李治军操作系统 笔记
第一篇:操作系统基础
1.1 操作系统概述
1.2 操作系统引导(总体做的:将操作系统读入内存+初始化)
bootsect.s
setup.s
读取硬件参数
读取system到内存0x00位置
从16位模式 转到 32位模式,即从实时模式 转到 保护模式, 使得寻址方式发生了改变,跳转到0x00执行system,其实是转到head.s代码
实时模式: 地址翻译 CS<<4 + IP
保护模式 :根据CS查表 + IP
head.s
初始化GDT,IDT表
转到main()函数,main()是c函数
main()
各种初始化,包括mem_init 标记那些内存块被使用,哪些没有被使用
1.3系统接口
1.3.1 操作系统接口
由系统提供的函数调用
1.3.2 系统调用的实现
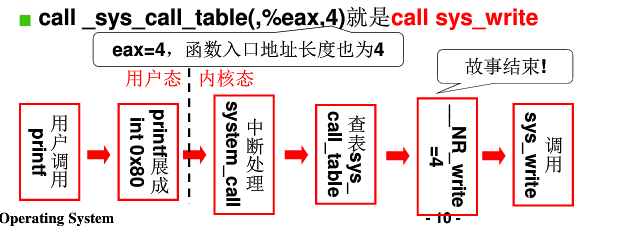
硬件上隔离用户段和内核段,DPL CPL来实现, 其实是把内存分段了,进行隔离保护 从用户段访问内核段,必须通过中断0x80才能访问内核段

库函数write:
1)系统调用号 => %eax
参数1 => %ebx
参数2 => %ecx
参数3 => %edx
2) int 0x80 中断,进入内核,调用 system_call, int 0x80 和 system_call函数的关系要先注册好 ,即设置IDT表,改变了DPL,以及段寄存器地址,还有偏移地址,实际上就是设置了DPL和中断函数地址 !!!
system_call:
call _sys_call_table(,%eax,4) //eax保存的是系统调用号,有查call_table表格
call_table :
//查找表,通过系统调用号查找对应的系统调用指针,然后去调用对应的sys_write
疑问
有system_call()的函数声明,但是没有实体,只有在.s文件中找到_system_call的标号
就是是_system_call,
在c语言中声明和调用的时候都写成system_call
在汇编中声明为_system_call,多一个下划线
汇编中调用汇编,则调用_system_call;
汇编中调用c函数,要在c函数前面加一个下划线,、_function;
1.4 操作系统历史
Unix
进程图谱
文件操作
第二篇. 操作系统之 进程与线程
六、 线程引出与实现
L10:用户级线程
进程 和 线程 都是动态概念
进程 = 资源 (包括寄存器值,PCB,内存映射表)+ 指令序列
线程 = 指令序列
线程 的资源是共享的,
进程 间的资源是分隔独立的,内存映射表不同,占用物理内存地址是分隔的
线程 的切换只是切换PC,切换了指令序列
进程 的切换不仅要切换PC,还包括切换资源,即切换内存映射表
用户级线程:调用Yield函数,自己主动让出cpu,内核看不见,内核只能看见所属进程而看不见用户级线程,所以一个用户级线程需要等待,内核会切到别的进程上,不会切到该进程下的其他用户级线程!!!
内核级线程: 内核能看见内核级线程,一个线程需要等待,内核会切到所属进程下的其他内核级线程。
L11:内核级线程
11.1 基本概念
只有内核级线程才能发挥多核性能,因为内核级线程共用一套MMU,即内存映射表,但是有多个CPU,可以一个CPU执行一个内核级线程
进程 无法发挥多核性能,因为进程切换都得切MMU,即切换内存映射表,一个
内核级线程的切换需要两套栈: 用户栈 + 内核栈
11.2 完整的系统调用中断过程:
- INT中断自动压栈的有下一条指令,以及用户级线程SS:SP,就是下图五个参数
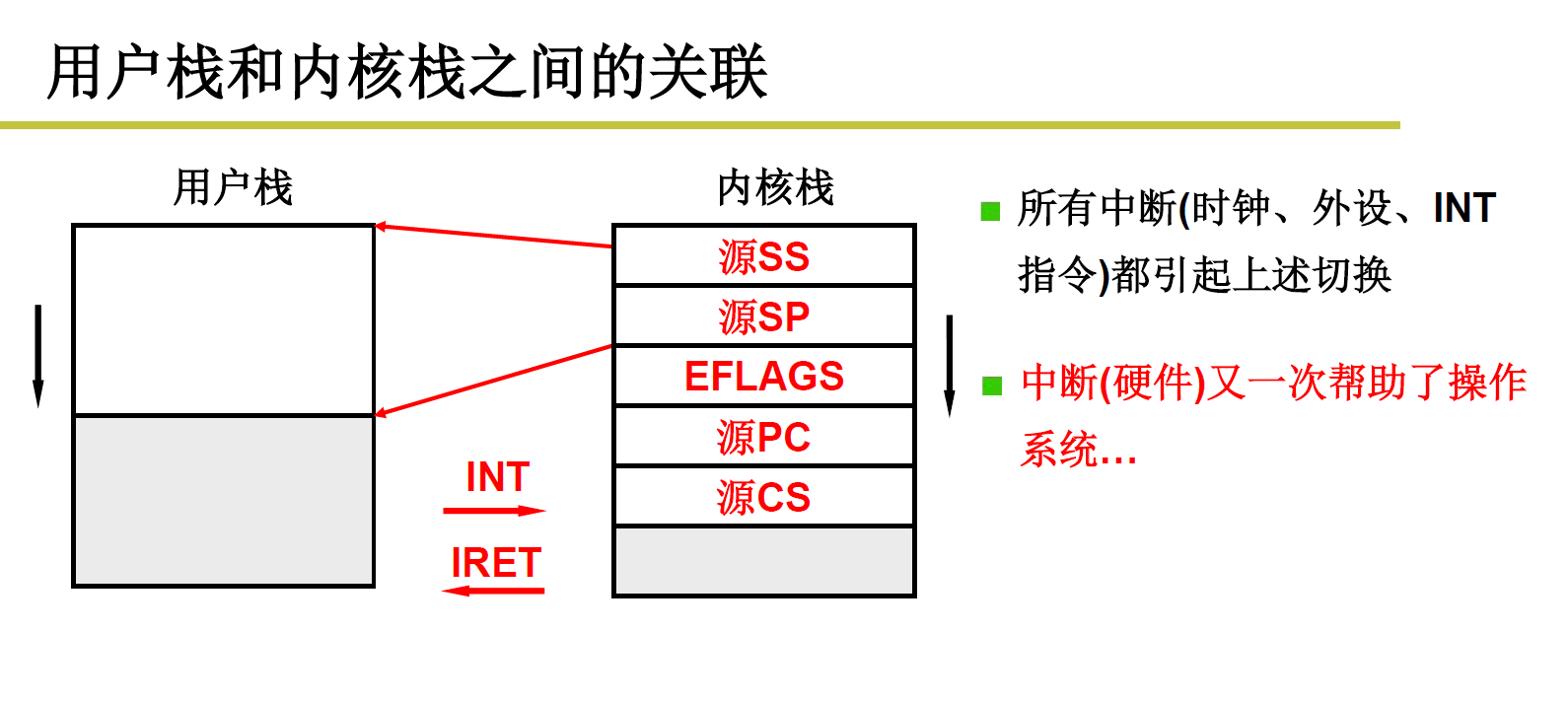
- _system_call 把寄存器保护压栈是压到内核栈中,需要手动压栈
- 系统调用,(有可能是_sys_fork,其实就是根据标号找到的系统调用),结束之后继续执行,要执行reschedule,先push $ret_from_sys_call,让其在_schedule之后返回到ret_from_sys_call, _schedule为c函数,结束右括号会把ret_from_sys_call pop出来,返回到这里执行,即执行ret_from_sys_call;
这里注意call 和 jmp的区别!!!
4)在ret_from_sys_call中pop出_system_call时保护的寄存器内容,然后中断返回!!!
5)中断返回是在最后,中断返回会把SS:SP 以及用户态的下一条指令 POP出来,即把5个寄存器pop出来!!!这样就会返回到用户栈,运行用户态的下一条指令!!!
代码:
reschedule:
pushl $ret_from_sys_call
jmp _schedule //如果用call就是先将下一条指令压栈,然后jmp,这样只能顺序往下走,但是用push+jmp则可以改变跳转地址!!!123
11.3 switch_to五段论

这里要注意,中断出口这里已经经过了前面的switch_to,中断的iret已经不是原先的中断返回了,是切换后的新中断的执行返回!!!这样返回以后就来到了引发该新中断的用户态代码来执行
11.4 内核级线程切换实例
fork函数经典调用
if (!fork()) //关键在于 INT 80 后面的指令 mov res, %eax;父进程和子进程都会执行这个代码,但是%eax的值不一样
{
子进程
}
else
{
父进程
}12345678
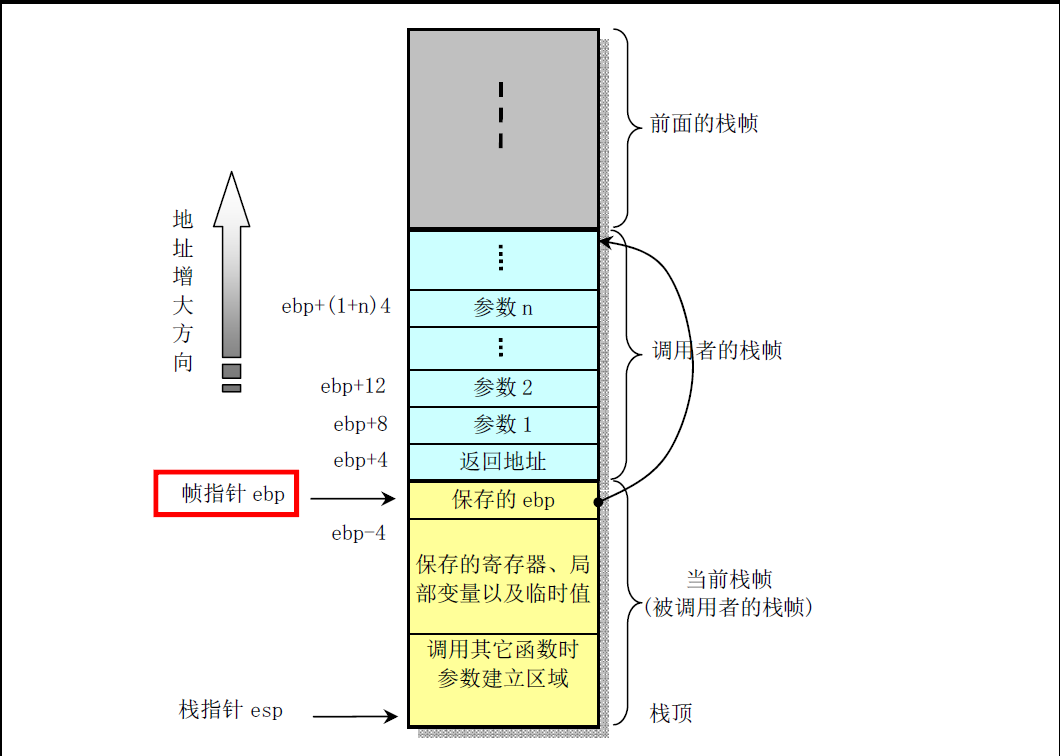
11.5 汇编调用c函数
实际上是把参数都压到栈里,然后c程序就可以调用,用call来调用
但是要注意c语言 调用结束后,要把栈里的参数删掉,即addl指令,把指针改一下,忽略那些参数
实际上是
push 参数
push 返回地址
jmp 调用地址
c函数右括号会生成ret指令,会返回到返回地址!
这个时候要把没用的参数从栈里去掉,这就是为什么要调用addl



L12 核心级线程实现实例
L13 操作系统的那棵树
只有进入内核才能进行内核调度,进入内核的唯一方法就是中断
七. CPU 调度
L14 CPU调度策略
14.1 指标
周转时间: 从开始申请执行任务,到执行任务完成
响应时间: 从开始申请执行任务到开始执行任务
14.2 三种调度方法
1) 先来先服务 平均周转时间可能会很长
2) 短作业优先(SJF)
周转时间短,但是响应时间长
适用于后台程序,如gcc的编译,快点把整个程序编译完
3) 时间片轮转(RR)
响应时间可以得到保证,nT,n为任务个数,T为时间片长度,
适用于前台程序,IO操作多的
4) 优先级轮转
固定优先级,可能会造成又程序一直没法得到执行,需要动态调整优先级
L15 一个实际的schedule函数
八. 进程同步与死锁
L16 进程同步与信号量
同步的作用: 各个程序走走停停,配合向前推进
同步 = 等待 + 唤醒
依据信号量来执行等待和唤醒
信号量 为负数表示欠
为整数表示富裕
L17 信号量临界区保护
17.1 为什么要保护
同时修改信号量可能造成empty的含义不正确

empty正常应该为-3,但是可能因为同时修改变成了-2,含义不对了
必须进入临界区以后才能修改信号量,修改完成后退出临界区,临界区是互斥的,只能有一个进程能够进入各自临界区!!!
验证保护算法是否合理的标准:
互斥进入
有空让进
有限等待

17.2 如何实现保护
其实是进入临界区的保护
17.2.1 软件方法
1)轮换法 有空让进效果不好!!!
2)标记法 可能会造成无限制空转等待
3)非对称标记 结合了标记和轮转两种思想
两个进程:Peterson算法
多个进程:面包店算法
17.2.2 硬件方法
关闭中断来关闭调度即可
但是注意,多CPU的时候不好使
这里涉及到多cpu如何schedule
17.2.3 硬件原子指令
其实是用 mutex锁信号量 来保护信号量,为了解决mutex仍然需要保护的问题
使用硬件级原子操作,不能被打断不能切出去进行调度

L18 信号量的代码实现
信号量的用法可以有两种:
1)sem 有正有负
-n 表示有n个进程在等待这个资源,欠了n个
+n 表示该资源有n个空余
这种可以用 if来判断是否睡眠
但是这里没说如何唤醒
2)sem 只有0,和1两种状态
1表示锁住态
0表示解锁态
在检查的时候用while处理,当锁住则睡眠,当被唤醒,重新要检查下状态是否被锁住
这个需要外围机制配合,唤醒的时候,是将整个等待此资源的队列里的所有进程都唤醒,然后让其根据优先级去竞争调度,起到优先级搞得优先获得该资源继续执行的效果!!!

唤醒等待此资源的队列里的所有进程的原理是,先唤醒队首进程,再让队首进程去唤醒下一个,以此类推,一路唤醒!!!
void sleep_on(struct task_struct **p){
//p是指向队首pcb的指针的指针
struct task_struct *tmp; tmp = *p;
//tmp指向原来的队首
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
schedule();
if (tmp) //用来唤醒下队列中下一个等待资源的进程
tmp->state=0;
}
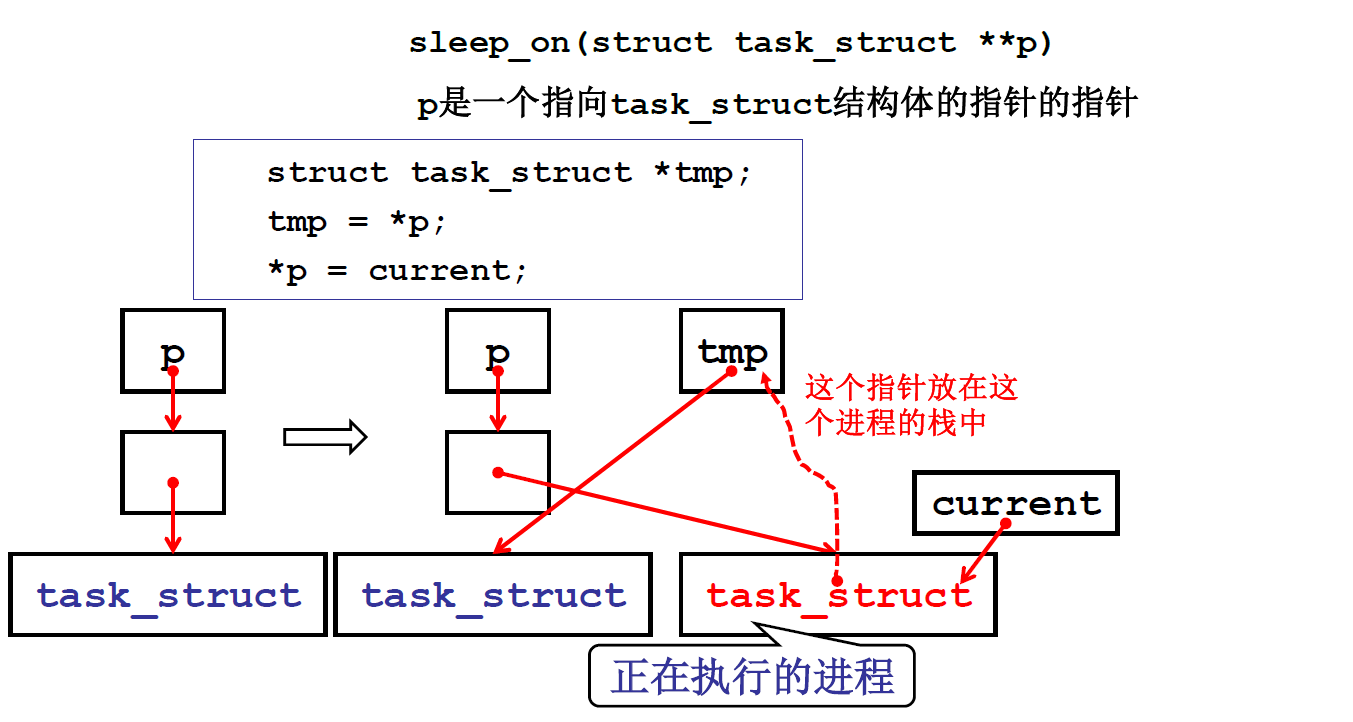
实际上市把自己作为了队首,然后用tmp记录了队列里的下一个pcb,便于在唤醒的时候能够唤醒队列里的下一个进程
L19 死锁
19.1 必要条件

形成了资源等待环路!!!
19.2 死锁处理方法

死锁预防:
死锁避免 :检测每个资源请求,假装分配,看看进程组是否会造成死锁,如果造成死锁就拒绝如果找到了安全序列,就可以这样分配。
银行家算法
但是这样的算法时间复杂度太高,每次请求资源都算一次,效率太低
死锁检测+恢复:
等出现问题了,有一些进程因为死锁而停住了,再处理,选择一个进程进行回滚,然后再用银行家算法来算是否能找到安全序列,如果不行,再回滚,直到所有程序都能执行。
但是回滚是个大问题!!!已经写入磁盘,还得退回来,那就很麻烦了。
死锁忽略:
windows,linux个人版都不做死锁处理,直接忽略,大不了重启就好了,小概率事件,代价可以接受
第三篇. 操作系统之 内存管理
九. 内存管理
L20 内存使用与分段
20.1 运行时重定位
基地址 + 逻辑偏移地址
基地址以表的形式保存在PCB中
一个程序分成多个段,每个段都需要记录其基地址,存在一个表中,该表称为段表,段表保存到PCB中
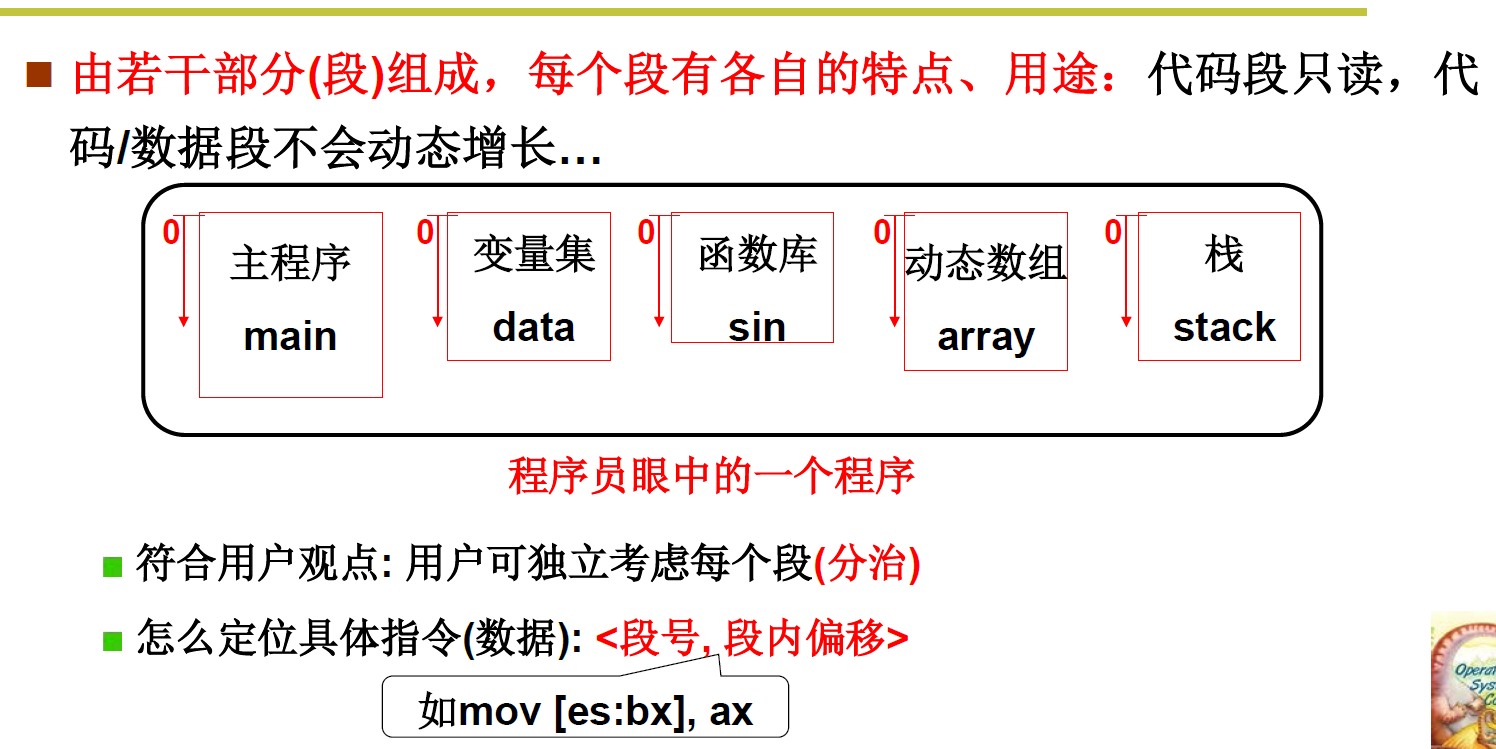
GDT : 操作系统的段表
LDT : 各个用户进程的段表
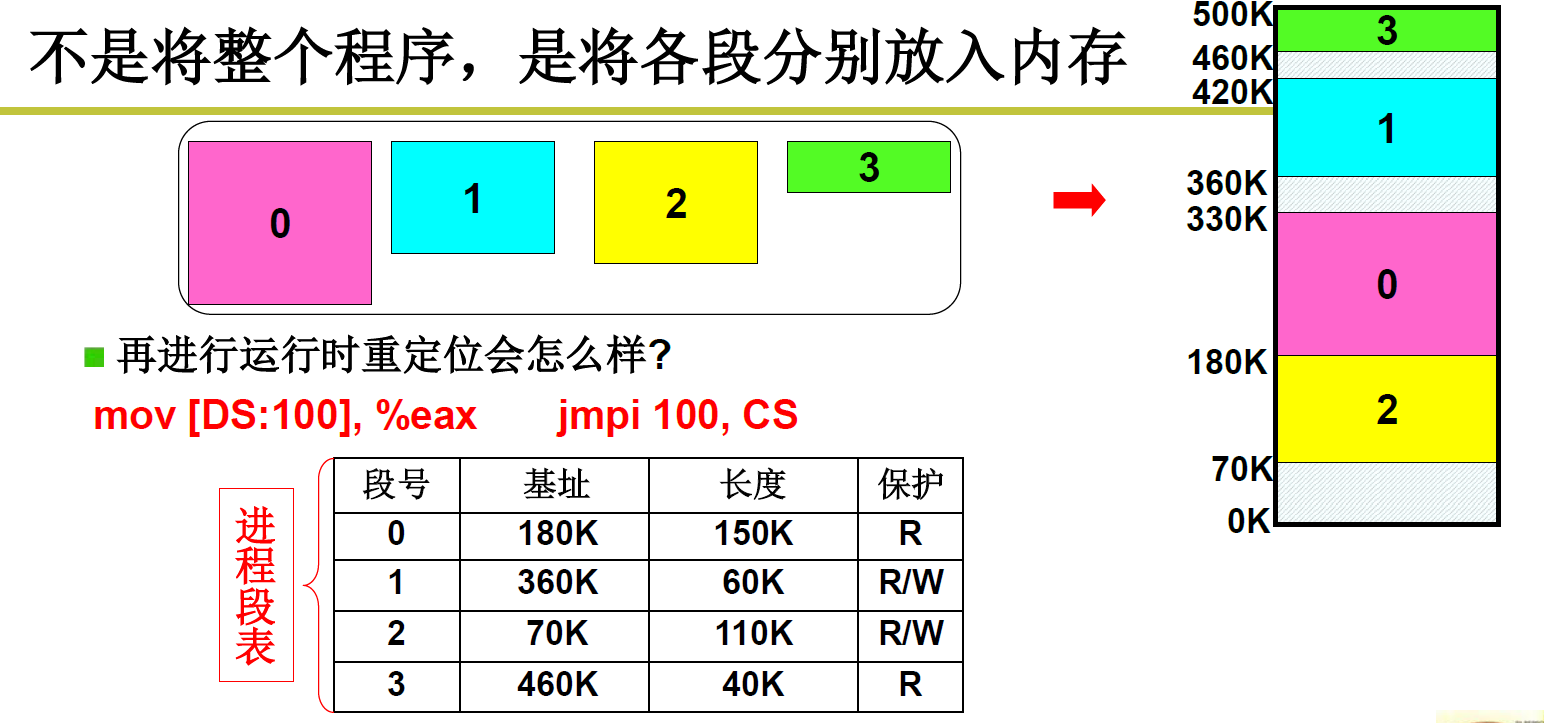
L21 内存分区与分页
直接按段来分,程序员很喜欢,可以将数据段 和 代码段分开加载,可以设置只读,可读写属性
但是会有一个很大的问题 : 内存碎片,导致后面没有符合要求大小的空闲内存
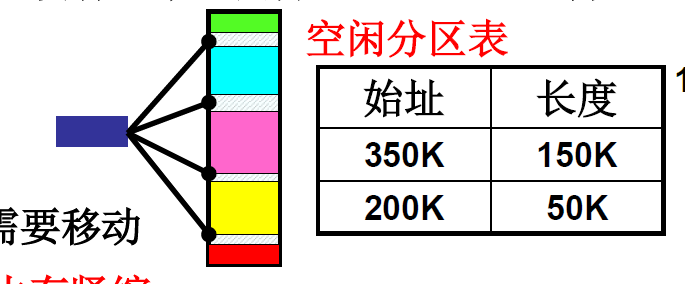
解决办法: 不要对内存进行连续的分配,将内存划分成1页1页,按页分配,1页4kb大小,最多浪费的也就4KB。这样不会有内存碎片,也不会出现没有符合要求大小的内存可以申请的情况,因为可以打散了分散到一页一页中。
连续的变成离散的,需要记录这种映射关系,所以就有了页表。

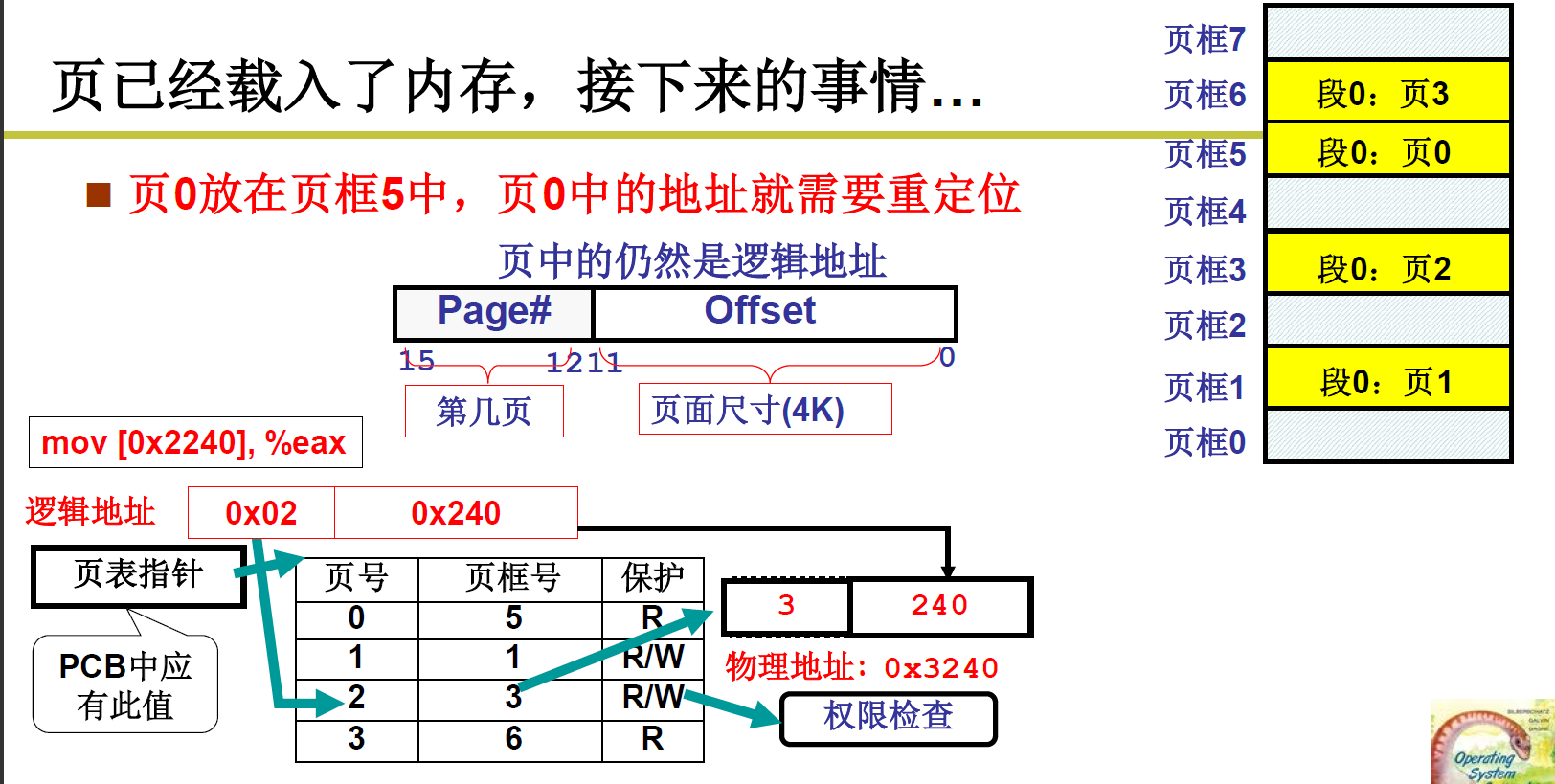
这里其实是对整个32条地址线的4G空间做了划分,建立了一个页表;
相当于说对可能用到的地址做一个虚拟页到物理页的映射转换
4G空间,每4KB一页,一共有1M页,那么映射表就是这1M页的相互连线映射关系
L22 多级页表和快表
按上一节的页表处理方式,页表的储存空间太大,1M页的映射关系,每条映射关系需要4字节来存储,那么就需要4M空间来存储页表;
每个进程4M,10个进程就要40M,十分的浪费!!!
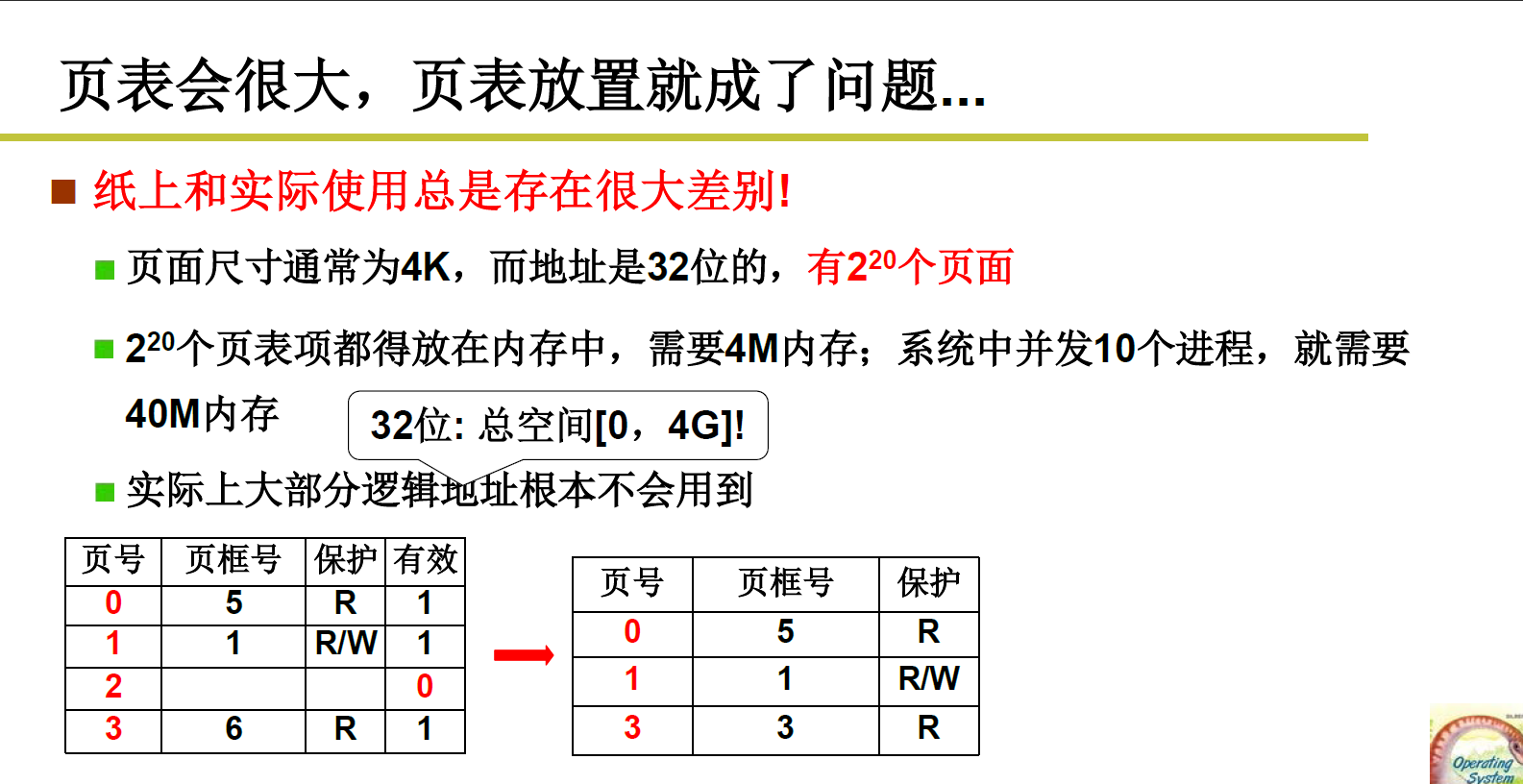
有很多都是没有用到的,一个程序不可能占满了4G内存空间!!!
所以要想办法减低存储。
法一.
删除那些没有用到的表项
虽然存储减低了,但是会造成无法页号编码不连续,查找映射关系的时候非常麻烦,需要从上往下遍历,看是否是该页号,时间效率很低
法二.
用多级页表
(相当于书的目录的作用)
既减轻了存储压力,每个还都连续,时间效率比较高
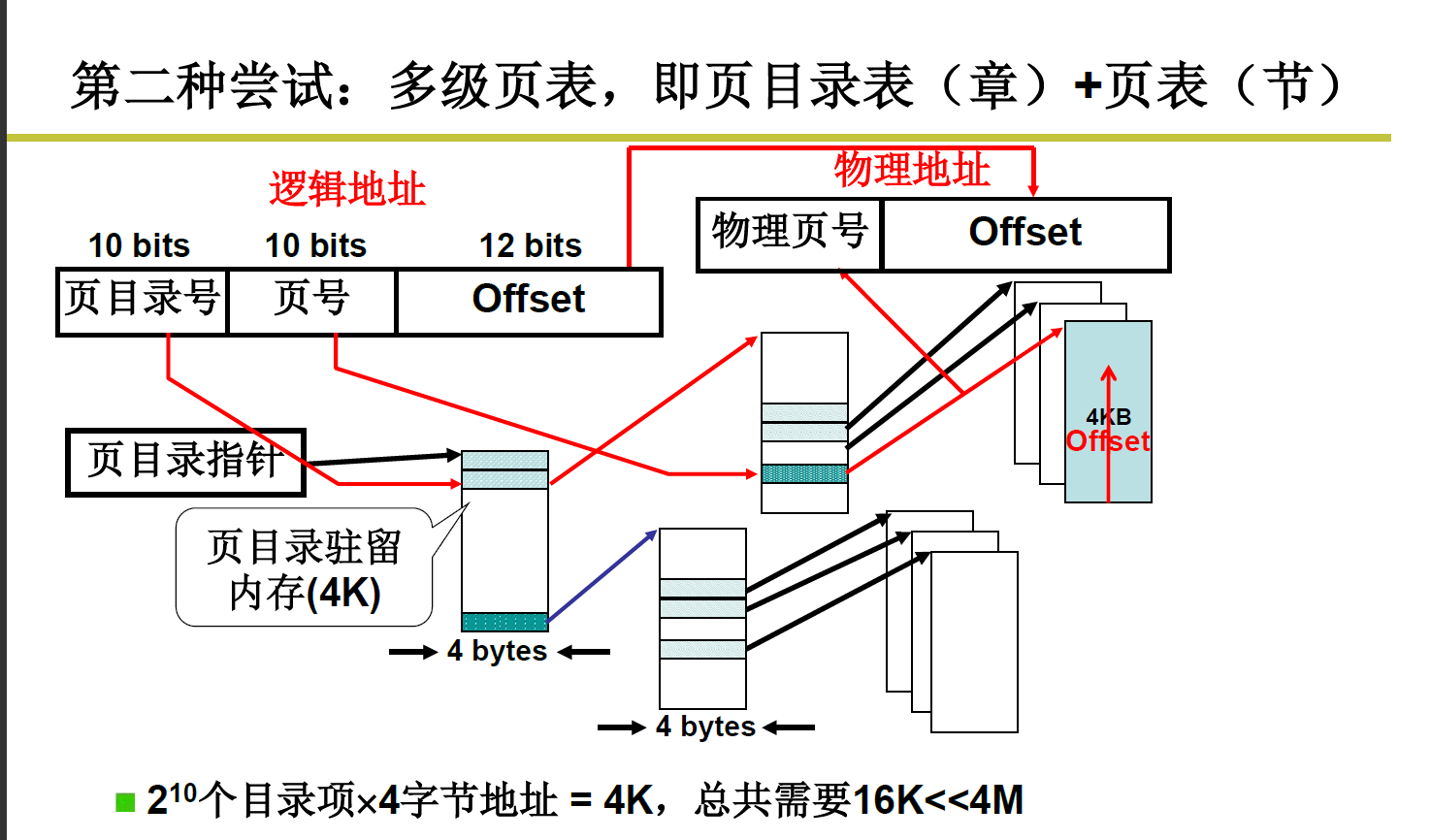
这里16K是这么来的:
用到三个页目录号,每个页目录号下一级的页表存储空间为 3 * 4KB = 12KB,
加上本身页目录表需要的4KB一共为16KB。
关键在于,有些没有用到的页目录号后面根本就没有再存下一级的映射表,节省了大量空间!!!
法三.
多级页表 + 快表
快表相当于一个cache,把频繁使用的地址映射记录下来
L23 段页结合的实际内存管理
程序员喜欢段,物理内存要用到页,为了满足这两个要求,操作系统在当中用虚拟内存做了一层中转
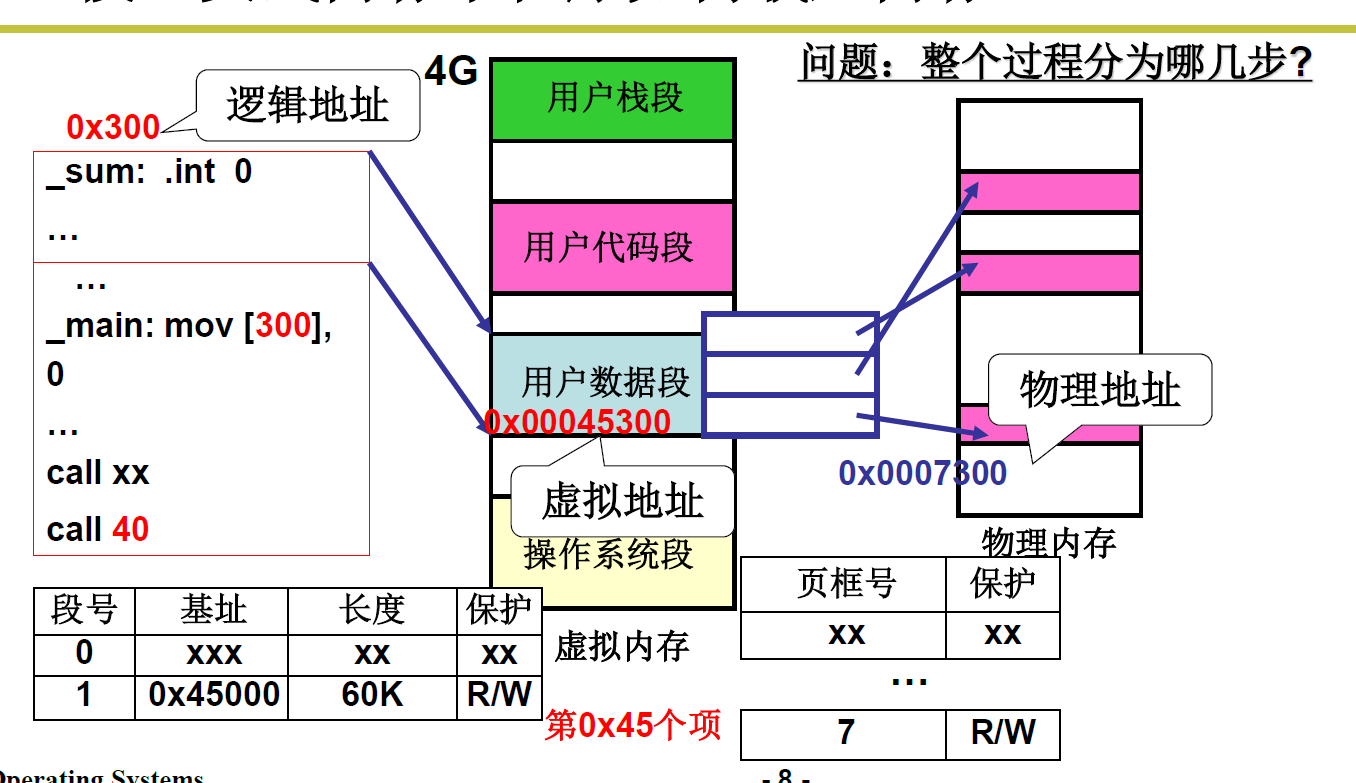
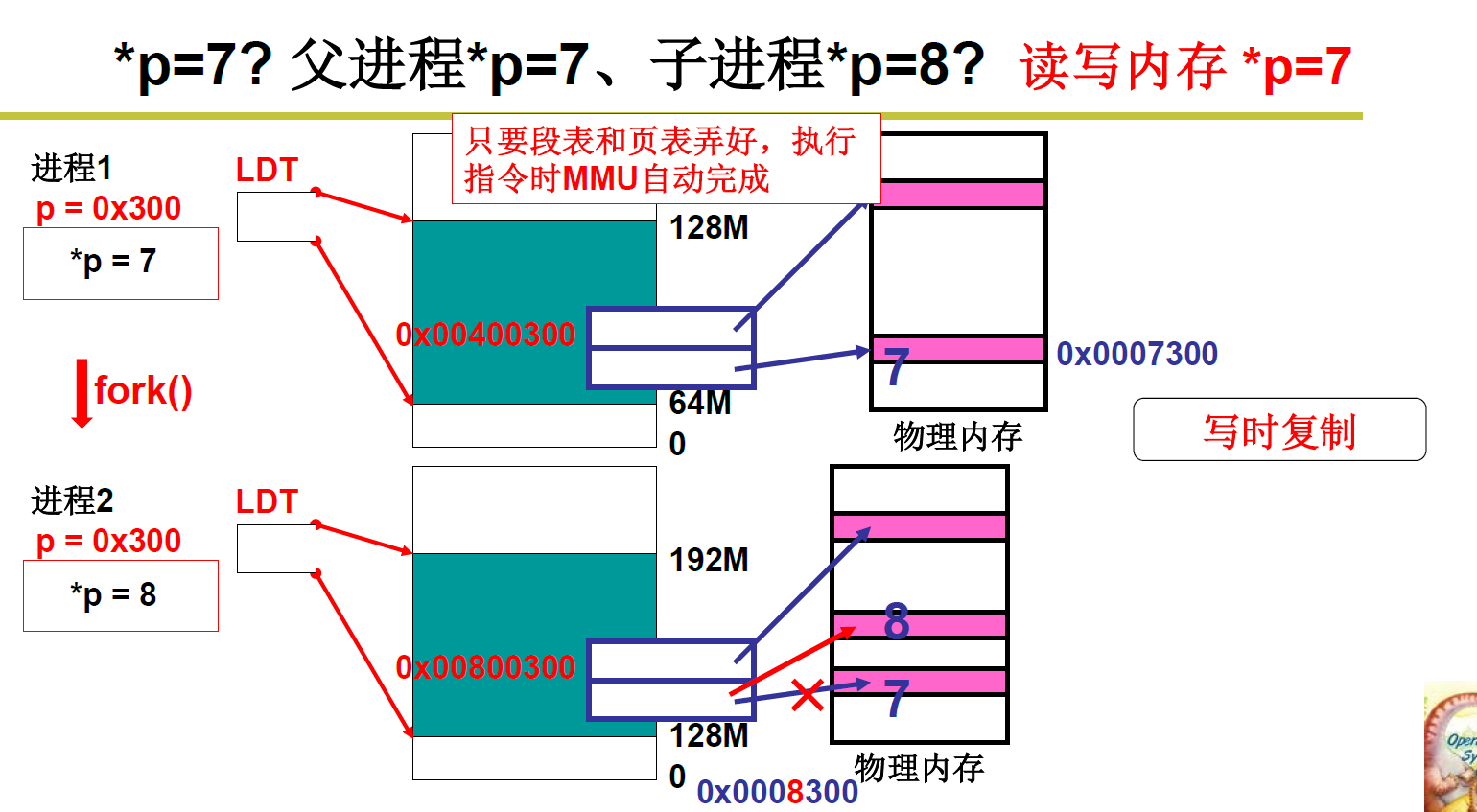
fork
copy_mem 这个函数可以好好读一下,配合linux0.11注解
1)子进程的数据段和代码段映射到不同的虚拟内存地址,每个进程分配 64M 虚拟内存地址
2)父进程和子进程共用一套页目录表,因为虚拟地址不同,页目录号号不同,不打架
3)在页目录表中增加对应页框号表,即父进程和子进程中对应的虚拟地址不同,但是不同地址映射到了同一块页框,也即映射到同一块物理内存。
4)然后对子进程设置共享内存段属性为只读,这样在子进程往里写的时候,会发现只读,会修改映射,映射到其他空间!!!
达到对于用户来讲虽然是操作的同一个地址,但其实对应的是物理内存的两块区域,即子进程和父进程的内存区域是分隔的!!!
L24 请求调页与内存换入
虚拟内存永远是4G空间, 但是物理内存可能只有1G或者2G
操作系统做了一层封装,对于用户来讲,使用的空间一直都是4G虚拟空间
操作系统配合MMU,把虚拟地址映射到物理内存页上
L25 内存换出
有换入就有换出
25.1 换出哪一页的算法
1)FIFO
2)MIN算法
最优,但是需要知道将来请求的页号,不现实
3)LRU 最近一段时间内,最久不使用的页换出去,即最近最少使用的换出去
时间戳: 时间代价太大
页码栈: 修改指针次数太多,代价还是太大
近似算法:
用是和否来表示,有访问到这块内存,MMU自动把R置1
指针去找R为0的地方替换,碰到R=1的地方先做R=0
但是这个方法有缺点:缺页比较少的时候,所有的R都为1,每次都要转一圈才能找到换出去的页,退化成FIFO,效率不高
改进: 双指针,一个快,一个慢,像时钟一样
快时钟做R的清0定时清0,等到慢指针转到这里的时候R=0,说明在定时时间片内没有备访问,该页可以被替换了
25.2 给一个进程分配多少个页框
工作集算法
