

转摘链接:https://www.zhihu.com/question/48356514/answer/123290631
来源:知乎
著作权归作者所有。
实现 AD 有两种方式,函数重载与代码生成。两种方式的原理都一样,链式法则。
不难想象,任何计算都可以由第1步到第k步的序列形式,其中第 i 步计算的输入,在之前的 i-1 步中已经计算(例如编译器生成的汇编指令序列)。因此,任何计算都可以看作形式如下图左侧的复合函数。微积分中的链式法则告诉我们,符合函数的导数可写作下图右侧的形式(假设每一步都可导)。请注意偏导数和全导数的区别。
图一
自动微分的第一个难点就在这,微积分中的链式法则。大家在课堂上学的链式法则的示例通常只有两到三个函数,而自动微分面对的计算,有无数个函数。许多人不习惯在这样大的规模上应用链式法则。不过一旦习惯,就会发现自动微分的原理十分简单。
如果上述内容过于抽象,请参看下面这个例子以后再看一遍。
图二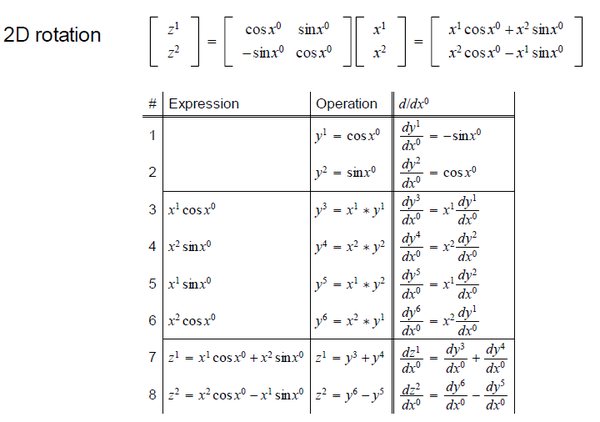
在上图中,顶部方程是二维旋转。输入 有三个变量,旋转角度及二维坐标。输出
有两个变量,即旋转后的二维坐标。上图列表第二列是该计算的序列形式,第一列是每一步对应的表达式,第三列是对应的链式法则(请对比图一)。
太繁琐了?看不出个所以然?不用担心。
如果把计算的序列形式及其导数计算每个步骤的依赖关系表示成图
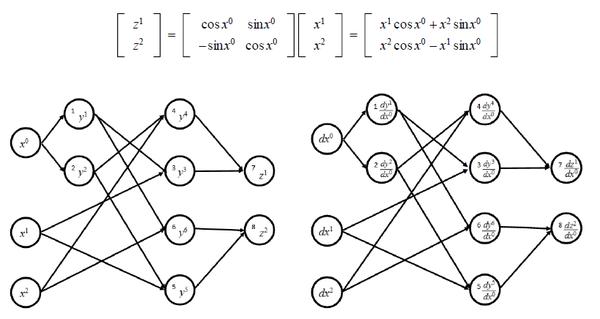
不难发现,两张图是等价的。也就是说,计算序列形式的每一步都与其导数计算的步骤有一一对应的关系。源程序怎么算,其导数就可以怎么算(从顺序上来说)。
以上便是自动微分的基本原理。下面我们来谈实现。如图二,图三,我们有两种方式来考虑自动微分的实现。
- 用户提供图二第二列序列形式的源代码,按顺序生成第三列的微分计算。此种方法的特点是,读一行源代码,生成一行微分计算,因此可以动态生成。
若源代码这一行在做乘法,那么就依据乘法法则生成该步的微分计算。若源代码这一行是三角函数 cos(x),那么它对应的微分计算就是 -sin(x),以此类推。每一步计算的偏导数都根据链式法则组合,得出该步骤的全导数。
该种方法的常见手段是函数重载。优点是简单直接,缺点是动态生成成本较高。 - 用户提供源代码,在编译时生成图三左侧的程序结构图,并生成图三右侧对应的微分程序。
该种方法的常见手段是编译时的代码生成(比如用 flex-bison 做词法、语法分析)。优点是静态生成效率高,一次生成,多次使用。缺点是编译原理有门槛,非计算机专业望而却步。
力求简单,下面给出以函数重载实现的简单示例 SAD - Simple Automatic Differentiation。请对照图二中的列表阅读。
main 函数中对应图二表中第二列,2D 旋转的计算。ADV 里重载的 +, -, *, sin, cos 不仅完成本来的计算,还负责图二表中第三列导数的计算。
main 函数中 x, y, z 的序号都与图二中对应。
1 #include <cmath> 2 #include <vector> 3 #include <iostream> 4 namespace SAD // Simple Automatic Differentiation 5 { 6 class ADV 7 { 8 public: 9 ADV(double v = 0, double d = 0); 10 11 // overloaded unary and binary operators 12 ADV operator + (const ADV &x) const; 13 ADV operator - (const ADV &x) const; 14 ADV operator * (const ADV &x) const; 15 friend ADV sin(const ADV &x); 16 friend ADV cos(const ADV &x); 17 18 double val; // value of the variable 19 double dval; // derivative of the variable 20 }; 21 22 ADV::ADV(double v, double d) : val(v), dval(d) {} 23 24 ADV ADV::operator+(const ADV &x) const 25 { 26 ADV y; 27 y.val = val + x.val; 28 y.dval = dval + x.dval; 29 return y; 30 } 31 32 ADV ADV::operator-(const ADV &x) const 33 { 34 ADV y; 35 y.val = val - x.val; 36 y.dval = dval - x.dval; // sum rule 37 return y; 38 } 39 40 ADV ADV::operator*(const ADV &x) const 41 { 42 ADV y; 43 y.val = val*x.val; 44 y.dval = x.val*dval + val*x.dval; // product rule 45 return y; 46 } 47 48 ADV sin(const ADV &x) 49 { 50 ADV y; 51 y.val = std::sin(x.val); 52 y.dval = std::cos(x.val)*x.dval; // chain rule 53 return y; 54 } 55 56 ADV cos(const ADV &x) 57 { 58 ADV y; 59 y.val = std::cos(x.val); 60 y.dval = -std::sin(x.val)*x.dval; // chain rule 61 return y; 62 } 63 } 64 65 66 int main() 67 { 68 using namespace SAD; 69 using namespace std; 70 71 static const double PI = 3.1415926; 72 vector<ADV> x; 73 74 x.emplace_back(PI, 1); // x = [PI, 2, 1] 75 x.emplace_back(2, 0); 76 x.emplace_back(1, 0); 77 78 ADV y1 = cos(x[0]); 79 ADV y2 = sin(x[0]); 80 ADV y3 = x[1] * y1; 81 ADV y4 = x[2] * y2; 82 ADV y5 = x[1] * y2; 83 ADV y6 = x[2] * y1; 84 85 ADV z1 = y3 + y4; 86 ADV z2 = y6 - y5; 87 88 cout << "x = [" << x[0].val << ", " << x[1].val << ", " << x[2].val << "]" << endl; 89 cout << "z = [" << z1.val << ", " << z2.val << "]" << endl; 90 cout << "[dz1/dx0, dz2/dx0] = [" << z1.dval << "," << z2.dval << "]" << endl; 91 }
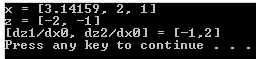
矢量 [2,1] 被旋转 180° , 变为 [-2,-1]。关于角度的导数为 [-1,2]。
自动微分的经典教材是该题目的奠基人 Griewank 著的 Evaluating Derivatives
(Society for Industrial and Applied Mathematics)
该书囊括了自动微分的所有方面,比如本文未介绍的 reverse mode, sparse Jacobian, Hessian 等。
如果不求全面,一本更通俗更面向代码实现的书是 The Art of Differentiating Computer Programs
(Society for Industrial and Applied Mathematics)
最后,自动微分是算导数的最优方法,比符号计算、有限微分更快更精确。
自动微分已经广泛应用在优化领域,包括人工神经网络的训练算法 back-propagation。
要解连续优化或非线性方程,自动微分是不二的选择。
几何福利(自动微分的张量推导)
刚才是科普,下面给出自动微分的张量公式,及其对应的,便于编程实现的矩阵公式。
图一的计算序列可以记作如下形式
其中是自变量
是中间变量
是因变量 他们可以是任意维度
微分流形上的矢量有两种:切空间 (Tangent space)的矢量,对偶空间 (Dual space)的矢量。
其中切空间的基 是关于坐标系的偏导算符
对偶空间的基是关于坐标系的微分
从切矢量出发 我们可以得到自动微分的正序模式 (forward mode)
从对偶矢量出发 我们可以得到自动微分的逆序模式 (reverse mode)
任意切矢量 的定义是其对应的方向导数算符
将它依次应用在计算序列的左边 便可获得下图左侧的张量公式
对张量缩并可得上图右侧的矩阵公式 其中 便是一阶导 Jacobian 矩阵
这种计算导数的方式与计算序列同序 故名正序模式
每一个方向导数的计算复杂度与计算序列相同 空间复杂度也相同
注意 若计算序列的自变量有 n 维 则获得 Jacobian 矩阵需要计算 n 个方向上的方向导数
任意对偶矢量 的定义是其对应方向的微分
对该矢量做关于坐标基 的坐标变换 便可获得下图左侧的张量公式
对涨量缩并可得上图右侧的矩阵公式 其中 D += TP 表示叠加 D = D + TP 便是关于
的一阶导
这种计算导数的方式与计算序列逆序 故名逆序模式
展开每一个基底 的计算复杂度与计算序列相同 但由于内存访问的顺序与计算序列相逆 所有中间结果都需要保存下来 因而空间复杂度与计算复杂度相当
若计算序列的因变量有 m 维 则获得 Jacobian 矩阵需要展开 m 个基底
