


python学习过程(四)
上节我们说了怎么从一个网页中获取所有的a标签,包括a标签的文本和a标签的url,以及最后经过整理,直接从网页中获取key-value键值对,也就是标签:url这种形式。
例如 : 百度: http://www.baidu.com
在此基础,我们还可以做一些模糊筛选,将我们感兴趣的所有标签查找初来,供进一步爬虫分别爬取各个页面。今天,我们就是来做的事情就是把页面中的文本内容取出来,
类似的效果比如是这样的:


下面我们就一步步来实现这个过程:
首先是我们做的事情是导入一个类工具,对应的代码可以和我照着这么写就可以了:
import urllib2 import re from sgmllib import SGMLParser
导入了这个东西以后,我们就可以来创建我们自己的类来继承这个类,到时候里面的很多方法会很有用哦. . .
看看我们的类是什么样的:
class GetIdList(SGMLParser): #此处定义一个自己的类,叫作GetIdList,它肯定要继承SGMLParser啦 def reset(self): self.IDlist = [] #这就是最后返回给我们的结果,先是空的 self.flag = False #这就是一个做标记的作用,默认开始是False self.getdata=False #这也是标志作用,是否开始获取数据 self.verbatim = 0 SGMLParser.reset(self) def start_div(self,attrs): #表示遇到了一个div的开始,也就是碰到了<div> if self.flag == True: self.verbatim +=1 #进入子层div return for k,v in attrs: #我的理解就是attrs包含了class的信息,如果是碰到了我感兴趣的, if k =='class' and v =='entry-content': #这里entry-content是根据自己网页改,看你自己对哪个感兴趣 self.flag=True return def end_div(self): #表示结束div,碰到</div> if self.verbatim ==0: self.flag=False if self.flag == True: self.verbatim -=1 def start_p(self,attrs): #碰到p标签开始 if self.flag == False: return self.getdata=True #可以获取数据 def end_p(self):#遇到</p> #碰到p标签结束, if self.getdata: self.getdata = False #停止获取数据啦 def handle_data(self, text):#处理文本 if self.getdata: self.IDlist.append(text) #把我获取到的数据加到list中 def printID(self): #这里就是打印出获取到的结果并返回 for i in self.IDlist: print i return self.IDlist
类写好了,怎么去用呢??用时需要条件嘛,现在只是一个类,我们要对它实例化,学过java的知道,我们没有对象,去new一个就可以了嘛,
有了这个类的实例,你还有给我网页的文本嘛,也就是html源码嘛,前面我们说了怎么从网络上获取html,这里我们就开头图上说的那个静态的字符串
好了,看代码怎么去操作这个html,解析出我们想要的数据:
def printText(html): lister = GetIdList() #创建实例,这里可千万别说new一个 lister.feed(html) #提供我们的html l = lister.printID() #开始打印输出吧 printText(the_page)
这样,我们就把网页中感兴趣的div内容取出了,看结果:

啊?为什么最头上的<a>123</a>怎么没有,而<p><a href="http://www.baidu.com">感兴趣内容里面的a标签</a></p>却有呀,
因为前面123直接在div下,而感兴趣内容里面的a标签在P标签下,仔细看我们设计的类里,因为后者在p标签下,为了也获取前者123,我们完全可以在类里加这么两个函数
来获取a标签的123,看图:
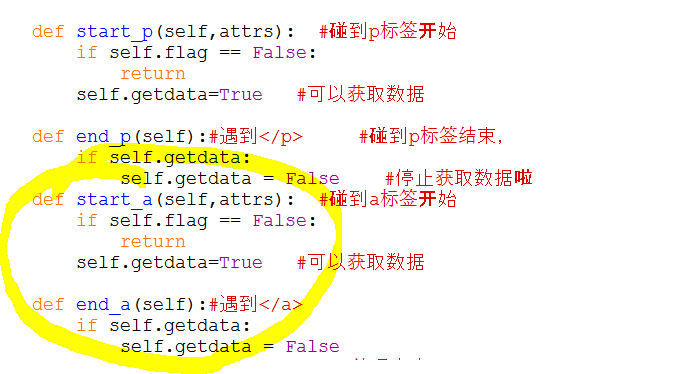

加了start_a和end_a,就可以获取到了我们div下的<a>123</a>了,那么我还想获取 <h1> 、<table> 、<ul> 、 . . . . . . 不用说了吧
接下来是不是可以获取到我感兴趣的一切啦?还在等什么,赶紧行动起来吧!!!
