浅谈字节序(Byte Order)及其相关操作
2010-02-10 23:05 Jeffrey Zhao 阅读(24104) 评论(41) 编辑 收藏 举报最近在为Tokyo Tyrant写一个.NET客户端类库。Tokyo Tyrant公开了一个基于TCP协议的二进制协议,于是我们的工作其实也只是按照协议发送和读取一些二进制数据流而已,并不麻烦。不过在其中涉及到了“字节序”的概念,这本是计算机体系结构/操作系统等课程的基础,不过我还是打算在这里进行简单说明,并且对.NET中部分类库在此类数据流处理时的注意事项进行些许记录与总结。
字节序(Byte Order)
说到程序间的通信,说到底便是发送数据流。我们一般把字节(byte)看作是数据的最小单位。当然,其实一个字节中还包含8个比特(bit)──有时候我奇怪为什么很多朋友会不知道bit或是它和byte的关系。当我们拿到一系列byte的时候,它本身其实是没有意义的,有意义的只是“识别字节的方式”。例如,同样4个字节的数据,我们可以把它看作是1个32位整数、2个Unicode、或者字符4个ASCII字符。
同样我们知道,在一个32位的CPU中“字长”为32个bit,也就是4个byte。在这样的CPU中,总是以4字节对齐的方式来读取或写入内存,那么同样这4个字节的数据是以什么顺序保存在内存中的呢?例如,现在我们要向内存地址为a的地方写入数据0x0A0B0C0D,那么这4个字节分别落在哪个地址的内存上呢?这就涉及到字节序的问题了。
每个数据都有所谓的“有效位(significant byte)”,它的意思是“表示这个数据所用的字节”。例如一个32位整数,它的有效位就是4个字节。而对于0x0A0B0C0D来说,它的有效位从高到低便是0A、0B、0C及0D——这里您可以把它作为一个256进制的数来看(相对于我们平时所用的10进制数)。
而所谓大字节序(big endian),便是指其“最高有效位(most significant byte)”落在低地址上的存储方式。例如像地址a写入0x0A0B0C0D之后,在内存中的数据便是:
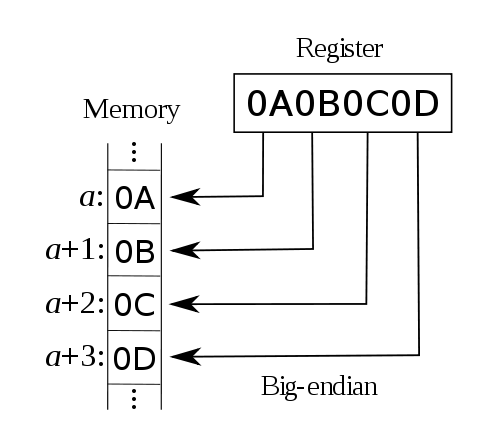
而对于小字节序(little endian)来说就正好相反了,它把“最低有效位(least significant byte)”放在低地址上。例如:
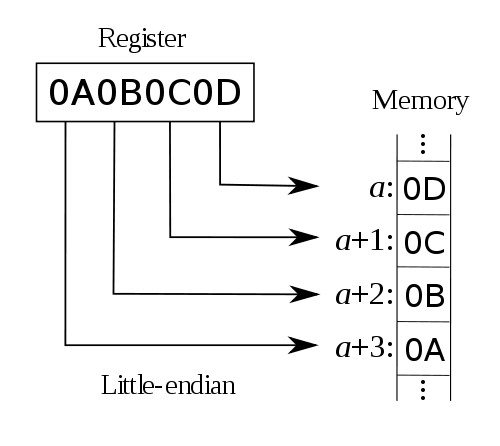
对于我们常用的CPU架构,如Intel,AMD的CPU使用的都是小字节序,而例如Mac OS以前所使用的Power PC使用的便是大字节序(不过现在Mac OS也使用Intel的CPU了)。此外,除了大字节序和小字节序之外,还有一种很少见的中字节序(middle endian),它会以2143的方式来保存数据(相对于大字节序的1234及小字节序的4321)。
关于字节序的详细说明,您可以参考Wikipedia里的Endianness条目。
相关.NET类库
BinaryWriter和BinaryReader
在.NET框架操作数据流的时候,我们往往会使用BinaryWriter和BinaryReader进行读写。这两个类中都有对应的WriteInt32或是ReadInt32方法,那么它们是如何处理字节序的呢?从MSDN上我们了解到BinaryReader使用小字节序读取数据。这意味着:
var stream = new MemoryStream(new byte[] { 4, 1, 0, 0 }); var reader = new BinaryReader(stream); int i = reader.ReadInt32(); // i == 260
与之类似,自然BinaryWriter也是使用小字节序来写入数据。
BitConverter
有时候我们还会使用BitConverter来转化byte数组及一个32位整数(自然也包括其他类型),这也是涉及到字节序的操作,那么它们又是如何处理的呢?与BinaryWriter和BinaryReader的“固定策略”不同,BitConverter的行为是平台相关的。
首先,BitConverter有一个只读静态字段IsLittleEndian,它表示当前平台的字节序。由于我们为不同的CPU会安装不同的.NET类库,因此您现在如果通过.NET Reflector来查看这个字段会发现它被设置为一个常量true。那么接下来,BitConverter上的各个方便便会根据IsLittleEndian的值产生不同行为了,例如它的ToInt32方法:
public static unsafe int ToInt32(byte[] value, int startIndex) { // ... fixed (byte* numRef = &(value[startIndex])) { if ((startIndex % 4) == 0) { return *(((int*)numRef)); } if (IsLittleEndian) { return numRef[0] | (numRef[1] << 8) | (numRef[2] << 16) | (numRef[3] << 24); } return (numRef[0] << 24) | (numRef[1] << 16) | (numRef[2] << 8) | numRef[3]; } }
显然,这里会根据IsLittleEndian返回不同的值。
判断当前平台的字节序
在.NET Framework中BitConverter.IsLittleEndian字段是一个常量,也就是说它在编译期便写入了一个静态的值。那么我们如果想要通过代码来判断当前平台的字节序,又该怎么做呢?其实这很简单:
static unsafe bool IsLittleEndian() { int i = 1; byte* b = (byte*)&i; return b[0] == 1; }
这里我们通过检查32位整数1的第一个字节来确定当前平台的字节序。当然,我们也可以使用其他类型,例如:
static unsafe bool AmILittleEndian() { // binary representations of 1.0: // big endian: 3f f0 00 00 00 00 00 00 // little endian: 00 00 00 00 00 00 f0 3f // arm fpa little endian: 00 00 f0 3f 00 00 00 00 double d = 1.0; byte* b = (byte*)&d; return (b[0] == 0); }
这段代码来自mono的BitConverter类库,至于它为什么使用double而不是int,我也不是很清楚。
Buffer.BlockCopy方法
.NET类库中自带一个Buffer.BlockCopy方法,它的作用是将一个数组的字节——不是元素——复制到另一个数组中去。换句话说,一个长度为100的int数组经过完整的复制后,就变成了长度为50的long数组,因为一个int为4字节,而long为8字节。从文档上看,Buffer.BlockCopy是与字节序相关的,也就是说,同样的.NET代码在字节序不同的平台上得到的结果可能不同。因此,我建议在使用这个方法的时候多加小心。
面向特定字节序编程
我们知道,BitConverter的工作结果是和当前平台的字节序相关的,但是在很多时候,尤其是根据某个公开的协议进行通信编程的时候,是需要固定一个字节序的。例如Tokyo Tyrant便要求每个整数都以大字节序的方式来通信——无论是发送还是读取。为了保证.NET代码的平台无关性,我们不能直接使用BitConverter.GetBytes或ToInt32方法进行转化。那么我们该怎么办呢?最直观的方法自然是手动进行转换:
static int ReadInt32(Stream stream) { var buffer = new byte[4]; stream.Read(buffer, 0, 4); return buffer[0] | (buffer[1] << 8) | (buffer[2] << 16) | (buffer[3] << 24); }
由于我们可以通过BitConverter.IsLittleEndian来得到当前平台的字节序,我们也可以用它进行判断:
static int ReadInt32(Stream stream) { var buffer = new byte[4]; stream.Read(buffer, 0, 4); if (BitConverter.IsLittleEndian) { Array.Reverse(buffer); } return BitConverter.ToInt32(buffer, 0); } static void WriteInt32(Stream stream, int value) { var buffer = BitConverter.GetBytes(value); if (BitConverter.IsLittleEndian) { Array.Reverse(buffer); } stream.Write(buffer, 0, buffer.Length); }
此外,我们知道BinaryWriter和BinaryReader都是依据小字节序进行读写的,因此我们也可以利用这点来读写数据流。要不,接下来就由您试试看如何?

