


Spark常用函数讲解之键值RDD转换
摘要:
RDD:弹性分布式数据集,是一种特殊集合 ‚ 支持多种来源 ‚ 有容错机制 ‚ 可以被缓存 ‚ 支持并行操作,一个RDD代表一个分区里的数据集
RDD有两种操作算子:
Transformation(转换):Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住 了数据集的逻辑操作
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
Ation(执行):触发Spark作业的运行,真正触发转换算子的计算
本系列主要讲解Spark中常用的函数操作:
1.RDD基本转换
2.键-值RDD转换
3.Action操作篇
本节所讲函数
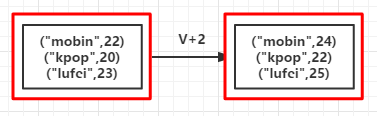
(例1):对每个的的年龄加2
1 2 3 4 5 6 7 8 9 10 | object MapValues { def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("map") val sc = new SparkContext(conf) val list = List(("mobin",22),("kpop",20),("lufei",23)) val rdd = sc.parallelize(list) val mapValuesRDD = rdd.mapValues(_+2) mapValuesRDD.foreach(println) }} |
输出:
(mobin,24) (kpop,22) (lufei,25)
(RDD依赖图:红色块表示一个RDD区,黑色块表示该分区集合,下同)
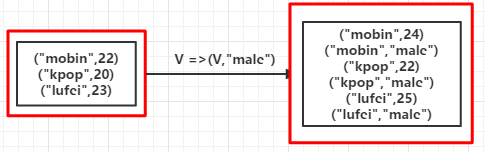
(例2):
1 2 3 4 | //省略<br>val list = List(("mobin",22),("kpop",20),("lufei",23))val rdd = sc.parallelize(list)val mapValuesRDD = rdd.flatMapValues(x => Seq(x,"male"))mapValuesRDD.foreach(println) |
输出:
(mobin,22) (mobin,male) (kpop,20) (kpop,male) (lufei,23) (lufei,male)
如果是mapValues会输出:
(mobin,List(22, male)) (kpop,List(20, male)) (lufei,List(23, male))
(RDD依赖图)
comineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions)
comineByKey(createCombiner,mergeValue,mergeCombiners)
createCombiner:在第一次遇到Key时创建组合器函数,将RDD数据集中的V类型值转换C类型值(V => C),
如例3:
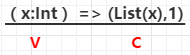
mergeValue:合并值函数,再次遇到相同的Key时,将createCombiner道理的C类型值与这次传入的V类型值合并成一个C类型值(C,V)=>C,
如例3:

mergeCombiners:合并组合器函数,将C类型值两两合并成一个C类型值
如例3:

partitioner:使用已有的或自定义的分区函数,默认是HashPartitioner
mapSideCombine:是否在map端进行Combine操作,默认为true
注意前三个函数的参数类型要对应;第一次遇到Key时调用createCombiner,再次遇到相同的Key时调用mergeValue合并值
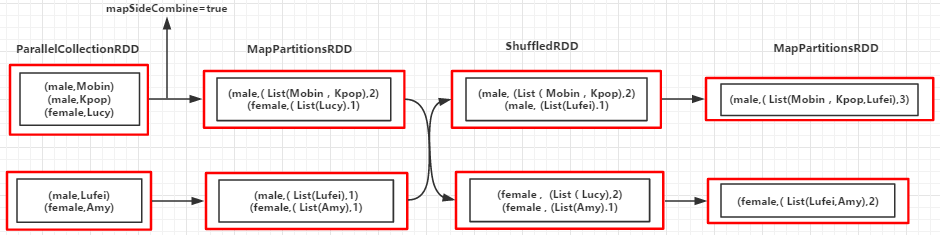
(例3):统计男性和女生的个数,并以(性别,(名字,名字....),个数)的形式输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | object CombineByKey { def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("combinByKey") val sc = new SparkContext(conf) val people = List(("male", "Mobin"), ("male", "Kpop"), ("female", "Lucy"), ("male", "Lufei"), ("female", "Amy")) val rdd = sc.parallelize(people) val combinByKeyRDD = rdd.combineByKey( (x: String) => (List(x), 1), (peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1), (sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2)) combinByKeyRDD.foreach(println) sc.stop() }} |
输出:
(male,(List(Lufei, Kpop, Mobin),3)) (female,(List(Amy, Lucy),2))
过程分解:

Partition1: K="male" --> ("male","Mobin") --> createCombiner("Mobin") => peo1 = ( List("Mobin") , 1 ) K="male" --> ("male","Kpop") --> mergeValue(peo1,"Kpop") => peo2 = ( "Kpop" :: peo1_1 , 1 + 1 ) //Key相同调用mergeValue函数对值进行合并 K="female" --> ("female","Lucy") --> createCombiner("Lucy") => peo3 = ( List("Lucy") , 1 ) Partition2: K="male" --> ("male","Lufei") --> createCombiner("Lufei") => peo4 = ( List("Lufei") , 1 ) K="female" --> ("female","Amy") --> createCombiner("Amy") => peo5 = ( List("Amy") , 1 ) Merger Partition: K="male" --> mergeCombiners(peo2,peo4) => (List(Lufei,Kpop,Mobin)) K="female" --> mergeCombiners(peo3,peo5) => (List(Amy,Lucy))
(RDD依赖图)
foldByKey(zeroValue,partitioner)(func)
foldByKey(zeroValue,numPartitiones)(func)
foldByKey函数是通过调用CombineByKey函数实现的
zeroVale:对V进行初始化,实际上是通过CombineByKey的createCombiner实现的 V => (zeroValue,V),再通过func函数映射成新的值,即func(zeroValue,V),如例4可看作对每个V先进行 V=> 2 + V
func: Value将通过func函数按Key值进行合并(实际上是通过CombineByKey的mergeValue,mergeCombiners函数实现的,只不过在这里,这两个函数是相同的)
例4:
1 2 3 4 5 | //省略 val people = List(("Mobin", 2), ("Mobin", 1), ("Lucy", 2), ("Amy", 1), ("Lucy", 3)) val rdd = sc.parallelize(people) val foldByKeyRDD = rdd.foldByKey(2)(_+_) foldByKeyRDD.foreach(println) |
输出:
(Amy,2) (Mobin,4) (Lucy,6)
先对每个V都加2,再对相同Key的value值相加。
例5
1 2 3 4 5 6 | //省略val arr = List(("A",3),("A",2),("B",1),("B",3))val rdd = sc.parallelize(arr)val reduceByKeyRDD = rdd.reduceByKey(_ +_)reduceByKeyRDD.foreach(println)sc.stop |
输出:
(A,5) (A,4)
(RDD依赖图)
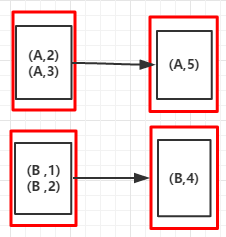
例6:
1 2 3 4 5 6 | //省略val arr = List(("A",1),("B",2),("A",2),("B",3))val rdd = sc.parallelize(arr)val groupByKeyRDD = rdd.groupByKey()groupByKeyRDD.foreach(println)sc.stop |
输出:
(B,CompactBuffer(2, 3)) (A,CompactBuffer(1, 2))
以上foldByKey,reduceByKey,groupByKey函数最终都是通过调用combineByKey函数实现的
7.sortByKey(accending,numPartitions):返回以Key排序的(K,V)键值对组成的RDD,accending为true时表示升序,为false时表示降序,numPartitions设置分区数,提高作业并行度
例7:
1 2 3 4 5 6 | //省略scval arr = List(("A",1),("B",2),("A",2),("B",3))val rdd = sc.parallelize(arr)val sortByKeyRDD = rdd.sortByKey()sortByKeyRDD.foreach(println)sc.stop |
输出:
(A,1) (A,2) (B,2) (B,3)
8.cogroup(otherDataSet,numPartitions):对两个RDD(如:(K,V)和(K,W))相同Key的元素先分别做聚合,最后返回(K,Iterator<V>,Iterator<W>)形式的RDD,numPartitions设置分区数,提高作业并行度
例8:
1 2 3 4 5 6 7 8 | //省略val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))val rdd1 = sc.parallelize(arr, 3)val rdd2 = sc.parallelize(arr1, 3)val groupByKeyRDD = rdd1.cogroup(rdd2)groupByKeyRDD.foreach(println)sc.stop |
输出:
(B,(CompactBuffer(2, 3),CompactBuffer(B1, B2))) (A,(CompactBuffer(1, 2),CompactBuffer(A1, A2)))
(RDD依赖图)
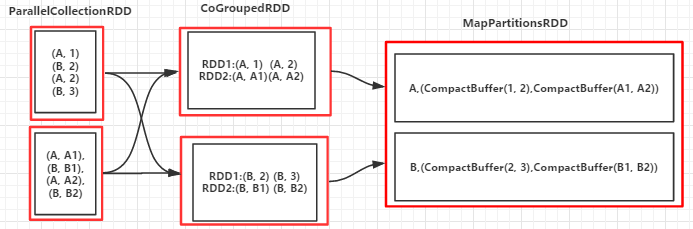
9.join(otherDataSet,numPartitions):对两个RDD先进行cogroup操作形成新的RDD,再对每个Key下的元素进行笛卡尔积,numPartitions设置分区数,提高作业并行度
例9
1 2 3 4 5 6 7 | //省略val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))val rdd = sc.parallelize(arr, 3)val rdd1 = sc.parallelize(arr1, 3)val groupByKeyRDD = rdd.join(rdd1)groupByKeyRDD.foreach(println) |
输出:
(B,(2,B1)) (B,(2,B2)) (B,(3,B1)) (B,(3,B2)) (A,(1,A1)) (A,(1,A2)) (A,(2,A1)) (A,(2,A2)
(RDD依赖图)
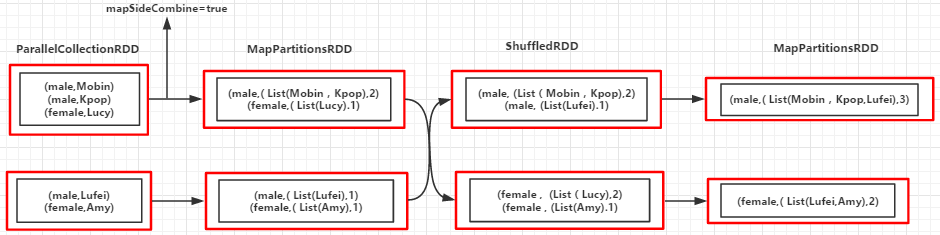
例10:
1 2 3 4 5 6 7 8 | //省略val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3),("C",1))val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"))val rdd = sc.parallelize(arr, 3)val rdd1 = sc.parallelize(arr1, 3)val leftOutJoinRDD = rdd.leftOuterJoin(rdd1)leftOutJoinRDD .foreach(println)sc.stop |
输出:
(B,(2,Some(B1))) (B,(2,Some(B2))) (B,(3,Some(B1))) (B,(3,Some(B2))) (C,(1,None)) (A,(1,Some(A1))) (A,(1,Some(A2))) (A,(2,Some(A1))) (A,(2,Some(A2)))
11.RightOutJoin(otherDataSet, numPartitions):右外连接,包含右RDD的所有数据,如果左边没有与之匹配的用None表示,numPartitions设置分区数,提高作业并行度
例11:
1 2 3 4 5 6 7 8 | //省略val arr = List(("A", 1), ("B", 2), ("A", 2), ("B", 3))val arr1 = List(("A", "A1"), ("B", "B1"), ("A", "A2"), ("B", "B2"),("C","C1"))val rdd = sc.parallelize(arr, 3)val rdd1 = sc.parallelize(arr1, 3)val rightOutJoinRDD = rdd.rightOuterJoin(rdd1)rightOutJoinRDD.foreach(println)sc.stop |
输出:
(B,(Some(2),B1)) (B,(Some(2),B2)) (B,(Some(3),B1)) (B,(Some(3),B2)) (C,(None,C1)) (A,(Some(1),A1)) (A,(Some(1),A2)) (A,(Some(2),A1)) (A,(Some(2),A2))


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构