

数据依赖公理系统
一、数据库闭包
由一个属性直接或间接推导出的所有属性的集合。
例: 设有关系模式R(U,F),其中U={A,B,C,D,E,I},F={A→D,AB→E,BI→E,CD→I,E→C},计算(AE)+
解: (1) 令X={AE},X(0)=AE,将F中的所有依赖右边化为单一元素
(2)在F中寻找尚未使用过的左边是A,E或AE的函数依赖,结果是: A→D, E→C;所以 X(1)=X(0)DC=ACDE, 显然 X(1)≠X(0).
(3) 在F中寻找尚未使用过的左边是ACDE的子集的函数依赖, 结果是: CD→I;所以 X(2)=X(1)I=ACDEI。虽然X(2)≠X(1),但F中寻找尚未使用过函数依赖的左边已经没有X(2)的子集,所以不必再计算下去,即(AE)+=ACDEI。 故AE的闭包为ACDEI,不包含所有的属性集合,
例如:f={a->b,b->c,a->d,e->f};由a可直接得到b和d,间接得到c,则a的闭包就是{a,b,c,d}
二、候选码
对于给定的关系R(A1,A2,…An)和函数依赖集F,可将其属性分为4类:
L类 仅出现在函数依赖左部的属性。
R 类 仅出现在函数依赖右部的属性。
N 类 在函数依赖左右两边均未出现的属性。
LR类 在函数依赖左右两边均出现的属性。
定理:对于给定的关系模式R及其函数依赖集F,若X(X∈R)是L类属性,则X必为R的任一候选码的成员。
推论:对于给定的关系模式R及其函数依赖集F,若X(X∈R)是L类属性,且X+包含了R的全部属性;则X必为R的唯一候选码。
具体的步骤:
(1)将R 的所有属性分为L、R、LR 和N 四类,并令X 代表L、N 类,Y 代表LR 类。 R类只在右边出现,一定不为候选码
(2)根据L类,求X+。若X+包含了R 的全部属性,则即为R 的唯一候选码,转(5);否则,转(3)。
(3)候选码可能的组合有L+LR中的任何一个;在Y 中取一属性A,求(XA)+ ,若它包含了R 的全部属性,则是候选码,转(4);否则,调换一属性反复进行这一过程,直到试完所有Y 中的属性。
(4)如果已找出所有候选码,则转(5);否则在Y 中依次取2 个、3 个、…,求它们的属性闭包,若其闭包包含R 的全部属性,则是候选码。
(5)结束。
例1:R<U,F>,U=(A,B,C,D,E,G),F={AB-->C,CD-->E,E-->A.A-->G},求候选码。
因G只在右边出现,所以G一定不属于候选码;而B,D只在左边出现,所以B,D一定属于候选码;BD的闭包还是BD,则对BD进行组合,除了G以外,BD可以跟A,C,E进行组合
先看ABD
ABD本身自包ABD,而AB-->C,CD-->E,A-->G,所以ABD的闭包为ABDCEG=U
再看BDC
CD-->E,E-->A,A-->G,BDC本身自包,所以BDC的闭包为BDCEAG=U
最后看BDE
E-->A,A-->G,AB-->C,BDE本身自包,所以BDE的闭包为BDEAGC=U
因为(ABD)、(BCD)、(BDE)的闭包都是ABCDEG所以本问题的候选码有3个分别是ABC、BCD和BDE
三、最小依赖集或最小覆盖
1.将F中的所有依赖右边化为单一元素
2.去掉F中的所有依赖左边的冗余属性.
如:X={AE}->Y
①找到左边A,E或AE的函数依赖,循环遍历求X的闭包,如果(x)+中最终包含Y,则X->Y为冗余函数依赖,删除部分函数依赖X->Y。(即x的闭包中包含Y则冗余)
四、最高规范化程度
1.1NF--存在部分依赖
2.2NF--完全依赖、存在传递依赖A->B B->C A->C(基本可消除插入异常)
3.3NF--完全依赖、没有传递依赖 (保持函数依赖,最高可以达到3NF)(属性全部是主属性,则R的最低范式3NF)(仍然存在一定的插入和删除异常)
4.BCNF--每一个表中只有一个候选码(全码组成的关系模式,最高可以达到BCNF)
五、判断无损连接
方法一:无损连接定理
关系模式R(U,F)的一个分解,ρ={R1<U1,F1>,R2<U2,F2>}具有无损连接的充分必要条件是:
U1∩U2→U1-U2 €F+ 或U1∩U2→U2 -U1€F+
方法二:算法
ρ={R1<U1,F1>,R2<U2,F2>,...,Rk<Uk,Fk>}是关系模式R<U,F>的一个分解,U={A1,A2,...,An},F={FD1,FD2,...,FDp},并设F是一个最小依赖集,记FDi为Xi→Alj,其步骤如下:
① 建立一张n列k行的表,每一列对应一个属性,每一行对应分解中的一个关系模式。若属性Aj Ui,则在j列i行上真上aj,否则填上bij;
② 对于每一个FDi做如下操作:找到Xi所对应的列中具有相同符号的那些行。考察这些行中li列的元素,若其中有aj,则全部改为aj,否则全部改为bmli,m是这些行的行号最小值。
如果在某次更改后,有一行成为:a1,a2,...,an,则算法终止。且分解ρ具有无损连接性,否则不具有无损连接性。
对F中p个FD逐一进行一次这样的处理,称为对F的一次扫描。
③ 比较扫描前后,表有无变化,如有变化,则返回第② 步,否则算法终止。如果发生循环,那么前次扫描至少应使该表减少一个符号,表中符号有限,因此,循环必然终止。
举例1:已知R<U,F>,U={A,B,C},F={A→B},如下的两个分解:
① ρ1={AB,BC}
② ρ2={AB,AC}
判断这两个分解是否具有无损连接性。
①因为AB∩BC=B,AB-BC=A,BC-AB=C
所以B→A ¢F+,B→C ¢ F+
故ρ1是有损连接。
② 因为AB∩AC=A,AB-AC=B,AC-AB=C
所以A→B €F+,A→C ¢F+
故ρ2是无损连接。
举例2:已知R<U,F>,U={A,B,C,D,E},F={A→C,B→C,C→D,DE→C,CE→A},R的一个分解为R1(AD),R2(AB),R3(BE),R4(CDE),R5(AE),判断这个分解是否具有无损连接性。
① 构造一个初始的二维表,若“属性”属于“模式”中的属性,则填aj,否则填bij
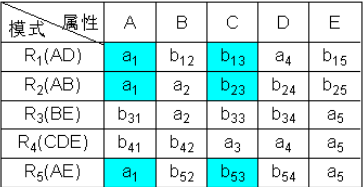
② 根据A→C,对上表进行处理,由于属性列A上第1、2、5行相同均为a1,所以将属性列C上的b13、b23、b53改为同一个符号b13(取行号最小值)。
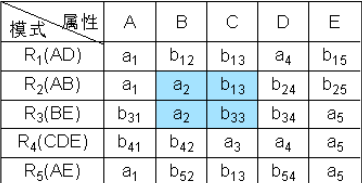
③ 根据B→C,对上表进行处理,由于属性列B上第2、3行相同均为a2,所以将属性列C上的b13、b33改为同一个符号b13(取行号最小值)。
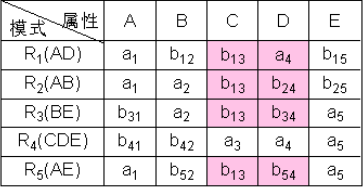
④ 根据C→D,对上表进行处理,由于属性列C上第1、2、3、5行相同均为b13,所以将属性列D上的值均改为同一个符号a4。
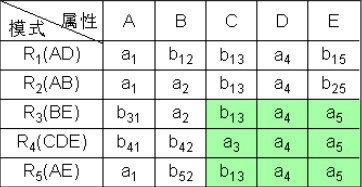
⑤ 根据DE→C,对上表进行处理,由于属性列DE上第3、4、5行相同均为a4a5,所以将属性列C上的值均改为同一个符号a3。
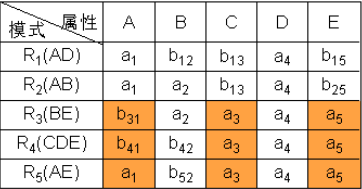
⑥ 根据CE→A,对上表进行处理,由于属性列CE上第3、4、5行相同均为a3a5,所以将属性列A上的值均改为同一个符号a1。
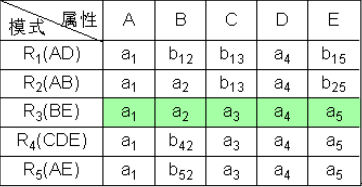
⑦ 通过上述的修改,使第三行成为a1a2a3a4a5,则算法终止。且分解具有无损连接性。
