洗礼灵魂,修炼python(62)--爬虫篇—模仿游戏
前言
《模仿游戏》这个电影相信如果你是搞IT的,即使没看过也听过吧?电影讲述了计算机之父——阿兰-图灵的一些在当时来讲算是计算机史里的里程碑事迹了。而【模仿游戏】这个名字咋一看,貌似和电影没啥关系,原名叫The Imitation Game,翻译过来就是模仿游戏,最开始其实是图灵的计算机相关测试,大概意思是如果计算机多次工作与人类似的工作,那么它可以智能的模仿人类的处理事务的方式来进行工作,在那个时代算是闻所未闻的,就像我现在跟正在读这篇博文的读者说“我其实很帅”一样,反正是没多少人信的对吧?好的,关于电影里的或者阿兰-图灵的话题,暂且不提,不深究这些,我只说字面意思上的模仿游戏
正题
前面学了那么多模块啊,什么方法属性,请求啥的,相信你不说精通,至少你可以爬一个网站了吧?
其实,我想说,爬虫真的不仅限于此,之前我提过,访问一个网站时,网站服务器可以看到客户端访问信息,以及以什么方式访问,如果是程序访问,原则是不行的,所以会被拒绝访问,因此需要修改参数来隐藏,我们已经学过的就是修改报文头部信息,模仿成浏览器式的访问,但这个还是有个问题,由于使用同一个IP多次访问,网站服务器不管user-agent是否是程序还是浏览器人为访问,都直接拒绝访问,或者显示验证页,让你输入验证码才行,网络爬虫自然是无法输入验证码的,输入验证码的相信你都知道吧,其实现在很多网站都有验证码才能过,这种就是简单防爬虫手段。
那么解决方法是什么呢?
有三个:
1.设置延迟,尽量的模仿人为访问的速度
2.设置代理IP
3.写高级爬虫程序过验证码(因为涉及更多扩展知识,这里暂且不提)
有了前两个方法,你写出来的爬虫程序就基本算是进阶级爬虫了,有了第三个方法,那么就是高级爬虫了。
本篇博文就说说前两个方法:
第一个方法就是导入time模块,然后在觉得该停顿的地方停顿对吧?time模块前面已经提过了,忘记了的,自己会去看吧。
具体怎么实行呢?好的,这里有一个小项目,写一个翻译程序,不管你用百度翻译,还是有道翻译,还是谷歌翻译,还是什么翻译,写一个简单的翻译程序出来,自己动手搞一个看看,前提是你必须稍微的会看一点点html代码,不然确实很吃力的,不需要会很多,只要能看懂个大概就行,不用去恶补html语法标签啥的
(请确保你已经思考过了,再看下面的。)
运行环境是python3
import urllib.request
import urllib.parse
import json,time
content=0
head={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
while True:
content=input("请输入需要翻译的内容(或者输入quit退出):")
if content!='quit':
url="http://fanyi.baidu.com/v2transapi"
data={}
data['from']='zh'
data['to']='en'
data['query']=content
data['transtype']='translang'
data['simple_means_flag']='3'
data=urllib.parse.urlencode(data).encode("utf-8")
req=urllib.request.Request(url,data,head)
response=urllib.request.urlopen(req)
html=response.read().decode("utf-8")
target=json.loads(html)
tgt=target['trans_result']['data'][0]['dst']
print("翻译的结果是:%s"% tgt)
time.sleep(3)
else:
break
结果测试:
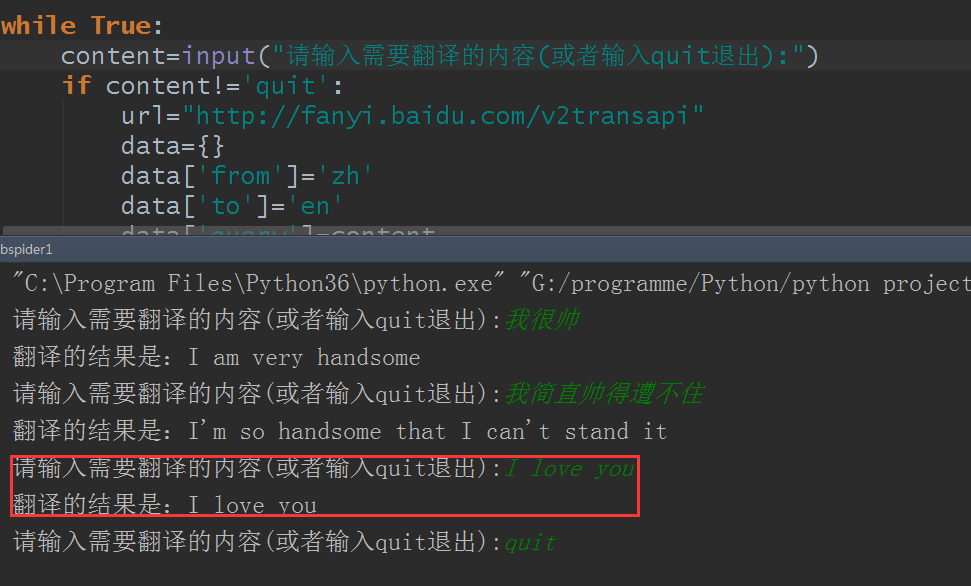
好的,完美翻译,不过这里还是有点小问题,比如只能中文翻译成英文,不能智能翻译,然后如果是用有道翻译或者其他什么翻译的又怎么写呢?好的,这些问题留为作业,自己去研究吧
好的,那么第二个方法,代理IP怎么搞呢?
代理ip得靠包模块urllib.requet创建代理对象urllib.request.ProxyHandler:
然后代理IP得有几个步骤:
- urllib.request.ProxyHandler()的参数是一个字典{‘类型’:‘代理ip:端口号’}:proxy = urllib.request.ProxyHandler({})
- 定制,创建一个opener:opener= urllib.request.build_opener(proxy_support)
- 安装opener:urllib.request.install_opener(opener)
- 调用opener:opener.open(url)
有了这几个步骤才能代理,在python3里就得这样,如果你要在python2里搞也可以的。
然后这里有个问题,代理IP怎么来呢?这里给个链接,西刺免费代理IP,如果你觉得不行,可以自行网上找了
例:
首先我选了一个代理ip:
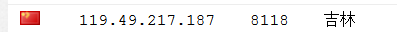
然后写好程序脚本,这里说下,本来没这么想的,但我还是把查询ip的网站用文字打码了,关于查询ip的网站网上很多,你们自己去测试吧,相关原因下面有提到
import urllib.request
proxy=urllib.request.ProxyHandler({'http':'119.49.217.187:8118'})
opener=urllib.request.build_opener(proxy)
urllib.request.install_opener(opener)
head={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'}
res=urllib.request.Request('http://XXXXX.XXX',headers=head)
result=urllib.request.urlopen(res).read().decode('utf-8')
print(result)
结果:

代理成功了,完美
提一下,代码是绝对没问题的,因为我第一次测试都没问题,再次测试就成这样
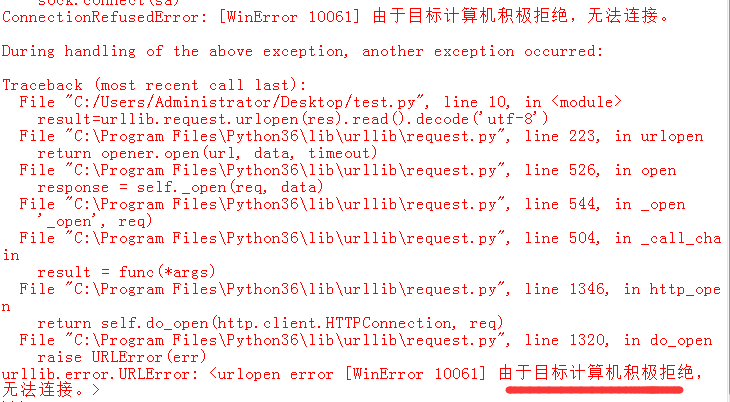
这不是别人网站小气,还是前面博文里说过的,私人网站,没那么抗压,所以都设置了防火墙,如果发现程序异常就拒绝访问,这很正常的,别人网站提供免费的查询,正常查询就好了,如果不设置防火墙,一会儿搞崩一次,一会儿搞崩一次,换成你你高兴不?对吧?
有关代理的补充:
代理分类时,既可以根据协议区分,也可以根据其匿名程度区分,下面分别总结如下:
根据协议区分
根据代理的协议,代理可以分为如下类别:
- FTP 代理服务器,主要用于访问 FTP 服务器,一般有上传、下载以及缓存功能,端口一般为 21、2121 等。
- HTTP 代理服务器,主要用于访问网页,一般有内容过滤和缓存功能,端口一般为 80、8080、3128 等。
- SSL/TLS 代理,主要用于访问加密网站,一般有 SSL 或 TLS 加密功能(最高支持 128 位加密强度),端口一般为 443。
- RTSP 代理,主要用于 Realplayer 访问 Real 流媒体服务器,一般有缓存功能,端口一般为 554。
- Telnet 代理,主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口一般为 23。
- POP3/SMTP 代理,主要用于 POP3/SMTP 方式收发邮件,一般有缓存功能,端口一般为 110/25。
- SOCKS 代理,只是单纯传递数据包,不关心具体协议和用法,所以速度快很多,一般有缓存功能,端口一般为 1080。SOCKS 代理协议又分为 SOCKS4 和 SOCKS5,SOCKS4 协议只支持 TCP,而 SOCKS5 协议支持 TCP 和 UDP,还支持各种身份验证机制、服务器端域名解析等。简单来说,SOCK4 能做到的 SOCKS5 都可以做到,但 SOCKS5 能做到的 SOCK4 不一定能做到。
根据匿名程度区分
根据代理的匿名程度,代理可以分为如下类别。
- 高度匿名代理,高度匿名代理会将数据包原封不动的转发,在服务端看来就好像真的是一个普通客户端在访问,而记录的 IP 是代理服务器的 IP。
- 普通匿名代理,普通匿名代理会在数据包上做一些改动,服务端上有可能发现这是个代理服务器,也有一定几率追查到客户端的真实 IP。代理服务器通常会加入的 HTTP 头有 HTTP_VIA 和 HTTP_X_FORWARDED_FOR。
- 透明代理,透明代理不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理除了能用缓存技术提高浏览速度,能用内容过滤提高安全性之外,并无其他显著作用,最常见的例子是内网中的硬件防火墙。
- 间谍代理,间谍代理指组织或个人创建的,用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
常见代理类型
- 使用网上的免费代理,最好使用高匿代理,使用前抓取下来筛选一下可用代理,也可以进一步维护一个代理池。
- 使用付费代理服务,互联网上存在许多代理商,可以付费使用,质量比免费代理好很多。
- ADSL 拨号,拨一次号换一次 IP,稳定性高,也是一种比较有效的解决方案。
- 蜂窝代理,即用 4G 或 5G 网卡等制作的代理,由于蜂窝网络用作代理的情形较少,因此整体被封锁的几率会较低,但搭建蜂窝代理的成本较高。
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站的站长有异议,请联系我立即删除

