


Spark常用函数讲解之Action操作
摘要:
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住 了数据集的逻辑操作
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
本发所讲函数
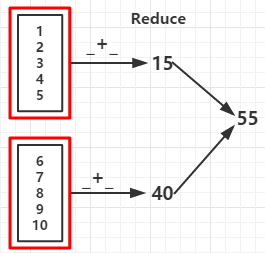
例1:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("reduce") val sc = new SparkContext(conf) val rdd = sc.parallelize(1 to 10,2) val reduceRDD = rdd.reduce(_ + _) val reduceRDD1 = rdd.reduce(_ - _) //如果分区数据为1结果为 -53 val countRDD = rdd.count() val firstRDD = rdd.first() val takeRDD = rdd.take(5) //输出前个元素 val topRDD = rdd.top(3) //从高到底输出前三个元素 val takeOrderedRDD = rdd.takeOrdered(3) //按自然顺序从底到高输出前三个元素 println("func +: "+reduceRDD) println("func -: "+reduceRDD1) println("count: "+countRDD) println("first: "+firstRDD) println("take:") takeRDD.foreach(x => print(x +" ")) println("\ntop:") topRDD.foreach(x => print(x +" ")) println("\ntakeOrdered:") takeOrderedRDD.foreach(x => print(x +" ")) sc.stop } |
输出:

func +: 55 func -: 15 //如果分区数据为1结果为 -53 count: 10 first: 1 take: 1 2 3 4 5 top: 10 9 8 takeOrdered: 1 2 3
(RDD依赖图:红色块表示一个RDD区,黑色块表示该分区集合,下同)
(RDD依赖图)
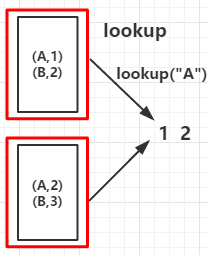
9.collectAsMap():作用于K-V类型的RDD上,作用与collect不同的是collectAsMap函数不包含重复的key,对于重复的key。后面的元素覆盖前面的元素
例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("KVFunc") val sc = new SparkContext(conf) val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3)) val rdd = sc.parallelize(arr,2) val countByKeyRDD = rdd.countByKey() val collectAsMapRDD = rdd.collectAsMap() println("countByKey:") countByKeyRDD.foreach(print) println("\ncollectAsMap:") collectAsMapRDD.foreach(print) sc.stop } |
输出:
countByKey: (B,2)(A,2) collectAsMap: (A,2)(B,3)
(RDD依赖图)
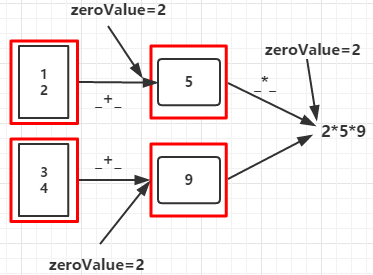
seqOp函数将每个分区的数据聚合成类型为U的值,comOp函数将各分区的U类型数据聚合起来得到类型为U的值
1 2 3 4 5 6 7 8 | def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("Fold") val sc = new SparkContext(conf) val rdd = sc.parallelize(List(1,2,3,4),2) val aggregateRDD = rdd.aggregate(2)(_+_,_ * _) println(aggregateRDD) sc.stop } |
输出:
90
步骤1:分区1:zeroValue+1+2=5 分区2:zeroValue+3+4=9
步骤2:zeroValue*分区1的结果*分区2的结果=90
(RDD依赖图)
12.fold(zeroValue:T)(op:(T,T) => T):通过op函数聚合各分区中的元素及合并各分区的元素,op函数需要两个参数,在开始时第一个传入的参数为zeroValue,T为RDD数据集的数据类型,,其作用相当于SeqOp和comOp函数都相同的aggregate函数
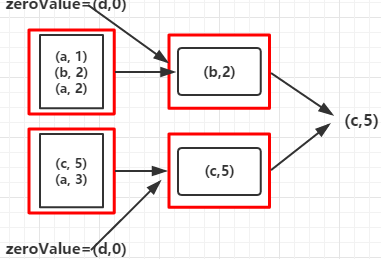
例3
1 2 3 4 5 6 7 8 | def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("Fold") val sc = new SparkContext(conf) val rdd = sc.parallelize(Array(("a", 1), ("b", 2), ("a", 2), ("c", 5), ("a", 3)), 2) val foldRDD = rdd.fold(("d", 0))((val1, val2) => { if (val1._2 >= val2._2) val1 else val2 }) println(foldRDD) } |
输出:
1 | c,5 |
其过程如下:
1.开始时将(“d”,0)作为op函数的第一个参数传入,将Array中和第一个元素("a",1)作为op函数的第二个参数传入,并比较value的值,返回value值较大的元素
2.将上一步返回的元素又作为op函数的第一个参数传入,Array的下一个元素作为op函数的第二个参数传入,比较大小
3.重复第2步骤
每个分区的数据集都会经过以上三步后汇聚后再重复以上三步得出最大值的那个元素,对于其他op函数也类似,只不过函数里的处理数据的方式不同而已
(RDD依赖图)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构