
【Java】解析Java对XML的操作
目录结构:
1 什么是XML
XML(eXtensible markup language) 是一种可扩展的标记语言 ,即使可以自定义标签的语言。
2 解析XML
2.1 XML解析的方式
XML的解析方式有很多,光开源的就有十多种:如Xerces、JDOM、DOM4J、XOM、JiBX、KXML、XMLBeans、jConfig、XStream、XJR等。但是最常用的还是sax、dom、pull、dom4j。
DOM:(Document Object Model,就是文档对象模型),是W3C组织推荐的处理XML的一种方式。使用该方式解析XML文档,会把文档中的所有元素,按照其出现的层次关系,在内存中构造出树形结构。因此对内存的压力大,解析熟读慢,优点就是可以遍历和修改节点的内容。
SAX:(Simple API for XML) 是一种XML解析的替代方法。相比较于DOM,解析速度更快,内存的压力更小;缺点就是不能修改节点的内容。
PULL:pull和sax很相似,区别在于:pull读取xml文件后触发相应的事件调用方法返回的是数字,且pull可以在程序中控制,想解析到哪里就可以停止解析。 (SAX解析器的工作方式是自动将事件推入事件处理器进行处理,因此你不能控制事件的处理主动结束;而Pull解析器的工作方式为允许你的应用程序代码主动从解析器中获取事件,正因为是主动获取事件,因此可以在满足了需要的条件后不再获取事件,结束解析。pull是一个while循环,随时可以跳出,而sax不是,sax是只要解析了,就必须解析完成。)
DOM4J:虽然DOM4J代表了完全独立的开发结果,但最初,它是JDOM的一种智能分支。它合并了许多超出基本XML文档表示的功能,包括集成的XPath支持、XML Schema支持以及用于大文档或流化文档的基于事件的处理。它还提供了构建文档表示的选项,它通过DOM4J API和标准DOM接口具有并行访问功能。从2000下半年开始,它就一直处于开发之中。为支持所有这些功能,DOM4J使用接口和抽象基本类方法。DOM4J大量使用了API中的Collections类,但是在许多情况下,它还提供一些替代方法以允许更好的性能或更直接的编码方法。直接好处是,虽然DOM4J付出了更复杂的API的代价,但是它提供了比JDOM大得多的灵活性。 在添加灵活性、XPath集成和对大文档处理的目标时,DOM4J的目标与JDOM是一样的:针对Java开发者的易用性和直观操作。它还致力于成为比JDOM更完整的解决方案,实现在本质上处理所有Java/XML问题的目标。在完成该目标时,它比JDOM更少强调防止不正确的应用程序行为。DOM4J是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的Java软件都在使用DOM4J来读写XML,特别值得一提的是连Sun的JAXM也在用DOM4J,除此Hibernate框架也是用的DOM4J方式解析XML。
2.2 使用DOM解析XML
DOM的全称是Document Object Model,也即文档对象模型。在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序正是通过对这个对象模型的操作,来实现对XML文档数据的操作。通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,这种利用DOM接口的机制也被称作随机访问机制。
DOM接口提供了一种通过分层对象模型来访问XML文档信息的方式,这些分层对象模型依据XML的文档结构形成了一棵节点树。无论XML文档中所描述的是什么类型的信息,即便是制表数据、项目列表或一个文档,利用DOM所生成的模型都是节点树的形式。也就是说,DOM强制使用树模型来访问XML文档中的信息。由于XML本质上就是一种分层结构,所以这种描述方法是相当有效的。
DOM树所提供的随机访问方式给应用程序的开发带来了很大的灵活性,它可以任意地控制整个XML文档中的内容。然而,由于DOM分析器把整个XML文档转化成DOM树放在了内存中,因此,当文档比较大或者结构比较复杂时,对内存的需求就比较高。而且,对于结构复杂的树的遍历也是一项耗时的操作。所以,DOM分析器对机器性能的要求比较高,实现效率不十分理想。不过,由于DOM分析器所采用的树结构的思想与XML文档的结构相吻合,同时鉴于随机访问所带来的方便,因此,DOM分析器还是有很广泛的使用价值的。
优点:
1、形成了树结构,有助于更好的理解、掌握,且代码容易编写。
2、解析过程中,树结构保存在内存中,方便修改。
缺点:
1、由于文件是一次性读取,所以对内存的耗费比较大。
2、如果XML文件比较大,容易影响解析性能且可能会造成内存溢出。
以下是解析代码:


<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book id="1"> <name>冰与火之歌</name> <author>乔治马丁</author> <year>2014</year> <price>89</price> </book> <book id="2"> <name>安徒生童话</name> <year>2004</year> <price>77</price> <language>English</language> </book> </bookstore>
public class DOMTest { public static void main(String[] args) { //创建一个DocumentBuilderFactory的对象 DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); //创建一个DocumentBuilder的对象 try { //创建DocumentBuilder对象 DocumentBuilder db = dbf.newDocumentBuilder(); //通过DocumentBuilder对象的parser方法加载books.xml文件到当前项目下 Document document = db.parse("books.xml"); //获取所有book节点的集合 NodeList bookList = document.getElementsByTagName("book"); //通过nodelist的getLength()方法可以获取bookList的长度 System.out.println("一共有" + bookList.getLength() + "本书"); //遍历每一个book节点 for (int i = 0; i < bookList.getLength(); i++) { System.out.println("=================下面开始遍历第" + (i + 1) + "本书的内容================="); //通过 item(i)方法 获取一个book节点,nodelist的索引值从0开始 Node book = bookList.item(i); //获取book节点的所有属性集合 NamedNodeMap attrs = book.getAttributes(); System.out.println("第 " + (i + 1) + "本书共有" + attrs.getLength() + "个属性"); //遍历book的属性 for (int j = 0; j < attrs.getLength(); j++) { //通过item(index)方法获取book节点的某一个属性 Node attr = attrs.item(j); //获取属性名 System.out.print("属性名:" + attr.getNodeName()); //获取属性值 System.out.println("--属性值" + attr.getNodeValue()); } //解析book节点的子节点 NodeList childNodes = book.getChildNodes(); //遍历childNodes获取每个节点的节点名和节点值 System.out.println("第" + (i+1) + "本书共有" + childNodes.getLength() + "个子节点"); for (int k = 0; k < childNodes.getLength(); k++) { //区分出text类型的node以及element类型的node if (childNodes.item(k).getNodeType() == Node.ELEMENT_NODE) { //获取了element类型节点的节点名 System.out.print("第" + (k + 1) + "个节点的节点名:" + childNodes.item(k).getNodeName()); //获取了element类型节点的节点值 System.out.println("--节点值是:" + childNodes.item(k).getFirstChild().getNodeValue()); //System.out.println("--节点值是:" + childNodes.item(k).getTextContent()); } } System.out.println("======================结束遍历第" + (i + 1) + "本书的内容================="); } } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } } DOM
2.3 使用SAX解析XML
SAX的全称是Simple APIs for XML,也即XML简单应用程序接口。与DOM不同,SAX提供的访问模式是一种顺序模式,这是一种快速读写XML数据的方式。当使用SAX分析器对XML文档进行分析时,会触发一系列事件,并激活相应的事件处理函数,应用程序通过这些事件处理函数实现对XML文档的访问,因而SAX接口也被称作事件驱动接口。
优点:
1、采用事件驱动模式,对内存耗费比较小。
2、适用于只处理XML文件中的数据时。
缺点:
1、编码比较麻烦。
2、很难同时访问XML文件中的多处不同数据。
以下是解析代码:
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book id="1"> <name>冰与火之歌</name> <author>乔治马丁</author> <year>2014</year> <price>89</price> </book> <book id="2"> <name>安徒生童话</name> <year>2004</year> <price>77</price> <language>English</language> </book> </bookstore>
public class SAXTest { /** * @param args */ public static void main(String[] args) { //锟斤拷取一锟斤拷SAXParserFactory锟斤拷实锟斤拷 SAXParserFactory factory = SAXParserFactory.newInstance(); //通锟斤拷factory锟斤拷取SAXParser实锟斤拷 try { SAXParser parser = factory.newSAXParser(); //锟斤拷锟斤拷SAXParserHandler锟斤拷锟斤拷 SAXParserHandler handler = new SAXParserHandler(); parser.parse("books.xml", handler); System.out.println("~!~!~!共有" + handler.getBookList().size() + "本书"); for (Book book : handler.getBookList()) { System.out.println(book.getId()); System.out.println(book.getName()); System.out.println(book.getAuthor()); System.out.println(book.getYear()); System.out.println(book.getPrice()); System.out.println(book.getLanguage()); System.out.println("----finish----"); } } catch (ParserConfigurationException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (SAXException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } public class SAXParserHandler extends DefaultHandler { String value = null; Book book = null; private ArrayList<Book> bookList = new ArrayList<Book>(); public ArrayList<Book> getBookList() { return bookList; } int bookIndex = 0; /** * 用来标识解析开始 */ @Override public void startDocument() throws SAXException { // TODO Auto-generated method stub super.startDocument(); System.out.println("SAX解析开始"); } /** * 用来标识解析结束 */ @Override public void endDocument() throws SAXException { // TODO Auto-generated method stub super.endDocument(); System.out.println("SAX解析结束"); } /** * 解析xml元素 */ @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { //调用DefaultHandler类的startElement方法 super.startElement(uri, localName, qName, attributes); if (qName.equals("book")) { bookIndex++; //创建一个book对象 book = new Book(); //开始解析book元素的属性 System.out.println("======================开始遍历某一本书的内容================="); //不知道book元素下属性的名称以及个数,如何获取属性名以及属性值 int num = attributes.getLength(); for(int i = 0; i < num; i++){ System.out.print("book元素的第" + (i + 1) + "个属性名是:" + attributes.getQName(i)); System.out.println("---属性值是:" + attributes.getValue(i)); if (attributes.getQName(i).equals("id")) { book.setId(attributes.getValue(i)); } } } else if (!qName.equals("name") && !qName.equals("bookstore")) { System.out.print("节点名是:" + qName + "---"); } } @Override public void endElement(String uri, String localName, String qName) throws SAXException { //调用DefaultHandler类的endElement方法 super.endElement(uri, localName, qName); //判断是否针对一本书已经遍历结束 if (qName.equals("book")) { bookList.add(book); book = null; System.out.println("======================结束遍历某一本书的内容================="); } else if (qName.equals("name")) { book.setName(value); } else if (qName.equals("author")) { book.setAuthor(value); } else if (qName.equals("year")) { book.setYear(value); } else if (qName.equals("price")) { book.setPrice(value); } else if (qName.equals("language")) { book.setLanguage(value); } } @Override public void characters(char[] ch, int start, int length) throws SAXException { // TODO Auto-generated method stub super.characters(ch, start, length); value = new String(ch, start, length); if (!value.trim().equals("")) { System.out.println("节点值是:" + value); } } }
2.4 使用PULL解析XML
xml文件:
<?xml version="1.0" encoding="utf-8"?> <root> <student id="1" group="1"> <name>张三</name> <sex>男</sex> <age>18</age> <email>zhangsan@163.com</email> <birthday>1987-06-08</birthday> <memo>好学生</memo> </student> <student id="2" group="2"> <name>李四</name> <sex>女</sex> <age>18</age> <email>lisi@163.com</email> <birthday>1987-06-08</birthday> <memo>好学生</memo> </student> <student id="3" group="3"> <name>小王</name> <sex>男</sex> <age>18</age> <email>xiaowang@163.com</email> <birthday>1987-06-08</birthday> <memo>好学生</memo> </student> <student id="4" group="4"> <name>小张</name> <sex>男</sex> <age>18</age> <email>xiaozhang@163.com</email> <birthday>1987-06-08</birthday> <memo>好学生</memo> </student> <student id="5" group="5"> <name>小明</name> <sex>男</sex> <age>18</age> <email>xiaoming@163.com</email> <birthday>1987-06-08</birthday> <memo>好学生</memo> </student> </root>
bean文件:
public class Student {
private int id;
private int group;
private String name;
private String sex;
private int age;
private String email;
private String memo;
private String birthday;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getGroup() {
return group;
}
public void setGroup(int group) {
this.group = group;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getMemo() {
return memo;
}
public void setMemo(String memo) {
this.memo = memo;
}
public String getBirthday() {
return birthday;
}
public void setBirthday(String birthday) {
this.birthday = birthday;
}
}
测试文件:
import java.io.InputStream; import java.util.ArrayList; import java.util.List; import org.xmlpull.v1.XmlPullParser; import org.xmlpull.v1.XmlPullParserFactory; import android.app.Activity; import android.os.Bundle; import android.os.Handler; import android.os.Message; import android.view.ViewGroup.LayoutParams; import android.widget.LinearLayout; import android.widget.TextView; public class PullActivity extends Activity implements Runnable{ private TextView pullTextView ; private LinearLayout layout; private Handler handler=new Handler(){ public void handleMessage(android.os.Message msg) { List<Student> lists=(List<Student>) msg.obj; for(int i=0;i<lists.size();i++){ Student student=lists.get(i); StringBuffer sb=new StringBuffer(); sb.append(student.getId()+" ").append(student.getName()+" ") .append(student.getAge()+" ").append(student.getSex()+" ").append(student.getBirthday()+" ") .append(student.getEmail()+" ").append(student.getGroup()+" "); TextView txt=new TextView(getApplicationContext()); txt.setLayoutParams(new LayoutParams(LayoutParams.WRAP_CONTENT, LayoutParams.WRAP_CONTENT)); txt.setText(sb.toString()); layout.addView(txt); } }; }; @Override protected void onCreate(Bundle savedInstanceState) { // TODO Auto-generated method stub super.onCreate(savedInstanceState); setContentView(R.layout.pull); pullTextView=(TextView) this.findViewById(R.id.pullTextView); layout=(LinearLayout) this.findViewById(R.id.layout); new Thread(this).start(); } //pull解析xml public List<Student> pullParseXml(){ List<Student> lists=null; Student student=null; try { XmlPullParserFactory factory=XmlPullParserFactory.newInstance(); //获取XmlPullParser实例 XmlPullParser pullParser=factory.newPullParser(); InputStream in=this.getClass().getClassLoader().getResourceAsStream("student.xml"); pullParser.setInput(in, "UTF-8"); //开始 int eventType=pullParser.getEventType(); while(eventType!=XmlPullParser.END_DOCUMENT){ String nodeName=pullParser.getName(); switch (eventType) { //文档开始 case XmlPullParser.START_DOCUMENT: lists=new ArrayList<Student>(); break; //开始节点 case XmlPullParser.START_TAG: if("student".equals(nodeName)){ student=new Student(); student.setId(Integer.parseInt(pullParser.getAttributeValue(0))); student.setGroup(Integer.parseInt(pullParser.getAttributeValue(1))); }else if("name".equals(nodeName)){ student.setName(pullParser.nextText()); }else if("sex".equals(nodeName)){ student.setSex(pullParser.nextText()); }else if("age".equals(nodeName)){ student.setAge(Integer.parseInt(pullParser.nextText())); }else if("email".equals(nodeName)){ student.setEmail(pullParser.nextText()); }else if("birthday".equals(nodeName)){ student.setBirthday(pullParser.nextText()); }else if("memo".equals(nodeName)){ student.setMemo(pullParser.nextText()); } break; //结束节点 case XmlPullParser.END_TAG: if("student".equals(nodeName)){ lists.add(student); student=null; } break; default: break; } // 手动的触发下一个事件 eventType=pullParser.next(); } } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } return lists; } @Override public void run() { // TODO Auto-generated method stub List<Student> lists=pullParseXml(); Message msg=handler.obtainMessage(); msg.obj=lists; handler.sendMessage(msg); } }
2.5 使用dom4j解析XML
在使用dom4j解析XML之前需要导入相关的工具包,比如笔者的: dom4j-1.6.1.jar 包
2.5.1 dom4j的API
//创建SAXReader,是dom4j包提供的解析器 SAXReader reader=new SAXReader(); //读取指定的文件 Document doc=reader.read(new File(filename)); Document Document getRootElement() 用于获取根元素 Element Element element(String name) 获取元素下指定名称的子元素 List<Element> elements() 获取元素下所有的子元素 String getName() 获取元素名 String getText() 获取元素文本内容 String elementText(String name) 获取子元素文本内容 Attribute attribute(String) 获取元素的属性 String attributeValue(String name) 获取元素的属性值 Attribute String getName() 获取属性的名字 String getValue() 获取属性的值
2.5.2 打印一个XML文件的全部内容
pricties.xml文件直接位于项目下
<?xml version="1.0" encoding="utf-8" ?> <books id="a"> <book id="b"> <name id="c_1" name="c_2">三国演绎</name> <author id="d_1" name="d_2" >罗贯中</author> <price id="e">58.8</price> </book> <book id="f_1" name="f_2"> <name id="g">水浒传</name> <author id="h">施耐庵</author> <price id="i">49.8</price> </book> <book id="j_1" name="j_2"> <name id="k">西游记</name> <author id="l">吴承恩</author> <price id="m">100.1</price> <order>1</order> </book> </books>
import java.io.File; import java.util.List; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; public class ParseXML { public static void main(String[] args) { //创建SAXReader对象 SAXReader saxr=new SAXReader(); Document docu=null; try{ //读取指定的文件,相对于项目路径 docu=saxr.read(new File("pricties.xml")); //获得元素的文件的根节点 Element e=docu.getRootElement(); searchAllElement(e); }catch(Exception e){ e.printStackTrace(); } } public static void searchAllElement(Element e){ //获得当前元素下的所有子元素,并存储到集合中 List<Element> elements=e.elements(); System.out.print("<"+e.getName());//打印开始标记 List<Attribute> atrs=e.attributes();//打印该标记下的所有属性 for(Attribute att:atrs){ System.out.print(" "+att.getName()+"=\""+att.getValue()+"\""); } System.out.println(">"); //如果集合的大小为0,表示该集合下没有子元素了 if(elements.size()==0){ System.out.println(e.getText());//打印文本信息 System.out.println("</"+e.getName()+">");//打印结束标记 return;//退出当前层方法 } //递归每一个子元素 for(Element ele:elements){ searchAllElement(ele); } System.out.println("</"+e.getName()+">");//打印结束标记 } }
2.6 在dom4j中应用XPath解析XML
首先需要在dom4j基础上引入相应的jar包,比如读者的: jaxen-1.1-beta-6.jar
2.6.1 XPath的API
Document List<Node> selectNodes(String xpath) Node selectSingleNode(String xpath)
2.6.2 XPath的路径表达式
2.6.2.1 XPath的路径表达式规则

2.6.2.2 XPath的路径表达式应用案例
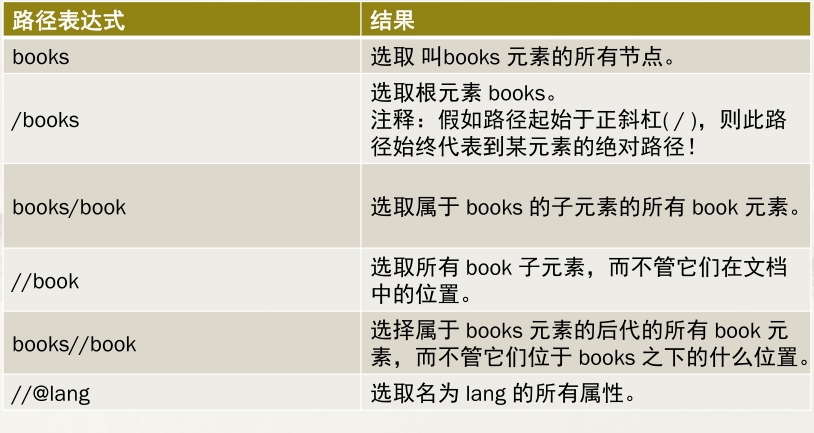
2.6.3 通配符
2.6.3.1 通配符规则

2.6.3.2 通配符应用案例

2.6.4 谓语
2.6.4.1 谓语规则
谓语是用来查找某个特定的节点或是包含某个指定的值的节点
谓语被嵌在方括号中
2.6.4.2 谓语应用案例

3 java写XML文件
3.1 将一个带有书籍信息的List集合解析为XML文件
package com.xdl.xml; public class Book { private String name; private String author; private String price; public Book() { super(); } public Book(String name, String author, String price) { super(); setName(name); setAuthor(author); setPrice(price); } /** * @return the name */ public String getName() { return name; } /** * @param name the name to set */ public void setName(String name) { this.name = name; } /** * @return the author */ public String getAuthor() { return author; } /** * @param author the author to set */ public void setAuthor(String author) { this.author = author; } /** * @return the price */ public String getPrice() { return price; } /** * @param price the price to set */ public void setPrice(String price) { this.price = price; } }
package com.xdl.xml; import java.io.File; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.dom4j.Document; import org.dom4j.DocumentHelper; import org.dom4j.Element; import org.dom4j.io.XMLWriter; public class WriteXML { public static void main(String[] args) { //创建一个Book集合用于存储书籍信息 List<Book> list_books=new ArrayList<Book>(); //插入书籍信息 for(int i=0;i<6;i++){ Book book=new Book("jame"+i,"author"+i,""+i); list_books.add(book); } //创建一个文档对象 Document doc=DocumentHelper.createDocument(); //创建一个根节点 Element books=DocumentHelper.createElement("books"); //获得书籍集合的大小 int size=list_books.size(); for(int i=0;i<size;i++){ //创建一个book节点 Element book=books.addElement("book"); //创建一个name节点 Element name=book.addElement("name"); //创建一个author节点 Element author=book.addElement("author"); //创建一个price节点 Element price=book.addElement("price"); name.setText(list_books.get(i).getName()); author.setText(list_books.get(i).getAuthor()); price.setText(list_books.get(i).getPrice()); } //设置文档根节点 doc.setRootElement(books); try { //如果文件不存在,会自动创建 FileOutputStream fos = new FileOutputStream(new File("books.xml")); XMLWriter xmlw = new XMLWriter(fos); xmlw.write(doc); xmlw.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }
4 Schema和DTD的区别
Schema是对XML文档结构的定义和描述,其主要的作用是用来约束XML文件,并验证XML文件有效性。DTD的作用是定义XML的合法构建模块,它使用一系列的合法元素来定义文档结构。它们之间的区别有下面几点:
1、Schema本身也是XML文档,DTD定义跟XML没有什么关系,Schema在理解和实际应用有很多的好处。
2、DTD文档的结构是“平铺型”的,如果定义复杂的XML文档,很难把握各元素之间的嵌套关系;Schema文档结构性强,各元素之间的嵌套关系非常直观。
3、DTD只能指定元素含有文本,不能定义元素文本的具体类型,如字符型、整型、日期型、自定义类型等。Schema在这方面比DTD强大。
4、Schema支持元素节点顺序的描述,DTD没有提供无序情况的描述,要定义无序必需穷举排列的所有情况。Schema可以利用xs:all来表示无序的情况。
5、对命名空间的支持。DTD无法利用XML的命名空间,Schema很好满足命名空间。并且,Schema还提供了include和import两种引用命名空间的方法。

