
python正则表达式-re模块
目录:
一、正则函数
二、re模块调用
三、贪婪模式
四、分组
五、正则表达式修饰符
六、正则表达式模式
七、常见的正则表达式
导读:
想要使用python的正则表达式功能就需要调用re模块,re模块为高级字符串处理提供了正则表达式工具。模块中提供了不少有用的函数,比如:compile函数、match函数、search函数、findall函数、finditer函数、split函数、sub函数、subn函数等。接下来本文将会介绍这些函数的使用情况,然后通过分析编译流程对比两种re模块的调用方式,之后会介绍其他一些应用正则表达式需要知道的理论知识,最后通过一些经典的实例将之前学习的理论应用于实际。让我们开始正则表达式的学习之旅吧~~~
一、正则函数
1. re.match函数
功能:re.match尝试从字符串的起始位置匹配一个模式,如果匹配成功则返回一个匹配的对象,如果不是起始位置匹配成功的话,match()就返回none。
语法:re.match(pattern,string,flags=0)
例子:
1 s = "12abc345ab" 2 m = re.match(r"\d+", s) ### \d表示匹配数字,相当于[0-9],+表示匹配一个或多个字符 3 print(m.group()) # answer:12 ### match只能匹配一次,group()返回匹配的完整字符串 4 print(m.span()) # answer:(0, 2) ### span()返回包含起始、结束位置的元组 5 6 m = re.match(r"\d{3,}", s) ### {3,}规定了匹配最少3个字符,match从起始位置匹配,匹配不到3个字符返回none 7 print(m) # answer:None
注:例子中涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
2. re.search函数
功能:re.search 扫描整个字符串并返回第一个成功的匹配,如果匹配成功re.search方法返回一个匹配的对象,否则返回None。
语法:re.search(pattern, string, flags=0)
例子:
1 s = "12abc345ab" 2 m = re.search(r"\d{3,}", s) ### search与match相比的优势,匹配整个字符串,而match只从起始位置匹配 3 print(m.group()) # answer:345 4 print(m.span()) # answer:(5, 8) 5 6 m = re.search(r"\d+", s) ### search和match一样,只匹配一次 7 print(m.group()) # answer:12 8 print(m.span()) # answer:(0, 2)
注:例子中涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
3. re.sub函数
功能:re.sub用于替换字符串中的匹配项。
语法:re.sub(pattern, repl, string, count=0, flags=0)
repl参数可以为替换的字符串,也可以为一个函数。
- 如果repl是字符串,那么就会去替换字符串匹配的子串,返回替换后的字符串;
- 如果repl是函数,定义的函数只能有一个参数(匹配的对象),并返回替换后的字符串。
例子:
1 phone = "2004-959-559 # 这是一个国外电话号码" 2 ### 删除字符串中的 Python注释 3 num = re.sub(r'#.*$', "", phone) ### '.*'表示匹配除了换行符以外的0个或多个字符,’#...'表示匹配注释部分,'$'表示匹配到字符末尾 4 print("电话号码是:", num) # answer:电话号码是: 2004-959-559 5 ### 删除非数字(-)的字符串 6 num = re.sub(r'\D', "", phone) ### '\D'表示匹配非数字字符,相当于[^0-9] 7 print("电话号码是:", num) # answer:电话号码是: 2004959559
count可指定替换次数,不指定时全部替换。例如:
1 s = 'abc,123,ef' 2 s1 = re.sub(r'[a-z]+', '*', s) 3 print(s1) # answer: *,123,* 4 s2 = re.sub(r'[a-z]+', '*', s, count=1) 5 print(s2) # answer: *,123,ef
repl可以为一个函数。例如:
1 # 调用函数对每一个字符进行替换,得到了不同的替换结果 2 def more(matched): 3 print(matched.group()) 4 return "*" * len(matched.group()) 5 s = 'abc,123,ef' 6 s = re.sub(r"[a-z]+", more, s) 7 print(s) 8 # answer1: abc answer2: ef answer3: ***,123,**
注:例子中涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
4. re.subn函数
功能:和sub函数差不多,但是返回结果不同,返回一个元组“(新字符串,替换次数)”
例子:
1 s = 'abc,123,ef' 2 s1 = re.subn(r'[a-z]+', '*', s) 3 print(s1) # answer: ('*,123,*', 2) 4 s2 = re.subn(r'[a-z]+', '*', s, count=1) 5 print(s2) # answer: ('*,123,ef', 1)
注:例子中涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
5. re.compile函数
功能:compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。如果匹配成功则返回一个Match对象。
语法:re.compile(pattern[, flags])
注:compilte函数调用情况比较复杂,下面会有一节专门讲解。
6. findall函数
功能:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
语法:findall(string[, pos[, endpos]])
例子:
1 s = "12abc345ab" 2 ms = re.findall(r"\d+", s) ### findall匹配所有字符,而match和search只能匹配一次 3 print(ms) # answer:['12', '345'] 4 5 ms = re.findall(r"\d{5}", s) ### {5}表示匹配5个字符,没有匹配到,返回空列表 6 print(ms) # answer:[]
注:例子中涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
7. re.finditer函数
功能:在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
语法:re.finditer(pattern, string, flags=0)
例子:
1 s = "12abc345ab" 2 for m in re.finditer(r"\d+", s): ### finditer返回的是迭代器 3 print(m.group()) # answer1:12 ,answer2:345 4 print(m.span()) # answer1:(0, 2) ,answer2:(5, 8)
注:例子中涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
8. re.split函数
功能:split 方法用pattern做分隔符切分字符串,分割后返回列表。如果用'(pattern)',那么分隔符也会返回。
语法:re.split(pattern, string[, maxsplit=0, flags=0])
例子:
1 m = re.split('\W+', 'dog,dog,dog.') ### '\W'表示匹配非字母数字及下划线,在这里匹配的就是','和'.',然后按这些字符分割 2 print(m) # answer:['dog', 'dog', 'dog', ''] 3 m = re.split('(\W+)', 'dog,dog,dog.') ### 使用'(pattern)',连带分隔符一起返回 4 print(m) # answer:['dog', ',', 'dog', ',', 'dog', '.', ''] 5 m = re.split('\W+', 'dog,dog,dog.', maxsplit=1) ### 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。 6 print(m) # answer:['dog', 'dog,dog.']
注:例子中涉及部分还未讲解的知识,若例子未看懂,可以将下面内容都看完后再回过头来看。
小结:
1. 函数辨析:match和search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search匹配整个字符串,直到找到一个匹配。
2. 函数辨析:3个匹配函数match、search、findall
match 和 search 只匹配一次 ,匹配不到返回None,findall 查找所有匹配结果。
3. 函数返回值
函数re.finditer 、 re.match和re.search 返回匹配对象,而findall、split返回列表。
4. re.compile函数是个谜。
二、re模块调用
re模块的使用一般有两种方式:
方法1:
直接使用上面介绍的 re.match, re.search 和 re.findall 等函数对文本进行匹配查找。
方法2:
(1)使用compile 函数将正则表达式的字符串形式编译为一个 Pattern 对象;
(2)通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果(一个 Match 对象);
(3)最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作。
接下来重点介绍一下compile函数。
re.compile函数用于编译正则表达式,生成一个Pattern对象,调用形式如下:
re.compile(pattern[, flag])
其中,pattern是一个字符串形式的正则表达式,flag是一个可选参数(下一节具体讲解)。
例子:
1 import re 2 # 将正则表达式编译成Pattern对象 3 pattern = re.compile(r'\d+')
利用Pattern对象可以调用前面提到的一系列函数进行文本匹配查找了,但是这些函数的调用与之前有一些小差别。
1. match函数
使用语法:
(1)re.match(pattern, string[, flags])
这个之前讲解过了。
(2)Pattern对象:match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
例子:
1 pattern = re.compile(r"\d+") 2 m = pattern.match('one12twothree34four') ### 这种情况下和re.match一样了 3 print(m) # answer: None 4 m = pattern.match('one12twothree34four', 3, 15) 5 print(m) # 返回一个Match对象 answer: <_sre.SRE_Match object; span=(3, 5), match='12'> 6 print(m.group()) # 等价于 print(m.group(0)) answer: 12 7 print(m.start(0)) # answer: 3 8 print(m.end(0)) # answer: 5 9 print(m.span(0)) # answer: (3, 5) 10 ### 对比 11 s = 'one12twothree34four' 12 s = re.match(r"\d+", s) 13 print(s) # answer: None
当匹配成功时会返回一个Match对象,其中:
- group([0, 1, 2,...]): 可返回一个或多个分组匹配的字符串,若要返回匹配的全部字符串,可以使用group()或group(0)。
- start(): 匹配的开始位置。
- end(): 匹配的结束位置。
- span(): 包含起始、结束位置的元组。等价于(start(), end())。
- groups(): 返回分组信息。等价于(m.group(1), m.group(2))。
- groupdict(): 返回命名分组信息。
例子:
1 pattern = re.compile(r"([a-z]+) ([a-z]+)", re.I) ### re.I 表示忽略大小写, ()表示一个分组,所以这里有2个分组。([a-z]+)表示匹配1个或多个字母 2 m = pattern.match('hello nice world') 3 print(m.groups()) # answer: ('hello', 'nice') 4 print(m.group(0)) # 等价于 m.group() answer: 'hello nice'。返回匹配的全部字符串。 5 print(m.span(0)) # answer: (0, 10)。返回匹配的全部字符串的起始位置。等价于(m.start(0), m.end(0)) 6 print(m.start(0)) # answer: 0 7 print(m.end(0)) # answer: 10 8 print(m.group(1)) # answer: hello。返回第一个分组匹配字符串。 9 print(m.span(1)) # answer: (0, 5)。返回第一个分组匹配字符串的起始位置。 10 print(m.start(1)) # answer: 0 11 print(m.end(1)) # answer: 5 12 print(m.group(2)) # answer: nice。返回第二个分组匹配字符串。 13 print(m.span(2)) # answer: (6, 10)。返回第二个分组匹配字符串的起始位置。 14 print(m.start(2)) # answer: 6 15 print(m.end(2)) # answer: 10
2. search函数
使用语法:
(1)re.search(pattern, string, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:search(string[, pos[, endpos]])
例子:
1 pattern = re.compile('\d+') 2 m = pattern.search('one12twothree34four') 3 print(m.group()) # answer: 12 4 print(m.span()) # answer: (3, 5) 5 # print(m.group(1)) # answer: 报错,不存在 6 print(m.groups()) # 等价于(m.group(1),...) answer: () 7 m = pattern.search('one12twothree34four', 10, 30) 8 print(m.groups()) # answer: () 9 print(m.group()) # answer: 34 10 print(m.span()) # answer: (13, 15)
3. findall函数
使用语法:
(1)findall(string[, pos[, endpos]])
这个函数前面已经讲解过了。
(2)Pattern对象:findall(string[, pos[, endpos]])
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
例子:
1 pattern = re.compile(r'\d+') 2 s1 = pattern.findall('hello world 123 456 789') 3 s2 = pattern.findall('one12twothree34four56', 0, 15) 4 print(s1) # answer: ['123', '456', '789'] 5 print(s2) # answer: ['12', '34']
4. finditer函数
使用语法:
(1)re.finditer(pattern, string, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:finditer(string[, pos[, endpos]])
finditer 函数与 findall 类似,但是它返回每一个匹配结果(Match 对象)的迭代器。
例子:
1 pattern = re.compile(r'\d+') 2 s1 = pattern.finditer('hello world 123 456 789') 3 s2 = pattern.finditer('one12twothree34four56', 0, 15) 4 for m in s1: 5 print(m.group()) # answer1: 123, answer2: 456, answer3: 789 6 print(m.span()) # answer1:(12, 15), answer2:(16, 19), answer3:(20, 23) 7 for m in s2: 8 print(m.group()) # answer1: 12, answer2: 34 9 print(m.span()) # answer1:(3, 5), answer2:(13, 15)
5. split函数
使用语法:
(1)re.split(pattern, string[, maxsplit=0, flags=0])
这个函数前面已经讲解过了。
(2)Pattern对象:split(string[, maxsplit]])
maxsplit 可指定分割次数,不指定将对字符串全部分割。
例子:
1 s = "a,1;b 2, c" 2 m = re.compile(r'[\s\,\;]+') 3 print(m.split(s)) # answer: ['a', '1', 'b', '2', 'c'] 4 m = re.compile(r'[\s\,\;]+') 5 print(m.split(s, maxsplit=1)) # answer: ['a', '1;b 2, c']
6. sub函数
使用语法:
(1)re.sub(pattern, repl, string, count=0, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:sub(repl, string[, count])
当repl为字符串时,可以用\id的形式引用分组,但不能使用编号0;当repl为函数时,返回的字符串中不能再引用分组。
1 pattern = re.compile(r'(\w+) (\w+)') 2 s = "ni 123, hao 456" 3 def func(m): 4 return 'hi'+' '+m.group(2) 5 print(pattern.sub(r'hello world', s)) # answer: "hello world, hello world" 6 print(pattern.sub(r'\2 \1', s)) # answer: "123 ni, 456 hao" 7 print(pattern.sub(func, s)) # answer: "hi 123, hi 456" 8 print(pattern.sub(func, s, 1)) # answer: "hi 123, hao 456"
7. subn函数
subn和sub类似,也用于替换操作。使用语法如下:
Pattern对象:subn(repl, string[, count])
返回一个元组,元组第一个元素和sub函数的结果相同,元组第二个元素返回替换次数。
例子:
1 p = re.compile(r'(\w+) (\w+)') 2 s = 'hello 123, hello 456' 3 def func(m): 4 return 'hi' + ' ' + m.group(2) 5 print(p.subn(r'hello world', s)) # answer: ('hello world, hello world', 2) 6 print(p.subn(r'\2 \1', s)) # answer: ('123 hello, 456 hello', 2) 7 print(p.subn(func, s)) # answer: ('hi 123, hi 456', 2) 8 print(p.subn(func, s, 1)) # answer: ('hi 123, hello 456', 1)
小结:
1. 使用Pattern对象的match、search、findall、finditer等函数可以指定匹配字符串的起始位置。
2. 对re模块的两种使用方式进行对比:
- 使用 re.compile 函数生成一个 Pattern 对象,然后使用 Pattern 对象的一系列方法对文本进行匹配查找;
- 直接使用 re.match, re.search 和 re.findall 等函数直接对文本匹配查找。
例子:
1 # 方法1 2 # 将正则表达式先编译成 Pattern 对象 3 pattern = re.compile(r'\d+') 4 print(pattern.match('123, 123')) 5 print(pattern.search('234, 234')) 6 print(pattern.findall('345, 345')) 7 # 方法2 8 print(re.match(r'\d+', '123, 123')) 9 print(re.search(r'\d+', '234, 234')) 10 print(re.findall(r'\d+', '345, 345'))
在上述例子中,我们发现他们共用了同一个正则表达式,表明上看好像没发现什么问题,但是当我们结合正则表达式的匹配过程进行分析时,就会发现这两种调用方式的效率是不一样的。使用正则表达式进行匹配的流程如下图所示:
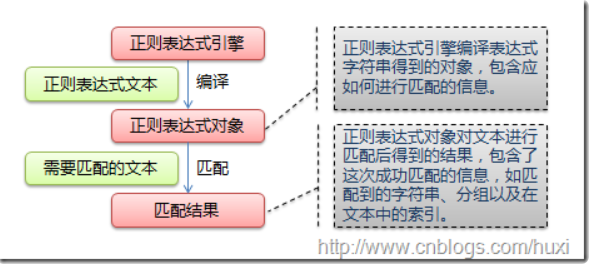
所以匹配流程是先对正则表达式进行编译,然后得到一个对象,再使用该对象对需要匹配的文本进行匹配。这时我们就发现方式2会对正则表达式进行了多次编译,这样效率不就降低了嘛。
所以我们可以得到如下结论:
如果一个正则表达式要用多次,那么出于效率考虑,我们可以预先编译正则表达式,然后调用的一系列函数时复用。如果直接使用re.match、re.search等函数,则需要每一次都对正则表达式进行编译,效率就会降低。因此在这种情况下推荐使用第一种方式。
三、贪恋匹配
正则表达式匹配时默认的是贪恋匹配,也就是会尽可能多的匹配更多字符。如果想使用非贪恋匹配,可以在正则表达式中加上'?'。
下面,我们来看1个实例:
1 content = 'a<exp>hello world</exp>b<exp>ni hao</exp>c' 2 pattern = re.compile(r'<exp>.*</exp>') 3 s = pattern.findall(content) ### 贪婪匹配,会在匹配到第一个</exp>时继续向右匹配,查找更长的匹配子串 4 print(s) # answer: ['<exp>hello world</exp>b<exp>ni hao</exp>'] 5 pattern2 = re.compile(r'<exp>.*?</exp>') 6 s2 = pattern2.findall(content) 7 print(s2) # answer: ['<exp>hello world</exp>', '<exp>ni hao</exp>']
四、分组
如果你想要提取子串或是想要重复提取多个字符,那么你可以选择用定义分组的形式。用()就可以表示要提取的分组(group),接下来用几个实例来理解一下分组的使用方式:
例子1:
1 m = re.match(r'(\d{4})-(\d{3,8})$', '0528-86889099') 2 print(m.group()) # answer: 0528-86889099 3 print(m.group(1)) # answer: 0528 4 print(m.group(2)) # answer: 86889099 5 print(m.groups()) # answer: ('0528', '86889099')
正则表达式'(\d{4})-(\d{3, 8})$'表示匹配两个分组,第一个分组(\d{4})是一个有4个数字的子串,第二个分组(\d{3,8})表示匹配一个数字子串,子串长度为3到8之间。
例子2:
1 s = 'ab123.456.78.90c' 2 m = re.search(r'(\d{1,3}\.){3}\d{1,3}', s) 3 print(m.group()) # answer: 123.456.78.90
正则表达式'(\d{1,3}\.){3}\d{1,3}‘的匹配过程分为两个部分,'(\d{1,3}\.){3}'表示匹配一个长度为1到3之间的数字子串加上一个英文句号的字符串,重复匹配 3 次该字符串,'\d{1,3}'表示匹配一个1到3位的数字子串,所以最后得到结果123.456.78.90。
例子3:
1 line = "Cats are smarter than dogs" 2 matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) 3 if matchObj: 4 print(matchObj.group()) # answer: Cats are smarter than dogs 5 print(matchObj.group(1)) # answer: Cats 6 print(matchObj.group(2)) # answer: smarter 7 else: 8 print("No match!!")
(.*)第一个分组,.* 代表匹配除换行符之外的所有字符。(.*?) 第二个匹配分组,.*? 后面加了个问号,代表非贪婪模式,只匹配符合条件的最少字符。后面的一个 .* 没有括号包围,所以不是分组,匹配效果和第一个一样,但是不计入匹配结果中。
group() 等同于group(0),表示匹配到的完整文本字符;
group(1) 得到第一组匹配结果,也就是(.*)匹配到的;
group(2) 得到第二组匹配结果,也就是(.*?)匹配到的;
因为只有匹配结果中只有两组,所以如果填 3 时会报错。
扩展:其他组操作如:命名组的使用、定义无捕获组、使用反向引用等,这部分内容还未弄懂,想了解的同学可以查看以下链接http://wiki.jikexueyuan.com/project/the-python-study-notes-second-edition/string.html
五、正则表达式修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。
| re.I | 忽略大小写。 |
| re.L | 做本地化识别(locale-aware)匹配。对中文支持不好。 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 单行。'.' 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 忽略多余空白字符,让表达式更易阅读。 |
例子:
1 s = "123abCD45ABcd" 2 print(re.findall(r"[a-z]+", s)) # answer: ['ab', 'cd'] 3 print(re.findall(r"[a-z]+", s, re.I)) # answer: ['abCD', 'ABcd']
六、正则表达式模式
下面列出了正则表达式模式语法中的特殊元素。
| ^ | 匹配字符串的开头。例如,^\d表示必须以数字开头。 |
| $ | 匹配字符串的末尾。例如,\d$表示必须以数字结束。若是^py$就只能匹配'py'了。 |
| . | 匹配任意字符,除了换行符“\n",当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。例如,要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| [...] | 用来表示一组字符,单独列出。例如:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符。例如:[^abc] 匹配除了a,b,c之外的字符。 |
| * | 匹配0个或多个的表达式。 |
| + | 匹配1个或多个的表达式。 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面表达式。例如, o{2} 不能匹配 "Bob" 中的 "o",但是能匹配 "food" 中的两个 o。 |
| {n,} | 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。"o{1,}" 等价于 "o+"。"o{0,}" 则等价于 "o*"。 |
| {n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b。例如,(P|p)ython可以匹配'Python'或者'python'。 |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]' |
| \W | 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]' |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字,等价于[^0-9] |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。例如,'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
七、常见的正则表达式
通常情况下,通过实例学习是一个高效的途径。接下来我将整理一些常见的正则表达式应用实例,大家可以试着将前面学的理论知识应用于实践啦。
(1)匹配国内13、15、18开头的手机号码的正则表达式
^(13[0-9]|15[0|1|2|3|5|6|7|8|9]|18[0-9])\d{8}$
(2)匹配中文的正则表达式
中文的unicode编码范围主要在 [\u4e00-\u9fa5],这个范围之中不包括全角(中文)标点。当我们想要把文本中的中文汉字提取出来时可以使用如下方式:
1 title = u'你好,hello,世界'
2 pattern = re.compile(r'[\u4e00-\u9fa5]+')
3 s = pattern.findall(title)
4 print(s) # answer: ['你好', '世界']
(3)匹配由数字、26个英文字母或下划线组成的字符串的正则表达式
^\w+$ #等价于 ^[0-9a-zA-Z_]+$
(4)匹配金额,精确到 2 位小数
^[0-9]+(.[0-9]{2})?$
(5)提取文本中的URL链接
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
(6)匹配身份证号码
15位:^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18位:^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
(7)匹配整数
^[1-9]\d*$ # 正整数 ^-[1-9]\d*$ # 负整数 ^-?[1-9]\d*$ # 整数 ^[1-9]\d*|0$ # 非负整数 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ # 正浮点数
注:由于平时正则用的太少,所以没有太多实用经验,本文内容只是研读了多个博客文章之后的整理笔记,对正则的解读很浅显。正则的相关知识太多,这里只是整理了我理解的部分内容,后续还会补充。
更多正则的相关内容可以参考以下文章:
极客学院的学习笔记:
1. python之旅 http://wiki.jikexueyuan.com/project/explore-python/Regular-Expressions/README.html
2. python网络爬虫 http://wiki.jikexueyuan.com/project/python-crawler/regular-expression.html
3. 轻松学习正则表达式 http://wiki.jikexueyuan.com/project/regex/introduction.html
4. python正则表达式指南 http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
最后,推荐一个更强大的正则表达式引擎-python的regex模块。

