
lucene如何通过docId快速查找field字段以及最近距离等信息?
http://www.cnblogs.com/LBSer/p/4419052.html
1 问题描述
我们的检索排序服务往往需要结合个性化算法来进行重排序,一般来说分两步:1)进行粗排序,这一过程由检索引擎快速完成;2)重排序,粗排序后将排名靠前的结果发送给个性化服务引擎,由个性化服务引擎进行深度排序。在我们的业务场景下检索引擎除了传递doc列表,还要传业务字段如商家id以及用户位置与该doc的最近距离。
我们的检索引擎基于lucene,而lucene查询的结果只包含docId以及对应的score,并未直接提供我们要传给个性化服务的业务字段列表以及对应的距离,因此本文要解决的问题是:如何根据docId快速查找field字段以及该doc对应的距离?
2 传统方法—从正排文件中获取数据
通过倒排检索得到的是docId,而直观上看可以根据docId从正排中得到具体的doc内容字段例如dealId等。
首先需要将数据写入正排,如果没写入当然就查询不了。如何写入呢?我们将dealId(DealLuceneField.ATTR_ID)、该deal对应的经纬度字符串(DealLuceneField.ATTR_LOCATIONS,多个时以“,”分隔)写入索引中,Field.Store.YES表示将信息存储在正排里,lucene会将正排信息存放在fdx、fdt两个文件中,fdt存放具体的数据,fdx是对fdt的一个索引(第n个doc数据在fdt中的位置)。
Document doc = new Document(); doc.add(new StringField(LuceneField.ATTR_ID, String.valueOf(id, Field.Store.YES)); doc.add(new StringField(LuceneField.ATTR_LOCATIONS, buildMlls(mllsSet, id), Field.Store.YES));
如何查询呢?
1)直接查询
通过docId直接查询得到document,并将document的内容取出,比如取出经纬度字符串后需要计算最近的距离。
for (int i = 0; i < sd.length; i++) {
Document doc = searcher.doc(sd[i].doc); //sd[i].doc就是docId,earcher.doc(sd[i].doc)就是根据docId查找相应的document
didList.add(Integer.parseInt(doc.get(LuceneField.ATTR_ID)));
if (query.getSortField() == DealSortEnum.distance) {
。。。
String[] mlls = locations.split(" ");
double dis = findMinDistance(mlls, query.getMyPos()) / 1000;
distBuilder.append(dis).append(",");
}
}
在实际运行中,根据docId获取经纬度信息并计算最短距离这一过程将耗费8ms左右,而且有的时候抖动至20多ms。
2)优化查询
直接查询时将返回所有Field.Store.YES的field数据,而事实上我们仅需要获取id、localtion这两个field的数据,因此优化方法是调用doc函数时传入需要获取的field集合,这样避免获取了整个数据带来的开销。
for (int i = 0; i < sd.length; i++) {
Document doc = searcher.doc(sd[i].doc, fieldsToLoad);
didList.add(Integer.parseInt(doc.get(LuceneField.ATTR_ID)));
if (query.getSortField() == DealSortEnum.distance) {
String locations = doc.get(LuceneField.ATTR_LOCATIONS);
String[] mlls = locations.split(" ");
double dis = findMinDistance(mlls, query.getMyPos()) / 1000;
distBuilder.append(dis).append(",");
}
}
然而在实际应用中相对于直接查询性能上并未有所提升。
原因有两点:1)使用Field.Store.YES的字段较少,除了id和location之外,只有两个field存进正排索引中,这种优化对于大量field存储进正排索引才有效果;2)从正排获取数据底层是通过读取文件来获得的,虽然我们已经通过内存映射打开索引文件,但是由于每次查询还需要定位解析数据,浪费大量开销。
3 优化方法1—从倒排的fieldcache中获取数据
从正排获取dealId以及location这两个字段的数据比较缓慢,如果能将这两个字段进行缓存那么将大大提高计算效率,比如类似一个map,key是docId,value是dealId或者mlls。可惜lucene并未向正排提供这种缓存,因为lucene主要优化的是倒排。
在lucene中,一些用于排序的字段,比如我们使用的“weight”字段,为了加快速度,lucene 在首次使用的时候将该“weight”这个field下所有term转换成float(如下图所示),并存放入FieldCache中,这样在第二次使用的时候就能直接从该缓存中获取。
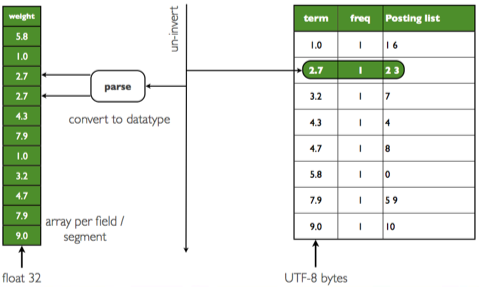
FieldCache.Floats weights = FieldCache.DEFAULT.getFloats(reader, "weight", true); //获取“weights”这一field的缓存,该缓存key是docId,value是相应的值 float weightvalue = weights.get(docId); // 通过docId获取值
for (int i = 0; i < sd.length; i++) {
。。。
if (query.getSortField() == DealSortEnum.distance) {
BytesRef bytesRefMlls = new BytesRef();
mllsValues.get(sd[i].doc, bytesRefMlls);
String locations = bytesRefMlls.utf8ToString();
if (StringUtils.isBlank(locations))
continue;
String[] mlls = locations.split(" ");
double dis = findMinDistance(mlls, query.getMyPos())/1000;
distBuilder.append(dis).append(",");
}
}
通过这种方式优化之后根据docId获取经纬度信息并计算最短距离这一过程平均响应时间从8ms降低为2ms左右,即使抖动响应时间也不超过10ms。
4 优化方法2—使用ShapeFieldCache
使用fieldcache增加了内存消耗,尤其是location这一字段,这里面存放的是该文档对应的经纬度字符串,对内存的消耗尤其巨大,尤其是某些文档的location字段存放着几千个经纬度(这在我们业务场景里不算少见)。
事实上我们不需要location这一字段,因为我们在建立索引的时候已经通过如下方式将经纬度写入到索引中,而且lucene在使用时会一次性将所有doc对应的经纬度都放至ShapeFieldCache这一缓存中。
for (String mll : mllsSet) {
String[] mlls = mll.split(",");
Point point = ctx.makePoint(Double.parseDouble(mlls[1]),Double.parseDouble(mlls[0]));
for (IndexableField f : strategy.createIndexableFields(point)) {
doc.add(f);
}
}
查询代码如下。
StringBuilder distBuilder = new StringBuilder();
BinaryDocValues idValues = binaryDocValuesMap.get(LuceneField.ATTR_ID);
FunctionValues functionValues = distanceValueSource.getValues(null, context);
BinaryDocValues idValues = binaryDocValuesMap.get(LuceneField.ATTR_ID);
for (int i = 0; i < sd.length; i++) {
BytesRef bytesRef = new BytesRef();
idValues.get(sd[i].doc, bytesRef);
String id = bytesRef.utf8ToString();
didList.add(Integer.parseInt(id));
if (query.getSortField() == SortEnum.distance) {
double dis = functionValues.doubleVal(doc)/1000;
distBuilder.append(dis).append(",");
}
}
a)进一步优化
上面方法节省了内存开销,但未避免计算开销。我们知道lucene是提供按距离排序功能的,但是lucene只是完成了排序,并告诉我们相应的docId以及score,但并未告诉我们每个deal与用户的最近距离值。有没有什么方法能将距离保存下来呢?
我的方法是通过改写lucene的collector以及lucene使用的队列PriorityQueue,通过重新实现这两个数据结构从而将距离值保存为score,这样就避免了冗余计算。核心代码如下:
@Override
protected void populateResults(ScoreDoc[] results, int howMany) {
// avoid casting if unnecessary.
FieldValueHitQueue<SieveFieldValueHitQueue.Entry> queue = (FieldValueHitQueue<FieldValueHitQueue.Entry>) pq;
for (int i = howMany - 1; i >= 0; i--) {
FieldDoc fieldDoc = queue.fillFields(queue.pop());
results[i] = fieldDoc;
results[i].score = Float.valueOf(String.valueOf(fieldDoc.fields[0])); //记录距离
}
}
这样优化后,获取数据的平均响应时间从2ms将至0ms,且从未出现抖动。
此外由于避免了在内存中加载location这个字段,gc的响应时间下降一半,服务整体平均响应时间也下降许多。
5 展望
针对如何通过docId快速查找field字段以及最近距离等信息这一问题,本文提供了多种方法并一一尝试,包括从正排文件获取,从倒排fieldcache里获取,以及经纬度从ShapeFieldCache获取。此外通过改造lucene的收集器和队列,避免了距离的二次计算。上述这些优化大幅度提升了检索服务的性能。
通过docId获取field数据的方式还有很多,例如docvalue等,以后将对这些方法进行探索。
检索实践文章系列:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号