
福大软工1816 · 第五次作业 - 结对作业2
结对队友:何裕捷
他的博客地址:http://www.cnblogs.com/fdhyj
他的本次作业地址:https://www.cnblogs.com/fdhyj/p/9769819.html
Github项目地址:https://github.com/ljjy/pair-project
分工明细
何裕捷:在个人项目的基础上改进WordCount,编码实现所有功能
黄培鑫:学习使用爬虫工具,辅助测试寻找bug,整理撰写博客
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 360 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 | 30 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 90 |
| · Coding | · 具体编码 | 360 | 600 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 60 |
| 合计 | 880 | 1370 |
解题思路描述与设计实现说明
1.爬虫使用
上网搜索了几款爬虫工具,最终选择了“八爪鱼采集器”。
(这里给出一个八爪鱼采集器入门教程:https://www.bilibili.com/video/av24131288?t=3820)
对于本次作业,首先我们来到主界面,点击自定义采集下方的立即使用。
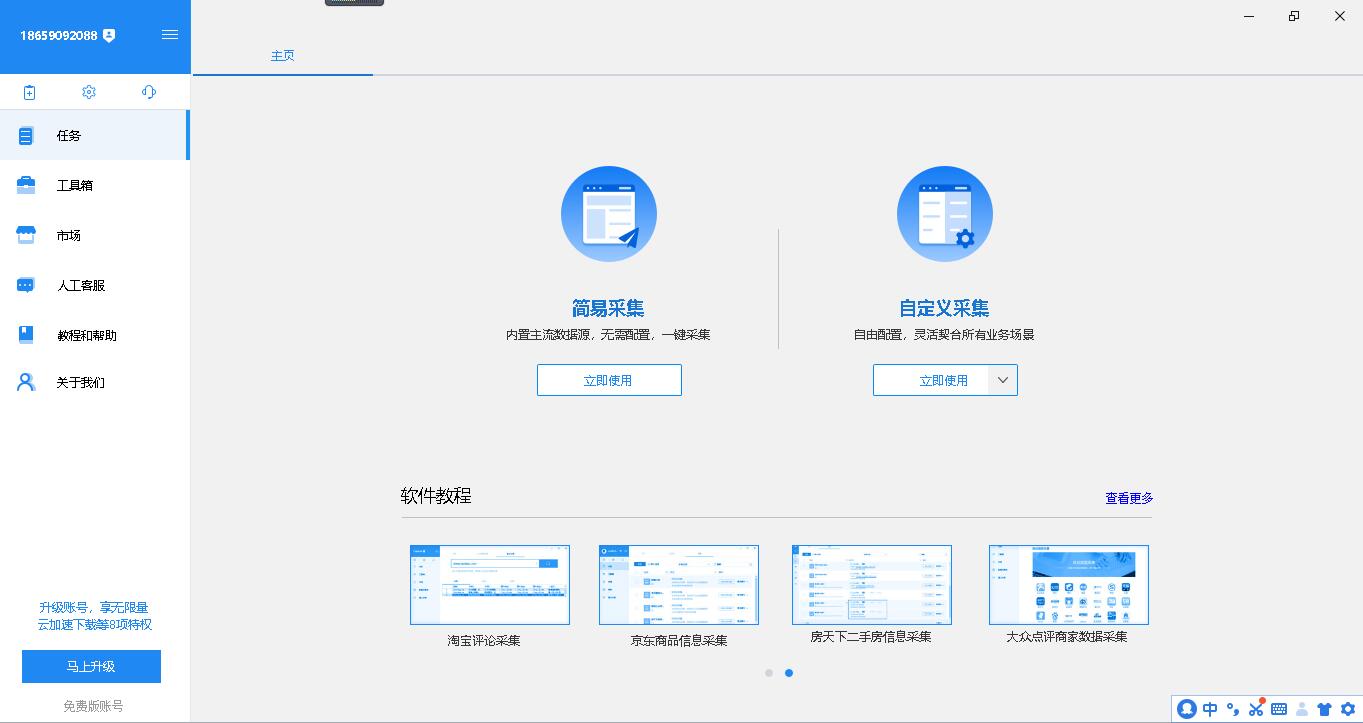
接着选择手动输入在网址中输入网址,然后点击保存网址,接下来就可以开始选择要采集什么数据了。
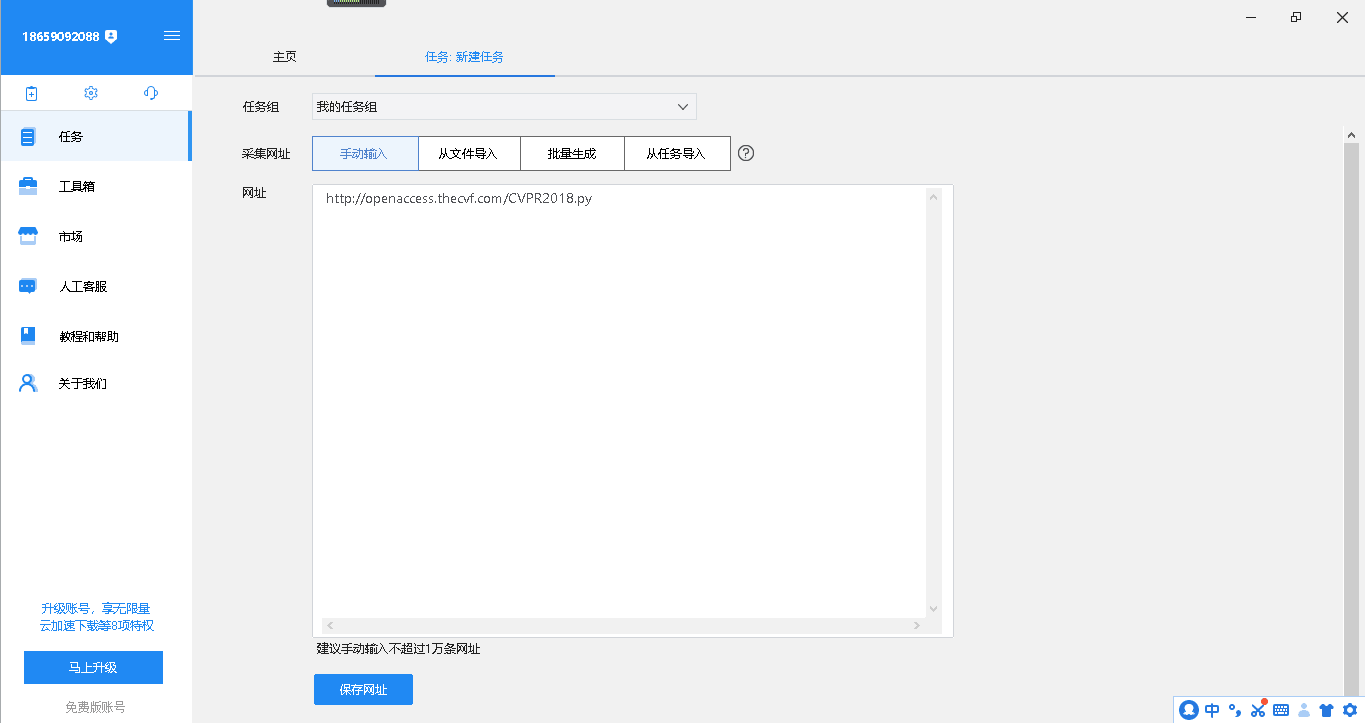
经过一会儿等待后八爪鱼采集器内置的浏览器便打开了这个网页,鼠标移动到第一篇论文的标题上,点击。
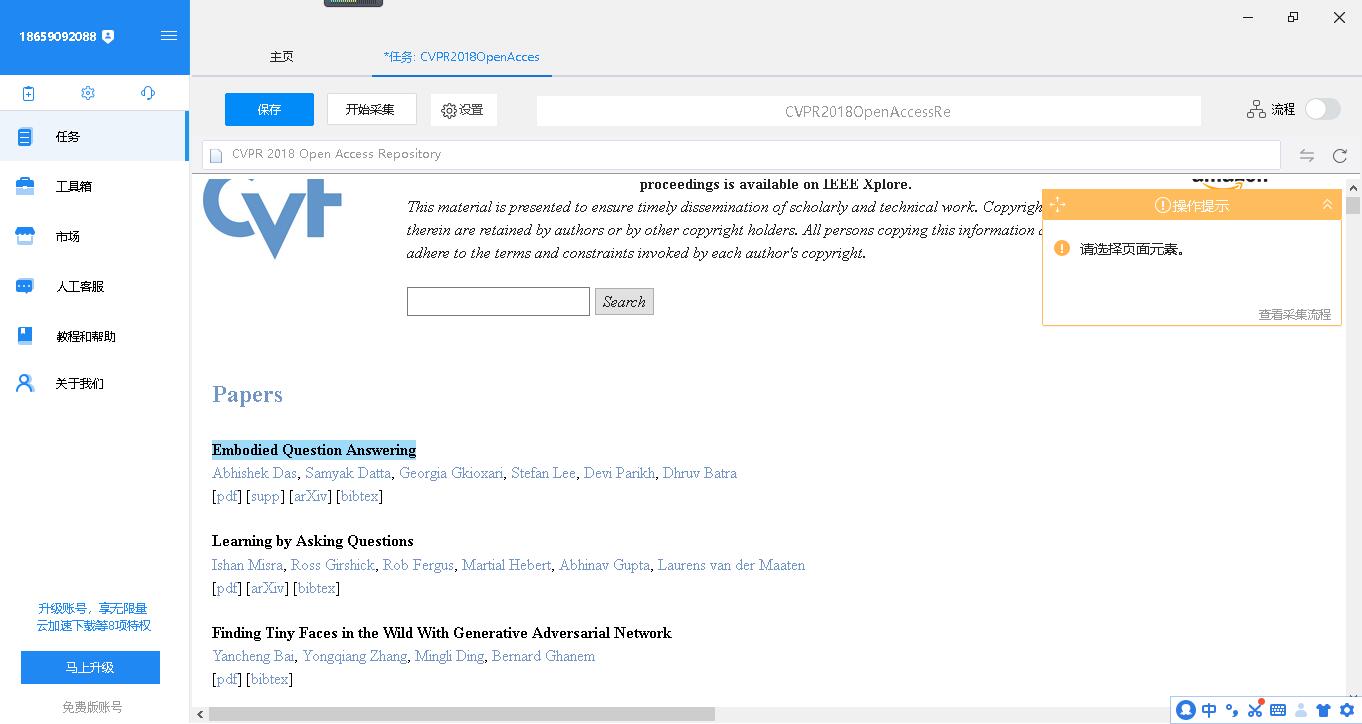
此时右侧出现了操作提示,依次点击“选中全部”-“循环点击每个链接”。
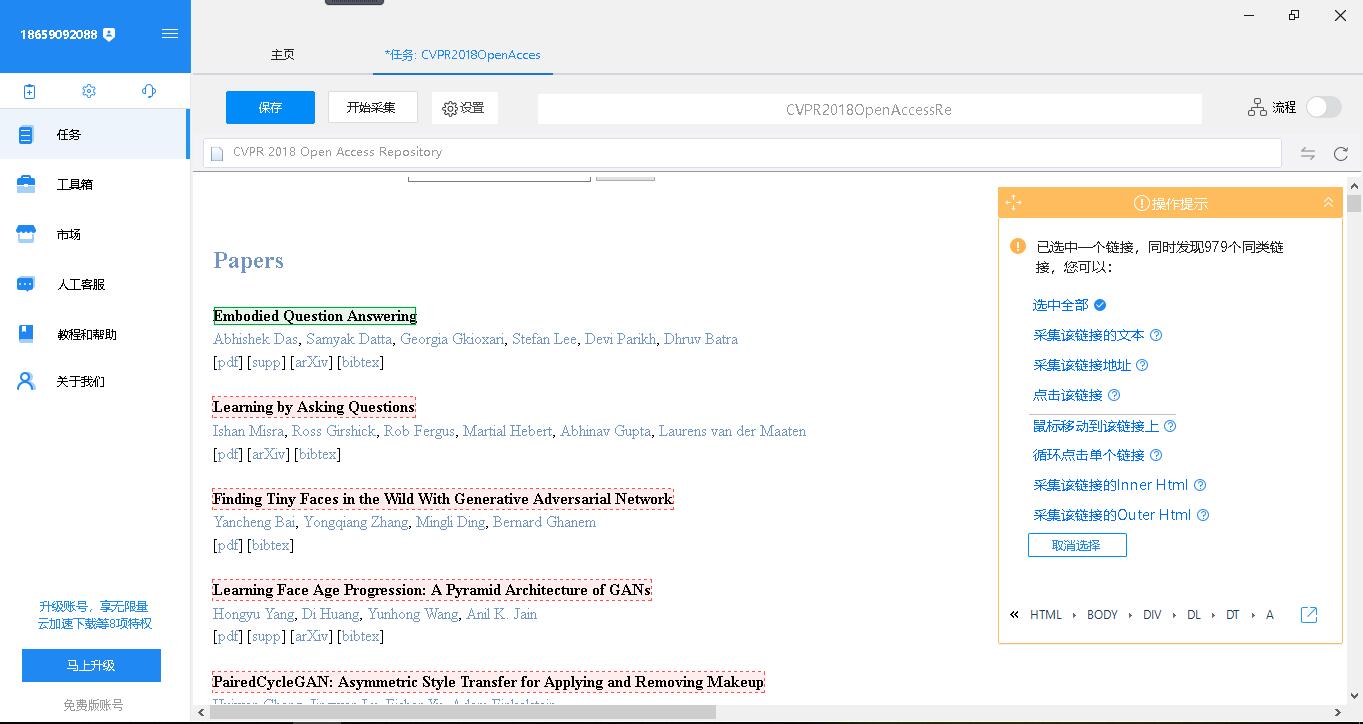
鼠标移动到标题处点击,选择“采集该元素的文本”;再移动到摘要处,选择“采集该元素的文本”。
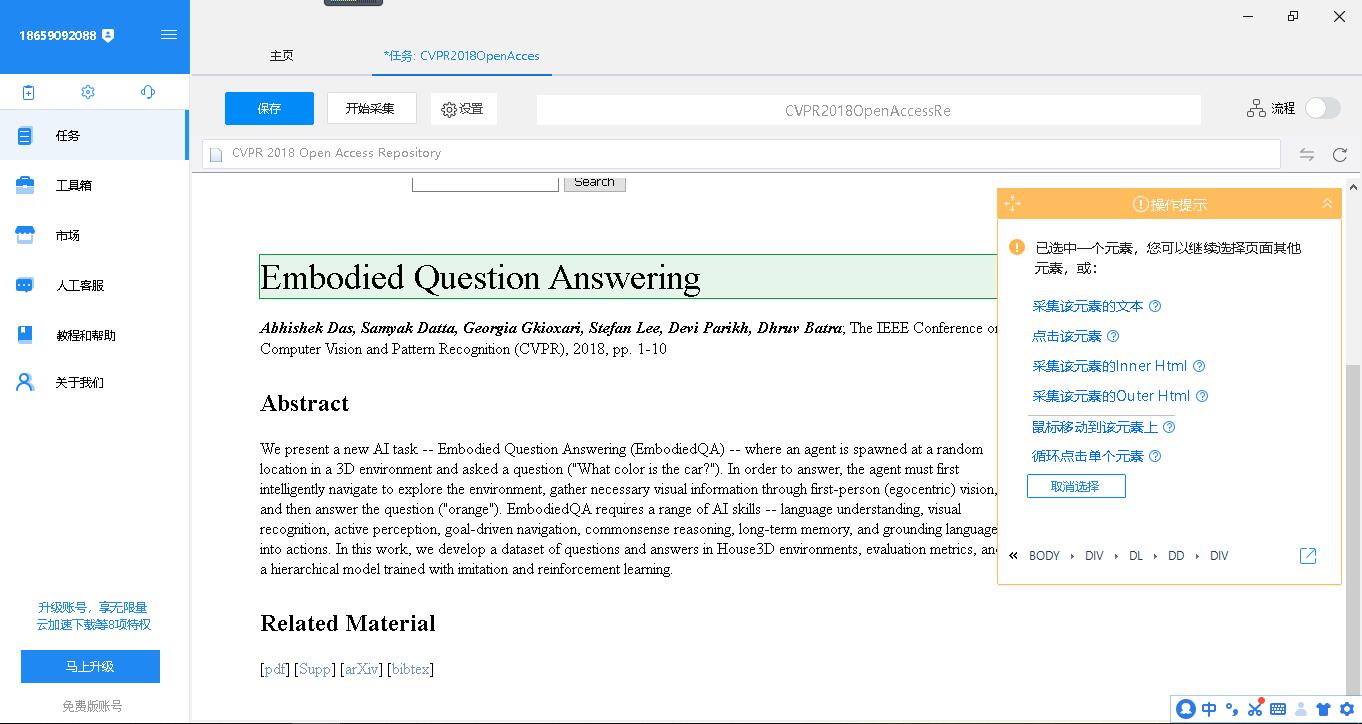
选择完要采集的东西之后,点击右上角的“流程”可以进行查看。
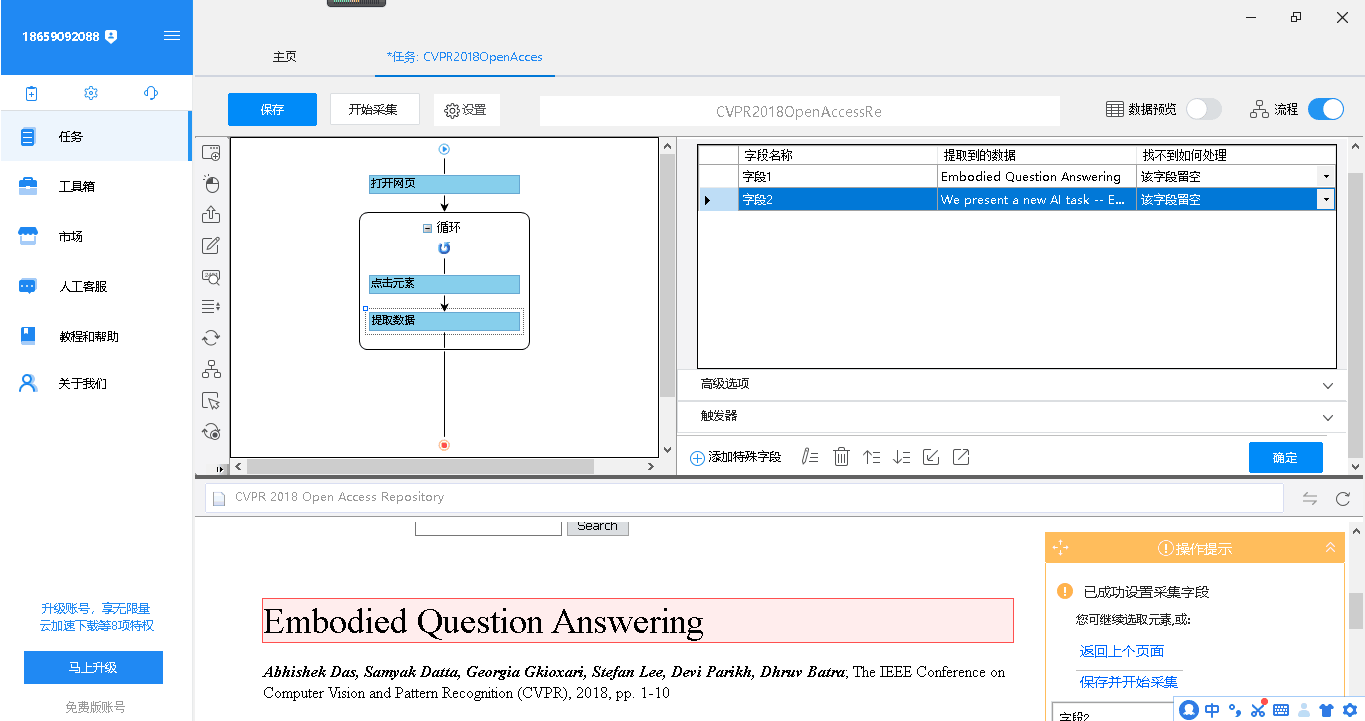
由于作业要求,标题前需加上“Title: ”,则选中字符1点击下方的铅笔状的“自定义数据字段”-“格式化数据”-“添加步骤”-“添加前缀“,在前缀处输入“Title: ”,点击下方的计算可以预览效果,然后点击确定。同理给摘要加上“Abstract: ”的前缀。
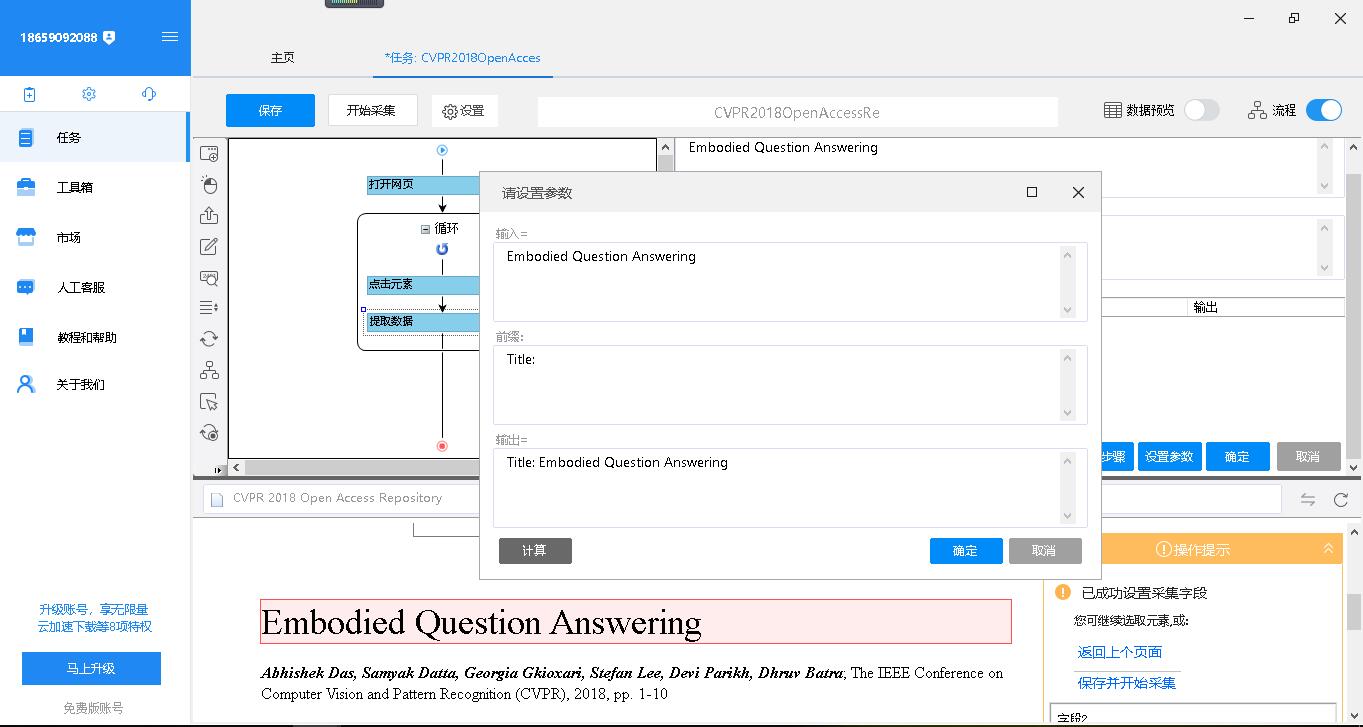
全部设置好了之后,点击“开始采集”-“启动本地采集”就可以愉快地开始采集数据了。
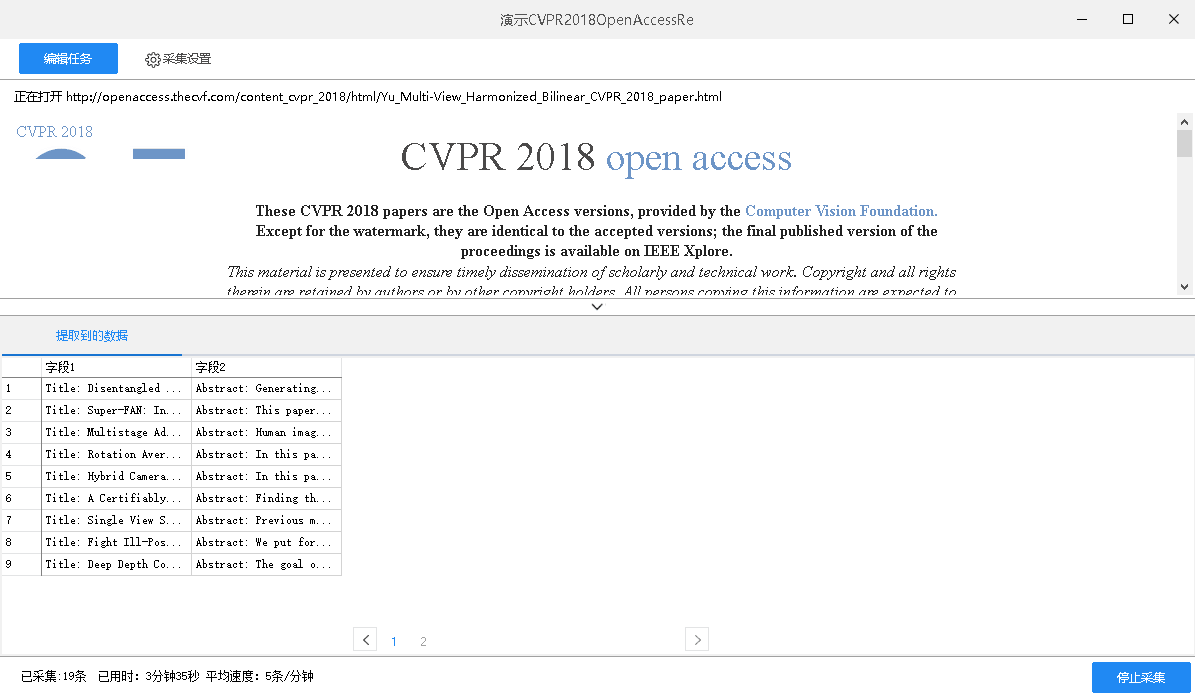
采集结束后,由于无法直接导出为符合作业格式要求的txt,所以选择导出为excel,再经过一番人工排版之后便形成美妙的result.txt。

2.代码组织与内部实现设计
类图:
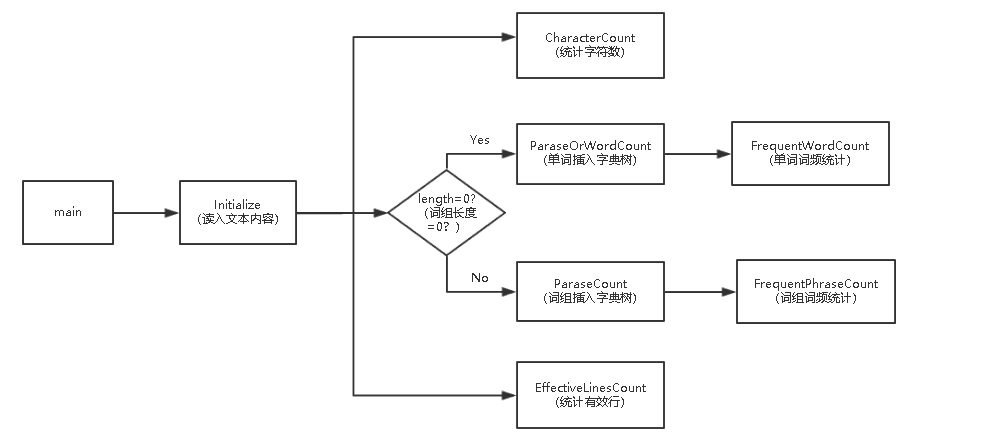
3.说明算法的关键与关键实现部分流程图
维护一个n+n-1的队列(n为词组长度),按顺序检索文本,遇到合法单词,压入该单词和单词后的分隔符串,如果队列未满,则什么都不干,如果队列恰好满了,则找到一个词组,此时将队头的合法单词和分隔符串移出队列。遇到非法单词,则直接清空队列。
流程图:
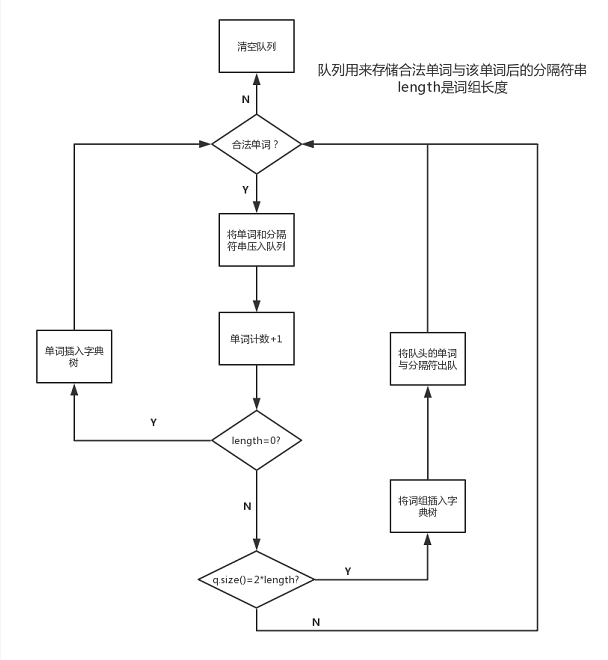
关键代码解释
struct FrequentWord
{
string word;
int weight;
friend bool operator < (FrequentWord a, FrequentWord b) //重载结构体小于号
{
if (a.weight == b.weight) //权重小的排在队头,权重相同时,字典序大的排在队头
return a.word<b.word;
else
return a.weight > b.weight;
}
}fqtWord;
priority_queue<FrequentWord> q_Word; //创建一个优先队列,用来保存词频高的单词
void triePreorderTraversal(trie root, int maxNumber) //树的先序遍历
{
if (root == NULL)
return;
if (root->weight != 0)
{
fqtWord.weight = root->weight;
fqtWord.word = root->word;
if (q_Word.size()<maxNumber) //维护maxNumber大小的优先队列
{
q_Word.push(fqtWord);
}
else
{
q_Word.push(fqtWord); //push一个新的结构体,队列会将权重小或字典序小的结构体排在队头
q_Word.pop(); //移出队列
}
}
for (int i = 0; i<ALPHABET_SIZE; i++)
{
triePreorderTraversal(root->children[i],maxNumber);
}
}
void FrequentWordCount(int maxNumber)
{
triePreorderTraversal(root_Words,maxNumber);
while (!q_Word.empty()) //保存优先队列内容,将数组倒序输出,即是所求词频
{
fqtWord = q_Word.top();
str_Words[d] = fqtWord.word;
ans_Words[d] = fqtWord.weight;
d++;
q_Word.pop();
}
//return root;
}
性能分析与改进
1.改进的思路
原先在判定n个单词是不是词组时,采用的是一次性抓取n个单词,如果这n个都是合法单词,则找到一个词组,否则前进一步,继续抓取n个单词,然后发现这样会造成重复判断同一个单词多次,效率低下,因而改进了算法,维护一个n+n-1的队列(n为词组长度),按顺序检索文本,遇到合法单词,压入该单词和单词后的分隔符串,如果队列未满,则什么都不干,如果队列恰好满了,则找到一个词组,此时将队头的合法单词和分隔符串移出队列。遇到非法单词,则直接清空队列。这样保证每个单词至多只会判断一次,提高了效率。
2.展示性能分析图和程序中消耗最大的函数
如图所示。
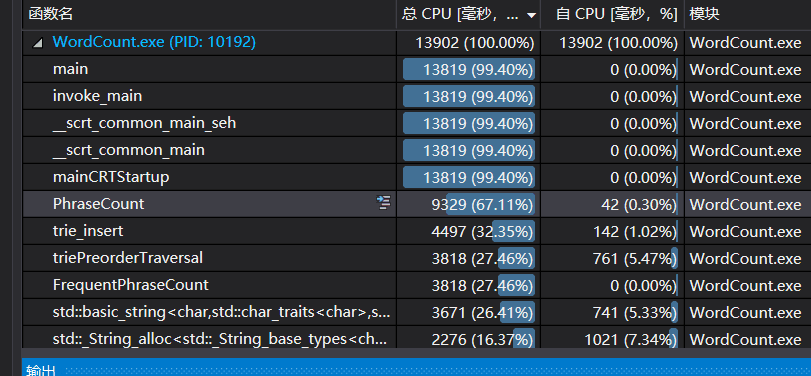
单元测试
对于WordCount给出如下10个单元测试,思路是尽可能为难编码者以更容易找到bug,其中Test1-Test7针对字符总数、单词总数、有效行数、部分异常进行测试,Test8、Test9针对单词词频进行测试,Test10针对词组词频进行测试。
| 测试序号 | 测试简介 |
|---|---|
| Test1 | 无合法单词测试 |
| Test2 | 空文件测试 |
| Test3 | 特殊符号测试 |
| Test4 | 合法单词判断测试 |
| Test5 | 文件不存在测试 |
| Test6 | 多个有效行测试 |
| Test7 | 较长的合法单词测试 |
| Test8 | 大小写相同测试 |
| Test9 | 单词词频结果测试 |
| Test10 | 词组词频结果测试 |
| 部分代码如图: | |
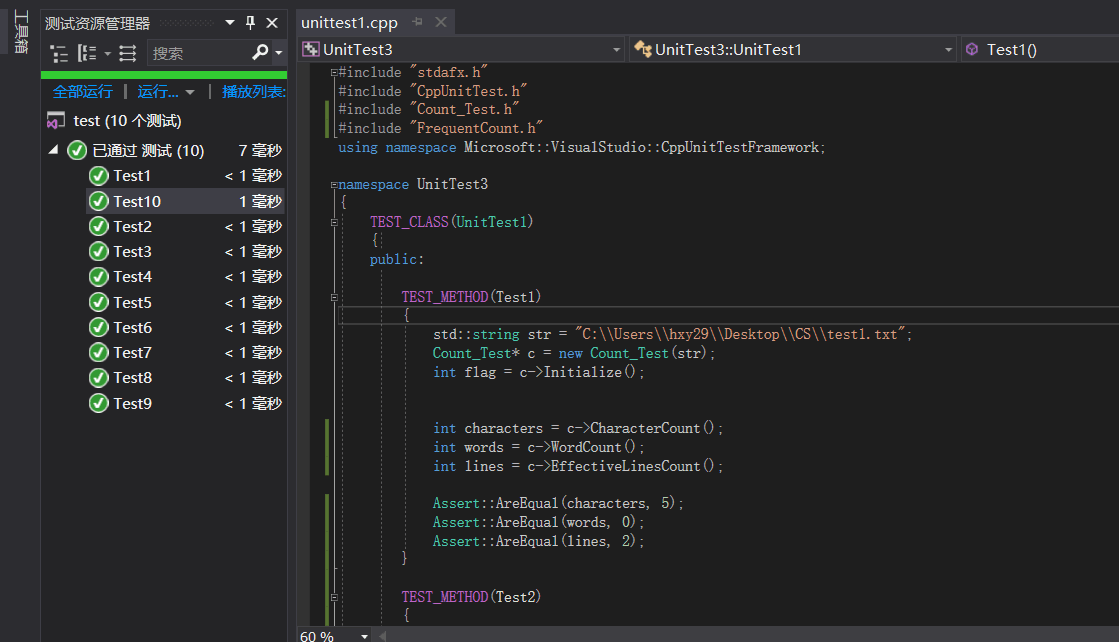 |
遇到的代码模块异常或结对困难及解决方法
爬虫方面:爬虫工具无法直接输出符合要求格式的txt,有点崩溃,一开始考虑使用某算法对txt进行排版,不过感觉有点复杂,后来选择先导出为excel,可以在excel上很方便地加入序号0到978,并在结尾加入无关紧要的后缀(比如“两个空行”),然后复制到word,把“两个空行”都替换为两个回车,如此便解决了空行问题。当然还有一些小的排版问题,不过都是可以用word容易解决的,在此不多赘述。即利用了excel和word的优势对采集的数据进行了处理。
代码方面:当遇到输入异常或文件异常时,继续运行会出错,因此选择输出相应的异常:
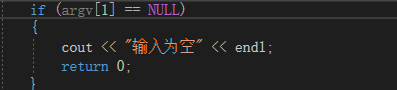


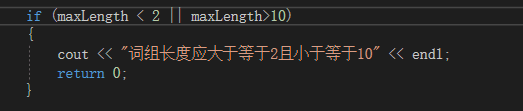

附加题设计与展示
在result.txt的基础上,额外爬取了作者和PDF链接。如下图所示:

评价你的队友
1.值得学习的地方
我的队友超强的,算法思路清晰明确,编码能力极佳,这些都是我所欠缺的。
2.需要改进的地方
太懒了,每次都在deadline前一刻才出炉完整代码。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 3 | 0 | 0 | 17 | 17 | Axure Rp;NABCD模型 |
| 4 | 1000 | 1000 | 23 | 40 | 八爪鱼采集器;字符统计 |

