
【python】-- RabbitMQ 队列消息持久化、消息公平分发
RabbitMQ 队列消息持久化
假如消息队列test里面还有消息等待消费者(consumers)去接收,但是这个时候服务器端宕机了,这个时候消息是否还在?
1、队列消息非持久化
服务端(producer):
import pika
# 声明一个socket 实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道
channel = connect.channel()
# 声明queue名称为test
channel.queue_declare(queue="test")
#RabbitMQ的消息永远不会被直接发送到队列中,它总是需要经过一次交换
channel.basic_publish(exchange='',
routing_key="test",
body="hello word")
print("Sent 'hello world'")
connect.close()
客户端(consumers):
import pika
import time
# 声明socket实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道 虽然在之前的produce代码中声明过一次管道,
# 但是在不知道produce中的管道是否运行之前(如果未运行,consumers中也不声明的话就会报错),
# 在consumers中也声明一次是一种正确的做法
channel = connect.channel()
#声明queue
channel.queue_declare(queue="test")
#回调函数
def callback(ch, method, properites, body):
time.sleep(30)
print("-----", ch, method, properites, body)
print("Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动确认收到消息,添加手动确认时,no_ack必须为False,不然就会报错
channel.basic_consume(callback,
queue="test",
no_ack=False)
print("Waiting for messages")
#这个start只要一启动,就一直运行,它不止收一条,而是永远收下去,没有消息就在这边卡住
channel.start_consuming()
上面的服务端和客户端声明queue的方式都是非持久的
channel.queue_declare(queue="test")
①服务端先发送往test队列里发送两条消息

②通过运行--services.msc进入服务重新启动RabbitMQ
③再次查看消息队列queue中的消息数量

通过小实验可以看出,非持久声明的queue,在服务端宕机后,消息队列queue和消息都不复存在了
2、队列消息持久化:
①队列持久化很简单,只需要在服务端(produce)声明queue的时候添加一个参数:
channel.queue_declare(queue='shuaigaogao', durable=True) # durable=True 持久化
②仅仅持久化队列是没有意义的,还需要多消息进行持久化
channel.basic_publish(exchange="",
routing_key="shuaigaogao", #queue的名字
body="hello world", #body是要发送的内容
properties=pika.BasicProperties(delivery_mode=2,) # make message persistent=>使消息持久化的特性
)
③最后一步,在服务端队列消息都持久化了之后需要在客户端声明queue的时候也持久化
channel.queue_declare(queue='shuaigaogao', durable=True)
这样就算再传递消息过程中,服务端的发生宕机,消息和队列也不会丢失
小结:
- RabbitMQ在服务端没有声明队列和消息持久化时,队列和消息是存在内存中的,服务端宕机了,队列和消息也不会保留。
- 服务端声明持久化,客户端想接受消息的话,必须也要声明queue时,也要声明持久化,不然的话,客户端执行会报错。
RabbitMQ 消息公平分发
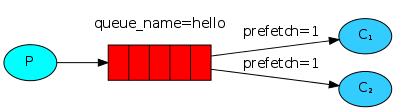
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
channel.basic_qos(prefetch_count=1)
通俗的讲就是消费者有多大本事,就干多少活,消费者处理的越慢,其消息分配分发的就少,反之消费者消息处理的多,处理的快,就可以多向这个消费者分配一些消息。服务端给客户端发消息的时候,先检查一下,这个消费者现在还有多少消息,如果处理的消息超过1条,就不给这个消费者发送消息了
队列消息持久化+公平分发示列:
服务端:
import pika
# 声明一个socket 实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道
channel = connect.channel()
# 声明queue名称为test
channel.queue_declare(queue="test", durable=True) # 队列持久化
#RabbitMQ的消息永远不会被直接发送到队列中,它总是需要经过一次交换
channel.basic_publish(exchange='',
routing_key="test",
body="hello word",
properties=pika.BasicProperties(delivery_mode=2,)) # 消息持久化
print("Sent 'hello world'")
connect.close()
客户端:
import pika
import time
# 声明socket实例
connect = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
# 声明一个管道 虽然在之前的produce代码中声明过一次管道,
# 但是在不知道produce中的管道是否运行之前(如果未运行,consumers中也不声明的话就会报错),
# 在consumers中也声明一次是一种正确的做法
channel = connect.channel()
#声明queue
channel.queue_declare(queue="test", durable=True)
#回调函数
def callback(ch, method, properites, body):
time.sleep(30)
print("-----", ch, method, properites, body)
print("Received %r" % body)
ch.basic_ack(delivery_tag=method.delivery_tag) # 手动确认收到消息,添加手动确认时,no_ack必须为False,不然就会报错
channel.basic_qos(prefetch_count=1) # 在消息消费之前加上消息处理配置
channel.basic_consume(callback,
queue="test",
no_ack=False)
print("Waiting for messages")
#这个start只要一启动,就一直运行,它不止收一条,而是永远收下去,没有消息就在这边卡住
channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号