

监督学习 分类模型 KNN
K近邻(KNN)
• 最简单最初级的分类器,就是将全部的训练数据所对应的类别都记录下 来,
当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其 进行分类
• K近邻(k-nearest neighbour, KNN)是一种基本分类方法,通过测量不同特征值之间的距离进行分类。
它的思路是:如果一个样本在特征空间 中的k个最相似(即特征空间中最邻近)
的样本中的大多数属于某一个类 另L则该样本也属于这个类别,其中K通常是不大于20的整数
• KNN算法中,所选择的邻居都是已经正确分类的对象
KNN示例
• 绿色圆要被决定赋予哪个类,是红色三 角形还是蓝色四方形?
• 如果K=3,由于红色三角形所占比例为 2/3,绿色圆将被赋予红色三角形那个类,
如果K=5,由于蓝色四方形比例为3/5, 因此绿色圆被赋予蓝色四方形类
• KN N算法的结果〈艮大程度取决于K的选择

KNN距离计算
• KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,
避免了对象之间的匹配I可题,在这里距蜀一般使用欧氏距离或曼哈顿距离:
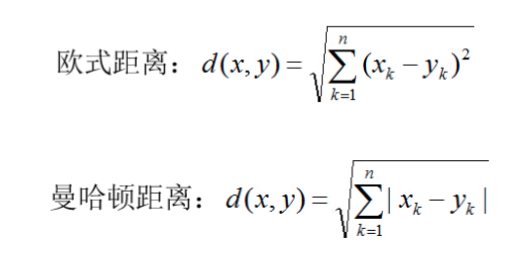
KNN算法
- 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,
找到训练集中与之最为相似的前K个数据, 则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
a) 计算测试数据与各个训练数据之间的距离;
b) 按照距离的递增关系进行排序;
c) 选取距离最小的K个点;
d) 确定前K个点所在类别的出现频率;
e) 返回前K个点中出现频率最高的类别作为测试数据的预测分类。
代码实现:
0.引入依赖 import numpy as np import pandas as pd # 这里直接引入 sklearn 里的数据集,iris 鸢尾花 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split # 切分数据集为训练集和测试集 from sklearn.metrics import accuracy_score # 计算分类预测的准确率 1.数据加载和预处理 iris = load_iris() df = pd.DataFrame(iris.data, columns = iris.feature_names) df['class'] = iris.target df['class'] = df['class'].map({0: iris.target_names[0], 1: iris.target_names[1], 2: iris.target_names[2]}) df.describe()

x = iris.data # 将 y 转化为二维数组 y = iris.target.reshape(-1, 1) print(x.shape, y.shape)
# 划分训练集和测试集 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=35, stratify=y) # print(x_train) print(x_train.shape, y_train.shape) print(x_test.shape, y_test.shape)

2.核心算法实现 # 距离函数定义 def l1_distance(a, b): return np.sum(np.abs(a-b), axis=1) def l2_distance(a, b): return np.sqrt(np.sum((a-b) ** 2, axis=1)) #x_test[0].reshape(1, -1).shape #np.sum(np.abs(x_train - x_test[0].reshape(1, -1)), axis=1) # 分类器的实现 class KNN(object): # 定义一个初始化方法:__init__ 是类的构造方法 def __init__(self, n_neighbors = 1, dist_func = l1_distance): self.n_neighbors = n_neighbors self.dist_func = dist_func # 训练模型的方法 def fit(self, x, y): self.x_train = x self.y_train = y # 模型预测方法 def predict(self, x): # 初始化预测分类数组 y_pred = np.zeros((x.shape[0], 1), dtype=self.y_train.dtype) # 遍历输入的 x 数据点,取出每一个数据点的序号 i 和数据 x_test for i, x_test in enumerate(x): # x_test 跟所有训练数据计算距离 distances = self.dist_func(self.x_train, x_test) # 得到的距离按照由近到远排序,取出索引值 nn_index = np.argsort(distances) # 西选取最近的 k 个点,保存它们对应的分类类别 nn_y = self.y_train[nn_index[:self.n_neighbors]].ravel() # 统计类别出现频率最高的那个,赋给 y_pred[i] y_pred[i] = np.argmax(np.bincount(nn_y)) return y_pred 3.测试 # 定义一个实例 knn = KNN(n_neighbors = 5) # 训练模型 knn.fit(x_train, y_train) # 传入测试数据,做预测 y_pred = knn.predict(x_test) # 求出预测准确率 accracy = accuracy_score(y_test, y_pred) print("预测准确率:", accracy)

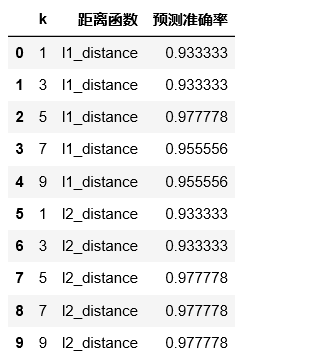
4.测试集 # 定义一个实例 knn = KNN(n_neighbors = 3) # 训练模型 knn.fit(x_train, y_train) # 保存结果 list result_list = [] # 针对不同的参数选取,做预测 for p in [1, 2]: knn.dist_func = l1_distance if p ==1 else l2_distance # 考虑不同的 k 取值 for k in range(1, 10, 2): knn.n_neighbors = k # 传入测试数据,做预测 y_pred = knn.predict(x_test) # 求出预测准确率 accracy = accuracy_score(y_test, y_pred) # 保存准确率 result_list.append([k, 'l1_distance' if p ==1 else 'l2_distance', accracy]) df = pd.DataFrame(result_list, columns=['k', '距离函数', '预测准确率']) df
请你一定不要停下来 成为你想成为的人
感谢您的阅读,我是LXL
