
Python学习笔记(1)
节选自: http://www.pythondoc.com/pythontutorial3
1. 多重赋值
变量赋值前:
- 右边首先完成计算
- 右边的表达式从左到右计算
如:
a, b = 0 , 1 // a = 0, b =1 a, b = b, a + b // a = 1, b = 1
2. 迭代过程中修改迭代序列
在迭代过程中修改迭代序列不安全(只有在使用链表这样的可变序列时才会有这样的情况)。如果你想要修改你迭代的序列(例如,复制选择项),你可以迭代它的复本。
使用切割标识就可以很方便的做到这一点:
words = ['1', 2, 3, '4']
for item in words[:]:
if item == 2:
words.pop(words.index(item))
print (words)
注意:
- 列表pop -- list.pop(index)
- 字典pop -- dict.pop(key[, default])
3. 循环中的else字句
循环可以有一个 else 子句;它在循环迭代完整个列表(对于 for )或执行条件为 false (对于 while)时执行,但循环被 break 中止的情况下不会执行。
以下搜索素数的示例程序演示了这个子句:
>>> for n in range(2, 10): ... for x in range(2, n): ... if n % x == 0: ... print(n, 'equals', x, '*', n//x) ... break ... else: ... # loop fell through without finding a factor ... print(n, 'is a prime number') ... 2 is a prime number 3 is a prime number 4 equals 2 * 2 5 is a prime number 6 equals 2 * 3 7 is a prime number 8 equals 2 * 4 9 equals 3 * 3
4. 函数默认赋值
默认值只被赋值一次。这使得当默认值是可变对象时会有所不同,比如列表、字典或者大多数类的实例。
例如,下面的函数在后续调用过程中会累积(前面)传给它的参数:
def f(a, L=[]):
L.append(a)
return L
print(f(1))
print(f(2))
print(f(3))
结果:
[1] [1, 2] [1, 2, 3]
5. 函数参数
定义:
def func2(must, *arguments, op1=1, op2=2, op3=3, **keywords):
print ("--")
print (must, op1, op2, op3)
print ("arguments:")
for arg in arguments:
print (arg)
print ("keywords:")
for kw in keywords.keys():
print (kw, ":", keywords[kw])
func2(1)
func2(1, 2)
func2(1, op2 = 0)
func2(1, 7, op3 = 4)
func2(op2 = 5, must = 8)
func2(1, 2, 3, 4, 1, 2, a=1, b=2)
func2(1, 7, op2=3, op3=4)
func2(1, 7, op2=4, a=1, b=2)
运行结果:
-- 1 1 2 3 arguments: keywords: -- 1 1 2 3 arguments: 2 keywords: -- 1 1 0 3 arguments: keywords: -- 1 1 2 4 arguments: 7 keywords: -- 8 1 5 3 arguments: keywords: -- 1 1 2 3 arguments: 2 3 4 1 2 keywords: a : 1 b : 2 -- 1 1 3 4 arguments: 7 keywords: -- 1 1 4 3 arguments: 7 keywords: a : 1 b : 2
5.1 位置参数
调用函数时根据函数定义的参数位置来传递参数
5.2 关键字参数
用于函数调用,通过“键-值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。
特别注意:有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序的
5.3 默认参数
用于定义函数,为参数提供默认值,调用函数时可传可不传该默认参数的值
特别注意:所有位置参数必须出现在默认参数前,包括函数定义和调用
5.4 可变参数
定义函数时,有时候我们不确定调用的时候会传递多少个参数(不传参也可以)。此时,可用包裹(packing)位置参数(参数列表),或者包裹关键字参数(参数字典),来进行参数传递,会显得非常方便。
5.4.1 参数列表
参数列表属于位置参数,只有value,没有key
如上例中的*arguments
5.4.2 参数字典
参数字典属于关键字参数,key-value形式
如上例中的**keywords
综上,定义:
def func3(must, op1=1, op2=2, op3=3, *arguments, **keywords):
print (must, op1, op2, op3)
for arg in arguments:
print (arg)
for kw in keywords.keys():
print (kw, ":", keywords[kw])
虽然能通过编译,但定义有严重问题的,其中,*arguments是属于位置参数,而op1,op2,op3是关键字参数,位置参数应该在关键字参数之前。
例如调用:
func(1, op1=1, op2=2, op3=3, 1, 2)
会报错:
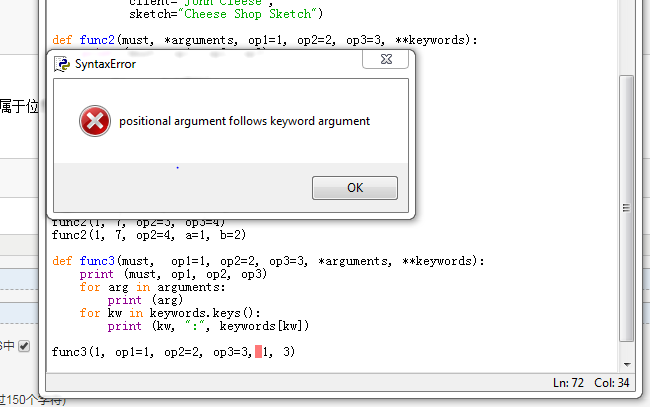
应该定义为:
def func(must, *arguments, op1=1, op2=2, op3=3, **keywords):
print (must, op1, op2, op3)
for arg in arguments:
print (arg)
for kw in keywords.keys():
print (kw, ":", keywords[kw])
6. Lambda 形式
通过 lambda 关键字,可以创建短小的匿名函数。
语法: lambda argumens: expression
1. Lambda 形式可以用于任何需要的函数对象。
2. 出于语法限制,它们只能有一个单独的表达式。
3. 语义上讲,它们只是普通函数定义中的一个语法技巧。
4. 类似于嵌套函数定义,lambda 形式可以从外部作用域引用变量
例如:
def make_increment(n):
return lambda x: x+n
等效于:
def make_increment(n):
def anonymous(x):
return x + n
return anonymous
7. 列表推导式
列表推导式为从序列中创建列表提供了一个简单的方法。普通的应用程式通过将一些操作应用于序列的每个成员并通过返回的元素创建列表,或者通过满足特定条件的元素创建子序列。
假设我们创建一个 squares 列表:
squares = [x ** 2 for x in range(10)]
等效于:
squares = []
for x in range(10):
squares.append(x **2)
或者:
squares = list(map(lambda x: x**2, range(10)))
列表推导式由包含一个表达式的括号组成,表达式后面跟随一个 for 子句,之后可以有零或多个 for 或 if 子句。
结果是一个列表,由表达式依据其后面的 for 和 if 子句上下文计算而来的结果构成。
更多的例子:
>>> keys = ['a', 'b', 'c']
>>> values = [1, 2, 3, 4]
>>> keys
['a', 'b', 'c']
>>> values
[1, 2, 3, 4]
>>> s = [{k: v} for k,v in zip(keys, values)]
>>> s
[{'a': 1}, {'b': 2}, {'c': 3}]
嵌套的列表推导式:
列表解析中的第一个表达式可以是任何表达式,包括列表解析。
考虑下面由三个长度为 4 的列表组成的 3x4 矩阵:
matrix = [
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
]
现在,如果你想交换行和列,可以用嵌套的列表推导式:
>>> [[row[i] for row in matrix] for i in range(4)] [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
像前面看到的,嵌套的列表推导式是对 for 后面的内容进行求值,所以上例就等价于:
>>> transposed = [] >>> for i in range(4): ... transposed.append([row[i] for row in matrix]) ... >>> transposed [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
反过来说,如下也是一样的:
>>> transposed = [] >>> for i in range(4): ... # the following 3 lines implement the nested listcomp ... transposed_row = [] ... for row in matrix: ... transposed_row.append(row[i]) ... transposed.append(transposed_row) ... >>> transposed [[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]
在实际中,你应该更喜欢使用内置函数组成复杂流程语句。对此种情况 zip() 函数将会做的更好:
>>> list(zip(*matrix)) [(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)]
其他推导式
与列表推导式类似,其他集合类型也有推导式
# list comprehension
>>> [(x, y) for x in range(3) for y in range(3) if x != y]
[(0, 1), (0, 2), (1, 0), (1, 2), (2, 0), (2, 1)] # ordered
# set comprehension
>>> {(x, y) for x in range(3) for y in range(3) if x != y}
{(0, 1), (1, 2), (2, 1), (2, 0), (1, 0), (0, 2)} # unordered
# dict comprehension
>>> {x: y for x in range(3) for y in range(3) if x != y}
{0: 2, 1: 2, 2: 1} # one key keeped if keys duplicate
# tuple no comprehension
>>> ((x, y) for x in range(3) for y in range(3) if x != y)
<generator object <genexpr> at 0x0000000002F67F48> # generator
特别注意:
1. set是无序的
2. dict的key是唯一的,重复赋值只会保留最后一次赋值
3. tuple没有推导式,但可以用如下代码:
>>> tuple((x, y) for x in range(3) for y in range(3) if x != y) ((0, 1), (0, 2), (1, 0), (1, 2), (2, 0), (2, 1))
