游戏架构设计:内存管理
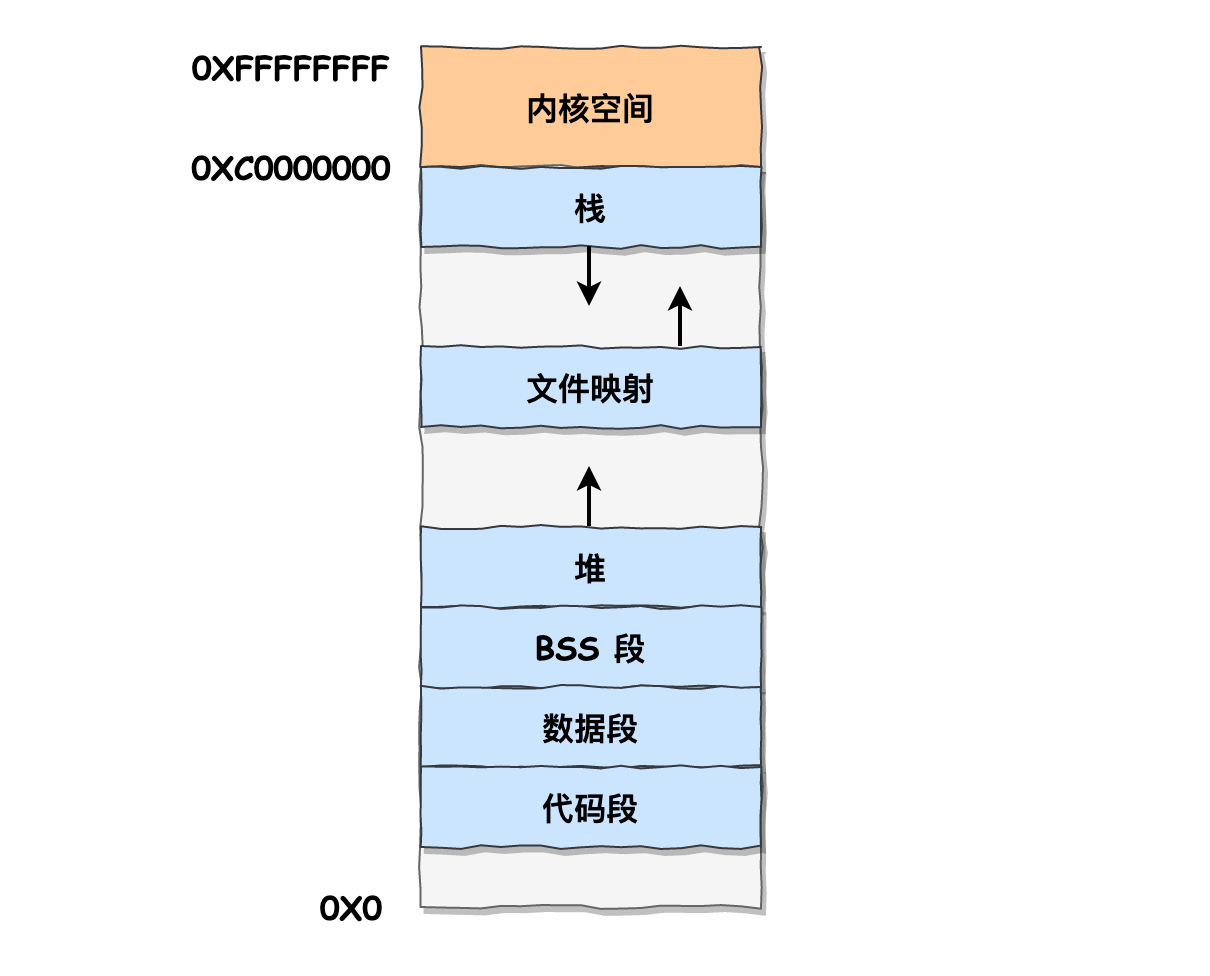
内存总览
对 C++ 游戏程序员来说,内存管理是一件相当头疼的问题。因为 C++ 是将内存赤裸裸的交给程序员,而不像 Java/C# 有垃圾回收(GC)机制。好处是我们可以根据需求定制自己的高性能内存管理机制,实现高性能的游戏程序,但是就需要 C++ 程序员对内存知识的掌握需要非常深刻(涉及到 C++ 语言、操作系统、计算机组成原理等层面),否则很难 hold 住。
内存分页与虚拟内存机制
现代操作系统往往使用 页式内存管理:将内存划分为一个个页(page),每个页都是相同大小的划分单位。
实际上,现代操作系统是段页式内存管理,只是段式管理没那么重要了,其更多意义上是旧操作系统遗留下来的产物(更早期的操作系统是纯段式内存管理,后来才演化出了段页式)。
内存在逻辑上虽然仍保有分段的概念,但是由于x64操作系统的内存空间巨大,本身就可以容纳巨量的分页,可直接通过页索引找到指定段的某个分页;也就是说,段寄存器的基址绝大部分情况下都会被设为 0,操作系统已经很少会使用硬件分段了。这样的设计有助以简化操作系统的设计,只不过在特殊的系统保护模式下,段寄存器仍然会被正常使用,从硬件层面隔绝非法越段访问。
不同的设备可能拥有不同的物理页大小,但大部分为如下情况:
- PC:4KB
- android 设备:4KB
- IOS 设备:iphone6s 及以后为 16KB,老设备为 4KB
现代操作系统还支持大小页分配,例如支持大中小页分配(4KB、2MB、1GB),从而优化大量连续页查询页表的开销。但这些都是在操作系统逻辑层面上的操作,与物理页大小无关。因此我们最好要假设 4KB 为最基本的页单位,因为不会有比这个更小的页大小。
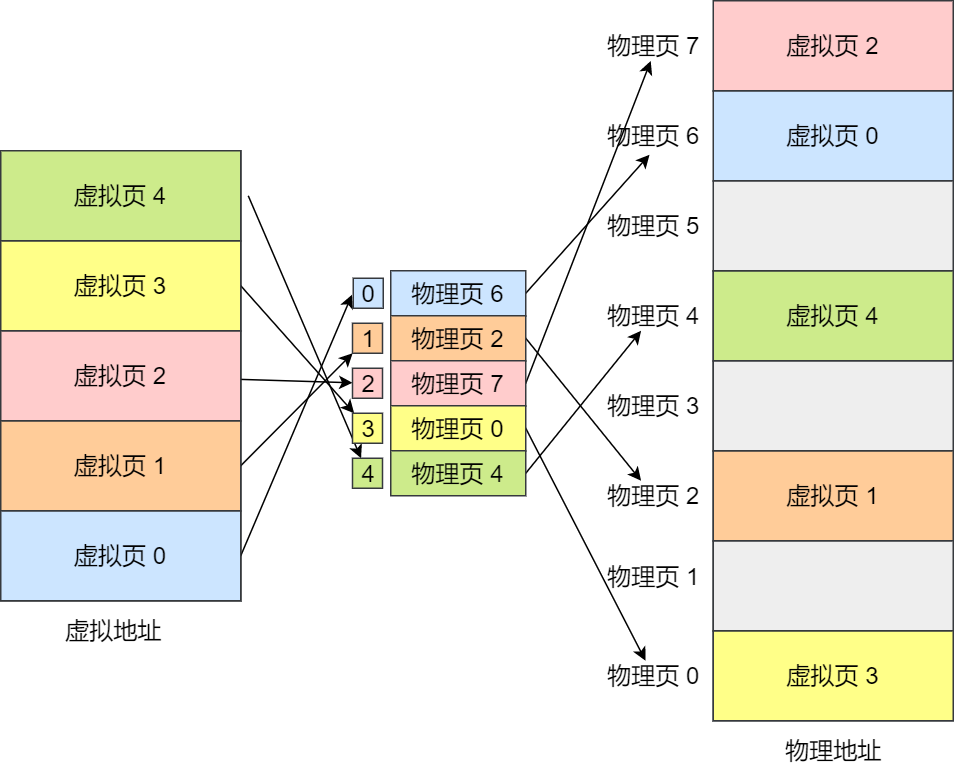
现代操作系统往往还采用虚拟内存机制:提供给用户超大的虚拟内存空间,该虚拟内存空间同样划分为一个个页(虚拟页),每个有效的虚拟页会通过页表机制映射到对应的物理页。
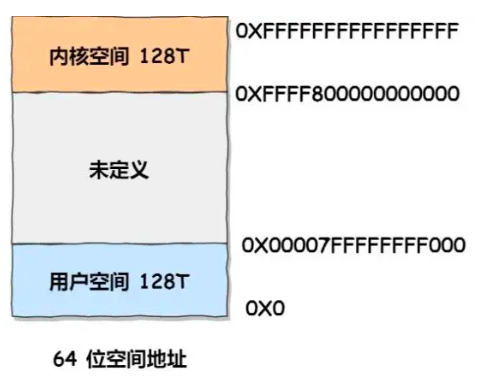
更具体地,每个进程有自己独立的虚拟内存空间,而其中还划分成了高地址部分的内核空间和低地址部分的用户空间。
虽然每个进程都各自有独立的虚拟内存,但是每个虚拟内存中的内核地址,其实关联的都是相同的物理内存。
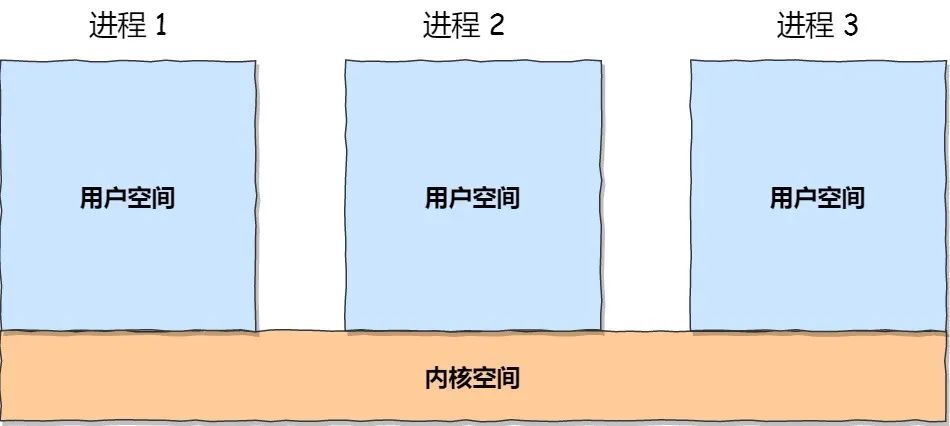
内核空间与用户空间的区别:
- 进程在用户态时,只能访问用户空间内存。
- 只有进入内核态后,才可以访问内核空间的内存。
在调用系统调用时,操作系统会从用户态切换到内核态,会比较耗时,因此要尽量避免系统调用。
多级页表与 TLB
页表机制采用了多级页表,但是我们知道多级页表是放在内存中,访问页表本身也是一种访存行为,会造成 memory bound。因此,硬件还额外设计了一块专门用于加速访问页表的 cache,称为 TLB(快表)。
这部分不多赘述。
内存交换(Swap)
虚拟内存提供的是一个超大的内存空间,反而机器的实际物理内存往往是不够虚拟内存空间大的,因此才有了虚拟内存的另一重要技术:Swap 机制,将外存(硬盘)作为额外的物理存储介质,并通过一定的换入换出机制(物理内存不足时将暂时用不上的某些物理内存数据换出到外存里存储,需要用到时再换入到物理内存中),使得用户感受到似乎在使用着一个超大的内存空间。
Swap 机制可以提供一个超大的虚拟内存空间,但是其要进行换入换出就必须得进行外存 IO,会给系统引入额外的延迟。其本质上就是在利用时间换空间。
zRAM
zRAM 技术 是一种辅助 Swap 机制的软件方法,其核心就是:首先,对物理内存专门划分出一块区域称为 zRAM;当物理内存不足时,将本该需要换出到外存的物理内存页进行某种压缩算法,压缩并放置到物理内存的 zRAM 上。当需要用到该物理内存页时,再把 zRAM 里对应的压缩页数据解压出来。
zRAM 技术可以避免外存 IO(因为 zRAM 本身就在物理内存上),其压缩/解压内存的速度也只是略慢于直接访问内存的速度,其唯一缺点是并不能像外存那样提供大量的物理空间(但实际上大部分时候虚拟内存换出的内存也不会多得特别夸张)。
例如 zRAM 假设采用的是 lz4hc-0 压缩算法,那么压缩率会约为 1/4,平均读取时延约为 0.003ms(硬盘平均读取时延约为 1ms,直接访问内存平均读取时延约为 0.0001ms)。
移动端虚拟内存
对于移动端设备来说,其物理内存即为运行内存,外存即为手机存储。然而虚拟内存的 Swap 技术并不适用与移动端设备,这因为手机存储的硬件特性是读写寿命短(读写次数稍微多了,其存储寿命会短得很快)。
因此移动端设备在内存不足时,不会采用基于外存内存交换的 Swap 技术,而是采用以下策略:
- 物理内存轻微不足时:
- 删除干净页。
- zRAM 技术:压缩不常用的脏页到 zRAM。
- 物理内存继续不足时:
- 各进程通知 memory warning。收到通知的进程可以尝试调用自定义函数来主动释放一些内存空间。
- 物理内存严重不足时:
- low memory killer:直接按优先级一个一个干掉进程,直到物理内存足够为止。
虚拟内存分配
mmap & munmap
读写文件通常是通过以下系统调用来进行的:
read() :文件内容先缓存进内核空间的 page cache 里,然后再将 page cache 的内容拷贝到用户空间的 buffer 中。write():在将修改后的用户空间 buffer 内容复制到内核空间的 page cache 上,然后内核空间再把 page cache 的内容立即回写到文件上。
read(fd, buffer, 4096); // 读取文件的内容到buffer
... // 修改buffer的内容
write(fd, buffer, 4096); // 把buffer的内容写入到文件
而 mmap() 是一个建立内存映射的系统调用,该调用可以被用于建立文件映射或者匿名映射。
当通过 mmap 来建立 文件映射:在逻辑上可以理解将一段虚拟空间映射到外存文件,这段虚拟内存的页会被称为文件页。而更具体的行为是文件内容其实会先缓存进内核空间的 page cache 里,然后将用户空间的一段虚拟内存直接映射到 page cache。
page cache 是操作系统内核态管理的一段内存区域,专门用来优化 I/O 传输的一个缓冲区域。当然其也与DMA等硬件技术息息相关,不多展开。
- 用户可以通过读写这段虚拟内存的内容来直接读写内核空间上的 page cache,避免了 buffer 拷贝的开销以及用户态的切换。
- 如果修改了 mmap 分配的虚拟内存(逻辑上相当于写入文件),page cache 并不会立即回写到文件上。这就意味着,可以多次修改 page cache 并一次回写到文件(相当于多次写入合并成一次落盘)。
- 干净页(clean page):未修改过的文件页都是干净页。物理内存不足时,干净页的物理内存可以被直接丢弃掉,因为以后有需要时再从外存重新读取就可以了。
- 脏页(dirty page):被修改过并且暂时还没落盘的文件页。脏页的物理内存需要等落盘以后才能被回收。
- ...
在处理大文件/频繁访问文件的情况,我们应当利用 mmap 来读写文件而非传统的 read/write。windows 自己也有类似作用的 mmap 函数。
当通过 mmap 来建立 匿名映射:将用户空间的一段虚拟内存直接映射到某段物理内存,这段虚拟内存的页会被称为匿名页。
匿名映射常被用来分配动态内存(malloc),本质上就和文件读写没有关系了,只是 Linux 系统的设计思想是“一切皆是文件”。
malloc & free
malloc 是 C 标准库里的动态内存分配函数。不过要注意,在现代操作系统中,其作用仅仅是分配虚拟内存空间,并不是分配物理内存空间;当其分配的虚拟内存第一次被访问后才会真正分配物理内存空间(OS的写时分配行为)。
实际上 malloc 只是 C 语言中的一个标准,其实现是有很多个版本的,并且每个实现版本的设计(例如如何管理 malloc 自带的内存池)都有一定程度的差异,各有各特色和优势。如
ptmalloc、jemalloc、tcmalloc等。
虽然 C/C++程序员也对 malloc/free 的使用比较熟悉,但是也应适当了解下它的基本实现:
-
首先,由于用户在使用 free 的时候的参数只有一个地址(而没有内存尺寸信息),因此需要在分配所得的内存块前塞入 header 数据(包含内存尺寸等信息)。也因此在用 malloc 请求分配内存时,实际分配的内存往往会大于请求内存的,因此其分配在空间利用上是有一定损失的(尤其分配越小的内存块空间利用率越低)。
-
其次,malloc 分配可以保证所返还的内存首地址是自动对齐的(windows x64 大都为8字节,Linux x64 大都为16字节,得看具体)。
-
然后,malloc 并不一定会调用系统调用,其行为大致如下:
-
首先,尝试在自己的内存池里找有没有可重用的空闲内存空间,如果没有才会进行系统调用。
-
如果用户分配的内存小于 128 KB(不同环境默认值可能不同),会通过系统调用
brk()申请内存 :根据分配大小将堆顶指针往上移一定的位置,并将返还对应的内存块地址。当 free 掉 brk() 方式分配的内存时,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用。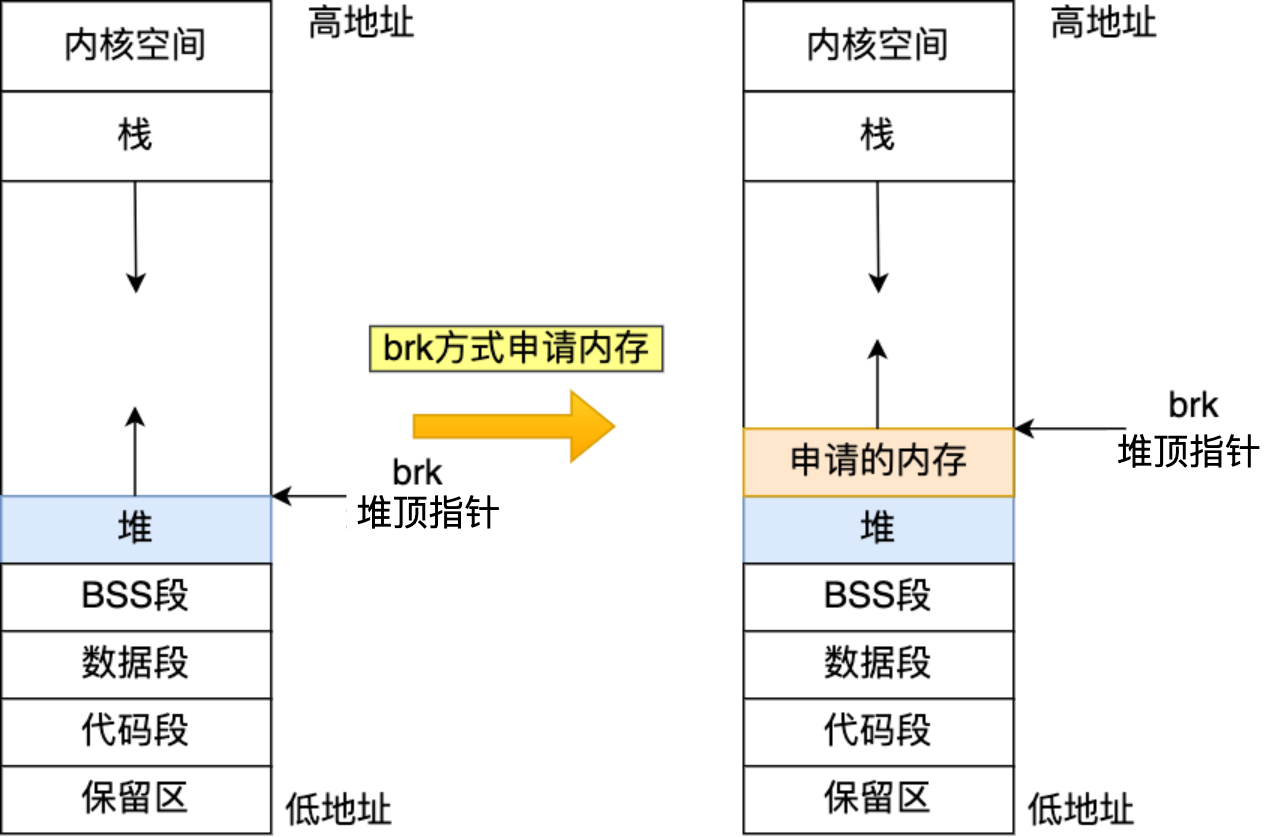
-
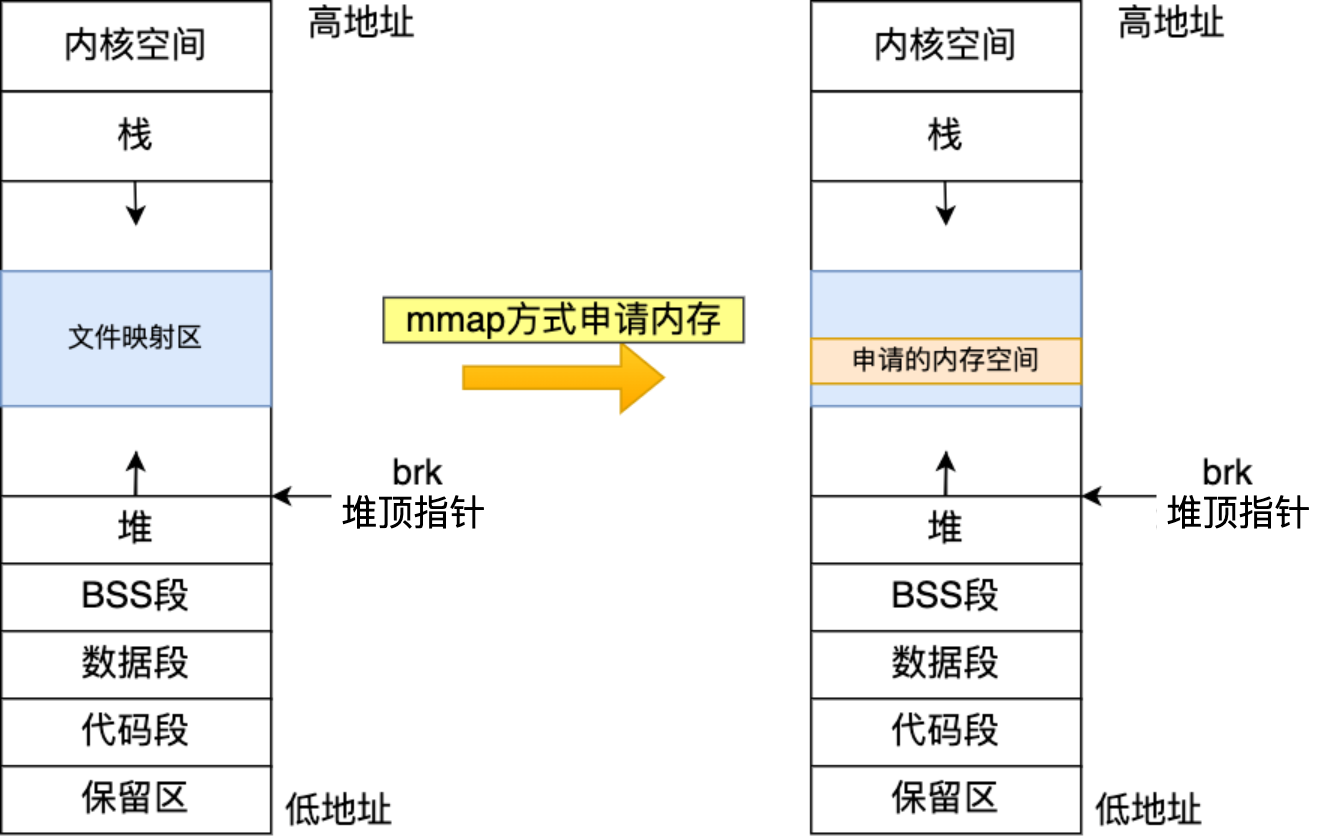
如果用户分配的内存大于 128 KB(不同环境默认值可能不同),则通过系统调用
mmap()申请内存:建立匿名映射来获取虚拟内存。当 free 掉 mmap() 方式分配的内存时,其实会调用munmap()来把内存归还给操作系统,即内存得到真正的释放。
-
new & delete
C++ 的 new/delete 与 C 的 malloc/free 的区别是八股老生常谈的问题了,无非就是 new/delete 在调用 malloc/free 的基础上,额外对 non-trivial class object 调用构造函数/析构函数(当然对于 trivial objects 是不用额外处理的)。而类似地,new[]/delete[] 的行为是在调用 malloc/free 的基础上,额外遍历 non-trivial class objects 并调用它们的构造函数/析构函数(同样,对于 trivial objects 是不用额外处理的)。
但是需要额外注意的是,delete[] 的参数是没有记录 object 数量的,因此在使用 new[] 来分配 non-trivial objects 时是需要额外又插入多一个 header 信息用来存放 objects 数量的,从而保证调用析构函数的次数是和实际 object 数量一致的。
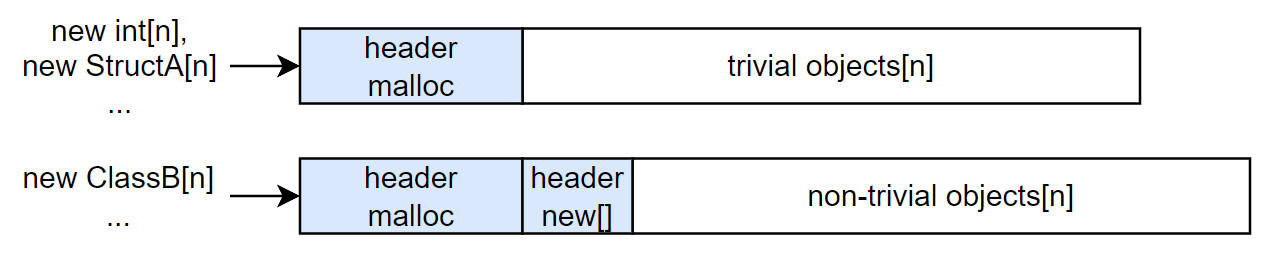
可能有人疑惑为什么不用 malloc 的尺寸大小除于元素类型大小来得出 object 数量,其实可以举个例子:假如我们使用 new[] 分配了一些子类对象,而使用 delete[] 的指针时用的可能是指向基类的指针,而编译器无法确定元素类型的实际大小(可能是基类的大小,也可能是子类的大小)。
内存分配潜在的问题
内存泄露
do{
T* object = new T();
}while(0);
上面的例子中。忘记回收内存,函数退栈导致丢失了object指针,就再也找回不了 new 的内存地址,这时内存一直就会被占用着。内存泄漏很容易理解,不作多讲。
内存碎片 & 内存扩散
用户对堆内存的分配/释放的顺序往往是很随机乱序的。在 malloc 多次分配内存后再释放掉其中某块内存,此时就会产生“洞”。
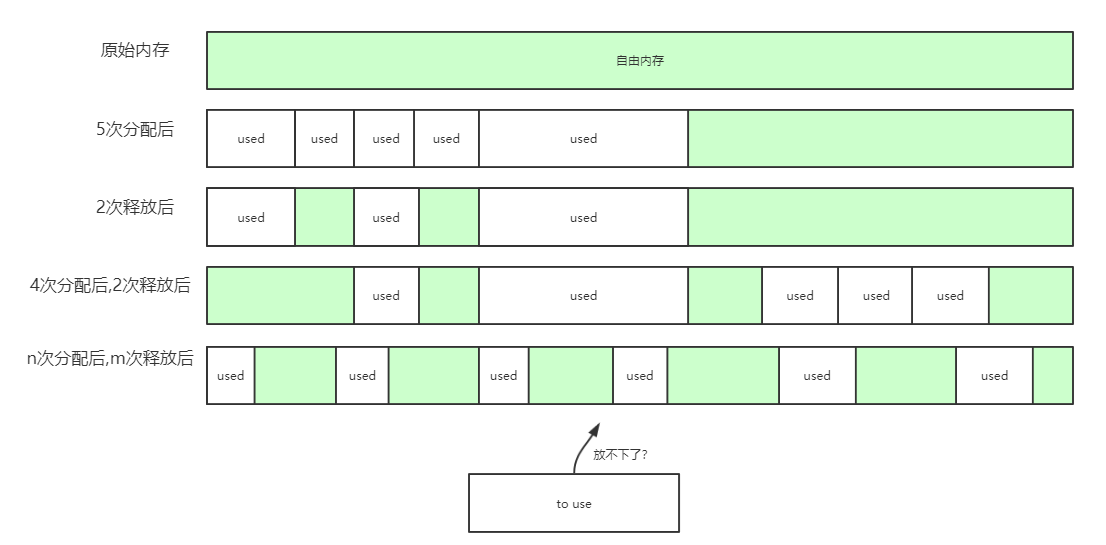
并且随着时间推移,堆内存越来越多出现这些“洞”,导致可用的自由内存块被拆分成越来越多个不连续的内存块。这就可能导致如下问题:
- 内存碎片:因为被过多的碎片切割了自由内存,即使自由内存表面上有足够的空间分配,但分配请求仍然可能会失败。
- 内存扩散(memory diffusion):多次连续分配的内存在物理空间上越来越不容易连续,从而导致 cache 命中率越来越低,造成了整个系统的运行效率越来越低。
内存地址对齐
很多指令是要求内存对齐为 4 字节或者 8 字节边界,否则会出现性能问题(例如需要插入额外访存指令)或错误结果。而 malloc 分配可以保证所返还的内存首地址是自动对齐的(windows x64 大都为8字节,Linux x64 大都为16字节,得看具体),这似乎并不需要程序员额外再进行处理。
但是在游戏程序中,我们常常还需要使用特殊的指令(例如 SSE/AVX 等 SIMD 指令),要发挥它们的作用就会要求 16/32/64 等字节对齐;除此之外,还可能有特殊的地址位运算也是需要提供特定对齐的内存分配方式。
C++17 提供了一定的特性来支持特殊对齐的内存分配:
// C++17 对类型使用 alignas(n) 来使得该类型变量在被构建时,会对齐到 n 字节边界。
struct alignas(16) XXX{
//...
};
// C++17 可以分配对齐 n 的栈内存,并通过 reinterpret_cast 强转成所需要的类型指针。
std::aligned_storage<sizeof(XXX), 16>::type buffer;
// C++17 可以通过 std::aligned_alloc 分配首地址对齐 n 字节的堆内存。
void* ptr = std::aligned_alloc(16, sizeof(XXX));
多线程环境
内存的分配和释放还需要考虑多线程环境,尽管 malloc/free 本身是线程安全的,但是代价是其内部均需要加全局锁,造成一定的性能下降。
铺垫了这么多内存的操作系统、计算机组成原理、C++底层等层面的知识,对我们游戏程序员来说有什么用?虽然可以说是巩固自己的计算机基础知识,知根知底可以更好理解一些工作中遇到的罕见错误...
但个人觉得最重要的是可以借鉴现代操作系统的内存设计:现在很多游戏都是开放世界游戏,各类系统都有可能需要支持 streaming 特性,而这个 streaming 其实就是和虚拟内存系统非常相似。例如更具体地,工业界已经有一些 virtual texture/virtual shadow map 等功能都是 streaming 特性,如果我们以后要改进它们的设计,就离不开参考现代操作系统设计。
内存分配策略
尽管 malloc 往往都有一些减少系统调用的现代化设计,然而我们还是需要尽量减少使用 malloc 的次数;而另一边,C++ STL 也提供了一些 allocator 的 API,但是对高性能程序来讲,还是有很多的可改进空间(而且往往需要在不同的地方使用不同的内存分配策略),因此自定义的内存分配还是很有必要的。
而常见内存分配策略大都会基于内存池(memory pool):预先通过 malloc 预先得到一大块内存(往往称为 memory arena),并制定好一系列的再分配/释放策略。当程序员需要申请小块内存(往往称为 block)时,就可以向这个内存池请求来获得而非通过 malloc。
- 由于内存池本身往往内存占用比较大,所以内存池本身的释放不易产生内存碎片。即使程序员由于操作失误导致内存池内部出现内存碎片或者内存泄漏问题,但是整个内存池本身只要正确释放,内存问题就不会向外扩张。
- 尽可能减少了使用 malloc 的次数:一次性分配大内存,避免了多次使用 malloc 分配操作引入的开销;因为 malloc 可能会调用系统调用,耗时更多。
那么接下来就是内存池如何再分配内存给程序员使用的问题了。以下将要介绍的分配器均为单一的分配策略设计,在实践中我们常常需要根据需要来组合策略一起使用。
内存地址对齐特定大小
如果我们自己来管理内存分配,就可以灵活地提供分配地址对齐特定大小的内存。
更具体地,例如我们可以先使用 malloc 分配一块内存,并将其首地址处不对齐的部分当成不可用的区块,并由首地址向后移动得一个满足对齐的地址将其返还给用户(当然也意味着我们这块内存有一点点的空间浪费)。这样即便没有 C++17 特性也不影响我们的实现。
多线程安全分配器
多线程安全内存分配器的原始实现都是直接在分配/释放内存时加锁,但这会让分配/释放内存的效率变得较低。因此在设计内存分配的策略时,不仅需要考虑多线程安全,同时还需要考虑如何尽可能减少锁的使用。
- 参考常见内存分配实现的 local free list、TLS 等技术,不多展开。
- 部分上锁操作可以换成原子操作。
- ...
栈式分配器(Stack Allocator)
栈分配器的核心思想是:在接管内存池后,它只会不断地再分配内存块出去,但释放内存行为却不做任何操作(除非栈分配器主动释放掉整个内存池,那就意味着之前再分配出去的各个内存块都会一起被销毁)。
栈分配器的实现是非常简单的,只要维护一个顶端指针。指针以下的内存是已分配的,以上的内存是未分配的。
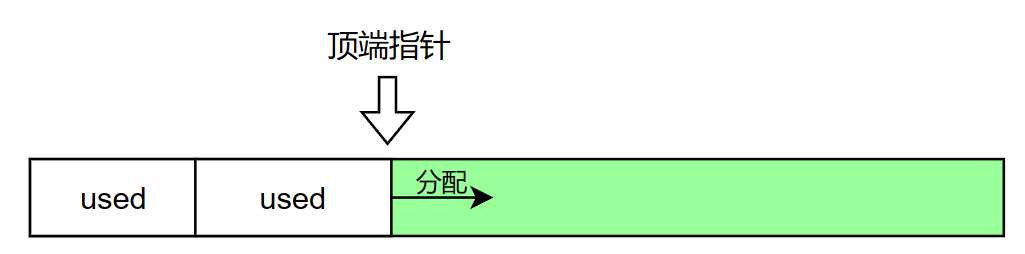
class StackAllocator{
public:
//给定总大小,构建一个栈式分配的内存池,内存资源来源于malloc/new
StackAllocator(uint32_t statckSize_bytes);
//释放掉整个内存池
~StackAllocator();
//从顶端指针分配一个新的内存块,并将顶端指针移上相应的位移大小。
void* alloc(uint32_t size_bytes);
//不做任何操作
void deallocate(void*);
//重置顶端指针为 0
void clear();
private:
uint32_t top; //顶端指针
uint32_t size; //内存池尺寸
void* pool; //内存池
};
总结其特点如下:
- 高效的内存分配(只需移动顶端指针)及释放(无任何操作)操作。
- 内存空间利用率较低:因为栈式分配器只会不断分配内存直至内存池满载,而不能释放其中任何单个块的内存(除非释放整个内存池)。
最后的缺点其实是比较痛苦的,因此我们常常会根据需要改进成我们所需要的栈式分配器来让它变得可用起来。
基于栈区/静态存储区的内存资源
栈式分配器的内存资源一般是来源于 malloc(即来源于堆空间)。而另一种实现是我们可以让其内存资源来源于栈区或静态存储区。
总结其特点如下:
- 这种实现可以让我们快速构造分配器对象,因为它完美避开了任何 malloc 调用:不再需要 malloc 出一个内存池,而只需要传入一个缓冲区地址及其尺寸信息。
- 这种方式尤其适合临时的小容器、小字符串(SSO优化)使用。
class StackAllocator{
public:
//传入一个在栈上/静态存储区上的缓冲区地址及其尺寸信息
StackAllocator(void* buffer, uint32_t size_bytes);
//不做任何操作
~StackAllocator();
//从顶端指针分配一个新的内存块,并将顶端指针移上相应的位移大小。
void* alloc(uint32_t size_bytes);
//不做任何操作
void deallocate(void*);
//重置顶端指针为 0
void clear();
private:
uint32_t top; //顶端指针
uint32_t size; //缓冲区尺寸
void* buffer; //缓冲区
};
void test()
{
char buffer[255];
StackAllocator allocator(buffer, 255);
// do something with allocator...
}
只是要注意,缓冲区的生命周期最好要大于或等于这种分配器对象的生命周期,否则可能会有内存访问越界问题。因此还可以进一步用模板把 buffer 和 allocator 封装绑定在一起,具体不多展开。
单帧内存分配器
为了提高栈式分配器的内存利用率,我们可以定期清理栈式分配器。其中一个例子便是单帧内存分配器:其分配的内存仅在当前帧有效,当前帧结束时自动释放其所有内存。
更具体地,单帧内存分配器会在一帧后简单地将内存池顶端指针重新指向内存块的起始地址,这样就能极为高效地每帧清理这些内存。
总结其特点如下:
- 高效的内存分配(只需移动顶端指针)及释放(只需重置顶端指针)操作。
- 无需考虑内存碎片问题。
- 适用场景:只在当前帧内有效的临时对象。
//单帧内存分配
class SingleFrameAllocator{
public:
//从栈式分配器中分配一个新的内存块
void* allocate(uint32_t size_bytes);
//不做任何操作
void deallocate(void*);
//游戏循环每帧需调用该函数用于清空堆栈内存池
void clear();
// ...
private:
StackAllocator mStack; //1个栈式分配器
};
双缓冲内存分配器
当然在一些引擎管线中,我们可能需要持续两帧的生命周期,这时候就可以使用双缓冲内存分配器:与单帧内存分配器相似,只是分配的内存可在当前帧及下一帧(共两帧)有效,当前帧结束时释放上一帧缓冲的所有内存。适用于生命周期持续一帧或两帧的对象。
//双缓冲内存分配
class DoubleBufferedAllocator{
public:
//从当前帧栈式分配器分配一个新的内存块
void* allocate(uint32_t size_bytes);
//不做任何操作
void deallocate();
//游戏循环每帧需调用该函数用于清空另一个栈式分配器,并且随后切换mCurStack
void clear();
// ...
private:
uint32_t mCurStack; //表示当前帧栈式分配器的索引。mCurStack值应总是为0或1,通过逻辑取反来切换
StackAllocator mStack[2]; //2个栈式分配器
};
可回收内存分配器
空闲链表法
栈式分配器分配出去的内存块往往做不到单独释放,往往需要清空整个内存池才能达成释放的效果。要实现内存块粒度的分配/释放,就需要引入空闲链表法。其原理就在于:
- deallocate 行为:将需要释放的内存块添加到空闲链表(free list)上。
- allocate 行为:先从空闲链表队首取得空闲内存块;若无空闲内存块,则上移顶端指针,并从顶端指针处分配出一个新的对象内存块。
当然在具体实现中,我们并不是真的要使用一个容器(这会让 allocator 占据更多额外的内存),而是在需要释放的内存块上覆写一些 header 信息,并和 allocator 的链表头结点 link 起来。
struct FreeListNode
{
FreeListNode* next; //指向下一个空闲内存块的首地址
uint32_t size; //表示当前空闲内存块的尺寸
};
class FreeListAllocator
{
//...
private:
//...
FreeListNode* freeList; //空闲链表头结点
}
在 x64 下,header 信息会占据 8+8=16字节的空间,这就相当于要求分配出去的内存块至少得 16 字节大小及以上,否则可能存在越界问题。对于后文即将要讲到的对象池或 size-class allocator ,它们都能保证每个内存块都是等大小,因此它们的 header 信息只需要一个 next 指针(即 8 字节)。
自动整理碎片
内存块回收可能会产生内存碎片,如果我们希望避免内存碎片的产生,提高内存利用率,那么考虑实现可整理内存碎片的功能。
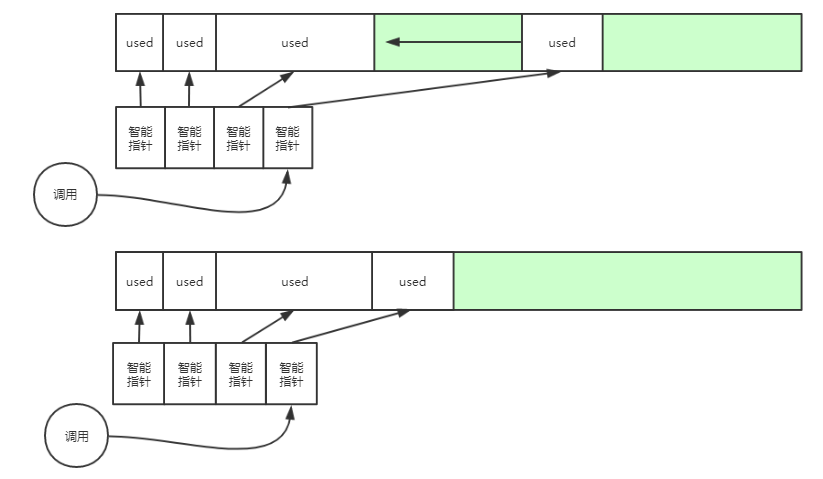
为了实现可整理碎片且保证外部指针不会因此而产生空悬,一般会引入额外一层重定向指针,外部指针指向重定向指针,而重定向指针指向实际的对象内存地址。这样,分配内存时应该返还重定向指针的地址;在自动整理需要移动对象内存的时候,会让对应的重定向指针里重新指向新复制好的内存地址。
碎片整理还有个比较苦恼开销较大的操作:复制移动内存块。所以为了避免一次性大开销(容易造成卡顿),我们无需一次性将所有碎片全部整理,可以将该成本平均分摊至N帧完成。
例如可以设定一帧最多可以进行K次内存块移动(通常是个小数目),这样可以预计大概若干帧便可以把所有碎片全部整理完,而且也不会对游戏造成卡顿的影响(毕竟开销平摊给每帧)。
总结其特点如下:
- 碎片整理是需要付出一定性能代价的:不仅是体现在碎片整理时所需要移动内存块的开销上,更体现在访问对象会导致两次指针跳转的开销(外部指针->重定向指针->实际对象内存)。
- 适用场景:各类生命周期长的小型对象。
顽皮狗的引擎中,重定向整理碎片的内存池只应用于游戏对象上,而游戏对象一般很小,从不会超过数千字节。
自动垃圾回收 [TODO]
核心是 lazy 思想:单次标记,批量回收。可以在耗时较小的短帧末尾进行垃圾回收操作。
传统的即时分配/释放往往是多个相互孤立的操作,很难考虑全局的情况。如果设计成分配/释放接口是 commit(提交操作),而分配器会在某个时间点再批量处理这些 commit 就可以享受到批量操作的高效化。
对象池(Object Pool)
对象池,是一个存放相同类型对象结构的内存池,多个类型就需要多个对象池。例如粒子对象池存放同种粒子对象,怪物对象池存放同种怪物对象...

对于遍历同种对象列表,对象池更加容易命中 CPU cache。另外在游戏引擎里,每帧都要进行同种组件遍历更新,所以说组件比较适合用对象池存储(其实就是 ECS 模式)。类似的在游戏逻辑里,还有大量同种类怪物都很适合用对象池来存储。
template<class T>
class ObjectPool{
public:
//先从freeList队首取得空闲内存块;
//若无空闲内存块,则上移顶端指针,并从顶端指针处分配出一个新的对象内存块。
T* allocate();
//将释放的内存块添加到freeList
void deallocate(T* ptr);
// ...
private:
uint32_t top; //顶端指针索引
FreeListNode* freeList; //空闲链表,其包含了各个已释放的块
uint32_t size; //内存池尺寸
T* pool; //内存池
};
总结其特点如下:
- 无需考虑内存碎片问题:因为每次分配/释放的内存都是相同大小的。
- cache 更友好:同类型对象的相关程度很高(尤其是遍历同种对象列表操作),从而让 cache 命中率更高。
- 适用场景:需要分配大量同一类型的对象。但如果类型太多可能会导致过多的对象池,从而会引入更复杂的系统设计和更多的内存提前占用。
对象池释放的方式可以选择:
- 空闲链表法:见上节空闲链表法。
- lazy delete:见上节自动垃圾回收。
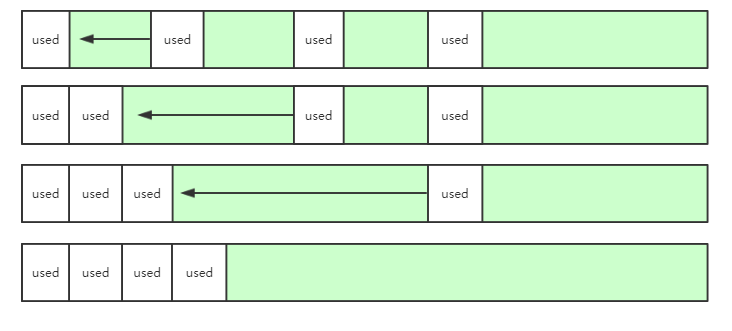
- 移动尾部对象到释放内存区域:每次释放把队尾的对象移动到被释放的区域,然后让顶端指针前移一个位置。这种方式可以让有效对象在内存布局上更加紧凑,无缝连续,从而对 cache 非常友好。其局限性也是有的:
- 如果存放的对象很大或者存在过于频繁的释放操作,那移动所带来的额外开销就可能不能忽视。
- 可能会导致对象地址变动,因此不可以保留指向其中某个对象的指针或引用。
- 会破坏对象的排列顺序,当然如果对象顺序不重要就可以无视这点局限。
此外,游戏里往往同时拥有多个对象池,但对象池分配后返还的指针有可能退化成基类指针甚至是void指针,在利用退化后的指针进行释放时,就丢掉了编译期类型信息不知道把内存归还给哪个对象池。
- 我们可以强制规定对象池的内存释放得用对象原类型的指针,不允许接受退化后的指针。
- 如果需要支持类型不明确指针(如退化成了无类型指针
void*)的内存释放操作,则需要通过一定算法算出指针指向的地址归属于哪个对象池。
Size-class Allocator(等尺寸类型分配器)
对象池的一个问题是,可能使用了过多的类型,导致产生过多的对象池数量。假如我们将等尺寸的各个类型视为同一类型,既能保持池的块仍然等大小,也可以显著减少池的数量,这就是 size-class allocator 的思想。
size-class allocator 往往包含若干个内存池,每个内存池分别对应存储 8,16,32,64,128,256...字节的元素,这样就足以应付大量类型各异但内存占用不大的对象。size-class allocator 容许实际对象小于内存池元素的大小(字节数不对齐的会被 padding),所以会浪费一些内存;然而相对于解决内存碎片问题,这种浪费绝对是值得的。
至于内存占用过大的对象最好还是使用别的分配器,否则可能会造成内存利用率过低。
总结其特点如下:
- 无需考虑内存碎片问题:虽然存在块内碎片,但是对于相同分配器,每次分配/释放的内存块都是相同大小的,不会产生块间碎片。
- 适用场景广:只要对象不是特别巨大,无论任何类型都可以使用该分配器,应用面极广。
此外, size-class allocator 的内存释放方式与对象池类似;但注意, size-class allocator 分配的对象往往是类型各异的,因此最好支持类型不明确指针以保证泛用性。
Grouping
size-class allocator 的 cache 可能相对没那么友好,因为许多类型不同的对象虽然内存大小一样,但是它们的相关性比较低,对 cache 命中率有一定影响。
我们可以先划分好若干个相关组(例如划分为动画组、渲染组、物理组),每个组有自己的一系列 size-class allocator 。在分配内存时,可以通过手动指定多额外一个参数来决定内存从哪个组里分配,从而让 size-class allocator 获得更多的相关性(因为逻辑上是同一组)。
一种无需依赖额外参数的分配方式是:HALO,它是一个收集运行时内存分配信息并分析相关性的算法,并划分好若干相关组,并利用 BOLT(链接后优化技术)来进行重写二进制,将新分配的内存分到合适的组。这种方法会有存在一定的过拟合现象,导致新分配的内存分组不准确。因此程序员手动指定分组相当于将其相关性信息显式指定出来,比起靠拟合算法去猜,会更准确且高效。
更小字节的分配
size-class allocator 能使用空闲链表法的关键在于其元素至少为 8 字节或以上,否则就不能被解释成链表结点。如果我们还想要分配 1~8 字节的更小块内存,可以考虑使用 bitmap 来管理内存块使用情况(每个 bit 可用来表示某个字节的是否空闲情况)。
部分常见内存分配实现
mimalloc 内存分配
mimalloc 是 windows 平台下性能最好的通用性 malloc 版本之一(毕竟是微软自家的东西),但是其在别的平台性能表现也相当不错。更详细的剖析可以自己去看论文和源码,本文只做简单介绍。
mimalloc 主体上采用了 size-class allocator 的设计:
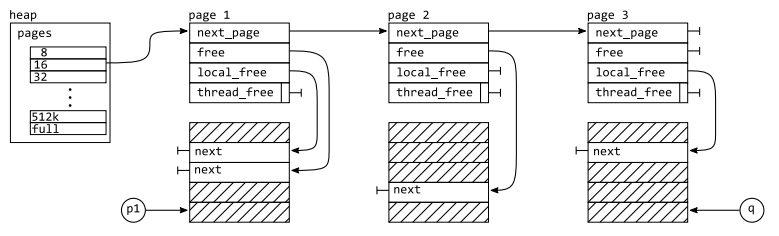
- 每个线程都拥有自己的 thread local heap(对内存堆的抽象),一个
heap相当于一个 size-class allocator ,包含若干个桶(从8B,16B 到 512KB 不等),每个桶包含了其对应的 pages 列表(数据结构为侵入式链表)。 page相当于一个句柄,其 handle 的可分配内存称为page area(一般为 64 KB),并且 page 也存放了一定的状态信息来表示 page area 的状态。我们所需要请求分配/释放的 block 就是从 page area 中切出的一块 block。
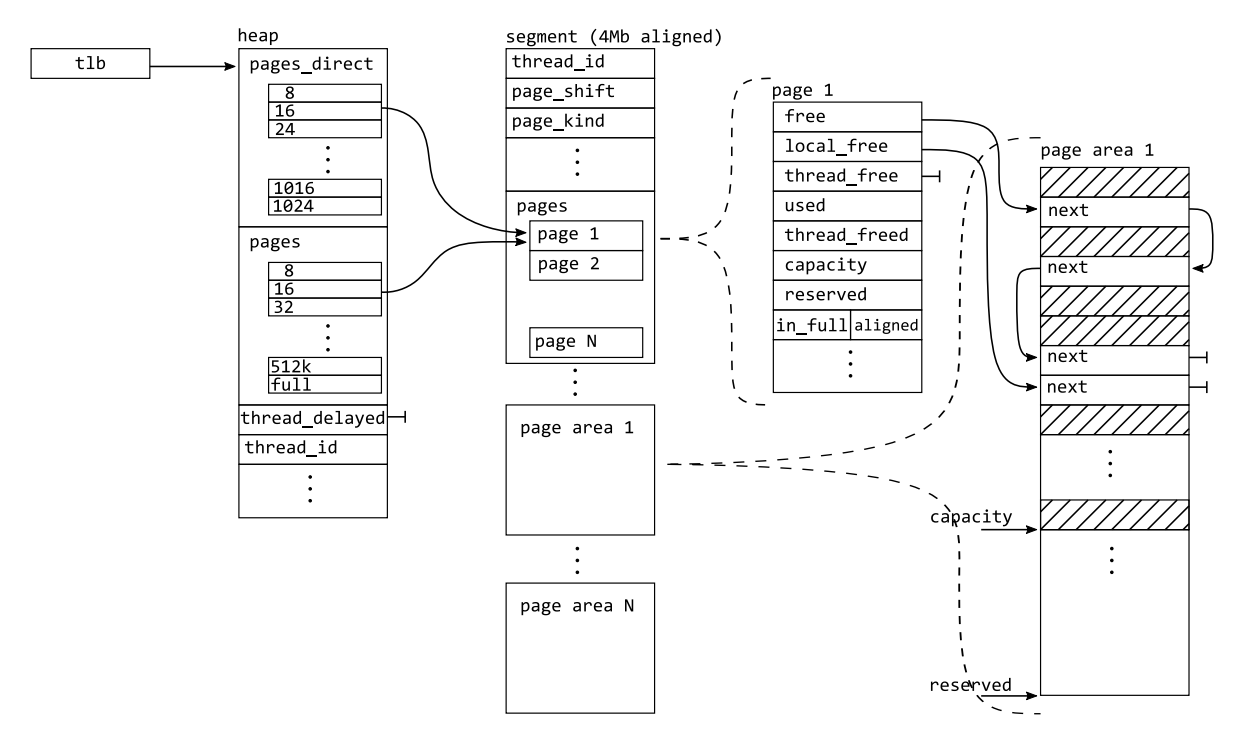
4MB对齐的 segment
free 的参数是一个无类型指针,这就意味着我们往往不知道将要释放的这块 block(当然如果 free 函数额外提供内存尺寸的参数是更好的了)到底多大,这也导致无法确定 block 归属于哪一个具体的小块分配内存池。
如果采用给 block 塞 header 信息的基础做法,小块内存的额外开销就太大了;如果通过哈希表映射找到归属于哪个池子,这种额外的数据结构开销也是有点过了。
mimalloc 通过操作系统分配出地址对齐 4MB 且内存占用大小也为 4MB 的 segment(概念对应于 memory arena),然后从 segment 身上切出一个个 page 及对应的 page area 以供 heap 使用;当一个 segment 的 pages 被用完时,可以再次申请新的 segment,因此可以说 mimalloc 的调用操作系统分配的粒度是 segment。
当然,segment 的大小根据需要(例如需要分配超大型对象)调整成比 4MB 更大的。
这样,当给定一个无类型地址,将其进行位运算就可以直接哈希到所属的 segment,无额外空间开销且常数超低的O(1)映射。
static inline mi_segment_t* _mi_ptr_segment(const void* p) {
return segment_t* segment = (segment_t*)((uintptr_t)p & ~(4*MB));
}
这时候 mimalloc 的整体框架如下:
Local Free List
mimalloc 还利用 local free list 的操作,重点优化了在多线程环境下的内存分配/释放操作。
前面我们知道,每个线程都管理着自己的 heap(thread local heap),而 heap 又管理着若干个 pages。而 mimalloc 让 page 都拥有自己的 thread_id 属性,即标记 page 是属于某个线程的;当然,不需要每个 page 都存储自己的 thread id,而是通过位运算找到其所在的 segment 再从而找到 thread_id,也就是说同一个 segment 中的 pages 都是属于同一线程的。
再具体剖析 page 的内容,会发现它有三个链表来指向可分配的 blocks,分别为 free,local_free,thread_free。
free为用来分配的 blocks 列表。local_free为本线程释放的 blocks 列表。thread_free为其它线程过来释放的 blocks 列表。
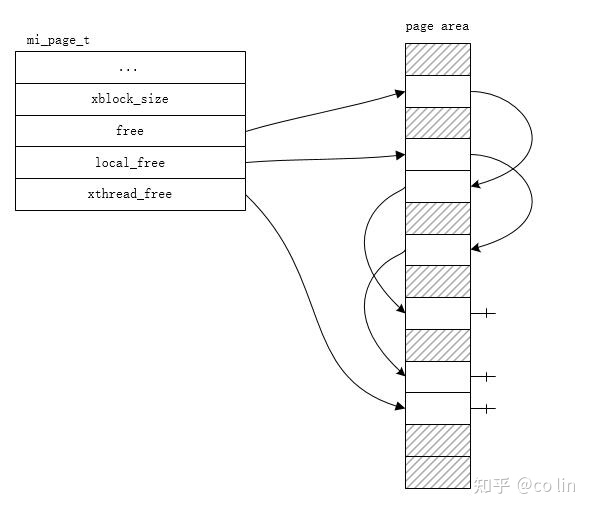
某个线程下,当需要尝试从 heap 中的某个 page 进行分配 block 时:
- [local] 如果 page 的
free列表足够分配,那么就直接出队一个结点来完成分配。 - [local] 如果 page 的
free列表不足分配,可以和local_freeswap 一下来获取它们的 blocks。 - [non-local] 如果还是不足, 可以和
thread_freeswap(原子操作) 一下来获取它们的 blocks。
某个线程下,当需要尝试释放 block 时:
- [local] 如果要释放的 block 是属于当前线程的,直接添加到
local_free队首。 - [non-local] 如果要释放的 block 是属于其它线程的,需要添加(原子操作)到
thread_free队首。
[local] 为本线程环境下的操作,无需任何线程同步开销。[non-local] 则为多线程环境下操作,一般需要原子操作来实现同步。
可以看到,通过 local free list 可以减少大部分本线程环境下的同步操作。
Fast Path(仿 TLB 机制)
mimalloc 还模仿操作系统 TLB 机制,在 heap 上弄了若干个快桶(称为 pages_direct),每个快速桶仅容纳一个 page。
于是在进行内存分配 block 时:
- [Fast Path] 优先去找对应 pages_direct(快桶) 的 page,如果该 page 的
free列表足够分配,那么就直接出队一个结点来完成分配。 - [Slow Path] 如果不足够分配,则遍历 pages(慢桶)的 pages,每个 page 会尝试分配;如果 page 满足分配会被挂到快桶上以供下次分配使用;如果 page 不满足分配,则继续遍历下一个 page。具体如何尝试分配,就是和上节讲的行为一样:
- [local] 如果
free列表足够分配,那么就直接出队一个结点来完成分配。 - [local] 如果
free列表不足分配,可以和local_freeswap 一下来获取它们的 blocks。 - [non-local] 如果还是不足, 可以和
thread_freeswap(原子操作) 一下来获取它们的 blocks。
- [local] 如果
可以看到 Fast Path 是非常快速的,并且无任何线程同步操作;当走 Fast Path 失败时,会走 Slow Path,遍历 pages 会导致一定的开销,甚至还可能有线程同步操作(原子操作)的开销。
UE 内存分配
UE 将内存分配接口抽象出来,这样就可以将不同内存分配器的调度与实现(如C标准分配、Binned 分配)封装起来,并向上层应用提供统一的 FMemory::Malloc 和 FMemory::Free 内存分配/释放接口。
使用到该接口的上层应用包括:
- 重载 new/delete 操作符
- UE 自己的字符串类(
FString) - UE 自己的各类容器(如
TArray,TSet) UObject的内存分配

UE 内存分配有三个实现版本,分别为 Binned1,Binned2 和 Binned3,每个后面的版本基本就是在前面的版本上做迭代。
本来也想继续剖析一下 Binned 3 的,但因为它还在完善中,此外就是本文字数已经超过1W2了,想了想还是留坑吧。
Binned1 主体上采用了 size-class allocator 设计:
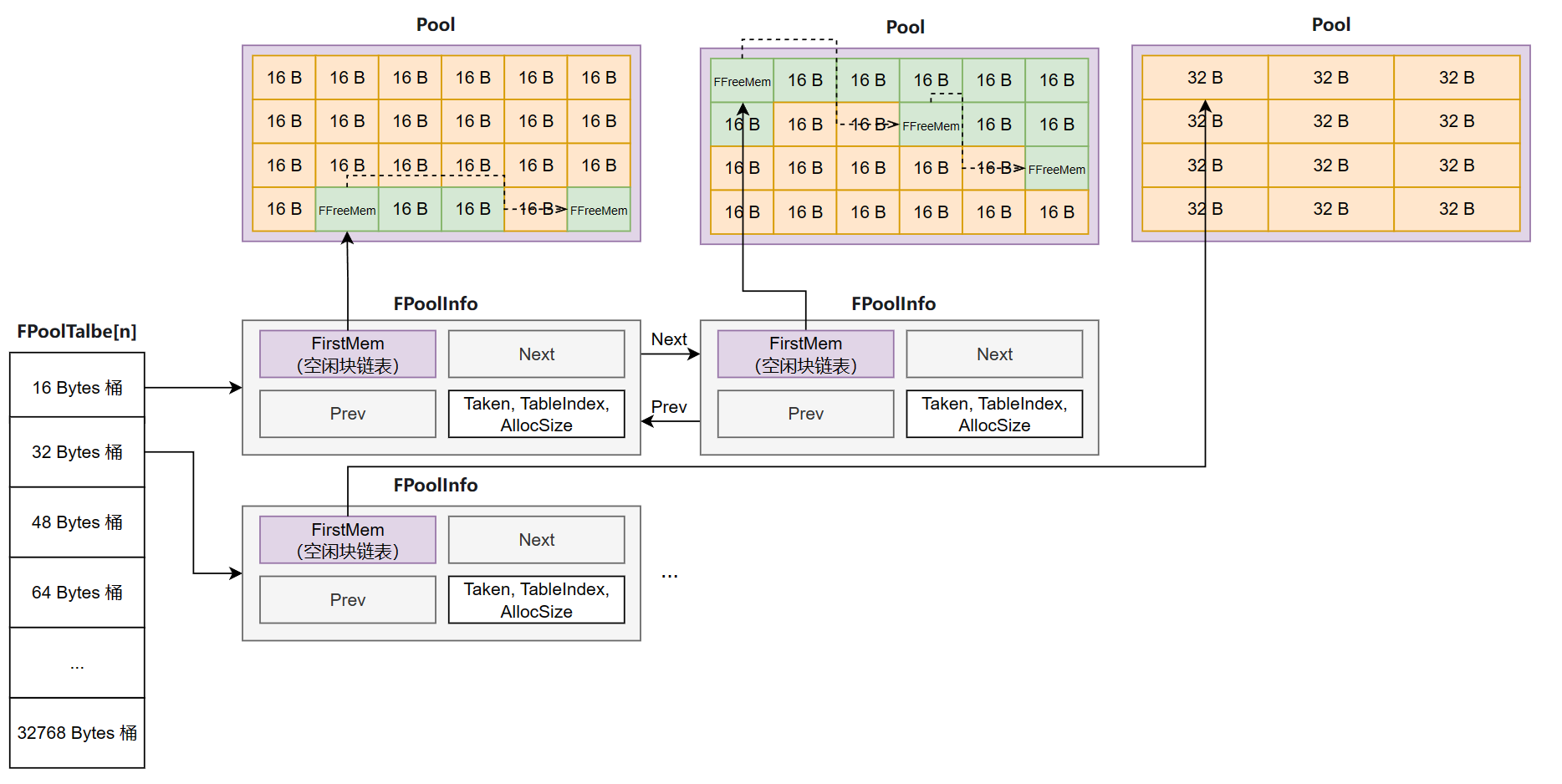
- 全局仅有一个 size-class allocator ,分为 16B,32B,...,32768B 共 41 个
FPoolTable(桶),每个桶都包含其对应的FPoolInfo列表(数据结构为侵入式链表)。 FPoolInfo相当于一个句柄,其 handle 的可分配内存称为 Pool(Pool 的大小是由PageSize决定的,PC 和安卓默认为 64 KB,IOS 为 16 KB),并且FPoolInfo也存放了一定的状态信息来表示 Pool 的状态。我们所需要请求分配/释放的 block 就是从 Pool 中切出的一块 block。
而桶实际上是持有 FPoolInfo 链表的头结点,从而在逻辑上相当于管理了若干个 Pools。
空闲链表法
Binned1 通过空闲链表法来管理空闲块。其分配的内存块在空闲时会被解释为空闲结点(表示自己当前块+后面连续的空闲内存块的数量,并指向了下一个空闲结点),这也意味着 x64 下内存块的最小单位必须得是 16 字节。
/** Information about a piece of free memory. 16 bytes */
struct alignas(16) FMallocBinned::FFreeMem
{
/** Next or MemLastPool[], always in order by pool. */
FFreeMem* Next;
/** Number of consecutive free blocks here, at least 1. */
uint32 NumFreeBlocks;
};
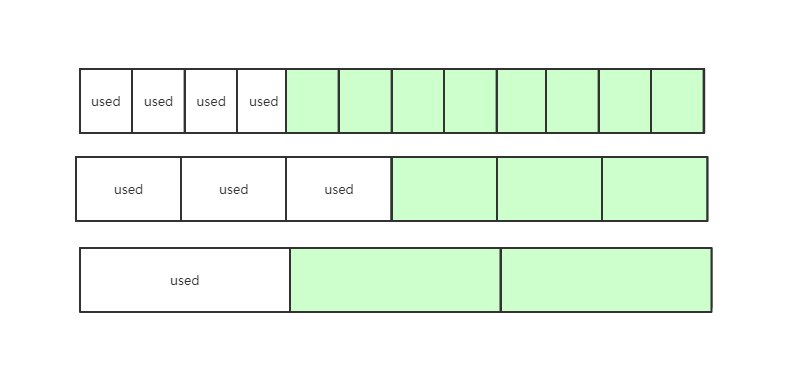
使用 NumFreeBlocks 的好处是,在构建空闲块链表时,我们不需要每个块都要建立链表结点,而只在连续多个块中的第一个块建立结点即可。减少了大量构建空闲块链表时所需要 link 的操作(如下图演示,有无 NumFreeBlocks 的区别)。
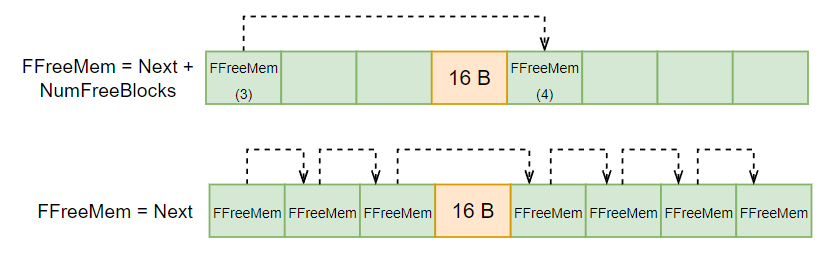
Malloc & Free
Malloc 的核心问题在于:给定一个申请大小,该如何找到合适的桶并获得其中某个 Pool 里的 block。
当需要分配内存块时,首先会根据申请大小:
- 如果申请大于 32768B,转去使用 OS 分配。
- 如果申请小于等于 32768B,则使用 binned 分配。
而 Binned1 分配会将申请大小作为 MemSizeToPoolTable[] 这个数组的索引,找到对应的 FPoolTable(桶),并进行对应的等尺寸类型分配行为。
MemSizeToPoolTable[]是一个有 32771 个元素的指针数组,其预存储出每个分配字节数(0,1,2,...,32768 字节)所对应的 FPoolTable 指针,从而实现 O(1) 复杂度根据字节数映射到自己的桶。但是这个映射用的数组占据的空间也不小,为此 Binned2 额外使用了位运算来简化映射关系的数量,最终其映射数组
MemSizeToIndex[]只需要 2048 个元素。FORCEINLINE uint32 BoundSizeToPoolIndex(SIZE_T Size) { auto Index = ((Size + BINNED2_MINIMUM_ALIGNMENT - 1) >> BINNED2_MINIMUM_ALIGNMENT_SHIFT); uint32 PoolIndex = uint32(MemSizeToIndex[Index]); return PoolIndex; }
Free 的核心问题在于:给定一个需要 Free 的地址,需要找到该地址归属于哪个 Pool,才能正确归还内存。
Binned 通过哈希表来解决该问题:给定一个地址,通过链式哈希表找到对应的 PoolHashBucket,其记录了该块 Pool 是来源于 binned 里分配的哪个 Pool 还是来源于 OS 分配的内存。
- 如果是 OS 分配的内存:直接转交给 OS 释放函数。
- 如果是 Binned 分配的 pool:以空闲链表法的方式归还 block。
虽然哈希表理论上是 O(1) 的映射速度,但是常数级别上还是有一定的开销。如果要改进,最好改成纯粹位运算的映射。
多线程 TLS
Binned1 的 Malloc 和 Free 都是很简单粗暴的直接加锁 FScopeLock。
而 Binned2 在 Binned1 的基础上额外引入了 TLS 机制,优化了多线程环境下的内存分配:
- 每个线程可以申请一个 TLS cache,其包含两个
FBundle(即元素为FBundleNode的链表)分别叫PartialBundle和FullBundle,TLS 的分配与释放操作均为无同步开销的。 - 还引入了一个全局的回收器
GGlobalRecycler,其每个 size-class 对应可以缓存最多 8 个FBundle,但这个可以类比成各线程可共享的 L2 cache,其释放与分配基本包含原子操作。
PS:Binned1 中的
FFreeMem被换成了 Binned2 中的FFreeBlock,并新增加了FBundleNode空闲结点解释方式(其实就是增加了个 union,让空闲结点可以在某些时候表示成两个指针)。
当需要释放内存时,
- [local] 优先把 block 归还给 TLS cache 的 PartialBundle;如果 PartialBundle 的 blocks 数量超过了一定阈值,就把 PartialBundle 挂到 FullBundle 上。
- [atomic] 如果 FullBundle 有东西,则把它归还给全局的 GGlobalRecycler 上。
- [lock] 如果 GGlobalRecycler 的缓存也满了,就只能走全局的内存池内存分配(binned1 方式)。
当需要申请内存时,
- [local] 优先从 TLS cache 的 PartialBundle 中获取 block。
- [atomic] 如果 PartialBundle 为空,那就去全局的 GGlobalRecycler 请求获取 block。
- [lock] 如果 GGlobalRecycler 的缓存为空,就只能走全局的内存池内存分配(binned1 方式)。
总结 [TODO]
-
尽量使用栈内存:这样就可以尽量把内存交给栈管理,而无需考虑堆内存分配的各种问题。当然内存需求太大的话就不该用栈,可能会爆。
-
慎用 STL 默认内存分配器:其使用效率一般不如自定义的好。
-
在设计内存池时,推荐根据自己具体需求,结合搭配使用各种分配策略。
-
如果让我简单直观的讲 mimalloc 和 UE Binned2 多线程策略,大概如下:
- mimalloc:每个人(线程)拥有一个自己的私人银行(thread local heap),每个人要去各自所属的私人银行借钱。一般自己还自己钱就直接去自己的私人银行还钱,VIP无需排队。但是有人可能借钱后会把钱交给另一个人去代还钱,这时候另一个人就需要去银行排队还钱了。
- Binned2:每个人(线程)拥有一个口袋(TLS),大家都往公共银行(全局分配)排队借钱。要还钱时优先放进自己口袋,如果口袋满了就把口袋里的钱归还公共银行(当然也是要排队的);如果要继续借钱,先翻翻自己口袋看还有没有钱,没钱再去公共银行再排队借钱。
参考
- 《游戏引擎架构(Game Engine Architecture)》 Jason Gregory
- microsoft/mimalloc: mimalloc is a compact general purpose allocator with excellent performance. (github.com)
- mimalloc研究报告 - 知乎 (zhihu.com)
- Mimalloc: Free List Sharding in ActionMicrosoft Technical Report MSR-TR-2019-18, June 2019.
- 4.1 为什么要有虚拟内存? | 小林coding (xiaolincoding.com)
- HALO: Post-Link Heap-Layout Optimisation (cam.ac.uk)
- UE4内存分配器概述 - 可可西 - 博客园 (cnblogs.com)
- [CppCon]2017- Bob Steagall "How to Write a Custom Allocator"
- 高性能内存分配库的研发小结 - 知乎 (zhihu.com)
游戏架构&游戏设计模式系列-其他文章:https://www.cnblogs.com/KillerAery/category/1307176.html
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。
