
软件质量与测试第4周小组作业:WordCount优化
GitHub项目地址
https://github.com/Guchencc/WordCounter
组长:
陈佳文:负责词频统计模块与其他模块
组员:
屈佳烨:负责排序模块
苑子尚:负责输出模块
李一凡:负责输入模块
PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
||
|
· Estimate |
· 估计这个任务需要多少时间 |
20 | 20 |
|
Development |
开发 |
||
|
· Analysis |
· 需求分析 (包括学习新技术) |
180 | 200 |
|
· Design Spec |
· 生成设计文档 |
30 | 30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 | 30 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 | 20 |
|
· Design |
· 具体设计 |
120 | 130 |
|
· Coding |
· 具体编码 |
120 | 150 |
|
· Code Review |
· 代码复审 |
60 | 60 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 | 60 |
|
Reporting |
报告 |
||
|
· Test Report |
· 测试报告 |
60 | 60 |
|
· Size Measurement |
· 计算工作量 |
20 | 10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 | 10 |
|
合计 |
750 | 780 |
词频统计模块设计与实现
该模块由三个函数组成:
ArrayList<WordInfo> countFrequency(String filename)
功能:接受文本文件名,读取文本内容,进行词频统计,并将结果存入动态数组中返回。
public static ArrayList<WordInfo> countFrequency(String filename) {
ArrayList<WordInfo> wordInfos=new ArrayList<>();
Pattern pattern=Pattern.compile("[a-zA-Z]+-?[a-zA-Z]*"); //定义单词的正则表达式
String text=Main.readFile(filename); //调用readFile()读取文本内容赋值给text
if (text==null){
return null;
}
Matcher matcher=pattern.matcher(text); //利用之前定义的单词正则表达式匹配text中的单词
String word;
int index;
WordInfo wordInfo;
while(matcher.find()) { //如果匹配到单词则进入循环处理
word=matcher.group().toLowerCase(); //将匹配到的单词赋值给word
if (word.endsWith("-")) //如果匹配到“单词-”情况,则去除符号“-”
word=word.substring(0,word.length()-1);
if ((index=Main.hasWord(wordInfos,word))!=-1) { //如果动态数组wordInfos中已经有该单词,则将频数加一
wordInfos.get(index).setFrequency(wordInfos.get(index).getFrequency()+1);
}else{ //如果动态数组wordInfos中无该单词,则将该单词加入动态数组
wordInfo=new WordInfo(word, 1);
wordInfos.add(wordInfo);
}
}
return wordInfos;
}
原理:
Pattern类用于创建一个正则表达式,也可以说创建一个匹配模式,它的构造方法是私有的,不可以直接创建,但可以通过Pattern.complie(String regex)简单工厂方法创建一个正则表达式,轮到Matcher类登场了,Pattern.matcher(CharSequence input)返回一个Matcher对象.
find()对字符串进行匹配,匹配到的字符串可以在任何位置. group()返回匹配到的子字符串
利用Pattern类创建定义单词的正则表达式,在本程序中即
Pattern pattern=Pattern.compile("[a-zA-Z]+-?[a-zA-Z]*");
调用readFile(String filename)读取文本文件内容,将文本赋值给字符串text,再用Pattern类产生Matcher类的实例,即
String text=Main.readFile(filename);
Matcher matcher=pattern.matcher(text);
matcher.find()对字符串进行匹配,若匹配到符合正则表达式的单词则返回true进入循环。
while(matcher.find()) {
......
}
如果匹配的单词类型是“单词-”,则将单词中的“-”符号去掉。
if (word.endsWith("-"))
word=word.substring(0,word.length()-1);
如果当前匹配到的单词,动态数组wordInfos中已经存在,则将该单词频数加一,否则将该单词加入动态数组。
if ((index=Main.hasWord(wordInfos,word))!=-1) {
wordInfos.get(index).setFrequency(wordInfos.get(index).getFrequency()+1);
}else{
wordInfo=new WordInfo(word, 1);
wordInfos.add(wordInfo);
}
int hasWord(ArrayList<WordInfo> wordInfos, String word)
功能:接受动态数组wordInfos和字符串word,判断word是否存在于wordInfos中,若存在则返回其具体位置,否则返回-1。
public static int hasWord(ArrayList<WordInfo> wordInfos, String word) { //判断word是否存在于动态数组wordInfos中,若存在则返回位置,负责返回-1
for (WordInfo wordInfo:wordInfos){
if (wordInfo.getWord().equals(word.trim().toLowerCase()))
return wordInfos.indexOf(wordInfo);
}
return -1;
}
原理:遍历动态数组,寻找word,若存在则返回其index,否则返回-1。
String readFile(String filename)
功能:接受文本文件名,读取该文本内容,并将其以字符串类型返回。
public static String readFile(String filename) { //读取filename文本文件
File file=new File(filename);
StringBuilder sb = new StringBuilder();
try {
FileReader reader = new FileReader(file);
BufferedReader br = new BufferedReader(reader);
String str;
while ((str = br.readLine()) != null) { //逐行读取文件内容,不读取换行符和末尾的空格
sb.append(str + "\n");
}
br.close();
return sb.toString();
}catch (IOException e){
System.out.println("读取文件失败!");
}
return null;
}
原理:逐行读取文件内容,不读取换行符和末尾的空格。将各行链接起来组成一个字符串。
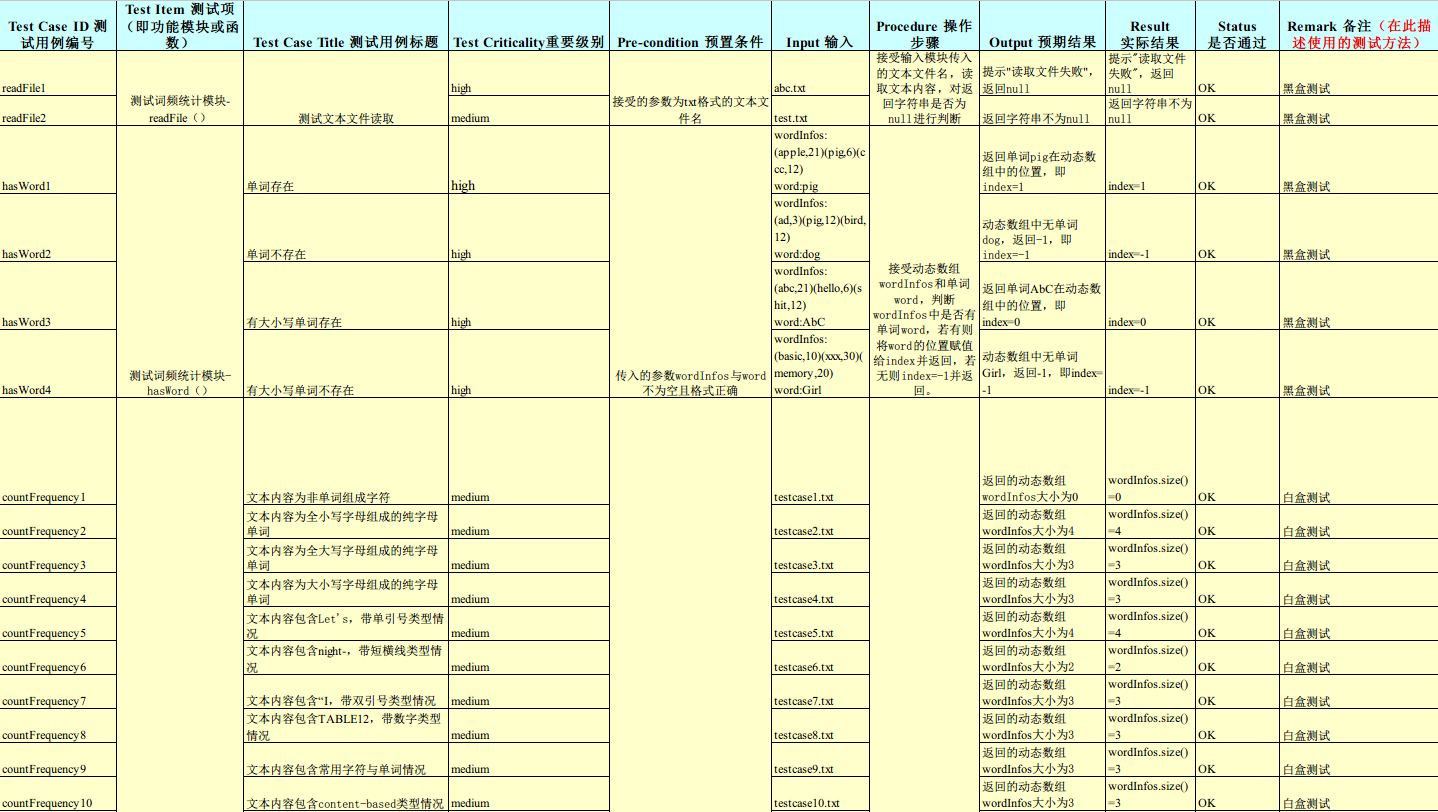
测试用例的设计
保证设计的测试用例应至少覆盖函数中所有的可执行语句,同时主要针对特殊字符、数字、连字符、大小写字母等 的出现设计测试用例。

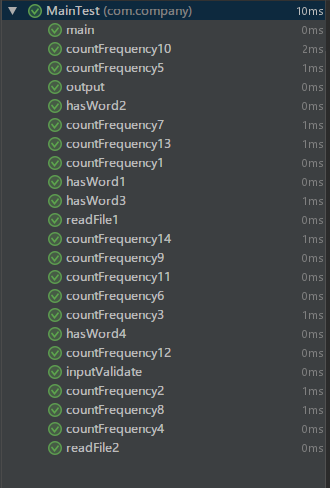
单元测试结果
下图为单元测试截图,由图可知,该模块通过了所有测试用例,且时间很短,因此该模块测试质量还是很上乘的。
小组贡献
作为此次小组项目的组长,负责团队开发管理与GitHub项目的管理,并且承担了大部分的代码编辑工作。故给自己的小组贡献分为0.4。
经讨论组员评分情况如下:
组长:
陈佳文 0.40
组员:
屈佳烨:0.35
苑子尚:0.15
李仪凡:0.10

