
2、4、pandas库修改excel文件内容,把excel格式存为csv格式,csv格式换为html
pandas库修改excel文件内容,把excel格式存为csv格式,csv格式换为html
需要工具:pandas库(或者直接下载anaconda)
安装如下:到cmd处安装
1.先读取一个excel文件:
代码如下:
df = pd.read_excel('file:///D:/文档/Python成绩.xlsx', index_col=None, na_values=['NA']) # 读取excel文件中的数据
可用print检查是否读取成功
如:
print(df)
显示文件的数据,效果如下:

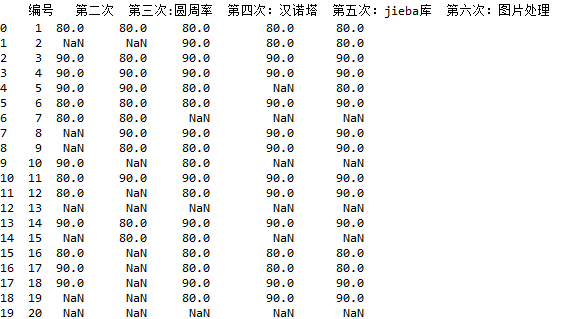
2、修改excel文件内容:
使用map()方法+字典,原地替换。
现在要将优秀改为90,良好改为80,及格改为60
代码如下:
df1=df[:] df1['第二次']=df1['第二次'].map({'优秀':90,'良好':80,'及格':60}) df1['第三次:圆周率']=df1['第三次:圆周率'].map({'优秀':90,'良好':80,'及格':60}) df1['第四次:汉诺塔']=df1['第四次:汉诺塔'].map({'优秀':90,'良好':80,'及格':60}) df1['第五次:jieba库']=df1['第五次:jieba库'].map({'优秀':90,'良好':80,'及格':60}) df1['第六次:图片处理']=df1['第六次:图片处理'].map({'优秀':90,'良好':80,'及格':60})
效果如下:
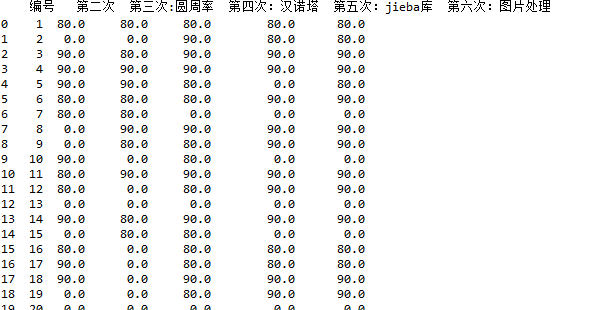
再将上述的NaN改为0
只需要用数据清洗之缺失数据填充fillna()就可以完成
运行代码如下:
df1=df1.fillna(0) print(df1)
效果如下:
最后将excel文件保存为csv文件
代码如下:
df1.to_csv('D:/文档\\thon.csv')
同时可以将csv文件保存为html格式
代码如下:
df1.to_csv('d:\\st.html')

