最大大小 |
|
/proc/sys/net/core/wmem_default |
"110592" |
定义默认的发送窗口大小 |
|
/proc/sys/net/core/wmem_max |
"110592" |
定义发送窗口的最大大小 |
|
/proc/sys/net/ipv4/tcp_window_scaling |
"1" |
要支持超过64KB的窗口,必须启用该值 |
|
/proc/sys/net/ipv4/tcp_sack |
"1" |
有选择地应答乱序接收到的报文来提高性能,让发送者只发送丢失的报文;对于广域网通信来说,这个选项应该启用,但是这会增加对CPU的占用 |
|
/proc/sys/net/ipv4/tcp_fack |
"1" |
启用转发应答 |
|
/proc/sys/net/ipv4/tcp_timestamps |
"1" |
以一种比重发超时更精确的方法来启用对RTT的计算;为了实现更好的性能应该启用这个选项 |
①有兴趣的话可参考czmmiao的博客http://czmmiao.iteye.comfblo∥1054966。
(续)
|
可调节的参数 |
默认值 |
选项说明 |
|
/proc/sys/neVipv4/tcp_mem |
“24576 32768 49152” |
确定TCP栈应该如何反映内存使用:每个值的单位都是内存页(通常是4KB)。第一个值是内存使用的下限。第二个值是内存压力模式开始对缓冲区使用应用压力的上限。第三个值是内存上限,超过 这个层次可以将报文丢弃,从而减少对内存的使用。对于较大的BDP可以增大这些值(但是要记住,其单位是内存页,而不是字节) |
|
/proc/sys/netjipv4/tcp_wmem |
“4096 16384 131072” |
自动调优定义每个socket使用的内存。第一个值是为socket的发送缓冲区分配的最少字节数。第二个值是默认值(该值会被wmem_default覆盖),缓冲区在系统负载不重的情况下可以增长到这个值。第三个值是发送缓冲区空间的最大字节数(该值会被wmem_max覆盖) |
|
/proc/sys/netjipv4/tcp_rmem |
“4096 87380 174760” |
与tcp_wmem类似,它表示的是为自动调优所使用的接收缓冲区的值 |
|
/proc/sys/net/ipv4/tcp_low_latency |
“0” |
允许TCP/IP栈适应在高吞吐量情况下低延时的情况;这个选项应该禁用 |
|
/proc/sys/net/ipv4/tcp_westwood |
“0” |
启用发送者端的拥塞控制算法,它可以维护对吞吐量的评估,并试图对带宽的整体利用情况进行优化;对于WAN通信来说应该启用这个选项 |
|
/proc/sys/net/ipv4/tcp_bic |
“1” |
为快速长距离网络启用Binary Increase (Congestion拥塞);这样可以更好地利用以GB速度进行操作的链接;对于WAN通信应该启用这个选项 |
从上表中我们了解了一些TCP/IP运行参数及其含义,在前面我们使用echo命令向/proc/sys/目录下的可写文件中设置数值。实际上还有代替这个功能的命令sysctl。sysctl是用
来在系统运作中查看及调整在/proc/sys/目录下的系统参数的,系统参数不仅包含TCP/IP堆栈设置,还包括与虚拟内存系统有关的高级选项。
首先我们使用sysctl读取一个指定变量的值,例如读取并发连接数kern.ipc.somaxconn,
命令如下:
# sysctl kern.ipc.Somaxconn
kern.ipc.Somaxconn: 3000
为了对在/proc/sys/目录下的可配置项有个快速的总体了解,输入sysctl—a命令就会产生一个大型综合列表供你参考。当然你也可以查看目录下的每个文件获取同样的信息,但那不是麻烦吗。
接下来我们设置一个指定参数的数值,可以直接用variable=value方式来实现,例如:
为了防止DOS攻击可用如下命令开启syscookies功能:
# sysctl net.inet.tcp.syncookies=1 #路径相当于/proc/sys/net/inet/tcp/syncookies
想必你发现了sysctl参数操作的时候不用写全整个路径,例如/proc/sys/net/ipv4/tcp_tw_
reuse文件,我们设置参数时使用net.ipv4.tcp_tw_reuse这种形式,目录斜杠被点符号代替,
proc.sys也假设已存在。
用sysctl设置的参数值只是临时起作用,如果你重启Linux系统,那么你刚用sysctl设
置的内核参数都会恢复原状。为了在系统启动时保留你的这些参数配置,你应该把对应的参
数值写入/etc/sysctl.conf中。每次系统启动时,init程序会运行/etc/rc.d/rc.sysinit胛本。这个
脚本包含了获取/etc/sysctl.conf配置参数以及执行sysctl命令向内核传递参数的代码,所以任何加入/etc/sysctl.conf的数值在每次系统启动后会生效。
读取内核参数 sysctl -a #读取全部内核参数 sysctl kern.ipc.Somaxconn #读取某个内核参数 设置内核参数 sysctl kern.ipc.Somaxconn=3000 echo 3000>/proc/sys/kern/ipc/Somaxconn 永久设置内核参数 /etc/sysctl.conf
2022-1-24
应用程序相连,比如程序和数据库相连,在unix系统上只能用谈Unix Domain Socket
unix上独有的,在tcp/ip普及之前,后来Linux保留了这种方式,所以很多数据库都也保留了unix domain socket方式,连接数据库
个人猜测
f


