用python进行自然语言处理--第一章:语言处理与python(nltk的基本操作函数理解)
加载所需要用的文本:

若想找到所需文本,则直接输入文本的名字:

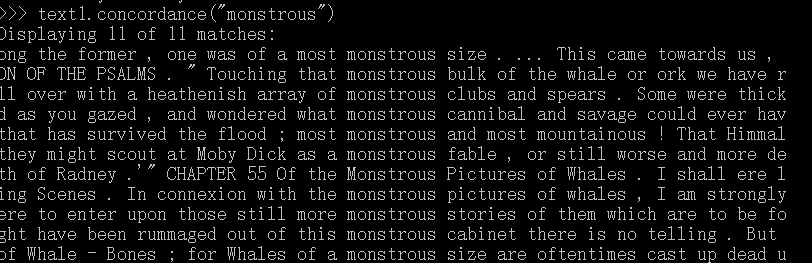
函数concordance()显示一个指定单词的的每一次出现,联通一些上下文一起显示:
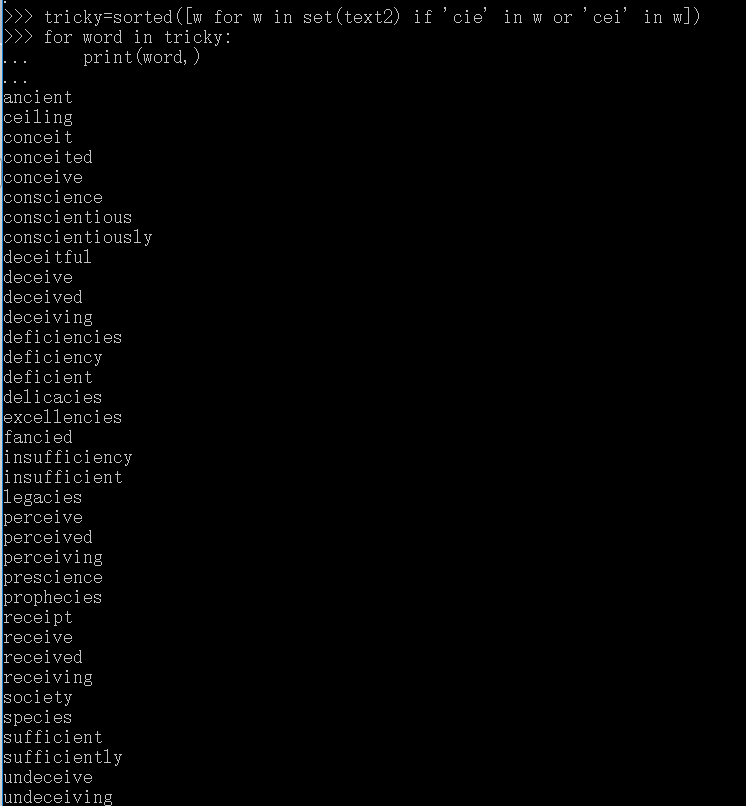
similar()函数:首先找到与给定词具有相同上下文的所有词,然后根据这些词的出现次数,按出现次数从高到低依次输出:

common_plot()函数:允许我们研究两个或两个以上的词共同的上下文

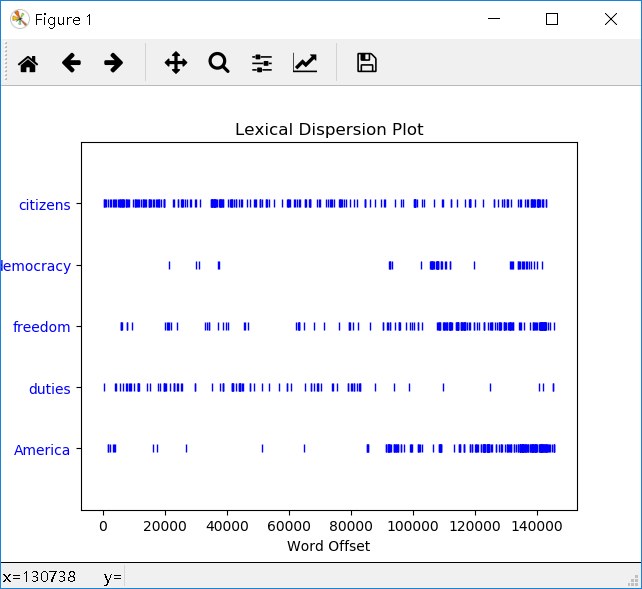
dispersion_plot():以离散图表示出指定词在文本中出现的位置和次数:

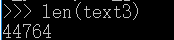
获取文本长度:
set()函数:获取指定文本的词汇表,即将所有文本词汇进行去重处理
sorted()函数:对词汇表进行排序,以各种标点符号开始,大写字母开头的单词排在小写字母的前面

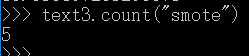
文本词汇的丰富度计算(即每个词汇平均被使用的次数):

计算一个词在文本中出现的次数:
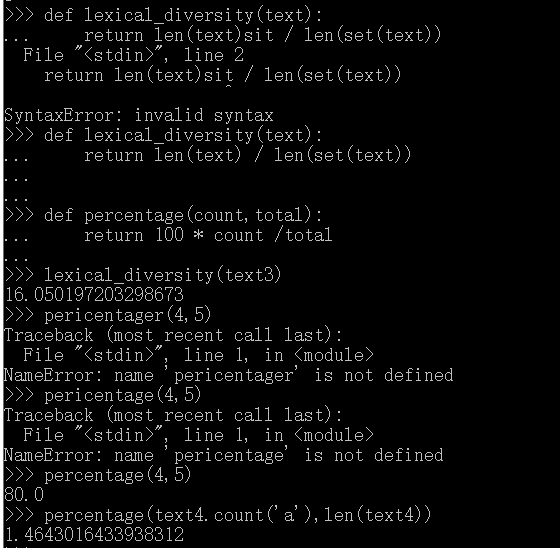
使用关键字def开定义函数:
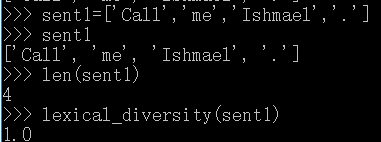
链表(list,也叫列表):
对链表的基本操作:连接、追加

索引列表:
找出文本text4中索引173的元素:
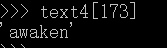
找出一个词第一次出现的索引:
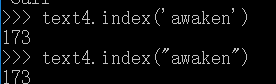
切片:

为Python变量选择名称时请注意:首先应以字母开始,后面跟数字或字母,不能包含空格,但可以用下划线把单词分开。
字符串:

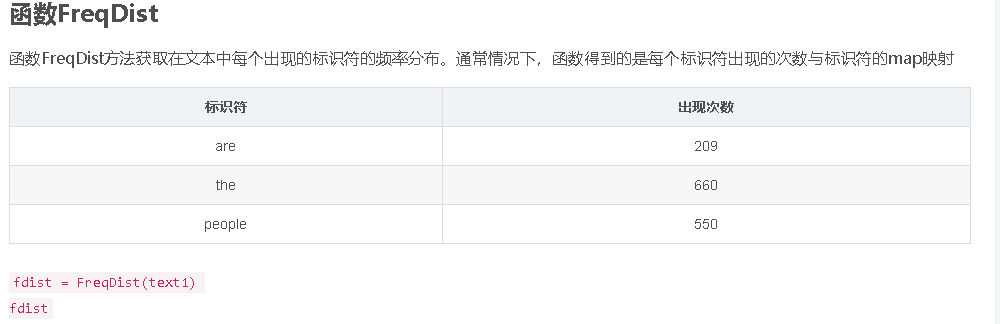
函数FreqDist():
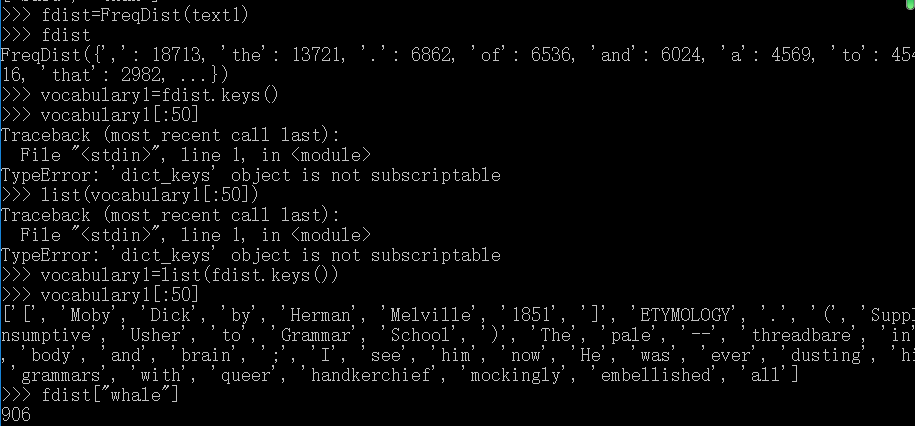
聊天语料库中所有长度超过7个字符并且出现次数超过7次的词:

获取二元组中最频繁搭配的组合:
不同词长单词的个数:
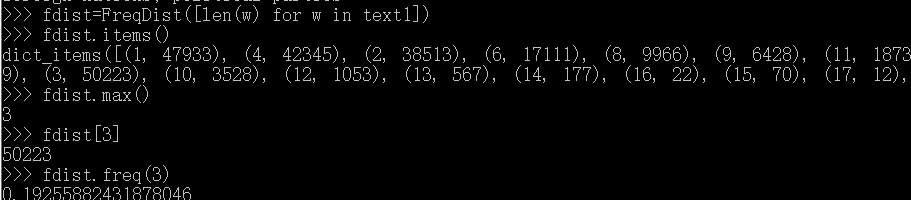
nltk频率分布类中定义的函数:

一些词的比较运算符:

决策与控制实例: