

python——线程与多线程基础
我们之前已经初步了解了进程、线程与协程的概念,现在就来看看python的线程。下面说的都是一个进程里的故事了,暂时忘记进程和协程,先来看一个进程中的线程和多线程。这篇博客将要讲一些单线程与多线程的基础,它们在执行中对cpu资源的分配,帮助还不了解多线程的小伙伴一招get写多线程代码的技能。已经了解的请自行跳过。
单线程

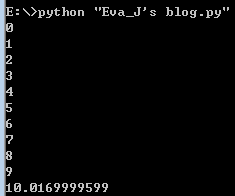
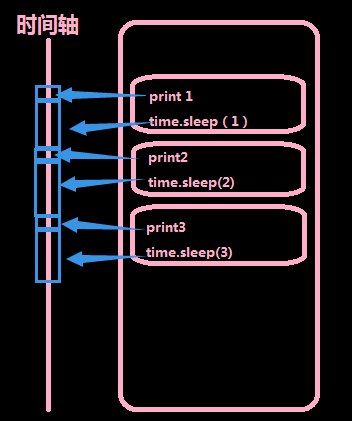
从上面的图中我们可以看出,这段代码执行了10秒多,这就是一段单单线程的一条道走到黑的代码,它们顺序执行,该sleep的时候就sleep,该print的时候就print。右边的图是python执行的时候所占用的cpu的情况。
多线程
但是,我们是无法忍受一共打印10个数,每个数之间还要sleep这个事实的,所以又出现了多线程,当一个线程sleeping的时候,cpu就去执行其他线程的内容了。例如:

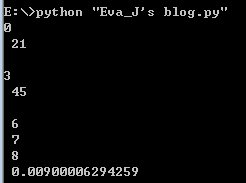
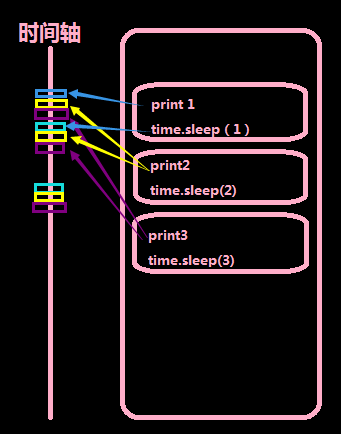
看上面的图,我们引入了threading模块,并使用Thread类实现了一个多线程的程序,这时,我们仅仅用了9毫秒的时间,就执行完了10个数字的打印。是因为我们将print这件事情,放到了多个线程中去执行,那么这几个线程就几乎同步去做事,表面上线程都在执行完打印之后进入了休眠状态,但是一个线程休息的间隙,cpu就可以去完成其他线程的任务了。看最右侧的时间图,我放大了时间轴,其实每一个颜色块就代表了他们在cpu中执行时占用的时间,它们之间的差别很小,大概是秒的-3次方这个数量级,足矣被我们忽略了,所以我们感觉他们是同时执行的,当线程执行sleep的时候,他们也几乎会同时开始计时,同时结束。我们看中间的结果图,打印的并不像上面单线程那么漂亮,这也是各个线程抢占输出资源的结果。于是我们知道了,多线程的执行几乎是同步的,并且共享内存,但是它会产生资源抢占的情况。
get一段多线程代码
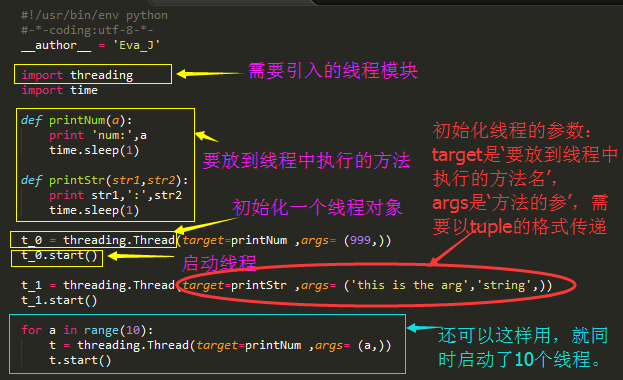
看上面的图,就是这样,其实开启一个线程非常简单,只需要引入一个threading包,然后初始化一个Thread的对象,将方法名和其参数作为Thread类初始化的参数传进去,再使用Thread的对象调用start方法,我们就启动了一个新的线程。我们可以在自己的程序中按照需求起一个或很多个线程。就像上面那样。


1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 __author__ = 'Eva_J' 4 5 import threading 6 import time 7 8 def printNum(a): 9 print 'num:',a 10 time.sleep(1) 11 12 def printStr(str1,str2): 13 print str1,':',str2 14 time.sleep(1) 15 16 t_0 = threading.Thread(target=printNum ,args= (999,)) 17 t_0.start() 18 19 t_1 = threading.Thread(target=printStr ,args= ('this is the arg','string',)) 20 t_1.start() 21 22 for a in range(10): 23 t = threading.Thread(target=printNum ,args= (a,)) 24 t.start()
参考文献:
python线程指南:http://www.cnblogs.com/huxi/archive/2010/06/26/1765808.html
武老师内部专享文章:python线程、进程和协程:http://www.cnblogs.com/wupeiqi/articles/5040827.html

