
在ElasticSearch中使用 IK 中文分词插件
我这里集成好了一个自带IK的版本,下载即用,
https://github.com/xlb378917466/elasticsearch5.2.include_IK
添加了IK插件意味着你可以使用ik_smart(最粗粒度的拆分)和ik_max_word(最细粒度的拆分)两种analyzer。
你也可以从下面这个地址获取最新的IK源码,自己集成,
https://github.com/medcl/elasticsearch-analysis-ik,
里面还提供了使用说明,可以很快上手。
一般使用elasticsearch-head测试比较方便。
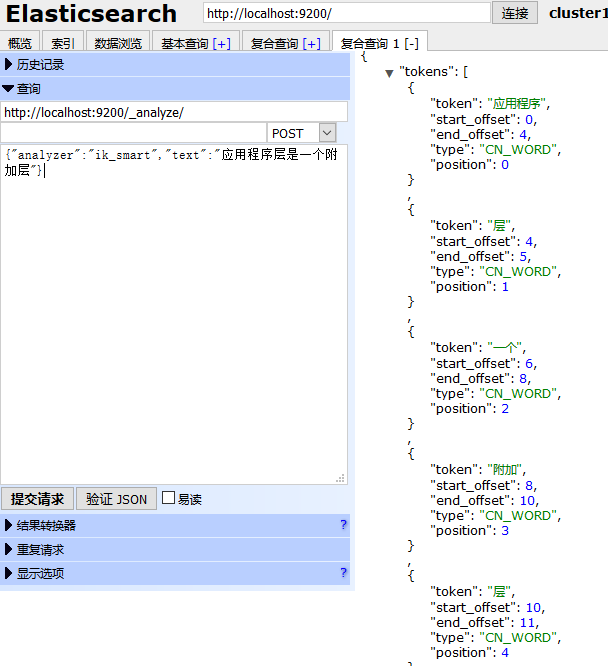
这个IK分词插件挺好用的,支持自定义分词,更重要的是支持热更新。
比如上面这个应用程序层是被分成了两个词,如果你把应用程序层作为一个词添加到你的自定义词典中,那么结果就会发生微妙的变化,通过这样不断的完善词库,相信搜索的体验会越来越好。
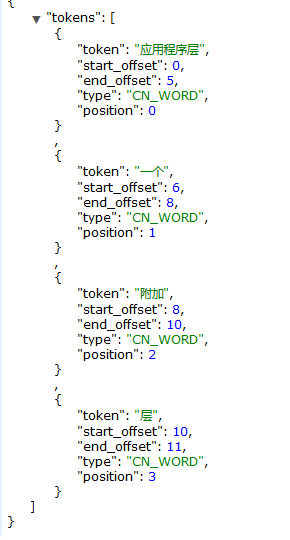
现在IK分词插件也算集成好了,如何使用?
首先新建一个索引,并且给这个索引下的文档类型设置Mapping关系
这里还是继续使用昨天新建的索引twitter作例子,所以只需要给文档类型tweet 新建一个字段Content,并设置这一个字段的Mapping来举例:
http://localhost:9200/twitter/_mapping/tweet/
1 2 3 4 5 6 7 8 9 10 11 12 13 | { "properties": { "content": { "type": "text", "store": "no", "term_vector": "with_positions_offsets", "analyzer": "ik_smart", "search_analyzer": "ik_smart", "include_in_all": "true", "boost": 8 } }} |
这样一来,后面添加的Content就会使用ik_smart来分词,
添加一条测试数据:
http://localhost:9200/twitter/tweet/1/ 选择Put Method
1 2 3 | { "content": "应用程序层是一个附加层"} |
查询测试:
http://localhost:9200/twitter/_search/
使用POST Method,因为我使用ElasticSearch Head 在Get的情况下不返回highlight信息,
1 2 3 4 5 6 7 8 9 10 | { "query" : { "match" : { "content" : "应用程序层是一个附加层" }}, "highlight" : { "pre_tags" : ["<tag1>", "<tag2>"], "post_tags" : ["</tag1>", "</tag2>"], "fields" : { "content" : {} } }} |
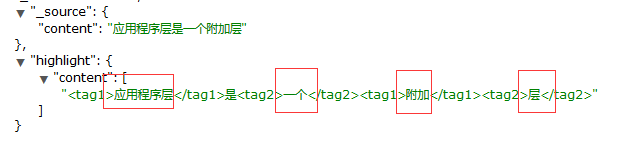
返回如下:
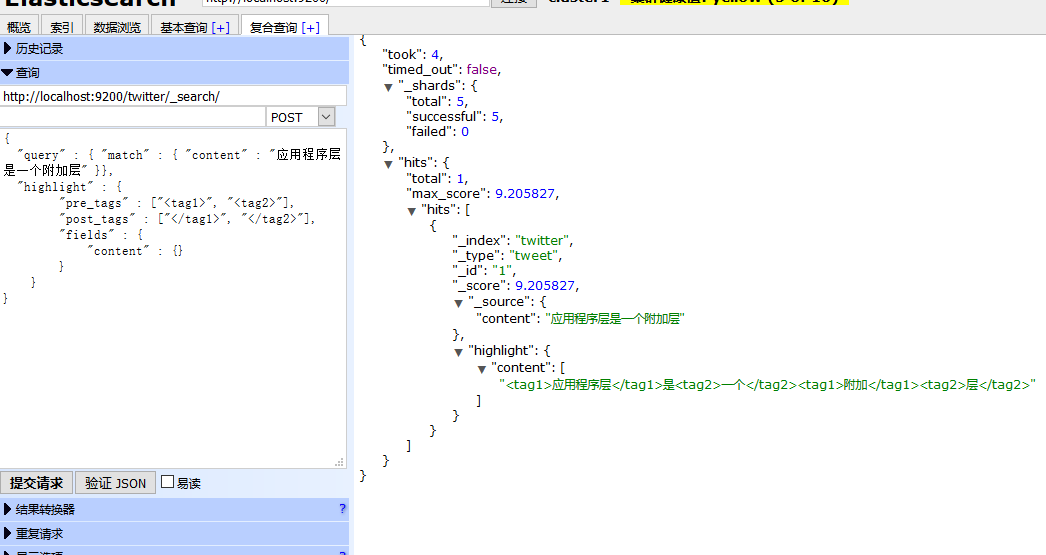
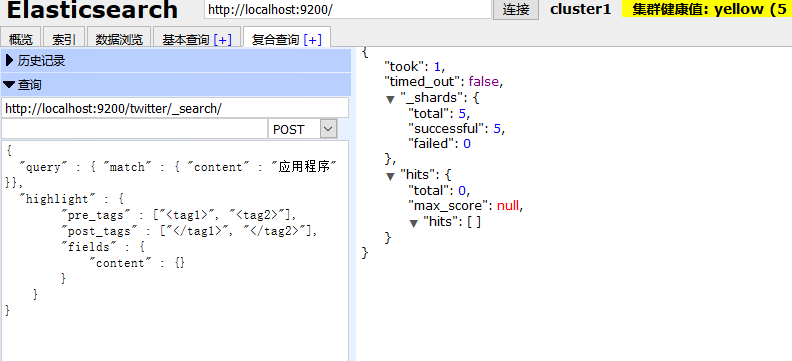
使用应用程序关键词是搜不到内容的,因为分词器不识别 这个词,就是说你要用被你拆分之后的词来搜索,才有匹配的记录。
比如下面几个就是被拆分出来的词

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步