
大型架构之科普工具篇
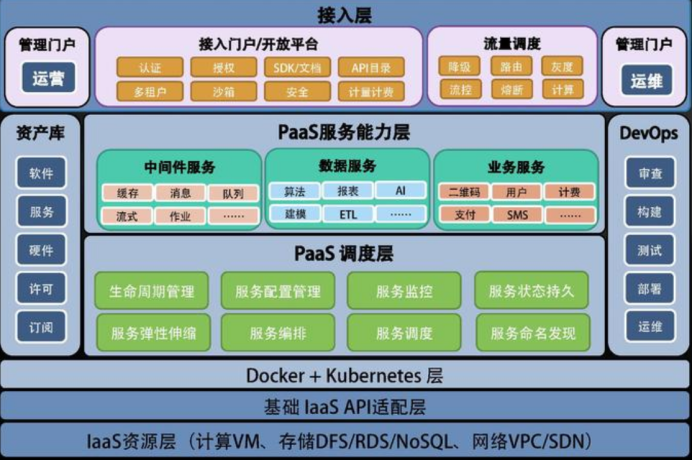
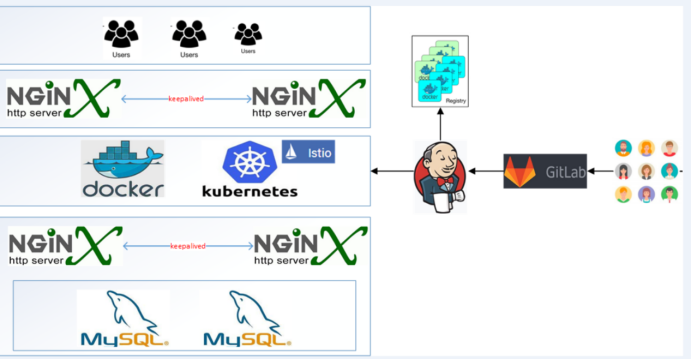
底部更多详情图....
I.1 Java Spring Boot
适合构建微服务系统
- 使用 Spring 项目引导页面可以在几秒构建一个项目
- 方便对外输出各种形式的服务,如 REST API、WebSocket、Web、Streaming、Tasks
- 非常简洁的安全策略集成
- 支持关系数据库和非关系数据库
- 支持运行期内嵌容器,如 Tomcat、Jetty
- 强大的开发包,支持热启动
- 自动管理依赖
- 自带应用监控
- 支持各种 IED,如 IntelliJ IDEA 、NetBeans
其它语言: .net core 、 Go 等
I.2 Jenkins
自动CI程序,持续集成
- 开源免费
- 跨平台,支持所有的平台(本人是安装在Ubuntu14.04上的,使用jenkins docker镜像没有成功)
- master/slave支持分布式的build
- web形式的可视化的管理页面
- 安装配置超级简单
- tips及时快速的帮助
- 已有的几百个插件
I.3 GitLab
- 一个自托管的Git项目仓库,可通过Web界面进行访问公开的或者私人项目安装。
它拥有与GitHub类似的功能,能够浏览源代码,管理缺陷和注释。可以管理团队对仓库的访问,它非常易于浏览提交过的版本并提供一个文件历史库。
团队成员可以利用内置的简单聊天程序(Wall)进行交流。它还提供一个代码片段收集功能可以轻松实现代码复用,便于日后有需要的时候进行查找。 - Dokcer
- Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的、可移植的、自给自足的容器。开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机)、bare metal、OpenStack 集群和其他的基础应用平台。
- Docker通常用于如下场景:
- web应用的自动化打包和发布;
- 自动化测试和持续集成、发布;
- 在服务型环境中部署和调整数据库或其他的后台应用;
- 从头编译或者扩展现有的OpenShift或Cloud Foundry平台来搭建自己的PaaS环境。
I.4 Kubernetes
- Kubernetes是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
- 通过Kubernetes你可以:
- 快速部署应用
- 快速扩展应用
- 无缝对接新的应用功能
- 节省资源,优化硬件资源的使用
I.5 MQ
当系统中出现“生产“和“消费“的速度或稳定性等因素不一致的时候,就需要消息队列,作为抽象层,弥合双方的差异。“ 消息 ”是在两台计算机间传送的数据单位。消息可以非常简单,例如只包含文本字符串;也可以更复杂,可能包含嵌入对象。消息被发送到队列中,“ 消息队列 ”是在消息的传输过程中保存消息的容器 。
- 解耦
- 冗余
- 扩展性
- 灵活性 & 峰值处理能力
- 可恢复性
- 送达保证
- 排序保证
- 缓冲
- 理解数据流
- 异步通信
I.6 SQL DB
- 数据库(Database)是按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库。
- 简单来说是本身可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据进行新增、截取、更新、删除等操作。
- 在经济管理的日常工作中,常常需要把某些相关的数据放进这样的“仓库”,并根据管理的需要进行相应的处理。
MySQL/PostgreSQL是传统关系型数据库的代表。
HBase是Big Tables技术的代表(行索引,列存储)。
Neo4j(http://www.neo4j.org/)是图数据库代表,用来存储复杂、多维度的图结构数据。
Redis是基于Key-Value的NoSQL代表,有Redis-to-go提供存储服务。
MongoDB/CouchDB是基于Document的NoSQL代表,Couchbase是Document/Key-Value技术的融合。
VoltDB是NewSQL的代表,具备数据一致性和良好的扩展性,性能宣称是MySQL的数十倍以上。
TiDB 是国内 PingCAP 团队开发的一个分布式 SQL 数据库。其灵感来自于 Google 的 F1 和 Google spanner, TiDB 支持包括传统 RDBMS 和 NoSQL 的特性。
I.7 TICK stack
InfluxDB
时序数据库工具。
Telegraf
是一个数据收集和入库的工具。提供了很多 input 和 output 插件,比如收集本地的 cpu、load、网络流量等数据,然后写入 InfluxDB 或者 Kafka 等。
Chronograf
绘图工具
Kapacitor
Kapacitor 是 InfluxData 家的告警工具,通过读取 InfluxDB 中的数据,根据 DLS 类型配置 TickScript 来进行告警。
I.8 Keepalived
keepalived是集群管理中保证集群高可用的一个服务软件,其功能类似于heartbeat,用来防止单点故障。
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的
I.9 Harbor
Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器。
I.10 Ignite / Redis
Apache Ignite 内存数据组织框架是一个高性能、集成化和分布式的内存计算和事务平台,用于大规模的数据集处理,比传统的基于磁盘或闪存的技术具有更高的性能,同时他还为应用和不同的数据源之间提供高性能、分布式内存中数据组织管理的功能。
|
序号 |
对比项目 |
Apache Ignite |
Redis |
|
1 |
JCache (JSR 107) |
Ignite完全兼容JCache(JSR107)缓存规范 |
不支持 |
|
2 |
ACID事务 |
Ignite完全支持ACID事务,包括乐观和悲观并发模型以及READ_COMMITTED, REPEATABLE_READ和SERIALIZABLE隔离级别。 |
Redis提供了客户端乐观事务的有限支持,在并发更新情况下,客户端需要手工重试事务。 |
|
3 |
数据分区 |
Ignite支持分区缓存,类似于一个分布式哈希,集群中的每个节点都存储数据的一部分,在拓扑发生变化的情况下,Ignite会自动进行数据的再平衡。 |
Redis没有提供分区,但是提供了副本的分片,使用分片非常死板,并且不管是客户端还是服务端,每当拓扑发生变化时都需要一系列相当复杂的手工步骤。 |
|
4 |
全复制 |
Ignite支持缓存的复制,集群中的每个节点的每个键值对都支持。 |
Redis不提供对全复制的直接支持。 |
|
5 |
原生对象 |
Ignite允许用户使用自己的领域对象模型并且提供对任何Java/Scala, C++和.NET/C#数据类型(对象)的原生支持,用户可以在Ignite缓存中轻易的存储任何程序和领域对象。 |
Redis不允许用户使用自定义数据类型,仅支持预定义的基本数据结构集合,比如Set、List、Array以及一些其他的。 |
|
6 |
客户端侧(近)缓存 |
Ignite提供对于最近访问数据的客户端侧缓存的直接支持。 |
不支持 |
|
7 |
(服务端侧)并置处理 |
Ignite支持在服务器端靠近数据以并置的方式直接执行任何Java, C++和.NET/C#代码。 |
Redis通常没有任何并置处理的能力,服务器端基本只支持LUA脚本语言,服务器端不直接支持Java, .NET,或者C++代码执行。 |
|
8 |
SQL查询 |
Ignite支持完整SQL(ANSI-99)语法以查询内存中的数据。 |
Redis不支持任何查询语言,只支持客户端缓存API。 |
|
9 |
持续查询 |
Ignite提供对客户端和服务器端持续查询的支持,用户可以设置服务器端的过滤器来减少和降低传输到客户端的事件数量。 |
Redis提供客户端基于键的事件通知的支持,但是他不提供服务器端的过滤器,因此造成了在客户端和服务器端中更新通知网络流量的显著增加。 |
|
10 |
数据库集成 |
Ignite可以自动集成外部的数据库-RDBMS, NoSQL,和HDFS。 |
Redis无法与外部数据库集成。 |
I.11 ELK
ELK由Elasticsearch、Logstash和Kibana三部分组件组成;
Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用
kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
I.12 Kong(Nginx)
Kong是一款基于Nginx_Lua模块写的高可用,易扩展由Mashape公司开源的API Gateway项目。由于Kong是基于Nginx的,所以可以水平扩展多个Kong服务器,通过前置的负载均衡配置把请求均匀地分发到各个Server,来应对大批量的网络请求。
Kong主要有三个组件:
Kong Server :基于nginx的服务器,用来接收API请求。
Apache Cassandra/PostgreSQL :用来存储操作数据。
Kong dashboard:官方推荐UI管理工具,当然,也可以使用 restfull 方式 管理admin api。
Kong采用插件机制进行功能定制,插件集(可以是0或n个)在API请求响应循环的生命周期中被执行。插件使用Lua编写,目前已有几个基础功能:HTTP基本认证、密钥认证、CORS( Cross-origin Resource Sharing,跨域资源共享)、TCP、UDP、文件日志、API请求限流、请求转发以及nginx监控。
I.13 Openstack
OpenStack + KVM
OpenStack:开源管理项目
OpenStack是一个旨在为公共及私有云的建设与管理提供软件的开源项目。它不是一个软件,而是由几个主要的组件组合起来完成一些具体的工作。OpenStack由以下五个相对独立的组件构成:
OpenStack Compute(Nova)是一套控制器,用于虚拟机计算或使用群组启动虚拟机实例;
OpenStack镜像服务(Glance)是一套虚拟机镜像查找及检索系统,实现虚拟机镜像管理;
OpenStack对象存储(Swift)是一套用于在大规模可扩展系统中通过内置冗余及容错机制,以对象为单位的存储系统,类似于Amazon S3;
OpenStack Keystone,用于用户身份服务与资源管理以及
OpenStack Horizon,基于Django的仪表板接口,是个图形化管理前端。
这个起初由美国国家航空航天局和Rackspace在2010年末合作研发的开源项目,旨在打造易于部署、功能丰富且易于扩展的云计算平台。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性,企图成为数据中心的操作系统,即云操作系统。
KVM:开放虚拟化技术
KVM(Kernel-based Virtual Machine)是一个开源的系统虚拟化模块,它需要硬件支持,如Intel VT技术或者AMD V技术,是基于硬件的完全虚拟化,完全内置于Linux。
2008年,红帽收购Qumranet获得了KVM技术,并将其作为虚拟化战略的一部分大力推广,在2011年发布RHEL6时支持KVM作为唯一的hypervisor。KVM主打的就是高性能、扩展性、高安全,以及低成本。
I.14 Disconf
专注于各种「分布式系统配置管理」的「通用组件」和「通用平台」, 提供统一的「配置管理服务」。
I.15 Apollo
Apollo是携程框架部门研发的配置管理平台,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性。
服务端基于Spring Boot和Spring Cloud开发,打包后可以直接运行,不需要额外安装Tomcat等应用容器。
I.16 gRPC
gRPC 是一个高性能、开源和通用的 RPC 框架,面向移动和 HTTP/2 设计。目前提供 C、Java 和 Go 语言版本,分别是:grpc, grpc-java, grpc-go. 其中 C 版本支持 C, C++, Node.js, Python, Ruby, Objective-C, PHP 和 C# 支持.
gRPC 基于 HTTP/2 标准设计,带来诸如双向流、流控、头部压缩、单 TCP 连接上的多复用请求等特。这些特性使得其在移动设备上表现更好,更省电和节省空间占用。
I.17 Canal
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。
基于日志增量订阅&消费支持的业务:
- 数据库镜像
- 数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- search build
- 业务cache刷新
- 价格变化等重要业务消息
I.18 Spark streaming
Spark Streaming 是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及TCP sockets,从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。
I.19 SonarQube
Sonar是一个用于代码质量管理的开源平台,用于管理源代码的质量,可以从七个维度检测代码质量
通过插件形式,可以支持包括java,C#,C/C++,PL/SQL,Cobol,JavaScrip,Groovy等等二十几种编程语言的代码质量管理与检测
I.20 DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
I.21 禅道管理 / Jira
禅道功能
1)产品管理:产品、需求、计划、发布、路线图等功能。
2)项目管理:项目、任务、团队、build、燃尽图等功能。
3)质量管理:bug、测试用例、测试任务、测试结果等功能。
4)文档管理:产品文档库、项目文档库、自定义文档库等功能。
5)事务管理:todo管理,我的任务、我的Bug、我的需求、我的项目等个人事务管理功能。
6)组织管理:部门、用户、分组、权限等功能。
7)统计功能:丰富的统计表。
8)搜索功能:通过搜索找到相应的数据。
JIRA功能
1)问题追踪和管理(问题类型包括New Feature-新功能、Bug-缺陷、Task-任务、 Improvement-改进 四种);
2)问题跟进情况的分析报告;
3)项目类别管理功能;
4)组件/模块负责人功能;
5)项目email地址功能;
6)无限制的工作流。
I.22 XXJOB
XXL-JOB是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
- 简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
- 动态:支持动态修改任务状态、暂停/恢复任务,以及终止运行中任务,即时生效;
- 调度中心HA(中心式):调度采用中心式设计,“调度中心”基于集群Quartz实现并支持集群部署,可保证调度中心HA;
- 执行器HA(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行HA;
- 注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
- 弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
- 路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
- 失败处理策略;调度失败时的处理策略,策略包括:失败告警(默认)、失败重试;
- 失败重试:调度中心调度失败且启用"失败重试"策略时,将会自动重试一次;执行器执行失败且回调失败重试状态时,也将会自动重试一次;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
- 动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
- 事件触发:除了"Cron方式"和"任务依赖方式"触发任务执行之外,支持基于事件的触发任务方式。调度中心提供触发任务单次执行的API服务,可根据业务事件灵活触发。
- 任务进度监控:支持实时监控任务进度;
- Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志;
- GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
- 脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS等类型脚本;
- 任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
- 一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
- 自定义任务参数:支持在线配置调度任务入参,即时生效;
- 调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞;
- 数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性;
- 邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件;
- 推送maven中央仓库: 将会把最新稳定版推送到maven中央仓库, 方便用户接入和使用;
- 运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
- 全异步:系统底层实现全部异步化,针对密集调度进行流量削峰,理论上支持任意时长任务的运行;
I.23 Salt stack
一种全新的基础设施管理方式,部署轻松,在几分钟内可运行起来,扩展性好,很容易管理上万台服务器,速度够快,服务器之间秒级通讯。
salt底层采用动态的连接总线, 使其可以用于编配, 远程执行, 配置管理等等.
I.24 Istio
Istio 作为用于微服务服务聚合层管理的新锐项目,是 Google、IBM、Lyft(海外共享出行公司、Uber劲敌) 首个共同联合开源的项目,提供了统一的连接,安全,管理和监控微服务的方案。
目前首个测试版是针对 Kubernetes 环境的,社区宣称在未来几个月内会为虚拟机和 Cloud Foundry 等其他环境增加支持。 Istio 将流量管理添加到微服务中,并为增值功能(如安全性,监控,路由,连接管理和策略)创造了基础。
- HTTP、gRPC 和 TCP 网络流量的自动负载均衡;
- 提供了丰富的路由规则,实现细粒度的网络流量行为控制;
- 流量加密、服务间认证,以及强身份声明;
- 全范围(Fleet-wide)的策略执行;
- 深度遥测和报告。
架构篇
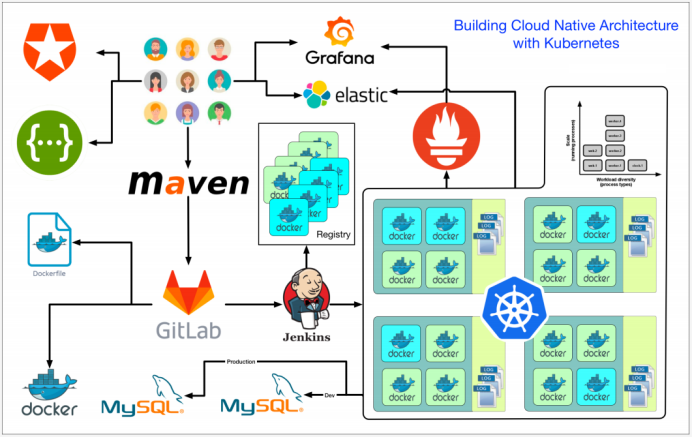
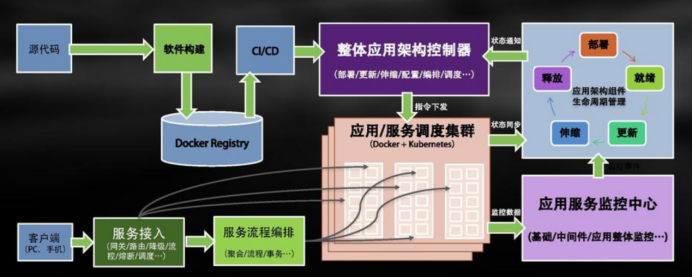
安全篇

基础篇
Salt Stack + OpenStack + KVM + Kubernetes + Istio

