TCP/IP Four Layer Protocol Format Learning
相关学习资料
tcp-ip详解卷1:协议.pdf
目录
0. 引言 1. 应用层 3. 传输层 4. 网络层
0. 引言
协议中的网络字节序问题
在学习协议格式之前,有一点必须明白,否则我们在观察抓包数据的时候可能会产生疑惑:
1. 协议格式中的字段排布,最高位在左边,记为0bit;最低位在右边,记为31 bit。 2. 4个字节的32bit值以下面的次序传输: 1) 首先是0~7bit 2) 其次8~15bit 3) 然后16~23bit 4) 最后是24~31bit 这种传输次序称作"big endian字节序" 3. 由于TCP/IP首部中所有的二进制整数在网络中传输时都要求以这种次序,因此它又称作"网络字节序" 4. 以其他形式存储二进制整数的机器,如little endian格式,则必须在传输数据之前把首部转换成网络字节序
1. 应用层
0x1: NTP网络协议
NTP有两种不同类型的报文,一种是时钟同步报文,另一种是控制报文(用于网络管理),NTP基于UDP报文进行传输,使用的UDP端口号为123
1. 时钟同步报文

1. LI(Leap Indicator)(2 bits) 1) 值为"11"时表示告警状态,时钟未被同步 2) 为其他值时NTP本身不做处理 2. VN(Version Number)(3 bits): 表示NTP的版本号,目前的最新版本为3 3. Mode(3 bits): 表示NTP的工作模式。不同的值所表示的含义分别是: 1) 0: 未定义 2) 1: 主动对等体模式 3) 2: 表示被动对等体模式 4) 3: 表示客户模式 5) 4: 表示服务器模式 6) 5: 表示广播模式或组播模式 7) 6: 表示此报文为NTP控制报文(MODE_CONTROL) 8) 7: 预留给内部使用(MODE_PRIVATE) 4. Stratum(8 bits): 系统时钟的层数,取值范围为1~16,它定义了时钟的准确度,这也表明了整个NTP的架构是一种层次型的架构 1) 层数为1的时钟准确度最高 2) 准确度从1到16依次递减 3) 层数为16的时钟处于未同步状态,不能作为参考时钟 5. Poll(8 bits): 轮询时间,即两个连续NTP报文之间的时间间隔 6. Precision(8 bits): 系统时钟的精度 7. Root Delay(32 bits): 本地到主参考时钟源的往返时间 8. Root Dispersion(32 bits): 系统时钟相对于主参考时钟的最大误差 9. Reference Identifier(32 bits): 参考时钟源的标识 10. Reference Timestamp(64 bits): 系统时钟最后一次被设定或更新的时间 11. Originate Timestamp(64 bits): NTP请求报文离开发送端时发送端的本地时间 12. Receive Timestamp(64 bits): NTP请求报文到达接收端时接收端的本地时间 13. Transmit Timestamp(64 bits): 应答报文离开应答者时应答者的本地时间 14. Authenticator((optional)96 bits): 验证信息
Relevant Link:
http://bjtime.cn/info/view.asp?id=270 http://www.rfc-editor.org/rfc/rfc958.txt http://wenku.baidu.com/view/4a7e73c308a1284ac85043a8.html http://wiki.wireshark.org/SampleCaptures http://qgjie456.blog.163.com/blog/static/354513672010821241599/ http://www.cnblogs.com/TianFang/archive/2011/12/20/2294603.html
2. 控制报文
控制报文和时钟同步报文的区别仅仅在于"Mode"字段的区别,
1. 常规NTP时间同步报文 模式1~5 2. NTP控制报文 模式6,由ntpq使用 3. NTP mode 7 (MODE_PRIVATE) 由ntpdc查询和控制工具使用
对于控制报文来说,"Mode"字段的值为6
Relevant Link:
http://wiki.wireshark.org/NTP http://wiki.wireshark.org/SampleCaptures
0x2: DNS
1. DNS可以使用UDP和TCP;DNS协议要求客户端先使用UDP进行查询,若响应数据超过512字节,则可再次使用TCP进行查询得到完整响应(我曾尝试首次就用TCP查询,结果是部分服务器不响应TCP三次握手,部分建立TCP连接成功但不响应DNS查询) 2. DNS服务器使用的端口号为53 3. 虽然DNS协议支持一次查询多个域名,但大部分的DNS服务器的实现都不支持querycout > 1的情况,会返回Format error错误;想要一次查询多个,需要使用DNS扩展协议EDNS 4. DNS有两种类型的报文,分别是查询报文和响应报文,查询报文和响应报文都包含相同的首部

1. 首部

1 1 1 1 1 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | ID | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ |QR| Opcode |AA|TC|RD|RA| Z | RCODE | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | QDCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | ANCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | NSCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | ARCOUNT | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
各字段意义如下
1. 标识(16位): 客户端每次查询使用不同的标志号。服务端在响应中重复这个标识号 2. 标志(16位): 意义如下 3. QR(1位): 1) 0表示查询报文 2) 1表示响应报文 4. OpenCode(4位): 定义查询或响应的类型 1) 0: 标准 2) 1: 反向,即通过ip地址查询域名相关信息 3) 2: 服务器状态请求 5. AA(1位): 当值为1时,表示名字服务器是权限服务器 6. TC(1位): 当值为1时,表示响应已超过512字节并已截断为512字节 7. RD(1位): 当值为1时,表示客户端希望得到递归回答。响应报文中重复这个值 8. RA(1位): 当值为1时,表示可得到递归响应。只能在响应报文中置位(值为1) 9. 保留(3位): 保留字段,全部为0 10. rCode(4位): 表示在响应中的差错状态。只有权限服务器才能做出这个判断 1) 0: 无差错 2) 1: 格式差错 3) 2: 问题在域名服务器上 4) 3: 域参照问题 5) 4: 查询类型不支持 6) 5: 在管理上被禁止 7) 6~15: 保留 11. 问题记录数(16位): 问题部分的查询记录数 12. 回答记录数(16位): 回答记录数,在查询报文中值为0 13. 授权记录数(16位): 回答记录数,在查询报文中值为0 14. 附加记录数(16位): 回答记录数,在查询报文中值为0
2. 问题记录格式

1 1 1 1 1 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | | / QNAME / / / +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | QTYPE | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | QCLASS | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
各字段意义如下
1. 查询名字: 域名的可变长字段;其中计数字段指明每一节中的字符数。 2. 查询类型(16位) 1) A = 1: 32位的IPv6地址 2) NS = 2: 名字服务器 3) CNAME = 5: 规范名称 4) SOA = 6: 授权开始 5) WKS = 11: 熟知服务 6) PTR = 12: 指针 7) HINFO = 13: 主机信息 8) MX = 15: 邮件交换 9) AAAA = 28: IPv6地址 10) AXFR = 252: 请求传送完整区文件 11) ANY = 255: 请求所有记录 3. 查询类别(16位): 定义使用DNS的特定协议 1) AN = 1: 因为特 2) CSNET = 2: CSNET网络 3) CS = 3: COAS网络 4) HS = 4: 由MIT开发的Hesoid服务器
3. 资源记录格式

1 1 1 1 1 1 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | | / / / NAME / | | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | TYPE | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | CLASS | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | TTL | | | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+ | RDLENGTH | +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--| / RDATA / / / +--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
各字段意义如下
1. 域名(16位): 由于响应包含查询中完整的问题部分,为不重复记录域名;这里使用问题记录中域名的偏移量表示 2. 域类型(16位)与问题记录的查询类型字段相同 3. 域类别(16位): 与问题记录的查询类别字段相同 4. 生存时间(32位): 在该时间内,接收方可以将次回答保存在告诉缓存中,单位为秒 5. 资源数据长度(16位) 6. 资源数据(可变长): 值内容取决于类型字段的值,可以是 1) 数值 2) 域名 3) 偏移指针 4) 字符串
Relevant Link:
http://my.oschina.net/simplefocus/blog/215310 https://technet.microsoft.com/zh-cn/library/dd197470(v=ws.10).aspx https://en.wikipedia.org/wiki/Domain_Name_System https://www.ietf.org/rfc/rfc1035.txt
0x3: UTP(uTorrent Transport Protocol)
BitTorrent协议支持基于TCP或UTP网络协议进行数据传输,但是由于TCP协议是有连接的,需要先进行握手。在进行数据传输的过程中,每个种子会占有大量的TCP连接(没对peer-to-peer都要占用一对TCP连接),从而占有大量的用户带宽。这给其他需要高实时性的应用造成很大的网络压力。于是BitTorrent又支持UTP协议用来进行数据传输,这也是当前大部分BT下载客户端所采用的实现方式。UTP(uTorrent Transport Protocol)是基于UDP网络协议的,也就是无连接协议,采用这种协议进行数据交换,可以很容易进行带宽控制,不会造成网络拥堵
0 4 8 16 24 32 +-------+-------+---------------+---------------+---------------+ | type | ver | extension | connection_id | +-------+-------+---------------+---------------+---------------+ | timestamp_microseconds | +---------------+---------------+---------------+---------------+ | timestamp_difference_microseconds | +---------------+---------------+---------------+---------------+ | wnd_size | +---------------+---------------+---------------+---------------+ | seq_nr | ack_nr | +---------------+---------------+---------------+---------------+
1. type: 数据包类型 1) 0--带负载数据包,就是通常在连接建立后,上传数据或下载数据的包 2) 1--连接结束数据包,结束一个连接 3) 2--数据回应包,当一个peer收到一个带负载数据包后,会回一个ACK包,来表示这个包已正确接收,有点类似于TCP的SYN的感觉,但是这个是在UDP包的数据段做连接控制(基于UDP实现的伪ACK机制) 4) 3--重置连接 5) 4--开始一个连接 2. ver: 协议版本,通常为1 3. extension: 扩展段,用于支持BEPs 4. connection_id: 连接id,同一个连接id的数据包属于一个连接,一般每两个peer之间会开两个连接,一个用于发,一个用于收 5. timestamp_microseconds: 包的发送时间 6. timestamp_difference_microseconds: 对于当前连接,最近收到的包时间和当前要发送的包之间的时间间隔 7. wnd_size: 发送方当前剩余窗口大小,用于进行速度和带宽控制。BitTorrent协议中每一个发出去的数据包,都要求接收方回一个ACK包。而一个peer的窗口大小是指当前发送出去,但还没有收到回应的包的总大小,单位为字节。每一个peer都一个最大窗口值和一个窗口大小上限值。当wnd_size小于最小UTP包大小的时候,发送方会停止发送数据包,或调整每个数据包的数据负载大小 8. seq_nr: 相对于一个连接,数据包的序列号,以一个包为计数单位 9. ack_nr: 发送方最近接收到的包的序列号
Relevant Link:
http://www.bittorrent.org/beps/bep_0029.html
0x4: SSDP(Simple Service Discovery Protocol)
SSDP 简单服务发现协议,是应用层协议,是构成UPnP(通用即插即用)技术的核心协议之一。它为网络客户端(network client)提供了一种发现网络服务(network services)的机制,采用基于通知和发现路由的多播方式实现
简单服务发现协议提供了在局部网络里面发现设备的机制。控制点(也就是接受服务的客户端)可以通过使用简单服务发现协议,根据自己的需要查询在自己所在的局部网络里面提供特定服务的设备。设备(也就是提供服务的服务器端)也可以通过使用简单服务发现协议,向自己所在的局部网络里面的控制点声明它的存在

1. 实现
简单服务发现协议是在HTTPU和HTTPMU的基础上实现的协议
1. 按照协议的规定,当一个控制点(客户端)接入网络的时候,它可以向一个特定的多播地址的SSDP端口使用M-SEARCH方法发送"ssdp:discover"消息。当设备监听到这个保留的多播地址上由控制点发送的消息的时候,设备会分析控制点请求的服务,如果自身提供了控制点请求的服务,设备将通过单播的方式直接响应控制点的请求 2. 类似的,当一个设备接入网络的时候,它应当向一个特定的多播地址的SSDP端口使用NOTIFY方法发送"ssdp:alive"消息。控制点根据自己的策略,处理监听到的消息。考虑到设备可能在没有通知的情况下停止服务或者从网络上卸载,"ssdp:alive"消息必须在HTTP协议头CACHE-CONTROL里面指定超时值,设备必须在约定的超时值到达以前重发"ssdp:alive"消息。如果控制点在指定的超时值内没有再次收到设备发送的"ssdp:alive"消息,控制点将认为设备已经失效 3. 当一个设备计划从网络上卸载的时候,它也应当向一个特定的多播地址的SSDP端口使用NOTIFY方法发送"ssdp:byebye"消息。但是,即使没有发送"ssdp:byebye"消息,控制点也会根据"ssdp:alive"消息指定的超时值,将超时并且没有再次收到的"ssdp:alive"消息对应的设备认为是失效的设备 4. 在IPv4环境,当需要使用多播方式传送相关消息的时候,SSDP一般使用多播地址239.255.255.250和UDP端口号1900。根据互联网地址指派机构的指派,SSDP在IPv6环境下使用多播地址FF0x::C,这里的X根据scope的不同可以有不同的取值
2. 协议内容解析
SSDP消息分为设备查询消息、设备通知消息两种,通常情况下,使用更多地是设备查询消息
设备查询消息
M-SEARCH * HTTP/1.1 HOST: 239.255.255.250:1900 MAN: "ssdp:discover" MX: 5 ST: ssdp:all 1. 其中第一行是消息头,固定 2. HOST对应的是广播地址和端口,239.255.255.250是默认SSDP广播ip地址,1900是默认的SSDP端口 3. MAN后面的ssdp:discover为固定 4. MX为最长等待时间 5. ST: 查询目标,它的值可以是 1) upnp:rootdevice 仅搜索网络中的根设备 2) uuid:device-UUID 查询UUID标识的设备 3) urn:schemas-upnp-org:device:device-Type:version 查询device-Type字段指定的设备类型,设备类型和版本由UPNP组织定义 4) ssdp:all
响应消息
在设备接收到查询请求并且查询类型(ST字段值)与此设备匹配时,设备必须向多播地址239.255.255.250:1900回应响应消息。一般形如
HTTP/1.1 200 OK / NOTIFY * HTTP/1.1(设备通知的HTTP头) CACHE-CONTROL: max-age = seconds until advertisement expires DATE: when reponse was generated EXT: LOCATION: URL for UPnP description for root device SERVER: OS/Version UPNP/1.0 product/version ST: search target //不常用的设备通知HTTP回包增加了下列的字段 NT 在此消息中,NT头必须为服务的服务类型。 NTS 表示通知消息的子类型,必须为ssdp:alive或者ssdp:byebye USN 表示不同服务的统一服务名,它提供了一种标识出相同类型服务的能力
Relevant Link:
http://blog.csdn.net/lilypp/article/details/6631951
http://baike.baidu.com/link?url=GsvncL_i_vpV3cRwwYFBju3MgD6sVgDcFx-XqmyybypBXYMTeV5ExjnxoIS0YNWS5ervCdHOtoqqJWwzsL5H2q
http://www.tuicool.com/articles/nUjmMf
3. 传输层
0x1: ICMP Internet控制报文协议
尽管对于ICMP协议属于网络层还是传输层有很多争议,但是从学习协议的严谨性上来说,ICMP应该算是传输层协议,因为ICMP数据报需要被包装在IP数据报的数据部分进行发送,所以ICMP也应该算是IP协议的一个上层协议。
ICMP属于传输层协议。ICMP 的正式规范参见RFC 792 [Posterl 1981b]

和其他大多数协议一样,ICMP有很多种数据报类型,它们的协议格式也不尽相同,我们按照类型的大分类来逐一学习
在ICMP数据报中,头部的类型(8bit)、和代码(8bit)字段决定了这个ICMP数据报的准确类型。类型和代码各占8bit,先决定类型,然后看代码,它们共同决定了这个ICMP数据报的类型

Destination Unreachable Message(目的不可达)

1. 类型 类型码为3 2. 代码 1) 0: 网络不可达 2) 1: 主机不可达 3) 2: 协议不可达 4) 3: 端口不可达 5) 4: 需要进行分片但设置了不分片bit 6) 5: 源站路由失败 7) 6: 目的网络不认识 8) 7: 目的主机不认识 9) 8: 源主机被隔离(作废不用) 10) 9: 目的网络被强制禁止 11) 10: 目的主机被强制禁止 12) 11: 由于服务类型TOS,网络不可达 13) 12: 由于服务类型TOS,主机不可达 14) 13: 由于过滤,通信被强制禁止 15) 14: 主机越权 16) 15: 优先权中止生效 3. 校验和 4. 4字节的unused字段,置零 5. 原始IP数据报的头部+64bit的数据部分
当发送一份ICMP差错报文时,报文始终包含IP的首部和产生ICMP差错报文的IP数据报的前8个字节(64bit)。这样,接收ICMP差错报文的模块就会把它与某个特定的协议(根据IP数据报首部中的
协议字段来判断)和用户进程(根据包含在IP数据报前8个字节中的TCP或UDP报文首部中的TCP或UDP端口号来判断)联系起来
Time Exceeded Message(超时)

1. 类型 类型码为11 2. 代码 1) 0: 传输期间生存期为0 2) 1: 在数据报组装期间生存期为0 3. 校验和 4. 4字节的unused字段,置零 5. 原始IP数据报的头部+64bit的数据部分 当发送一份ICMP差错报文时,报文始终包含IP的首部和产生ICMP差错报文的IP数据报的前8个字节(64bit)。这样,接收ICMP差错报文的模块就会把它与某个特定的协议(根据IP数据报首部中的
协议字段来判断)和用户进程(根据包含在IP数据报前8个字节中的TCP或UDP报文首部中的TCP或UDP端口号来判断)联系起来
Parameter Problem Message(参数错误)

1. 类型 类型码为12 2. 代码 1) 0: 错误信息的指针 3. 校验和 4. 4字节的unused字段,置零 5. 原始IP数据报的头部+64bit的数据部分 当发送一份ICMP差错报文时,报文始终包含IP的首部和产生ICMP差错报文的IP数据报的前8个字节(64bit)。这样,接收ICMP差错报文的模块就会把它与某个特定的协议(根据IP数据报首部中的
协议字段来判断)和用户进程(根据包含在IP数据报前8个字节中的TCP或UDP报文首部中的TCP或UDP端口号来判断)联系起来
Source Quench Message(源站被抑制)

1. 类型 类型码为4 2. 代码 1) 0: 源站被抑制 3. 校验和 4. 4字节的unused字段,置零 5. 原始IP数据报的头部+64bit的数据部分 当发送一份ICMP差错报文时,报文始终包含IP的首部和产生ICMP差错报文的IP数据报的前8个字节(64bit)。这样,接收ICMP差错报文的模块就会把它与某个特定的协议(根据IP数据报首部中的
协议字段来判断)和用户进程(根据包含在IP数据报前8个字节中的TCP或UDP报文首部中的TCP或UDP端口号来判断)联系起来
Redirect Message(重定向)

1. 类型 类型码为5 2. 代码 1) 0: 对网络重定向 2) 1: 对主机重定向 3) 2: 对服务类型和网络重定向 4) 3: 对服务类型和主机重定向 3. 校验和 4. Gateway Internet Address 指明重定向后的IP地址 5. 原始IP数据报的头部+64bit的数据部分 当发送一份ICMP差错报文时,报文始终包含IP的首部和产生ICMP差错报文的IP数据报的前8个字节(64bit)。这样,接收ICMP差错报文的模块就会把它与某个特定的协议(根据IP数据报首部中的
协议字段来判断)和用户进程(根据包含在IP数据报前8个字节中的TCP或UDP报文首部中的TCP或UDP端口号来判断)联系起来
对于ICMP Redirect重定向数据报,我们需要注意的,攻击者可以针对指定主机或者路由器发送ICMP Redirect数据报,来强制更新目标主机或路由器的"网关设置",从而劫持目标主机的原始流量。
http://insecure.org/sploits/arp.games.html
Echo or Echo Reply Message(ping)

1. 类型 1) 0: 回显应答 2) 8: 回显请求 2. 代码 0 3. 校验和 5. Identifier、Sequence Number 发送方用它们对每次的echo和reply进行匹配 6. 数据
Timestamp or Timestamp Reply Message(ICMP时间戳请求与应答)

ICMP时间戳请求允许系统向另一个系统查询当前的时间。返回的建议值是自午夜开始计算的毫秒数,协调的统一时间(Coordinated Universal Time, UTC)
1. 类型 1) 13: 发送时间戳 2) 14: 返回时间戳 2. 代码 0 3. 校验和 5. Identifier、Sequence Number 发送方用它们对每次的echo和reply进行匹配 6. Originate Timestamp 请求端填写发起时间戳,然后发送报文 7. Receive Timestamp 应答系统收到请求报文时填写接收时间戳 8. Transmit Timestamp 在 发送应答时填写发送时间戳
0x2: TCP(Transmission Control Protocol)
1. TCP用于从应用程序到网络的数据传输控制 2. TCP负责在数据传送之前将它们分割为IP包(面向应用层提供65535bytes的载荷空间,但是受限于下层网络层IP协议的限制,需要根据MTU进行分包),然后在它们到达的时候将它们重组 3. TCP是面向连接的通信协议,通过三次握手建立连接,通讯完成时要拆除连接,由于TCP是面向连接的所以只能用于端到端的通讯 4. TCP提供的是一种可靠的数据流服务,采用"带重传的肯定确认"技术来实现传输的可靠性。TCP还采用一种称为"滑动窗口"的方式进行流量控制,所谓窗口实际表示接收能力,用以限制发送方的发送速度 5. 如果IP数据包中有已经封好的TCP数据包,那么IP将把它们向"上"传送到TCP层。TCP将包排序并进行错误检查,同时实现虚电路间的连接。TCP数据包中包括序号和确认,所以未按照顺序收到的包可以被排序,而损坏的包可以被重传 6. TCP将它的信息送到更高层的应用程序,例如Telnet的服务程序和客户程序。应用程序轮流将信息送回TCP层,TCP层便将它们向下传送到IP层,设备驱动程序和物理介质,最后到接收方 7. 面向连接的服务(例如Telnet、FTP、rlogin、X Windows和SMTP)需要高度的可靠性,所以它们使用了TCP。DNS在某些情况下使用TCP(发送和接收域名数据库),但使用UDP传送有关单个主机的信息
1. TCP segment structure
Transmission Control Protocol accepts data from a data stream, divides it into chunks(根据MTU), and adds a TCP header creating a TCP segment. The TCP segment is then encapsulated into an Internet Protocol (IP) datagram, and exchanged with peers.
Processes transmit data by calling on the TCP and passing buffers of data as arguments. The TCP packages the data from these buffers into segments and calls on the internet module(例如IP) to transmit each segment to the destination TCP
A TCP segment consists of a segment header and a data section. The TCP header contains 10 mandatory fields, and an optional extension field (Options, pink background in table).
The data section follows the header. Its contents are the payload data carried for the application. The length of the data section is not specified in the TCP segment header. It can be calculated by subtracting the combined length of the TCP header and the encapsulating IP header from the total IP datagram length (specified in the IP header).
| Offsets | Octet | 0 | 1 | 2 | 3 | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Octet | Bit | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| 0 | 0 | Source port | Destination port | ||||||||||||||||||||||||||||||
| 4 | 32 | Sequence number | |||||||||||||||||||||||||||||||
| 8 | 64 | Acknowledgment number (if ACK set) | |||||||||||||||||||||||||||||||
| 12 | 96 | Data offset | Reserved 0 0 0 |
N S |
C W R |
E C E |
U R G |
A C K |
P S H |
R S T |
S Y N |
F I N |
Window Size | ||||||||||||||||||||
| 16 | 128 | Checksum | Urgent pointer (if URG set) | ||||||||||||||||||||||||||||||
| 20 ... | 160 ... |
Options (if data offset > 5. Padded at the end with "0" bytes if necessary.) ... |
|||||||||||||||||||||||||||||||
1. Source port (16 bits): identifies the sending port 2. Destination port (16 bits): identifies the receiving port 3. Sequence number (32 bits): has a dual role: 1) If the SYN flag is set (1), then this is the initial sequence number. The sequence number of the actual first data byte and the acknowledged number in the corresponding ACK are then this sequence number plus 1. 2) If the SYN flag is clear (0), then this is the accumulated sequence number of the first data byte of this segment for the current session. 4. Acknowledgment number (32 bits) if the ACK flag is set then the value of this field is the next sequence number that the receiver is expecting. This acknowledges receipt of all prior bytes (if any). The first ACK sent by each end acknowledges the other end's initial sequence number itself, but no data. 5. Data offset (4 bits) specifies the size of the TCP header in 32-bit words. The minimum size header is 5 words and the maximum is 15 words thus giving the minimum size of 20 bytes and maximum of 60 bytes, allowing for up to 40 bytes of options in the header. This field gets its name from the fact that it is also the offset from the start of the TCP segment to the actual data. 6. Reserved (3 bits): for future use and should be set to zero 7. Flags (9 bits) (aka Control bits): contains 9 1-bit flags 1) NS (1 bit) – ECN-nonce concealment protection (experimental: see RFC 3540). 2) CWR (1 bit) – Congestion Window Reduced (CWR) flag is set by the sending host to indicate that it received a TCP segment with the ECE flag set and had responded in congestion control mechanism (added to header by RFC 3168). 3) ECE (1 bit) – ECN-Echo has a dual role, depending on the value of the SYN flag. It indicates: 3.1) If the SYN flag is set (1), that the TCP peer is ECN capable. 3.2) If the SYN flag is clear (0), that a packet with Congestion Experienced flag set (ECN=11) in IP header received during normal transmission (added to header by RFC 3168). This serves as an indication of network congestion (or impending congestion) to the TCP sender. 4) URG (1 bit) – indicates that the Urgent pointer field is significant 5) ACK (1 bit) – indicates that the Acknowledgment field is significant. All packets after the initial SYN packet sent by the client should have this flag set. 6) PSH (1 bit) – Push function. Asks to push the buffered data to the receiving application. 7) RST (1 bit) – Reset the connection 8) SYN (1 bit) – Synchronize sequence numbers. Only the first packet sent from each end should have this flag set. Some other flags and fields change meaning based on this flag, and some are only valid for when it is set, and others when it is clear. 9) FIN (1 bit) – No more data from sender 8. Window size (16 bits) the size of the receive window, which specifies the number of window size units (by default, bytes) (beyond the segment identified by the sequence number in the acknowledgment field) that the sender of this segment is currently willing to receive (用于时间窗口流控制) 9. Checksum (16 bits): The 16-bit checksum field is used for error-checking of the header and data 10. Urgent pointer (16 bits): if the URG flag is set, then this 16-bit field is an offset from the sequence number indicating the last urgent data byte 11. Options (Variable 0–320 bits, divisible by 32) 12. Padding: The TCP header padding is used to ensure that the TCP header ends and data begins on a 32 bit boundary. The padding is composed of zeros.
2. Protocol operation
A TCP connection is managed by an operating system through a programming interface that represents the local end-point for communications, the Internet socket. During the lifetime of a TCP connection the local end-point undergoes a series of state changes
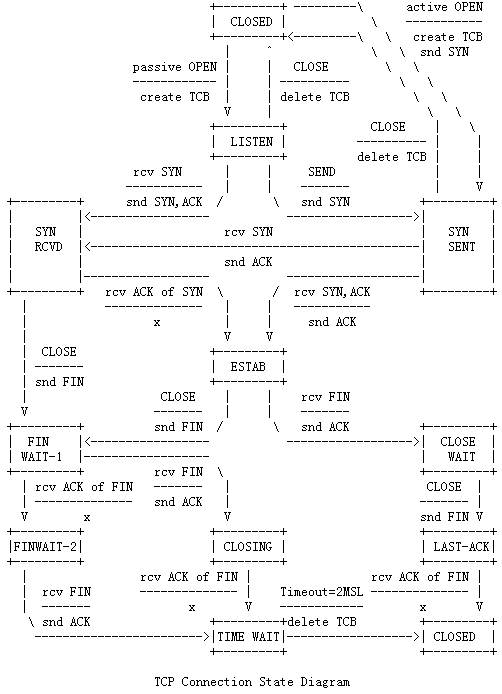
1. LISTEN: (server) represents waiting for a connection request from any remote TCP and port. 2. SYN-SENT: (client) represents waiting for a matching connection request after having sent a connection request. 3. SYN-RECEIVED: (server) represents waiting for a confirming connection request acknowledgment after having both received and sent a connection request. 4. ESTABLISHED: (both server and client) represents an open connection, data received can be delivered to the user. The normal state for the data transfer phase of the connection. 1) SYN: The active open is performed by the client sending a SYN to the server. The client sets the segment's sequence number to a random value A. 2) SYN-ACK: In response, the server replies with a SYN-ACK. The acknowledgment number is set to one more than the received sequence number i.e. A+1, and the sequence number that the server chooses for the packet is another random number, B. 3) ACK: Finally, the client sends an ACK back to the server. The sequence number is set to the received acknowledgement value i.e. A+1, and the acknowledgement number is set to one more than the received sequence number i.e. B+1. 5. FIN-WAIT-1: (both server and client) represents waiting for a connection termination request from the remote TCP, or an acknowledgment of the connection termination request previously sent. 6. FIN-WAIT-2: (both server and client) represents waiting for a connection termination request from the remote TCP. 7. CLOSE-WAIT: (both server and client) represents waiting for a connection termination request from the local user. 8. CLOSING: (both server and client) represents waiting for a connection termination request acknowledgment from the remote TCP. 9. LAST-ACK: (both server and client) represents waiting for an acknowledgment of the connection termination request previously sent to the remote TCP (which includes an acknowledgment of its connection termination request). 10. TIME-WAIT: (either server or client) represents waiting for enough time to pass to be sure the remote TCP received the acknowledgment of its connection termination request. [According to RFC 793 a connection can stay in TIME-WAIT for a maximum of four minutes known as two MSL (maximum segment lifetime).] 11. CLOSED: (both server and client) represents no connection state at all.
3. 糊涂窗口综合症
当发送端应用进程产生数据很慢、或接收端应用进程处理接收缓冲区数据很慢,或二者兼而有之;就会使应用进程间传送的报文段很小,特别是有效载荷很小。 极端情况下,有效载荷可能只有1个字节;而传输开销有40字节(20字节的IP头+20字节的TCP头) 这种现象就叫糊涂窗口综合症
1. 发送端求解 如果发送端为产生数据很慢的应用程序服务(典型的有telnet应用),例如,一次产生一个字节。这个应用程序一次将一个字节的数据写入发送端的TCP的缓存。如果发送端的TCP没有特定的指令,它就产生只包括一个字节数据的报文段。结果有很多41字节的IP数据报就在互连网中传来传去。解决的方法是防止发送端的TCP逐个字节地发送数据。必须强迫发送端的TCP收集数据,然后用一个更大的数据块来发送。发送端的TCP要等待多长时间呢?如果它等待过长,它就会使整个的过程产生较长的时延。如果它的等待时间不够长,它就可能发送较小的报文段,于是,Nagle找到了一个很好的解决方法,发明了Nagle算法。而他选择的等待时间是一个RTT,即下个ACK来到时 2. 接收端求解 接收端的TCP可能产生糊涂窗口综合症,如果它为消耗数据很慢的应用程序服务,例如,一次消耗一个字节。假定发送应用程序产生了1000字节的数据块,但接收应用程序每次只吸收1字节的数据。再假定接收端的TCP的输入缓存为4000字节。发送端先发送第一个4000字节的数据。接收端将它存储在其缓存中。现在缓存满了。它通知窗口大小为零,这表示发送端必须停止发送数据。接收应用程序从接收端的TCP的输入缓存中读取第一个字节的数据。在入缓存中现在有了1字节的空间。接收端的TCP宣布其窗口大小为1字节,这表示正渴望等待发送数据的发送端的TCP会把这个宣布当作一个好消息,并发送只包括一个字节数据的报文段。这样的过程一直继续下去。一个字节的数据被消耗掉,然后发送只包含一个字节数据的报文段 对于这种糊涂窗口综合症,即应用程序消耗数据比到达的慢,有两种建议的解决方法 1) Clark解决方法: Clark解决方法是只要有数据到达就发送确认,但宣布的窗口大小为零,直到或者缓存空间已能放入具有最大长度的报文段,或者缓存空间的一半已经空了。 2) 延迟确认ACK: 这表示当一个报文段到达时并不立即发送确认。接收端在确认收到的报文段之前一直等待,直到入缓存有足够的空间为止。延迟的确认防止了发送端的TCP滑动其窗口。当发送端的TCP发送完其数据后,它就停下来了。这样就防止了这种症状。迟延的确认还有另一个优点:它减少了通信量。接收端不需要确认每一个报文段。但它也有一个缺点,就是迟延的确认有可能迫使发送端重传其未被确认的报文段。可以用协议来平衡这个优点和缺点,例如现在定义了确认的延迟不能超过500毫秒
4. nagle算法
TCP/IP协议中,无论发送多少数据,总是要在数据前面加上协议头,同时,对方接收到数据,也需要发送ACK表示确认。为了尽可能的利用网络带宽,TCP总是希望尽可能的发送足够大的数据。(一个连接会设置MSS参数,因此,TCP/IP希望每次都能够以MSS尺寸的数据块来发送数据)。Nagle算法就是为了尽可能发送大块数据,避免网络中充斥着许多小数据块
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓"小段",指的是小于MSS尺寸的数据块,所谓"未被确认",是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到
/source/net/ipv4/tcp_output.c
1. It is full sized. (provided by caller in %partial bool): 如果包长度达到MSS,则允许发送 2. Or it contains FIN. (already checked by caller): 如果该包含有FIN,则允许发送 3. Or TCP_CORK is not set, and TCP_NODELAY is set: 设置了TCP_NODELAY选项(意在禁止nagle),则允许发送 4. Or TCP_CORK is not set, and all sent packets are ACKed: 未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送 5. 上述条件都未满足,但发生了超时(一般设置延迟ACK,一般为200ms),则立即发送
Nagle算法只允许一个未被ACK的包存在于网络,它并不管包的大小,因此它事实上就是一个扩展的停-等协议,只不过它是基于包停-等的,而不是基于字节停-等的。Nagle算法完全由TCP协议的ACK机制决定,这会带来一些问题,比如如果对端ACK回复很快的话,Nagle事实上不会拼接太多的数据包,虽然避免了网络拥塞,网络总体的利用率依然很低。另外,他是一个自适应的方法
Nagle算法是silly window syndrome(SWS)预防算法的一个半集,预防SWS不止nagle算法一个途径。SWS算法预防发送少量的数据,Nagle算法是其在发送方的实现,而接收方要做的时不要通告缓冲空间的很小增长,不通知小窗口,除非缓冲区空间有显著的增长。这里显著的增长定义为完全大小的段(MSS)或增长到大于最大窗口的一半
5. TCP握手交互Flag状态机
在Linux的协议栈实现中,tcp_rcv_state_process函数负责处理了TCP连接/释放的状态机
/net/ipv4/tcp_input.c
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb, const struct tcphdr *th, unsigned int len) { struct tcp_sock *tp = tcp_sk(sk); struct inet_connection_sock *icsk = inet_csk(sk); int queued = 0; tp->rx_opt.saw_tstamp = 0; switch (sk->sk_state) { case TCP_CLOSE: goto discard; case TCP_LISTEN: if (th->ack) return 1; if (th->rst) goto discard; if (th->syn) { if (th->fin) goto discard; if (icsk->icsk_af_ops->conn_request(sk, skb) < 0) return 1; /* Now we have several options: In theory there is * nothing else in the frame. KA9Q has an option to * send data with the syn, BSD accepts data with the * syn up to the [to be] advertised window and * Solaris 2.1 gives you a protocol error. For now * we just ignore it, that fits the spec precisely * and avoids incompatibilities. It would be nice in * future to drop through and process the data. * * Now that TTCP is starting to be used we ought to * queue this data. * But, this leaves one open to an easy denial of * service attack, and SYN cookies can't defend * against this problem. So, we drop the data * in the interest of security over speed unless * it's still in use. */ kfree_skb(skb); return 0; } goto discard; case TCP_SYN_SENT: queued = tcp_rcv_synsent_state_process(sk, skb, th, len); if (queued >= 0) return queued; /* Do step6 onward by hand. */ tcp_urg(sk, skb, th); __kfree_skb(skb); tcp_data_snd_check(sk); return 0; } if (!tcp_validate_incoming(sk, skb, th, 0)) return 0; /* step 5: check the ACK field */ if (th->ack) { int acceptable = tcp_ack(sk, skb, FLAG_SLOWPATH | FLAG_UPDATE_TS_RECENT) > 0; switch (sk->sk_state) { case TCP_SYN_RECV: if (acceptable) { tp->copied_seq = tp->rcv_nxt; smp_mb(); tcp_set_state(sk, TCP_ESTABLISHED); sk->sk_state_change(sk); /* Note, that this wakeup is only for marginal * crossed SYN case. Passively open sockets * are not waked up, because sk->sk_sleep == * NULL and sk->sk_socket == NULL. */ if (sk->sk_socket) sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT); tp->snd_una = TCP_SKB_CB(skb)->ack_seq; tp->snd_wnd = ntohs(th->window) << tp->rx_opt.snd_wscale; tcp_init_wl(tp, TCP_SKB_CB(skb)->seq); if (tp->rx_opt.tstamp_ok) tp->advmss -= TCPOLEN_TSTAMP_ALIGNED; /* Make sure socket is routed, for * correct metrics. */ icsk->icsk_af_ops->rebuild_header(sk); tcp_init_metrics(sk); tcp_init_congestion_control(sk); /* Prevent spurious tcp_cwnd_restart() on * first data packet. */ tp->lsndtime = tcp_time_stamp; tcp_mtup_init(sk); tcp_initialize_rcv_mss(sk); tcp_init_buffer_space(sk); tcp_fast_path_on(tp); } else { return 1; } break; case TCP_FIN_WAIT1: if (tp->snd_una == tp->write_seq) { tcp_set_state(sk, TCP_FIN_WAIT2); sk->sk_shutdown |= SEND_SHUTDOWN; dst_confirm(__sk_dst_get(sk)); if (!sock_flag(sk, SOCK_DEAD)) /* Wake up lingering close() */ sk->sk_state_change(sk); else { int tmo; if (tp->linger2 < 0 || (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt))) { tcp_done(sk); NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPABORTONDATA); return 1; } tmo = tcp_fin_time(sk); if (tmo > TCP_TIMEWAIT_LEN) { inet_csk_reset_keepalive_timer(sk, tmo - TCP_TIMEWAIT_LEN); } else if (th->fin || sock_owned_by_user(sk)) { /* Bad case. We could lose such FIN otherwise. * It is not a big problem, but it looks confusing * and not so rare event. We still can lose it now, * if it spins in bh_lock_sock(), but it is really * marginal case. */ inet_csk_reset_keepalive_timer(sk, tmo); } else { tcp_time_wait(sk, TCP_FIN_WAIT2, tmo); goto discard; } } } break; case TCP_CLOSING: if (tp->snd_una == tp->write_seq) { tcp_time_wait(sk, TCP_TIME_WAIT, 0); goto discard; } break; case TCP_LAST_ACK: if (tp->snd_una == tp->write_seq) { tcp_update_metrics(sk); tcp_done(sk); goto discard; } break; } } else goto discard; /* step 6: check the URG bit */ tcp_urg(sk, skb, th); /* step 7: process the segment text */ switch (sk->sk_state) { case TCP_CLOSE_WAIT: case TCP_CLOSING: case TCP_LAST_ACK: if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) break; case TCP_FIN_WAIT1: case TCP_FIN_WAIT2: /* RFC 793 says to queue data in these states, * RFC 1122 says we MUST send a reset. * BSD 4.4 also does reset. */ if (sk->sk_shutdown & RCV_SHUTDOWN) { if (TCP_SKB_CB(skb)->end_seq != TCP_SKB_CB(skb)->seq && after(TCP_SKB_CB(skb)->end_seq - th->fin, tp->rcv_nxt)) { NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPABORTONDATA); tcp_reset(sk); return 1; } } /* Fall through */ case TCP_ESTABLISHED: tcp_data_queue(sk, skb); queued = 1; break; } /* tcp_data could move socket to TIME-WAIT */ if (sk->sk_state != TCP_CLOSE) { tcp_data_snd_check(sk); tcp_ack_snd_check(sk); } if (!queued) { discard: __kfree_skb(skb); } return 0; } EXPORT_SYMBOL(tcp_rcv_state_process);

序列号和确认号
TCP会话的每一端都包含一个32位(bit)的序列号,该序列号被用来跟踪该端发送的数据量。每一个包中都包含序列号,在接收端则通过确认号用来通知发送端数据成功接收
包1: TCP会话的每一端的序列号(seqnumber)都从0开始,同样的,确认号也从0开始(初始的本端不需要向谁确认),因为此时通话还未开始,没有通话的另一端需要确认 包2: 服务端响应客户端的请求,响应中附带序列号0(由于这是服务端在该次TCP会话中发送的第一个包,所以序列号为0,seqnumber = 0)和相对确认号1(表明服务端收到了客户端发送的包1中的SYN)(acknumber = 1) //需要注意的是,尽管客户端没有发送任何有效数据,确认号还是被加1,这是因为接收的包中包含SYN或FIN标志位(并不会对有效数据的计数产生影响,因为含有SYN或FIN标志位的包并不携带有效数据) 包3: 和包2中一样,客户端使用确认号1(seqnumber = 1)响应服务端的序列号0,同时响应中也包含了客户端自己的序列号(由于服务端发送的包中确认收到了客户端发送的SYN,故客户端的序列号由0变为1) //此时,通信的两端的序列号都为1,通信两端的序列号增1发生在所有TCP会话的建立过程中 包4: 这是流中第一个携带有效数据的包(确切的说,是客户端发送的HTTP请求),序列号依然为1,因为到上个包为止,还没有发送任何数据,确认号也保持1不变,因为客户端没有从服务端接收到任何数据 //需要注意的是,包中有效数据的长度为725字节
0x6: 各个Flag触发条件
RST
RST: (Reset the connection)用于复位因某种原因引起出现的错误连接,也用来拒绝非法数据和请求。如果接收到RST位时候,通常发生了某些错误
1. 发送RST包关闭连接时,不必等缓冲区的包都发出去,直接就丢弃缓冲区中的包,发送RST 2. 而接收端收到RST包后,也不必发送ACK包来确认
系统会在以下几个条件下发送RST包
1. 建立连接的SYN到达某端口,但是该端口上没有正在监听的服务 例如主机A向主机B发送一个SYN请求,表示想要连接主机B的40000端口,但是主机B上根本没有打开40000这个端口,于是就向主机A发送了一个RST。这种情况很常见。特别是服务器程序core dump之后重启之前连续出现RST的情况会经常发生 如果云上ECS向某地区进行大量端口扫描,则该地区(例如武汉)可能会发送大量的RST包返回给云ECS 2. TCP收到了一个根本不存在的连接上的分节 我们知道,TCP在数据传输前,要通过三路握手(three-way handshake)建立连接,即连接建立起后,服务器和客户端都有一个关于此连接的描述,具体形式表现为套接口对,如果收到的某TCP分节,根据源 IP,源tcp port number,及目的IP,目的tcp port number在本地(指服务器或客户端)找不到相应的套接口对,TCP则认为在一个不存在的连接上收到了分节,说明此连接已错,要求重新建立连接,于是发出了RST的TCP包 3. 请求超时。使用setsockopt的SO_RCVTIMEO选项设置recv的超时时间。接收数据超时时,会发送RST包 4. 提前关闭 5. 在一个已关闭的socket上收到数据: 客户端在服务端已经关闭掉socket之后,仍然在发送数据。这时服务端会产生RST 1. 使用shutdown、close关闭套接字,发送的是FIN,不是RST 2. 套接字关闭前,使用sleep。对运行的程序Ctrl+C,会发送FIN,不是RST 3. 套接字关闭前,执行return、exit(0)、exit(1),会发送FIN、不是RST
其中,ACK是可能与SYN,FIN等同时使用的
1. 比如SYN和ACK可能同时为1,它表示的就是建立连接之后的响应 2. 如果只是单个的一个SYN,它表示的只是建立连接。TCP的几次握手就是通过这样的ACK表现出来的 3. 但SYN与FIN是不会同时为1的,因为前者表示的是建立连接,而后者表示的是断开连接 4. RST一般是在FIN之后才会出现为1的情况,表示的是连接重置 5. 一般地 1) 当出现FIN包或RST包时,我们便认为客户端与服务器端断开了连接 2) 而当出现SYN和SYN + ACK包时,我们认为客户端与服务器建立了一个连接 6. PSH为1的情况,一般只出现在DATA内容不为0的包中,也就是说PSH为1表示的是有真正的TCP数据包内容被传递
Relevant Link:
http://baike.baidu.com/view/7649.htm?fromtitle=tcp%2Fip&fromid=214077&type=syn http://www.w3school.com.cn/tcpip/tcpip_protocols.asp https://en.wikipedia.org/wiki/Transmission_Control_Protocol https://tools.ietf.org/html/rfc793 http://www.cnblogs.com/zhaoyl/archive/2012/09/20/2695799.html
http://www.oschina.net/question/234345_47411
http://www.mianfeiwendang.com/doc/0545169db5932b91fd62609b/2
http://blog.csdn.net/wudiyi815/article/details/8505726
http://blog.csdn.net/guowenyan001/article/details/11766929
http://baike.baidu.com/view/1044719.htm
http://my.oschina.net/costaxu/blog/127394
4. 网络层
本章节介绍网络层的各种协议、以及格式规范。
(这里给一张网络层总体架构图,尽量包含完整的网络层协议)
0x1: IP 网际协议
IP是TCP/IP协议族中最为核心的协议。RFC 791[Postel 1981a]是IP的正式规范文件: http://www.rfc-editor.org/rfc/rfc791.txt

1. 版本(4bit) 1) 版本号4: IPv4 2) 版本号6: IPv6 2. 首部长度(4bit) 首部占32bit(4字节)字的数目(所以首部长度为这个字段值*4),包括任何选项。普通IP数据报(没有任何选择项)字段的值是5(20字节) 3. 服务类型(TOS)(8bit) 1) 优先权子字段(3bit): 现在已被忽略 2) TOS子字段(4bit) 2.1) Bit 0: 最小时延 2.2) Bit 1: 最大吞吐量 2.3) Bit 2: 最高可靠性 2.4) Bit 3: 最小费用 3) 未用置0字段(1bit) 在单个IP数据报中,TOS子字段4bit中只能置其中1 bit。如果所有4bit均为0,那么就意味着是一般服务。RFC 1340、RFC 1349详细地描述了TOS的特性: 1) Domain Name Service 1.1) UDP Query: 1000: 最小时延 1.2) TCP Query: 0000: 一般服务 1.3) Zone Transfer: 0100: 最大吞吐量 2) NNTP: 0001: 最小费用 3) ICMP 3.1) Errors: 0000: 一般服务 3.2) Requests: 0000: 一般服务 3.3) Responses: 0000: 一般服务 4) Any IGP: 0010: 最高可靠性 5) EGP: 0000: 一般服务 6) TELNET: 1000: 最小时延 Telnet要求最小的传输时延,因为人们主要用它们来传输少量的交互数据 7) FTP 7.1) Control: 1000: 最小时延 7.2) Data: 0100: 最大吞吐量 FTP文件传输则要求有最大的吞吐量 8) TFTP: 0100: 最大吞吐量 9) SMTP 9.1) Command phase: 1000: 最小时延 9.2) DATA phase: 0100: 最大吞吐量 10) BOOTP: 0000: 一般服务 对于IP数据报中的TOS字段,我们需要明白的是: 现在大多数的TCP/IP实现都不支持TOS特性,但是在很多Unix系统上对它提供了设置。另外,路由协议如OSPF和IS-IS都能根据这些字段的值进
行路由决策。所以,研究TOS还是很有现实意义的 4. 总长度(16bit) 总长度字段是指整个IP数据报的长度(以字节为单位)。利用总长度字段-首部长度字段,就可以知道IP数据报中数据内容的起始位置和长度。由于该字段长16比特,所以IP数据报最长可达65535
字节。当数据报被分片时,该字段的值也随着变化(关于数据报分片,我们之后会详细学习) 总长度字段是IP首部中必要的内容,因为一些数据链路(如以太网)需要填充一些数据以达到最小长度。尽管以太网的最小帧长为46字节,但是I P数据可能会更短(IP的头部只有20字节,数据部
分可以为0)。如果没有总长度字段,那么IP层就不知道46字节中有多少是IP数据报的内容,有多少是padding的内容 5. 标识(16bit) 标识字段唯一地标识主机发送的每一份数据报。通常每发送一份报文它的值就会加1。在分片和重组时会使用到 6. 标志(3bit) 1) Bit 0: 保留,必须置为0 2) Bit 1: 2.1) 0: 可以分组 2.2) 1: 不可以分组 3) Bit 2: 3.1) 0: 已经是最后一个分组了 3.2) 1: 还有更多分组 7. 片偏移(13bit) 当前分片在完整数据报中的偏移 8. 生存时间TTL(8bit) TTL(time-to-live)生存时间字段设置了数据报可以经过的最多路由器数。它指定了数据报的生存时间。TTL的初始值由源主机设置(通常为32或64),一旦经过一个处理它的路由器,它的值就
减去1。当该字段的值为0时,数据报就被丢弃,并发送ICMP报文通知源主机。 9. 协议(8bit) 该IP数据包携带的的上层协议,这个字段的作用为了实现"分用",所谓分用,即当目的主机收到一个以太网数据帧时,数据就开始从协议栈中由底向上升,同时去掉各层协议加上的报文首部。每
层协议盒都要去检查报文首部中的协议标识,以确定接收数据的上层协议。这个过程称作分用(Demultiplexing) 10. 首部检验和(16bit) 首部检验和字段是根据"IP首部"计算的检验和码(注意,只是首部),它不对首部后面的数据进行计算。 为了计算一份数据报的IP检验和,首先把检验和字段置为0。然后,对首部中每个16bit进行二进制反码求和(整个首部看成是由一串16bit的字组成),结果存在检验和字段中。当收到一份IP数
据报后,同样对首部中每个16bit进行二进制反码的求和。由于接收方在计算过程中包含了发送方存在首部中的检验和,因此,如果首部在传输过程中没有发生任何差错,那么接收方计算的结果
应该为全1。如果结果不是全1(即检验和错误),那么I P就丢弃收到的数据报。但是不生成差错报文,由上层去发现丢失的数据报并进行重传 11. 源IP地址(32bit) 每一份IP数据报都包含源IP地址和目的I P地址,它们都是32 bit的值 12. 目的IP地址(32bit) 每一份IP数据报都包含源IP地址和目的I P地址,它们都是32 bit的值 13. 选项OPTION 选项数据报中的一个"可变长"、"可选信息"。 1) 安全和处理限制(用于军事领域,详细内容参见RFC 1108[Kent 1991]) 2) 记录路径(让每个路由器都记下它的IP地址) 3) 时间戳(让每个路由器都记下它的IP地址和时间) 4) 宽松的源站选路(loose source route)(为数据报指定一系列必须经过的IP地址) http://en.wikipedia.org/wiki/Loose_Source_Routing 5) 严格的源站选路(strict source route)(与宽松的源站选路类似,但是要求只能经过指定的这些地址,不能经过其他的地址)
可以使用: loose: ping –j <hosts>、strict: ping –k <hosts>进行测试 14. Padding填充: 选项字段一直都是以32 bit作为界限,在必要的时候插入值为0的填充字节。这样就保证IP首部始终是32bit的整数倍(这是首部长度字段所要求的,因为它是以2为基底的) 14. 数据 IP数据包携带的上层数据
Copyright (c) 2014 LittleHann All rights reserved
