

C++结构体字节对齐(c++常见问题开篇)
本站文章均为Jensen抹茶喵原创,转载务必在明显处注明:
转载自【博客园】 原文链接:http://www.cnblogs.com/JensenCat/p/4770171.html
1.0版本:
这里是头文件结构的定义:
一个非字节对齐结构体_tagTest2
一个字节对齐_tagTest3
(使用#pragma pack(push,1)来使字节以1个来对齐 , 使用#pragma pack(pop)来还原默认)
1 #pragma once 2 3 4 struct _tagTest1 5 { 6 }; 7 8 //非字节对齐的结果 9 struct _tagTest2 10 { 11 int n1; 12 char ch1; 13 float f1; 14 char szName[21]; 15 _tagTest1* pTag; 16 }; 17 18 #pragma pack(push,1) 19 //_tagTest3和2是一样的结构,字节对齐后的结果 20 struct _tagTest3 21 { 22 int n1; 23 char ch1; 24 float f1; 25 char szName[21]; 26 _tagTest1* pTag; 27 }; 28 29 #pragma pack(pop)
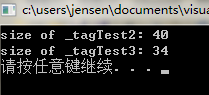
这里是实验代码:注释处写了分析,结果也入分析所料
1 #include "msgdef.h" 2 #include <Windows.h> 3 #include <iostream> 4 using namespace std; 5 6 void main() 7 { 8 /* 9 非字节对齐下,当前最大的空间是4个字节,所有结构都会向4个字节对齐... 10 int n1; 4 11 char ch1; 4 注解:1不是4的倍数..将扩张到4 12 float f1; 4 13 char szName[21]; 24 注解:21不是4的倍数..将扩张到24 14 _tagTest1* pTag; 4 15 总和为:40 16 */ 17 _tagTest2 k2; 18 cout<<"size of _tagTest2: "<<sizeof(k2)<<endl; 19 //看看内存模型 20 k2.n1 = 1; 21 k2.ch1 = 1; 22 k2.f1 = 1.0f; 23 memset(k2.szName , 1 , sizeof(k2.szName)); 24 k2.pTag = (_tagTest1*)&k2.n1; //此处测试用,别纠结 25 26 27 /* 28 字节对齐下, 29 int n1; 4 30 char ch1; 1 31 float f1; 4 32 char szName[21]; 21 33 _tagTest1* pTag; 4 34 总和为:34 35 */ 36 _tagTest3 k3; 37 cout<<"size of _tagTest3: "<<sizeof(k3)<<endl; 38 //看看内存模型 39 k3.n1 = 1; 40 k3.ch1 = 1; 41 k3.f1 = 1.0f; 42 memset(k3.szName , 1 , sizeof(k3.szName)); 43 k3.pTag = (_tagTest1*)&k3.n1; //此处测试用,别纠结 44 45 system("pause"); 46 }
实验结果输出:如分析所说的一样
这时候问题来了,那么字节不对齐时在内存是怎样的呢...下面是字节不对齐时的内存截图

下面的顺序清楚的对应,其中字节对齐的空位在内存里面补了cc,这个为什么本人没有深究,其他变量一目了然了,
至于浮点数的内存模型为什么是这样,可以度娘一下,很多人分析了浮点数float的内存模型。
----------------------------------------------------------------------------------------------------------------------------
----------------------------邪恶的分割线------------------------------------------------------------------------------------
2.0版本:
鉴于上面有些地方不够清晰...现在再列出几个例子...例子来自网上摘下...
1.在不对齐的情况下,拥有相同变量的结构最后得出的size也是不一样的..
//定义两个结构,下面描述一下内存存放地址
struct A
{
//假设内存地址从0开始...
int a; //0-3
char b; //4
short c;//6-7
}
//由于0-7的相加的结果为8...为自对齐4的倍数...
//所以结果:sizeof(A) = 8
//
struct B
{
//假设内存地址从0开始...
char a;//0
int b; //4-7
short c;//8-10
}
//由于0-10的相加的结果为11...不为自对齐4的倍数...补齐后为12
//所以结果:sizeof(B) = 12
2.再来使用Pragma手工更改了字节对齐值的情况,先看看Struct C的定义:
#pragma pack(2)
struct C
{
//假设从0开始
char a;//0
int b;//2-5
short c;//6-7
};
sizeof(C)的答案为8
Struct C的分析摘自网友总结:
step 1: 确定结构体C对齐值:选择成员中最大的对齐值,即int a,对齐值为4
step 2: 确定手工指定对齐值,使用手工指定的值:2
step 3: char a 的有效地址值=min(1,2),(因为0x0000%2=0),这样a的地址就是0x0000
step 4: int b 的有效对齐值=min(4,2),地址依次从0x0002~0x0005 (因为Ox0002%2=0)开始,分配4个字节,目前地址段分配情况就是:0x0000~0x0005
step 5: short c 的有效对齐值=min(2,2),由于要求考虑到对齐的情况,从0x0006(因为0x0006%2=0)开始,分配2个字节的地址0x0006~0x0007
目前为止,地址段的分配情况就是:0x0000~0x0007共8个字节,同时也保证了Struct C的对齐情况(2字节对齐,pragma(2)),sizeof(C)=8
结论:

最后的最后补多一个混合的例子:
struct tagS1 { //假设地址从0开始,这里最长的类型为_unT1,长度为8... //变量的首地址为地址模sizeof(变量类型)结果为0的地址开始 char a;//0 (0模1==0,所以从0开始) int n;//4-7 (2和3模4不等于0,从4开始) _unT1 t1;//8-15(8模8等于0,从8开始) long l;//16-19(16模4等于0,从16开始) char sz[22];//20-41(20模1等于0,从20开始) }; //由于0-41的长度为42,42不为8的倍数,所以补长为8的倍数,结果为48
