

Python实战爬虫——街拍美图
python学了有一段时间了,觉得看书也只是划水,还是要动手码代码,感觉对爬数据挺有感觉,想爬来试试,于是开始了学习崔庆才的网络爬虫开发实战,由于信息技术的更新,崔老师的书中的源代码跑起来感觉会有一些出入,所以还是要多看时间最近的相关博客,,,,,,还是在崔老师的基础上再结合博客修改之后的。
在搜索栏搜街拍,然后右键,检查,network,注意,运用开发者页面的时候点击network,如果点Elements,看到的不是源代码。由于页面是Ajax过的,所以我们直接看XHR
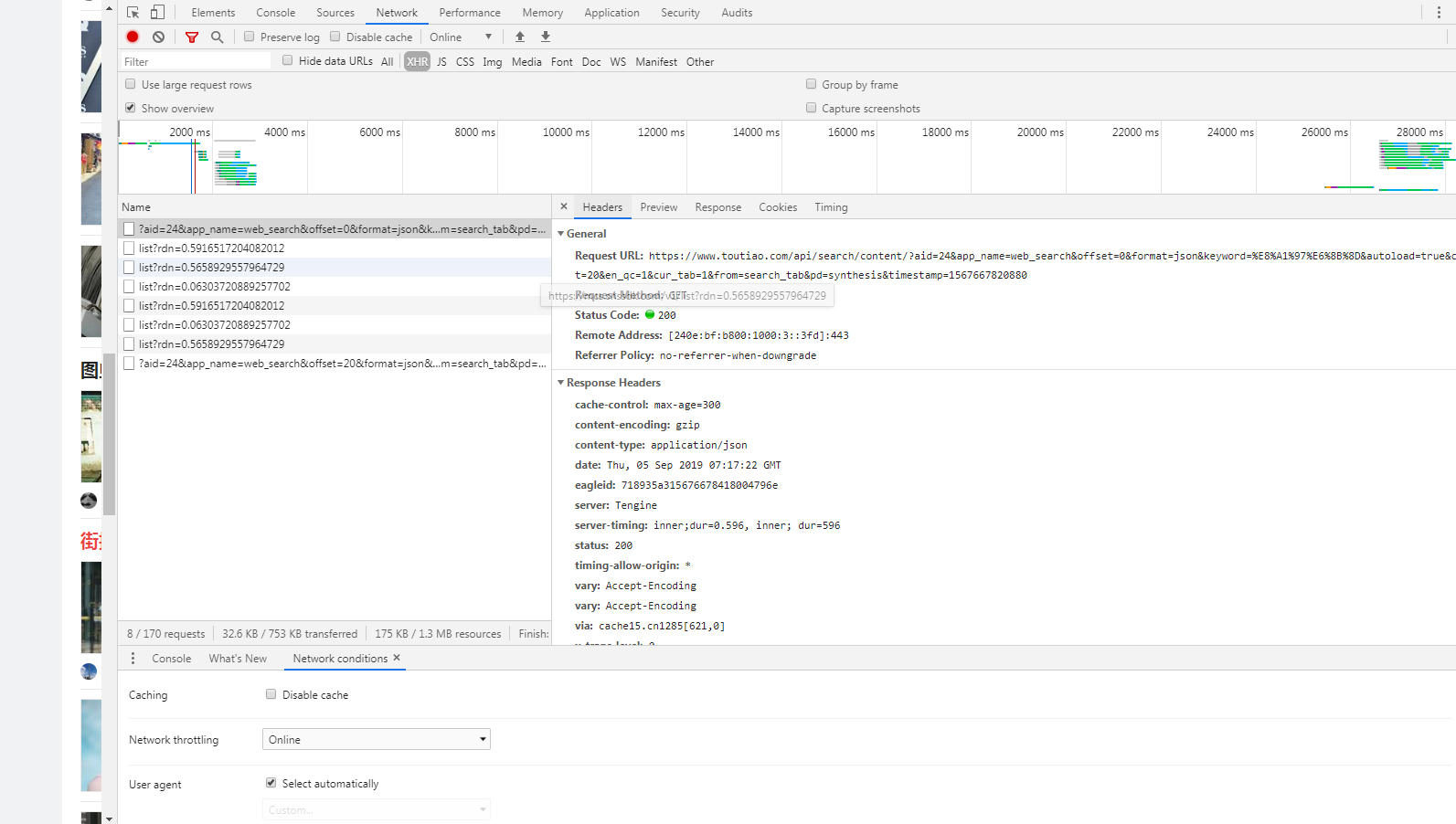
因为头条的页面是向上滚动鼠标就可以继续加载页面,就会发现每次滚动滚轮,name这一栏都会有新的刷新内容,分析name栏中每个选项的Preview和Response
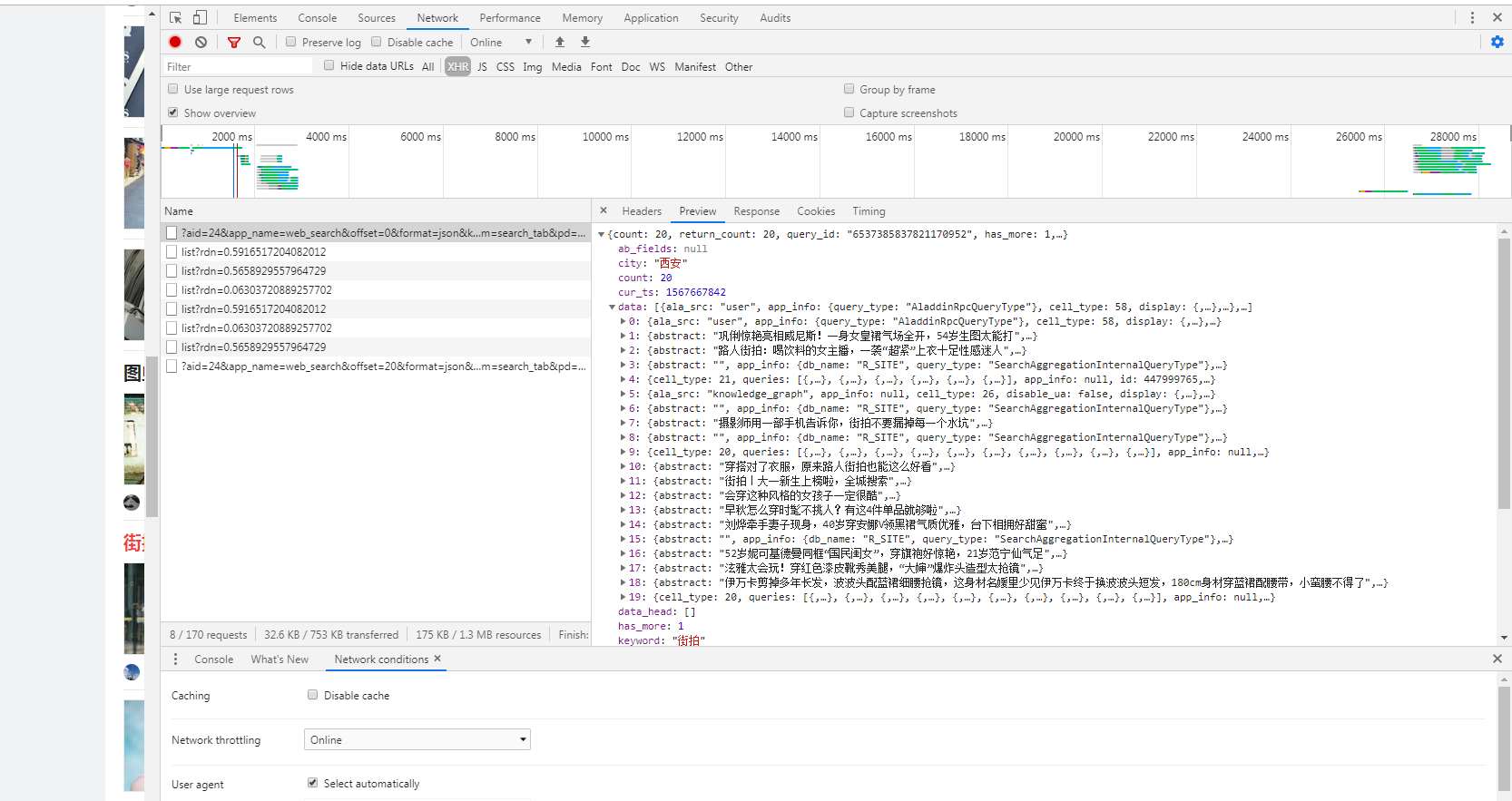
我们可以发现在第一项的Preview这一栏包含了一组data信息,里面出现了具体的图片名称和其他信息,所以,我们可以继续滚动页面,对比其他的类似选项,在经过对比后我们可以发现,每一条url的变化仅是offset这一项发生了变化,在崔老师的书中写的比较详细,具体怎么构建url,所以在这里,直接把代码复制过来
1 import requests 2 import os 3 from hashlib import md5 4 from urllib.parse import urlencode 5 from multiprocessing.pool import Pool 6 def get_data(offset): 7 #构造URL,发送请求 8 params = { 9 'aid': '24', 10 'app_name': 'web_search', 11 'offset': offset, 12 'format': 'json', 13 'autoload': 'true', 14 'count': '20', 15 'en_qc': '1', 16 'cur_tab': '1', 17 'from': 'search_tab', 18 } 19 base_url = 'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D' 20 url = base_url + urlencode(params)
然后判断requests请求后的结果,并将其改成成JSON格式
1 try: 2 res = requests.get(url) 3 if res.status_code == 200: 4 return res.json() 5 except requests.ConnectionError: 6 return 'sorry.'
接下来就是对请求的结果进行信息提取,获取图片的名称,以及图片的下载地址
1 def get_img(data): 2 if data.get('data'): 3 page_data = data.get('data') 4 for item in page_data: 5 title = item.get('title') 6 imgs = item.get('image_list') 7 for img in imgs: #yield是一个生成器,具体的解释可以去博客:https://blog.csdn.net/qq_33472765/article/details/80839417 8 yield { 9 'title': title, 10 'img': img.get('url') 11 }
现在我们需要的就是将图片保存,建立文件夹,然后用title给文件夹命名
1 def save(item): 2 img_path = 'img' + '/' + item.get('title') 3 if not os.path.exists(img_path): 4 os.makedirs(img_path) 5 try: 6 res = requests.get(item.get('img')) 7 if res.status_code == 200: 8 file_path = img_path + '/' + '{name}.{suffix}'.format( 9 name=md5(res.content).hexdigest(), 10 suffix='jpg') 11 if not os.path.exists(file_path): 12 with open(file_path, 'wb') as f: 13 f.write(res.content) 14 print('Successful') 15 else: 16 print('Already Download') 17 except requests.ConnectionError: 18 print('Failed to save images')
接下来就是构造一个offset数组,然后进行遍历
1 def main(offset): 2 data = get_data(offset) 3 for item in get_img(data): 4 print(item) 5 save(item) 6 START = 0 7 END = 10 8 if __name__ == "__main__": 9 pool = Pool() 10 offsets = ([n * 20 for n in range(START, END + 1)]) 11 pool.map(main,offsets) 12 pool.close() 13 pool.join()
多进程模块Pool的用法可以看看博客https://www.cnblogs.com/zrmw/p/10272034.html
最后所有的代码:
1 import requests 2 import os 3 from hashlib import md5 4 from urllib.parse import urlencode 5 from multiprocessing.pool import Pool 6 def get_data(offset): 7 #构造URL,发送请求 8 params = { 9 'aid': '24', 10 'app_name': 'web_search', 11 'offset': offset, 12 'format': 'json', 13 'autoload': 'true', 14 'count': '20', 15 'en_qc': '1', 16 'cur_tab': '1', 17 'from': 'search_tab', 18 } 19 base_url = 'https://www.toutiao.com/api/search/content/?keyword=%E8%A1%97%E6%8B%8D' 20 url = base_url + urlencode(params) 21 try: 22 res = requests.get(url) 23 if res.status_code == 200: 24 return res.json() 25 except requests.ConnectionError: 26 return 'sorry.' 27 def get_img(data): 28 if data.get('data'): 29 page_data = data.get('data') 30 for item in page_data: 31 title = item.get('title') 32 imgs = item.get('image_list') 33 for img in imgs: 34 yield { 35 'title': title, 36 'img': img.get('url') 37 } 38 def save(item): 39 img_path = 'img' + '/' + item.get('title') 40 if not os.path.exists(img_path): 41 os.makedirs(img_path) 42 try: 43 res = requests.get(item.get('img')) 44 if res.status_code == 200: 45 file_path = img_path + '/' + '{name}.{suffix}'.format( 46 name=md5(res.content).hexdigest(), 47 suffix='jpg') 48 if not os.path.exists(file_path): 49 with open(file_path, 'wb') as f: 50 f.write(res.content) 51 print('Successful') 52 else: 53 print('Already Download') 54 except requests.ConnectionError: 55 print('Failed to save images') 56 def main(offset): 57 data = get_data(offset) 58 for item in get_img(data): 59 print(item) 60 save(item) 61 START = 0 62 END = 10 63 if __name__ == "__main__": 64 pool = Pool() 65 offsets = ([n * 20 for n in range(START, END + 1)]) 66 pool.map(main,offsets) 67 pool.close() 68 pool.join()
代码主要参考崔老师书中的代码和其他的博客,大家如果感兴趣,还是要多看看近一年的博客,因为现在网络的变化太快了,如有问题,欢迎大家一起探讨
