Iptables、Netfilter原理分析
一、Iptables/Netfilter基本简介
0x1:Iptables和Netfilter的概念关系
在文章的最开头,我们首先要明确一个概念,Iptables/Netfilter到底是什么,它们之间的关系是怎样的。
我们可以这样简单地理解:
Netfilter是Linux操作系统核心层内部的一个数据包处理模块,它具有如下功能:
- 1)网络地址转换(Network Address Translate)
- 2)数据包内容修改
- 3)以及数据包过滤的防火墙功能
Netfilter平台中制定了五个数据包的挂载点(Hook Point),我们可以理解为回调函数点,数据包到达这些位置的时候会主动调用我们的函数,使我们有机会能在数据包路由的时候有机会改变它们的方向、内容,这5个挂载点分别是
- 1)PRE_ROUTING 2)INPUT3)OUTPUT4)FORWARD 5)POST_ROUTING
Netfilter所设置的规则是存放在内核内存中的。
Iptables是一个应用层(Ring3)的应用程序,它通过Netfilter放出的接口来对存放在内核内存中的Xtables(Netfilter的配置表)进行修改,这是一个典型的Ring3和Ring0配合的架构。
0x2:Xtables
我们知道Netfilter是负责实际的数据流改变工作的内核模块,而Xtables就是它的规则配置文件,Netfilter依照Xtables的规则来运行,Iptables在应用层负责修改这个规则文件。
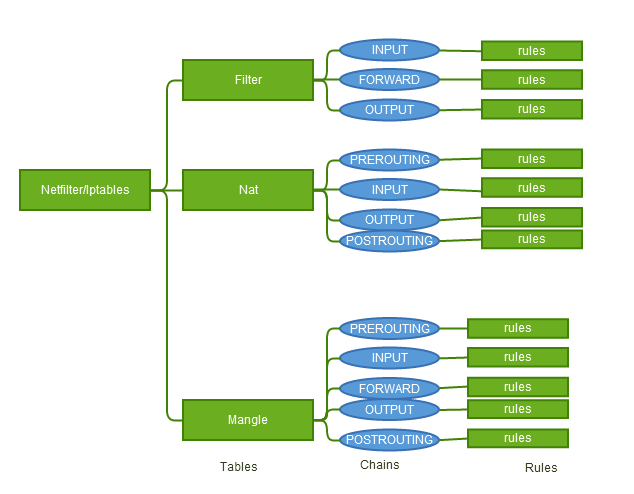
Xtables由"表"、"链"、"规则rule"组成
- 1、Filter(表):Filter表是专门过滤包的,内建三个链,可以毫无问题地对包进行DROP、LOG、ACCEPT和REJECT等操作
- INPUT(链):INPUT针对那些目的地是本地的包
- 规则rule ..
- FORWARD(链):FORWARD链过滤所有不是本地产生的并且目的地不是本地(即本机只是负责转发)的包
- 规则rule
- OUTPUT(链):OUTPUT是用来过滤所有本地生成的包
- 规则rule ..
- INPUT(链):INPUT针对那些目的地是本地的包
- 2、Nat(表):Nat表的主要用处是网络地址转换,即Network Address Translation,缩写为NAT。做过NAT操作的数据包的地址就被改变了,当然这种改变是根据我们的规则进行的。属于一个流的包(因为包的大小限制导致数据可能会被分成多个数据包)只会经过这个表一次。如果第一个包被允许做NAT或Masqueraded,那么余下的包都会自动地被做相同的操作。也就是说,余下的包不会再通过这个表,一个一个的被NAT,而是自动地完成
- PREROUTING(链):PREROUTING 链的作用是在包刚刚到达防火墙时改变它的目的地址
- 规则rule
- INPUT(链)
- 规则rule
- OUTPUT(链):OUTPUT链改变本地产生的包的目的地址
- 规则rule
- POSTROUTING(链):POSTROUTING链在包就要离开防火墙之前改变其源地址。
- 规则rule
- PREROUTING(链):PREROUTING 链的作用是在包刚刚到达防火墙时改变它的目的地址
- 3、Mangle(表):这个表主要用来mangle数据包。我们可以改变包头的内容,比如 TTL,TOS或MARK。 注意MARK并没有真正地改动数据包,它只是在内核空间为包设了一个标记。防火墙内的其他的规则或程序(如tc)可以使用这种标记对包进行过滤或高级路由。注意,mangle表不能做任何NAT,它只是改变数据包的TTL,TOS或MARK,而不是其源目地址。NAT必须在nat表中操作的。
- PREROUTING(链):PREROUTING在包进入防火墙之后、路由判断之前改变包
- 规则rule
- NPUT(链):INPUT在包被路由到本地之后,但在用户空间的程序看到它之前改变包
- 规则rule
- FORWARD(链):FORWARD在最初的路由判断之后、最后一次更改包的目的之前mangle包
- 规则rule
- OUTPUT(链):OUTPUT在确定包的目的之前更改数据包
- 规则rule
- POSTROUTING(链):POSTROUTING是在所有路由判断之后
- 规则rule
- PREROUTING(链):PREROUTING在包进入防火墙之后、路由判断之前改变包
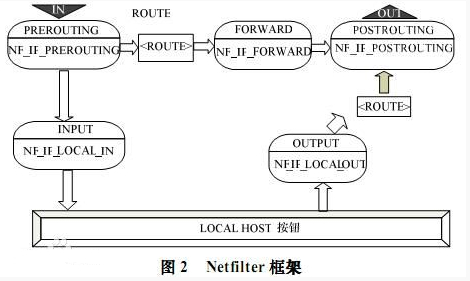
0x3:Netfilter的Hook点
Netfilter的架构就是在整个网络流程的若干位置放置了一些检测点(HOOK)(或者说是回调函数),而在每个检测点上登记(callback)了一些处理函数进行处理(如包过滤,NAT等,甚至可以是 用户自定义的功能)
- 1. NF_IP_PRE_ROUTING:刚刚通过数据链路层解包,进入网络层的数据包通过此点(刚刚进行完版本号,校验和等检测),目的地址转换在此点进行
- 2. NF_IP_LOCAL_IN:经路由查找后,送往本机的通过此检查点,INPUT包过滤在此点进行
- 3. NF_IP_FORWARD:要转发的包通过此检测点,FORWARD包过滤在此点进行
- 4. NF_IP_POST_ROUTING:所有马上便要通过网络设备出去的包通过此检测点,内置的源地址转换功能(包括地址伪装)在此点进行
- 5. NF_IP_LOCAL_OUT:本机进程发出的包通过此检测点,OUTPUT包过滤在此点进行
可以看到,Iptables/Netfilter的工作是针对网络的数据包进行修改的,所以,Iptables/Netfilter在某种程度上可以算是一种网络层的路由器/防火墙。
我们可以看到,通过"5个代表不同阶段的Hook点"、"表、链、规则"这种"松耦合"、"规则型"的结构,我们作为管理员可以获得最大程度的控制灵活性、可以有非常巨大的想象空间。
Netfilter是由Rusty Russell提出的Linux 2.4内核防火墙框架,该框架既简洁又灵活,可实现安全策略应用中的许多功能,如
- 数据包过滤
- 数据包处理
- 地址伪装
- 透明代理
- 动态网络地址转换(Network Address Translation,NAT)
- 基于用户及媒体访问控制(Media Access Control,MAC)地址的过滤
- 基于状态的过滤
- 包速率限制等
Iptables/Netfilter的这些规则可以通过灵活组合,形成非常多的功能、涵盖各个方面,这一切都得益于它的优秀设计思想。
参考链接:
https://www.frozentux.net/iptables-tutorial/cn/iptables-tutorial-cn-1.1.19.html http://zh.wikipedia.org/wiki/Netfilter http://www.netfilter.org/projects/iptables/ http://linux.vbird.org/linux_server/0250simple_firewall.php http://linux.vbird.org/linux_server/0250simple_firewall.php http://www.vpser.net/security/linux-iptables.html
二、Linux数据包路由原理
我们已经知道了Netfilter和Iptables的架构和作用,并且学习了控制Netfilter行为的Xtables表的结构,那么这个Xtables表是怎么在内核协议栈的数据包路由中起作用的呢?
网口数据包由底层的网卡NIC接收,通过数据链路层的解包之后(去除数据链路帧头),就进入了"TCP/IP协议栈(本质就是一个处理网络数据包的内核驱动)和Netfilter混合"的"数据包处理流程"中了。
数据包的接收、处理、转发流程构成一个有限状态向量机,经过一些列的内核处理函数、以及Netfilter Hook点,最后被转发、或者本次上层的应用程序消化掉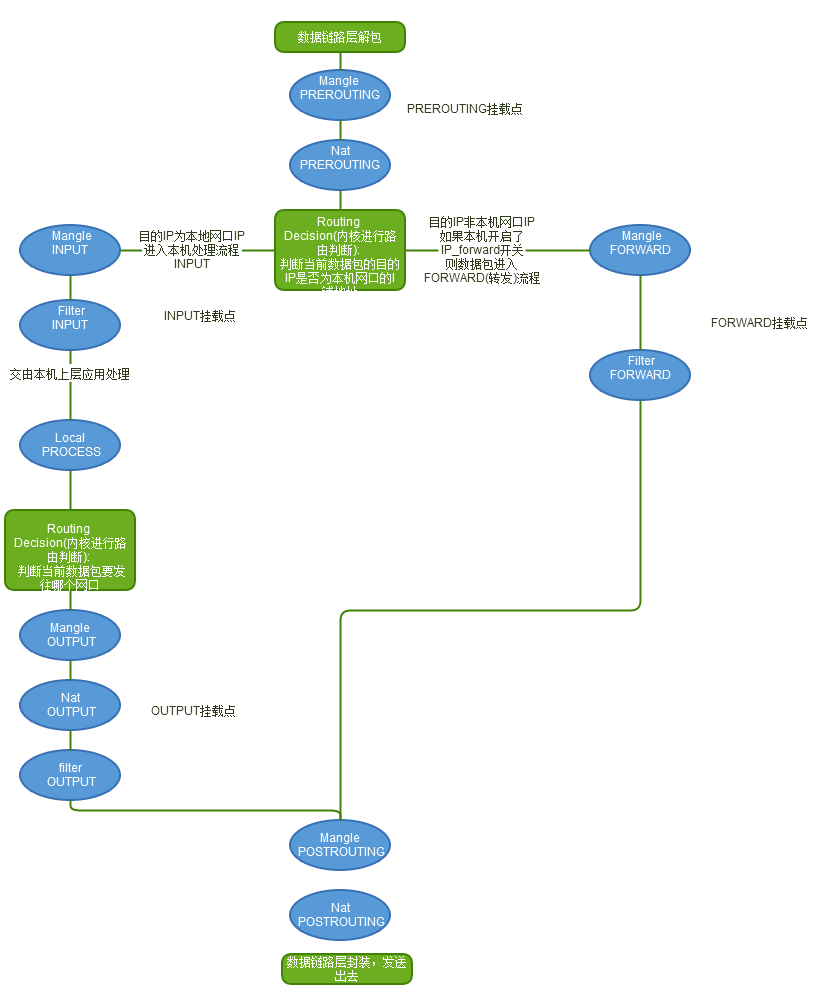
从这张图中,我们可以总结出以下规律:
- 1. 当一个数据包进入网卡时,数据包首先进入PREROUTING链,在PREROUTING链中我们有机会修改数据包的DestIP(目的IP),然后内核的"路由模块"根据"数据包目的IP"以及"内核中的路由表"判断是否需要转送出去(注意,这个时候数据包的DestIP有可能已经被我们修改过了)
- 2. 如果数据包就是进入本机的(即数据包的目的IP是本机的网口IP),数据包就会沿着图向下移动,到达INPUT链。数据包到达INPUT链后,任何进程都会收到它
- 3. 本机上运行的程序也可以发送数据包,这些数据包经过OUTPUT链,然后到达POSTROTING链输出(注意,这个时候数据包的SrcIP有可能已经被我们修改过了)
- 4. 如果数据包是要转发出去的(即目的IP地址不再当前子网中),且内核允许转发,数据包就会向右移动,经过FORWARD链,然后到达POSTROUTING链输出(选择对应子网的网口发送出去)
我们在写Iptables规则的时候,要时刻牢记这张路由次序图,根据所在Hook点的不同,灵活配置规则。
三、Iptables规则编写原则
我们前面说过,使用Iptables是一个非常灵活的过程,我们在写规则的时候,一定要时刻牢记上面的这张"数据包路由图",明白在5个Hook点,3种"表"分别所处的位置,以及结合在这个5个Hook点可以实现的功能,来理解规则。理解规则的原理比强记规则本身效果要好得多。
0x1:需求分析
在正式编写Iptables规则之前,我们一定是有一个实现某个功能、目的的需求,我们必须先将它整理出来,为下一步抽象化作准备,这里我以我项目中的需求为例,大家在自己的实验中可以举一反三
1. 网口at0(10.0.0.1)是一个伪AP的网口,目标客户端连接到伪AP网口at0之后会发起DHCPDISCOVER过程,监听在at0上的DHCPD会进行回应,为客户端分配10.0.0.100的IP地址,并设置客户
端的默认网关为10.0.0.1(即at0的IP地址)、默认DNS服务器为10.0.0.1(即at0的IP地址) 2. 需要将网口at0(10.0.0.1)的入口流量牵引到真正连接外网的网卡接口eth0(192.168.159.254)上,做一个NAT服务 3. 对网口at0(10.0.0.1)的DHCP流量(目的端口67的广播数据包)予以放行,因为我们需要在伪AP所在的服务器上假设DHCP服务器 4. 对网口at0(10.0.0.1)的DNS流量(目的端口53)予以放行,因为我们需要在伪AP所在的服务器上假设DNS服务器
0x2:逐步抽象化我们的需求
我们根据我们的需求进行抽象化,即用规则来抽象化描述我们的目的,在编写的过程中要注意不同的Hook点所能做的修改是不同的
//开启Linux路由转发开关,由于本机对数据包进行转发 echo "1" > /proc/sys/net/ipv4/ip_forward //将客户端的HTTP流量进行NAT,改变数据包的SrcIP,注意,是在POSTROUTING(数据包即将发送出去之前进行修改) iptables -t nat -A POSTROUTING -p tcp -s 10.0.0.0/24 --dport 80 -j SNAT --to-source 192.168.159.254 //将远程WEB服务器返回来的HTTP流量进行NAT,回引回客户端,注意,是在PREROUTING(数据包刚进入协议栈之后马上就修改) iptables -t nat -A PREROUTING -p tcp -d 192.168.159.254 -j DNAT --to 10.0.0.100
我们在DHCP服务器中指定客户端的默认DNS服务器是10.0.0.1(本机),即伪DNS,但我目前还没有在本机架设DNS,所以目前还需要将53号端口的DNS数据包NAT出去,牵引到谷歌的DNS: 8.8.8.8上去
iptables -t nat -A PREROUTING -p udp -s 10.0.0.0/24 --dport 53 -j DNAT --to 8.8.8.8 iptables -t nat -A POSTROUTING -p udp -s 10.0.0.0/24 --dport 53 -j SNAT --to-source 192.168.159.254 iptables -t nat -A PREROUTING -p udp -d 192.168.159.254 --sport 53 -j DNAT --to 10.0.0.100 iptables -t nat -A POSTROUTING -p udp -s 8.8.8.8 --sport 53 -j SNAT --to-source 10.0.0.1

四、iptables-nfqueue
iptables-nfqueue ,是将网络包发送到用户程序去做接收/丢弃决定的 iptables 特性。NFQUEUE 需要用户程序监听 NFQUEUE 队列,并对接收到的网络包响应对应的判决结果。
iptables -A INPUT -j NFQUEUE --queue-num 0
用户态软件必须监听队列 0(connect to queue 0),并从内核获取消息;然后给每个网络包给出判决(verdict)。
0x1:使用 Go 对接 iptables NFQUEUE 的例子
从 iptables NFQUEUE 中接收 tcp 连接的 SYN 包,并从 SYN 包中解析得到源 IP 地址、源 tcp 端口、目的 IP 地址、目的 tcp 端口等信息。
git clone https://github.com/Asphaltt/go-nfnetlink-example.git make run ./nfnetlink-example

使用的 iptables 规则如下:
iptables -t raw -I PREROUTING -p tcp --syn -j NFQUEUE --queue-num 1 --queue-bypass
- --queue-num 指当前规则将对应的网络包放到 1 号队列
- --queue-bypass 指当没有用户程序监听当前队列时,默认放行网络包,而不是丢包
在 raw 表 PREROUTING 链上匹配 tcp 连接的 SYN 包。
nfnetlink_queue 在 /proc 下的路径:/proc/net/netfilter/nfnetlink_queue


- 1:队列号:由 --queue-number 指定
- 49732:对端接口 ID:监听队列的 pid
- 0:队列数量:当前在队列里等待的网络包数量
- 2:复制模式:0 和 1 只提供元数据;2 同时还会提供限定复制范围的部分网络包内容(a part of packet of size copy range)。
- 65531:复制范围:放进消息里的网络包长度
- 0:队列丢包数量:因队列满了而丢包的网络包数量
- 0:用户丢包数量:因不能发送到用户态而丢包的网络包数量。如果该数值不为 0,尝试增大 netlink 缓存大小(increase netlink buffer size)。在程序侧,如果发生丢包,可以看到整数索引不连续了(see gap in packet id)。
- 1:ID 序列:最后一个网络包的整数索引
0x2:NFQUEUE 的工作机制
NFQUEUE 的工作机制可分上下两场:
- 上半场:
- 接收 -j NFQUEUE 发送过来的网络包
- 入队
- 通过 nfnetlink 将网络包发给用户程序
- 下半场:
- 接收用户程序通过 nfnetlink 发送过来的判决结果
- 出队
- 处理判决结果
- 继续 iptables 后续的处理
上半场的函数调用栈如下:
|-->NF_HOOK() // include/linux/netfilter.h |-->nf_hook() |-->nf_hook_slow() // net/netfilter/core.c |-->nf_queue() // net/netfilter/nf_queue.c |-->__nf_queue() |-->struct nf_queue_handler *qh->outfn() / / / |-->nfqnl_enqueue_packet() // net/netfilter/nfnetlink_queue.c |-->__nfqnl_enqueue_packet() |-->nfnetlink_unicast() |-->__enqueue_entry()
下半场的函数调用栈如下:
|-->nfqnl_recv_verdict() // net/netfilter/nfnetlink_queue.c |-->verdict_instance_lookup() |-->find_dequeue_entry() |-->__dequeue_entry() |-->nfqnl_reinject() |-->nf_reinject() // net/netfilter/nf_queue.c |-->entry->state.okfn() |-->//继续 `iptables` 后续的处理
当一个网络包触发 NFQUEUE 目标,它将被插入到 --queue-num 指定的队列里。网络包队列是一个链式列表,列表元素是网络包和元数据(Linux 内核 skb):
- 固定长度的链式列表
- 使用整数索引网络包
- 当用户态程序对指定整数索引的网络包做出判决后,该网络包将被释放掉
- 当队列满了,队列不再接收网络包
用户态程序会有如下影响:
- 批量读取消息,并批量给出判决。当队列未满时,批量处理不会产生影响。
- 可以无序地给网络包做出判决。比如,得到 1、2、3、4 网络包,以 4、2、3、1 顺序做出判决。
- 过慢的判决会导致队列充满。此时,内核会丢掉新来的网络包,而不是插入队列。
NFQUEUE 因为需要将网络包发送给用户程序,所以它的性能并不高。但相比于堆叠 iptables 规则,NFQUEUE 的处理方式更加灵活。
而对于 XDP、xt_bpf 等拥有同等灵活性的新技术而言,NFQUEUE 的适用范围更广、能够适配很多老旧系统。
0x3:高级特性
--queue-balance 多队列
--queue-balance 是 NFQUEUE 选项,由 Florian Westphal 实现,实现了同一条 iptables 规则的网络包负载均衡到多个队列。用法非常简单。比如,负载均衡 INPUT 流量到 0-3 队列的规则如下:
iptables -A INPUT -j NFQUEUE --queue-balance 0:3
注意,负载均衡是基于流实现的(made with respect to the flow),一条流的所有网络包会发送到同一个队列。
可用范围:Linux 内核 >= 2.6.31,iptables >= 1.4.5。
多线程
收包/发包(nfnetlink 包)操作需要被锁保护,防止并发写。
收包和发包是完全分开的操作,它们不共享内存。判决只用到包 ID(packet index)。与此同时,上锁能让不同线程对任何包进行判决。
包重排序
NFQUEUE 很容易地为任意入队的包做包重排序。然而,需要注意的是内核是使用链式列表来排队包的;所以,乱序判决会带来一定的损耗。
队列容量
NFQUEUE 是有容量限制的,默认是 1024;用户程序可以在监听队列的时候设置容量大小。如果队列满了,iptables 默认会丢包;在内核 3.6 之后,可以使用 --fail-open 选项将这默认丢包改为默认接收。
如何知道队列满了后发生丢包呢?有两种方式:
- 每次丢包都会打印一条系统日志
- cat /proc/net/netfilter/nfnetlink_queue 里有丢包统计
但需要注意的是,无法通过程序的方式实时感知到队列满了、或者丢包了。
复制到用户程序的网络包的大小
将网络包复制到用户程序的时候,对网络包的大小是有限制的,默认是 65531;用户程序可以在监听队列的时候设置复制网络包的最大值。
如果只需要根据 IP 和端口进行判决,则可以将这个限制设置为 40(三层和四层的头部总大小),避免不必要的网络包内容复制。
没有响应判决结果
如果没有对网络包响应其判决结果,则该网络包会永远阻塞在 iptables,iptables 不会自动丢弃这样的网络包。
参考链接:
https://asphaltt.github.io/post/go-nfnetlink-example/ https://github.com/Asphaltt/go-nfnetlink-example/tree/main https://asphaltt.github.io/post/iptables-nfqueue/ https://asphaltt.github.io/post/iptables-nfqueue-usage/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号