shell脚本--grep以及正则表达式
grep命令
1、grep程序:Linux三剑客--grep、awk、sed
2、GrepL:文本 行过滤工具
sed:文本 行编辑器
Awk:报告生成器(做文本输出格式化)
3、grep包含三个命令:grep、egrep、fgrep,它们是用来进行 行模式(pattern)匹配的
Egrep=grep -E //使用扩展的正则表达式进行匹配
fgrep=fast grep //只使用文件通配符进行匹配
*grep默认使用正则表达式进行文本匹配
4、grep命令的用法:grep [option].....PATTERN [filename]
5、Grep的常见参数:-E(支持使用扩展的正则表达式,regexp(正则表达式))
-P(使用per语言的正则表达式引擎进行搜索(每一种语言的正则表达式引擎都不相同,甚至sed grep awk使用的正则表达式引擎也不相同))
-i(忽略大小写)、-v(进行反选)、-n(显示行号)、--color(显示着色)
-o(仅仅输出匹配的内容,默认输出的是匹配到的行)
PATTERN---正则表达式
1、作用:通过一些特殊字符,来表示一类字符内容,然后交给前面的命令来执行,如果使用特殊字符本身含义,就需要进行\进行转义;
2、字符匹配:.(代表任意一个字符,相当于?)、[ ](匹配范围内的一个字符)、 [^](范围外的一个字符)
字符类:[:digit:](数字) [:alnum:](数字和大小写字母) [:alpha:](大小写字母) [:lower:](小写字母)
[:upper:] (大写字母) [:space:](空格) [:punct:](特殊符号)
3、次数匹配:*(匹配前面的字符0次到n(无数)次)
?(匹配前面的字符0次到1次)
+(匹配前面的字符1次到n次)
\{m\}(匹配前面的一个字符m次)
\{m,n\}(匹配前面的字符m到n(固定的数值)次)
\{m,\}(匹配前面的字符至少m次)
4、位置锚定:^(锚定行首)
$(锚定行尾)
\b(锚定词首和锚定词尾)
\>(锚定词尾)
\<(锚定词首)
5、分组特性:默认情况下,Linux系统会分组指定变量,变量的表示形式\1\2\3..
分组字符:分组字符:\(\)(示例:\(abc\)*-----匹配0到n次的abc)
if语句:

在某些条件下,如果不满足该条件,我们必须手动退出程序,否则后面的代码无法执行;
指定输出码:exit 0、exit 1
在程序错误输出的时候,可以用来判断程序错误的地方
Exit退出码,后面的数值是可以自己定义的,一般正确为0,而错误则为非0即可。
练习:
1、显示/proc/meminfo文件中以大小s开头的行
|
1
|
grep -i "^s" /proc/meminfo |
2、显示/etc/passwd文件中不以/bin/bash结尾的行
|
1
|
grep -v "/bin/bash$" /etc/passwd |
3、显示/etc/passwd文件中UID号最大的用户的用户名
|
1
|
sort -n -t: -k3 /etc/passwd |tail -1 |cut -d: -f1 |
4、如果用户root存在,显示其默认的shell程序
方法一:
|
1
|
grep "^root\>" /etc/passwd &> /dev/null && grep "^root\>" /etc/passwd |cut -d: -f7 |
方法二:
|
1
|
id root &> /dev/null && grep "^root\>" /etc/passwd |cut -d: -f7 |
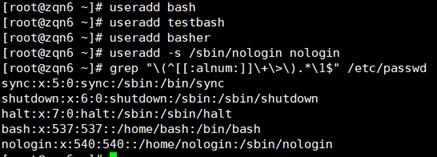
5、找出/etc/passwd中的两位或三位数
|
1
|
grep -w "[0-9]\{2,3\}" /etc/passwd |
6、显示/etc/rc.d/rc.sysinit文件中,至少以一个空白字符开头的切后面为非空白字符的行
|
1
|
grep "^[[:space:]]\+.*[^[:space:]]$" /etc/rc.d/rc.sysinit |
7、找出”netstat -tan”命令的结果中,以”LISTEN”后跟0、1或多个空白
|
1
|
netstat -tan | grep "LISTEN[[:space:]]*$" |